はじめに
世の中には数多のデータベース製品があり、各データベース製品はその機能や性能の優位性を競い合っています。当記事では 「データベースの検索処理の高速化」 について注目して、色々なデータベース製品が提供している検索高速化のための手法をザックリまとめてみます。
一口にデータベース製品といっても、ご存知のように RDB、Key-Value DB、Document DB、Wide-Column DB、Graph DB など様々なカテゴリのデータベース製品が存在します。当記事では、その内で RDB をベースにした説明内容で進めますが、1つ1つの手法のエッセンスはデータベースのカテゴライズに依らず通ずるところがあるかなと思います。それでは本題に入ります。
データベース検索を高速化する2つのアプローチ
まず、話をとても簡単にするため下図のようなデータ表の中から目的のデータ(★マーク)を見つけるケースを想定したいと思います。通常は愚直にデータを探しに行くとなると、表の中のデータを1行1行 総なめしながら探すことになります。
※補足: ちなみに、★マークが見つかったところでデータ読み込みを終了するか、表の最後まで読み込むかは、今回の記事の内容に大きくは影響しませんので、マーク以降の矢線を見やすさのため省略します。
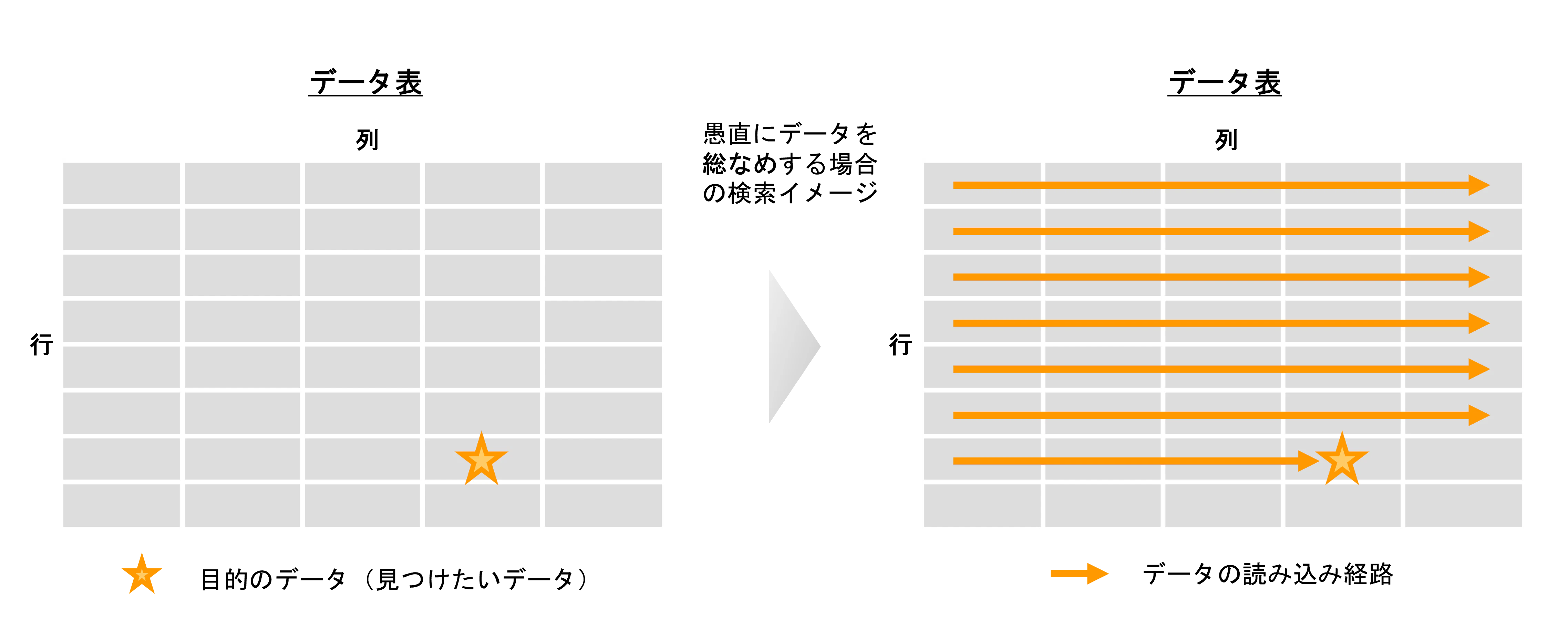
このような状況において、より高速に、より効率的に目的のデータにたどり着くためにどんなアプローチがあるか考えてみます。大きく分けて、次の2つアプローチがあるかと思います。
-
アプローチA(近道系): データを見つけ出すまでの読み込むデータ量(byte)を減らす
-
アプローチB(力技系): 単位時間あたりに読めるデータ量(byte)を増やす
前者のアプローチAは、言い換えると効率よく近道してピンポイントに目的のデータにアクセスするアプローチです。後者のアプローチBは、マシーンパワーを最大限に活用して力技で目的のデータを見つけ出すアプローチです。実際に上記2つのアプローチを実現するための具体的な手法を、前述の総なめ検索のイメージ図と比較する形で考察していきます。なおイメージ図はあくまで概念的なもので、データベース内部の正確な挙動とは差があるかもしれませんが、ご容赦下さい。
A. 読み込むデータ量を減らすアプローチ
それでは、まず アプローチA: データを見つけ出すまでの読み込むデータ量(byte)を減らす手法から見ていきます。
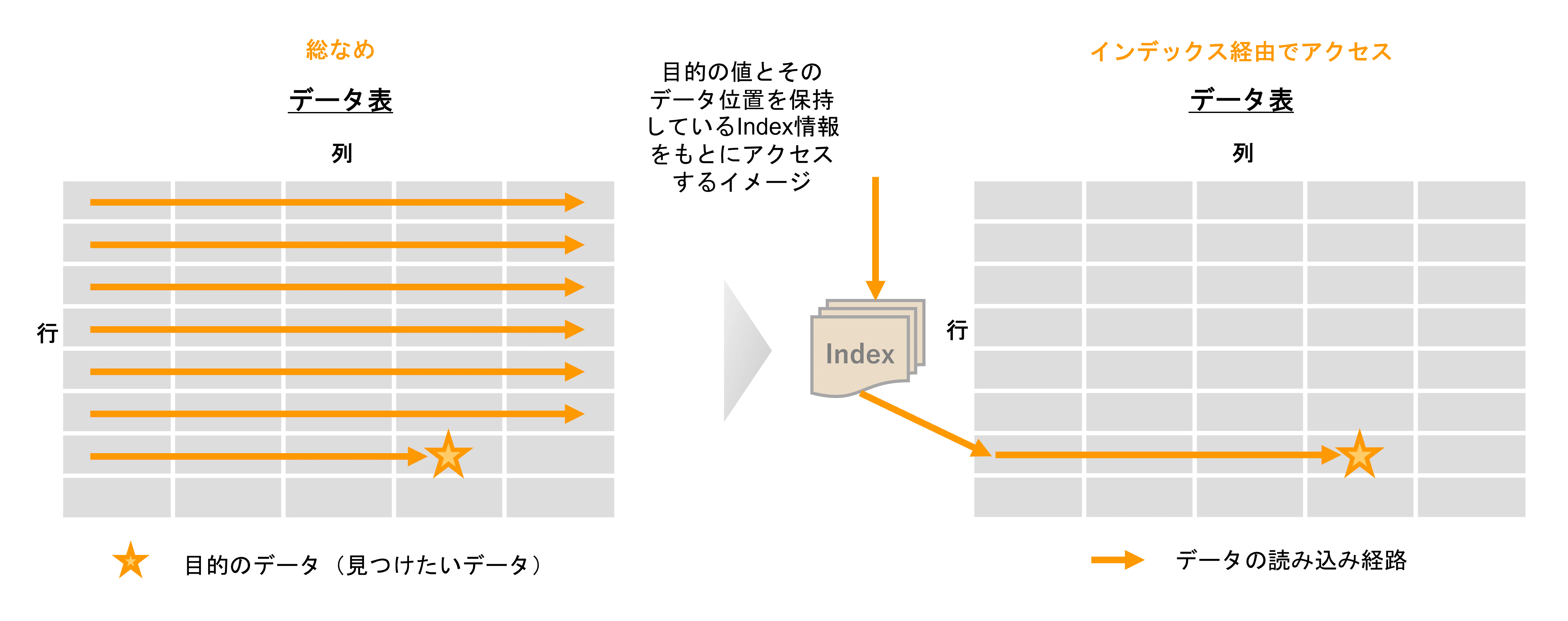
1. インデックス(索引)
まずは、みんな大好きインデックス(索引)です。データベース検索の性能チューニング時に最初に思い浮かべる手法のひとつかと思います。代表的なものとして B-Treeインデックスが挙げられます。目的の値を持つレコードが表の中のどこに格納されているかの目次をあらかじめ作成することで、その情報を使って効率よくレコードにアクセスします。但し、データ検索時に威力を発揮するインデックスではありますが、データ更新時は表の中の値に加えてインデックス情報も合わせて更新する必要があるため、データ更新時にはオーバーヘッドが発生します。
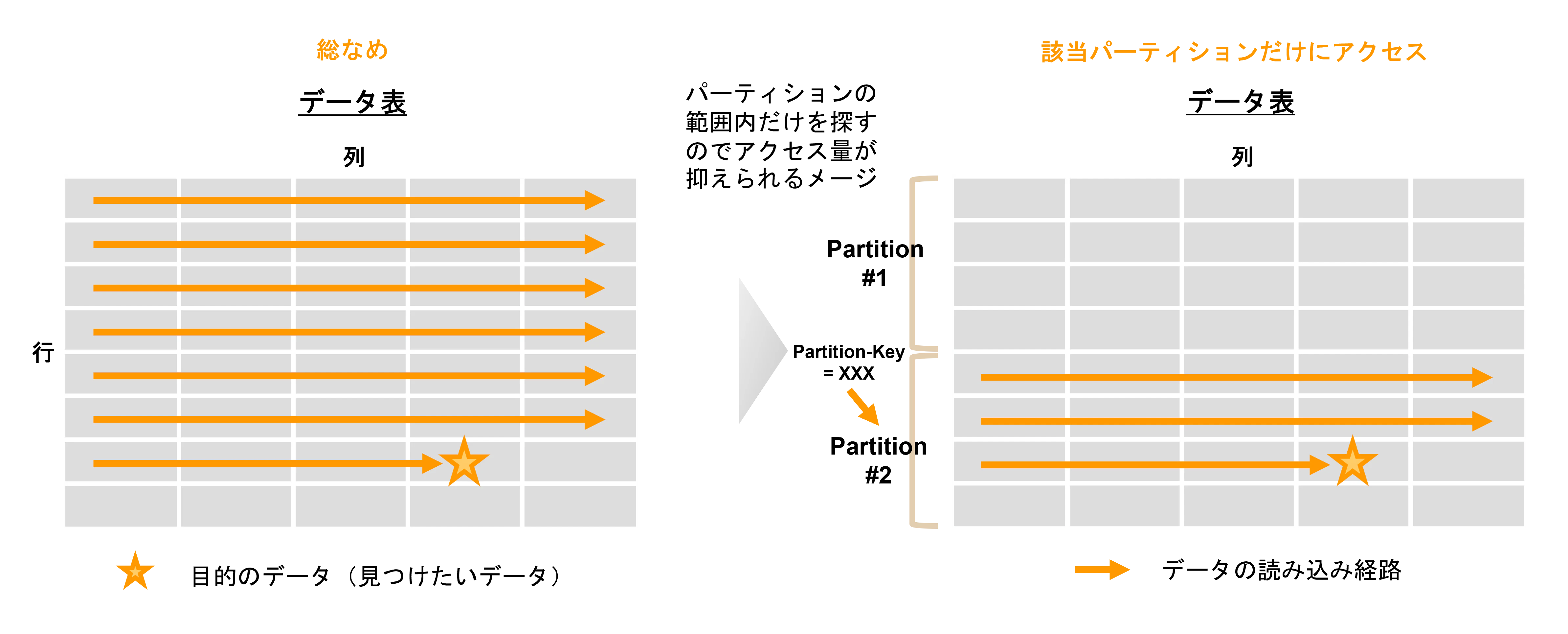
2. パーティショニング
データの各行(または各列)をパーティションと呼ばれるグループに分けて管理する方法。データ分割の基準となるキーがパーティションキーで、範囲分割、リスト分割、ハッシュ分割などで設定します。このパーティションキーを指定して検索することで検索範囲が該当パーティションだけに絞り込まれ、全データ総なめよりもアクセス量が減ることでより素早く目的のデータにたどり着けます。なお、下記の絵はあたかも都合よくアクセス出来るように描いておりますが、実際にはどのようにパーティションキーを設定してパーティショニングをしたら、アクセス効率が良くなるかをしっかりと設計する必要があります。
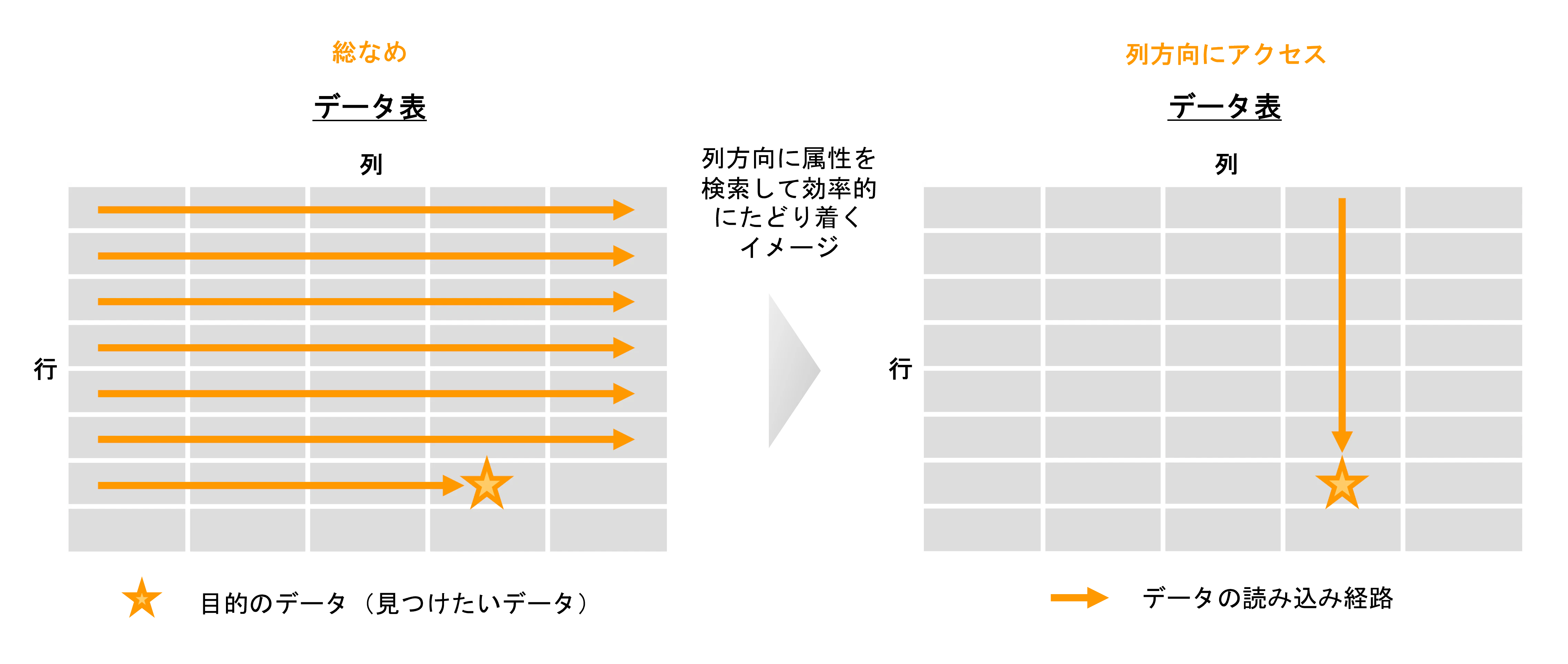
3. カラムナフォーマット
従来、RDB は行単位にデータを検索する(イメージ図で言うと横方向)ため、検索する過程で必要のない属性の情報までも読み込んでしまいます。データベースの更新操作をする上では行単位での操作の方が扱いが楽ですが、検索操作をする上では前述のように無駄なアクセスが発生します。これを解決するために、目的の属性に対して列方向からアクセスできるカラムナフォーマットというデータ形式があります。これにより目的の属性の目的の値に効率よくアクセスすることが出来ます。但し、たくさんの属性にアクセスするようなクエリの場合、結局は読み込まないといけないカラム(縦線)が増えてしまいメリットが活きません。
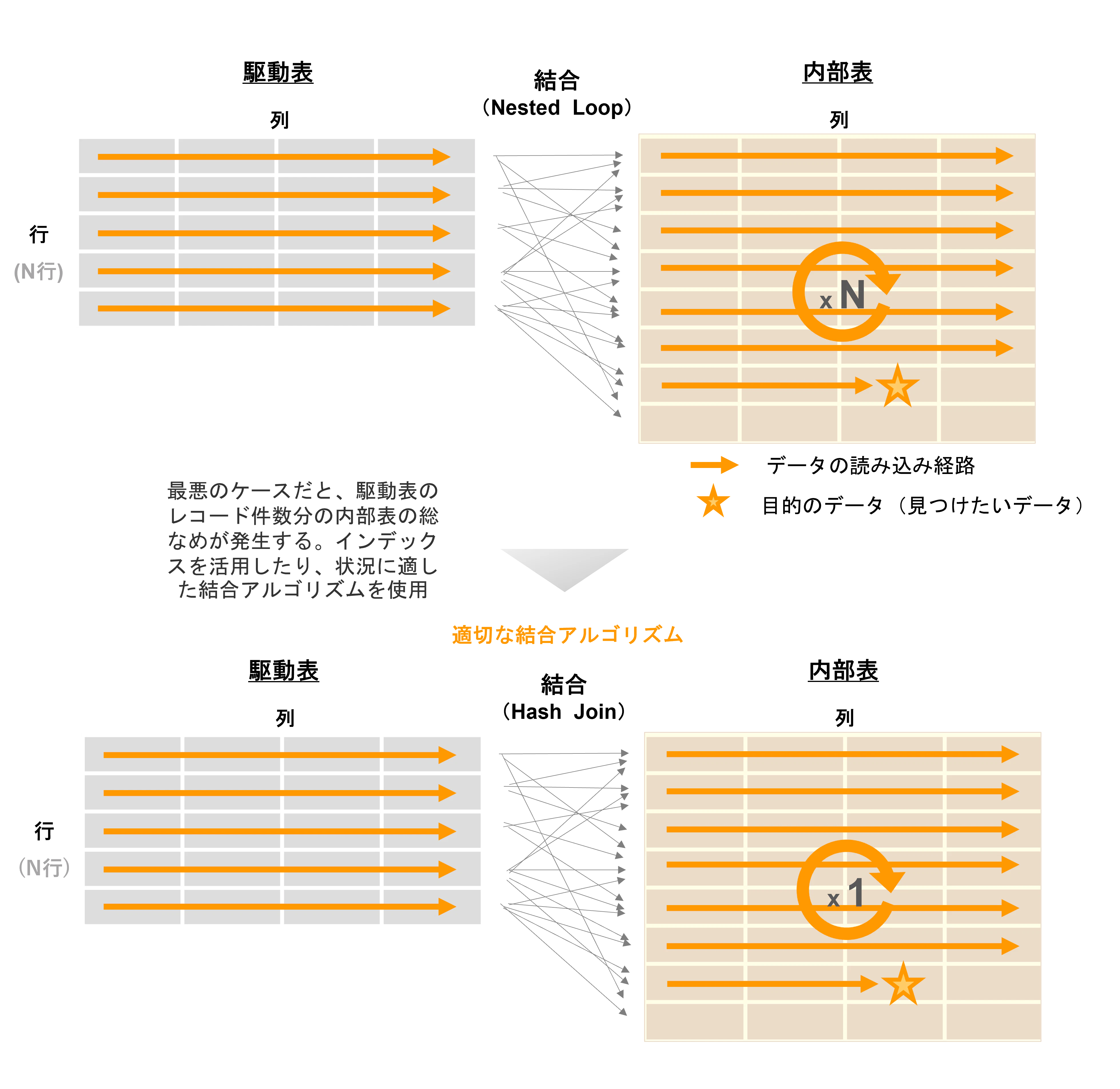
4. 結合アルゴリズム
SQLにおける結合操作(JOIN 句)は検索において非常に強力な操作で、まさにリレーショナルモデルの肝とも言えます。一方で性能負荷も高い操作です。間違った結合アルゴリズムを選択すると性能が大きく劣化します。主なデータベース製品が提供している結合アルゴリズムの代表的なものとして、Nested Loop結合、Hash結合、Sort Merge結合があります。適した結合アルゴリズムを選択することで、無駄な読み込みを抑えることが出来ます。
具体的に、どういった状況(例: レコードが少量に絞られた上での結合のケースや、大量に結合レコードが存在するケース等)で、どの結合アルゴリズムが適しているかについては当記事の範疇を超えるので割愛いたします。下記の図は最悪ケースの一例として、駆動表のレコード件数分だけ結合先の表(内部表)の総なめが発生するケースを記載しています。
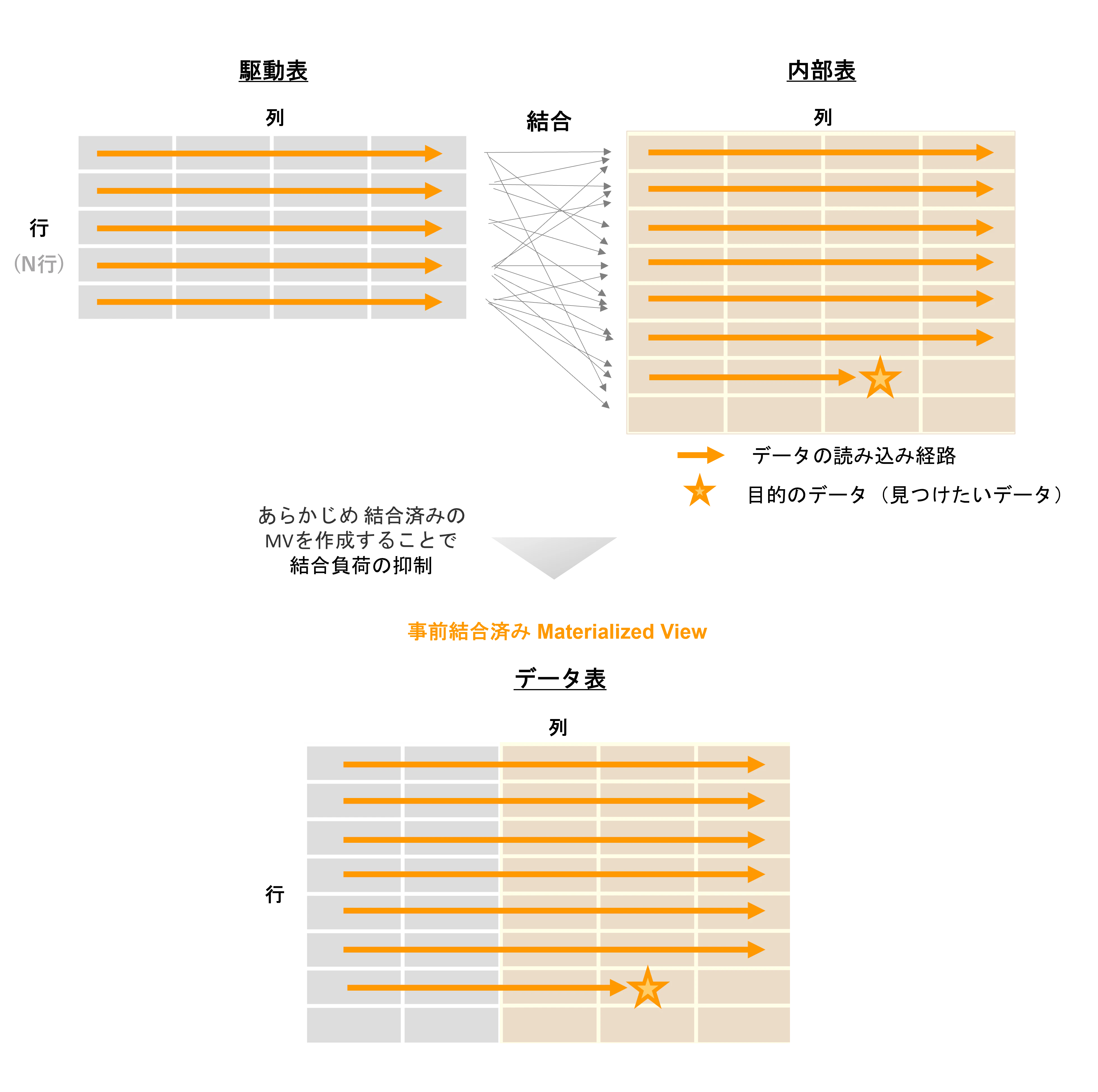
5. Materialized View
前述の結合操作の負荷を緩和する1つの手法として、Materialized View という手法もあります。検索SQLが発行されてから結合操作を開始していたら結合が終わるまでに時間がかかるので、あらかじめ事前に結合済みのデータセットを Materialized View として保持することで結合処理の負荷を軽減することが出来ます。もっとも、Materialized View は、事前結合済みにする目的だけでなく事前集計済みのデータセットを保持する目的でも利用されます。結合や集計といった I/O負荷のみならずCPU負荷も含めた負荷の高い処理全般を検索SQL発行毎に実施するのではなく、事前に実施しておいてSQL発行毎に都度計算する手間を省きます。
※補足: Materialized View をアプローチA の手法として結びつけるのは いささか強引ですが、今回 広義の意味で挙げています。
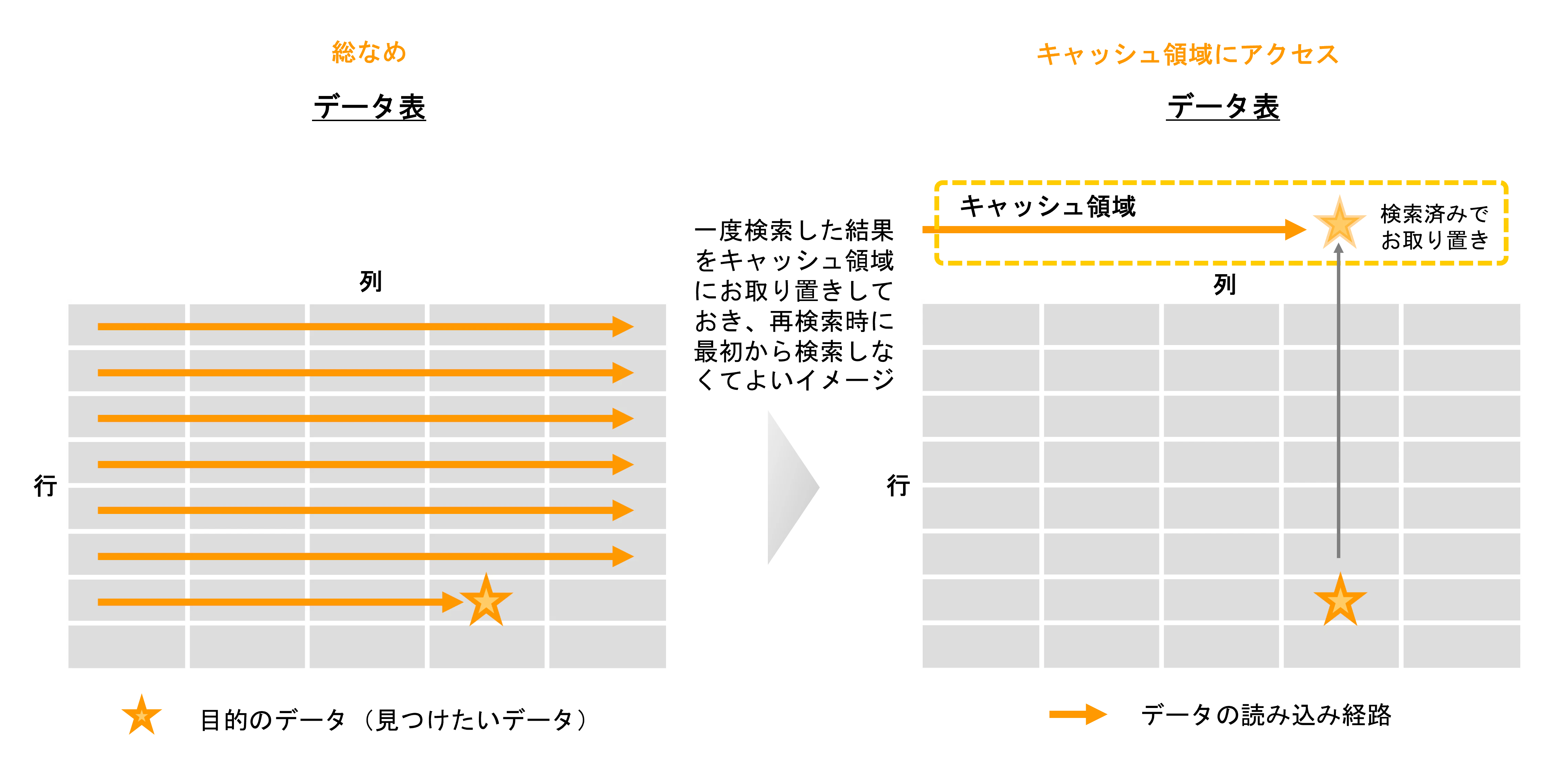
6. クエリキャッシュ
一度検索したクエリとその結果をキャッシュ領域に別途お取り置きしておくことで、2回目以降の検索でそこに素早くアクセスして目的のデータを取り出すことが出来ます。初回検索においてはアドバンテージはありませんが、この手法を使って頻繁に検索されるデータをキャッシュ領域に格納したり、プロビジョニング時に前もってキャッシュ領域に格納することで実運用上の高速検索のアドバンテージを得ることができます。但し 付随して、表の中のオリジナルの値が更新されるとキャッシュ上の値が古くなってしまい、いつキャッシュを再更新・破棄するかといったキャッシュ鮮度の考慮も必要になってきます。
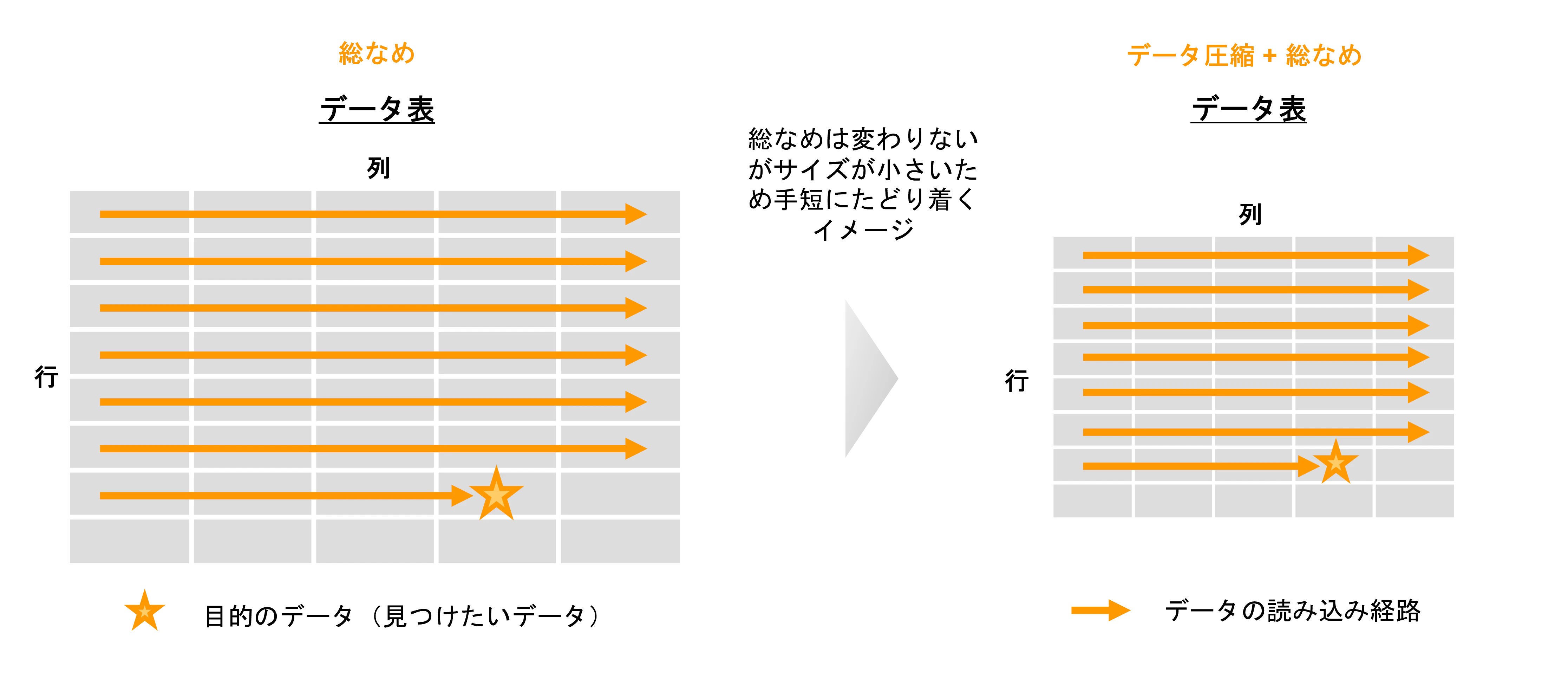
7. データ圧縮
アプローチAの他の手法のような近道系の手法ではないですが、格納するデータを圧縮してデータサイズ自体を小さくすることで、目的のデータを見つけ出すまでの読み込み量を減らす手法です。言い方を少し変えると、単位時間当たりに読み込めるレコード数を増やすとも言えます。データ圧縮に伴い、最終的なデータの読み書き時に 圧縮処理 ⇔ 復元処理のオーバーヘッドが発生しますが、通常はそれを上回る効果があります。
注意点
以上、アプローチA に関する手法でした。ここまで書いてきておいてなんですが、必ずしも総なめが悪いわけではありません。むしろ、対象レコードが少ないケースや、後半のアプローチB で紹介する手法を用いて ザザーっと総なめした方が高速化されるケースもあります。あくまで、総なめするよりかは近道した方が効率いい場合に アプローチA の手法が活きてきます。
B. 単位時間あたりに読めるデータ量を増やすアプローチ
では続いて、アプローチB: 単位時間あたりに読めるデータ量(byte)を増やす手法を見ていきます。
8. ディスクストレージ高速化
まずは単純にディスクストレージの性能が上がれば、単位時間当たりにデータアクセスできる量が増え、それだけ倍速で目的のデータにたどり着けます。コスト面で折り合いがついてこの手法(より高性能なストレージの導入)を採用できるならば、変に複雑なチューニング手法を組み入れなくともシンプルに高速化が期待できます。データベース製品によっては、データベースミドルウェア + 専用ディスクストレージ をアプライアンス製品という形でセットで提供するものもあります。
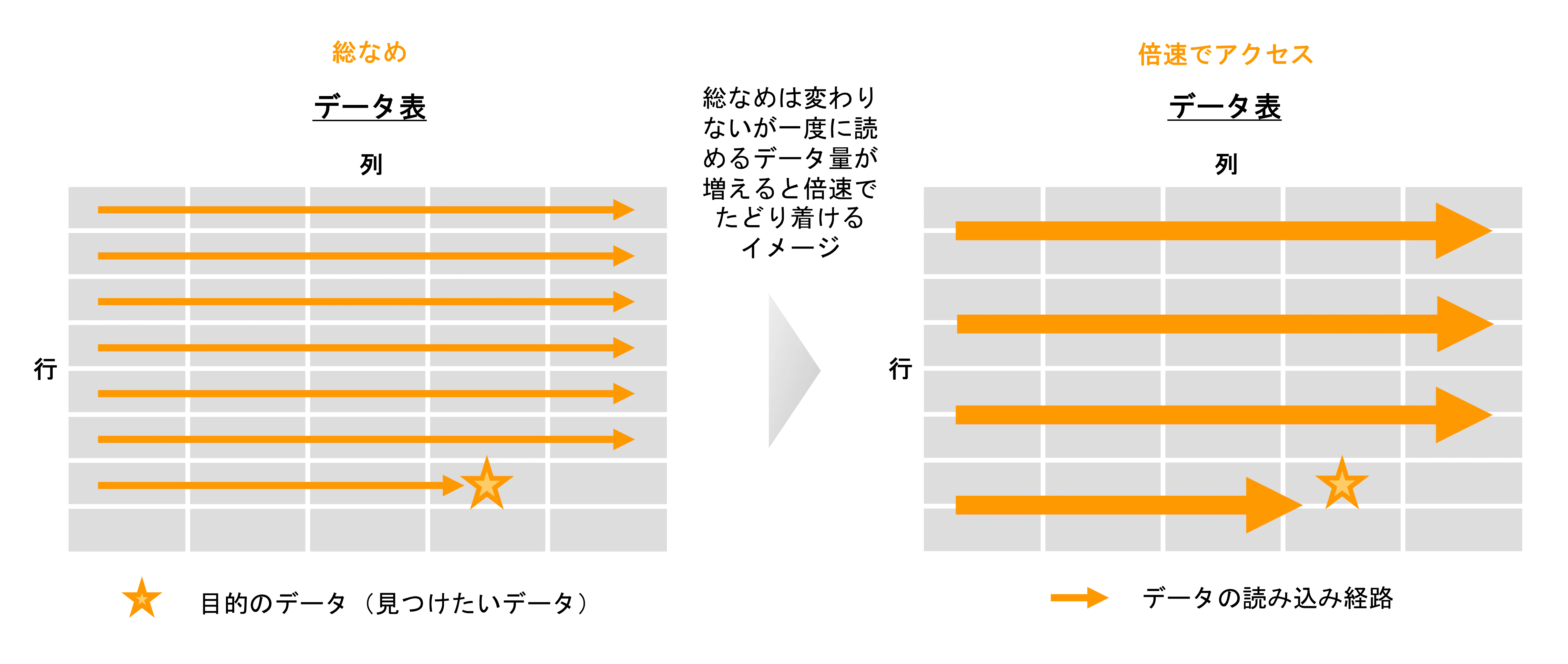
9. インメモリ化
次のインメモリ化も、先ほどのディスクストレージ高速化と同様のアプローチです。メモリ領域にデータを置くことで更に倍速で目的のデータにたどり着けます。ただ一般的に、メモリ領域はディスク領域に比べて高速にアクセスできる一方でサイズが限られています。全データをメモリ領域にのせるというよりかは、主に キャッシュデータ や セッションデータなどの配置に利用されるケースが多いと思います。
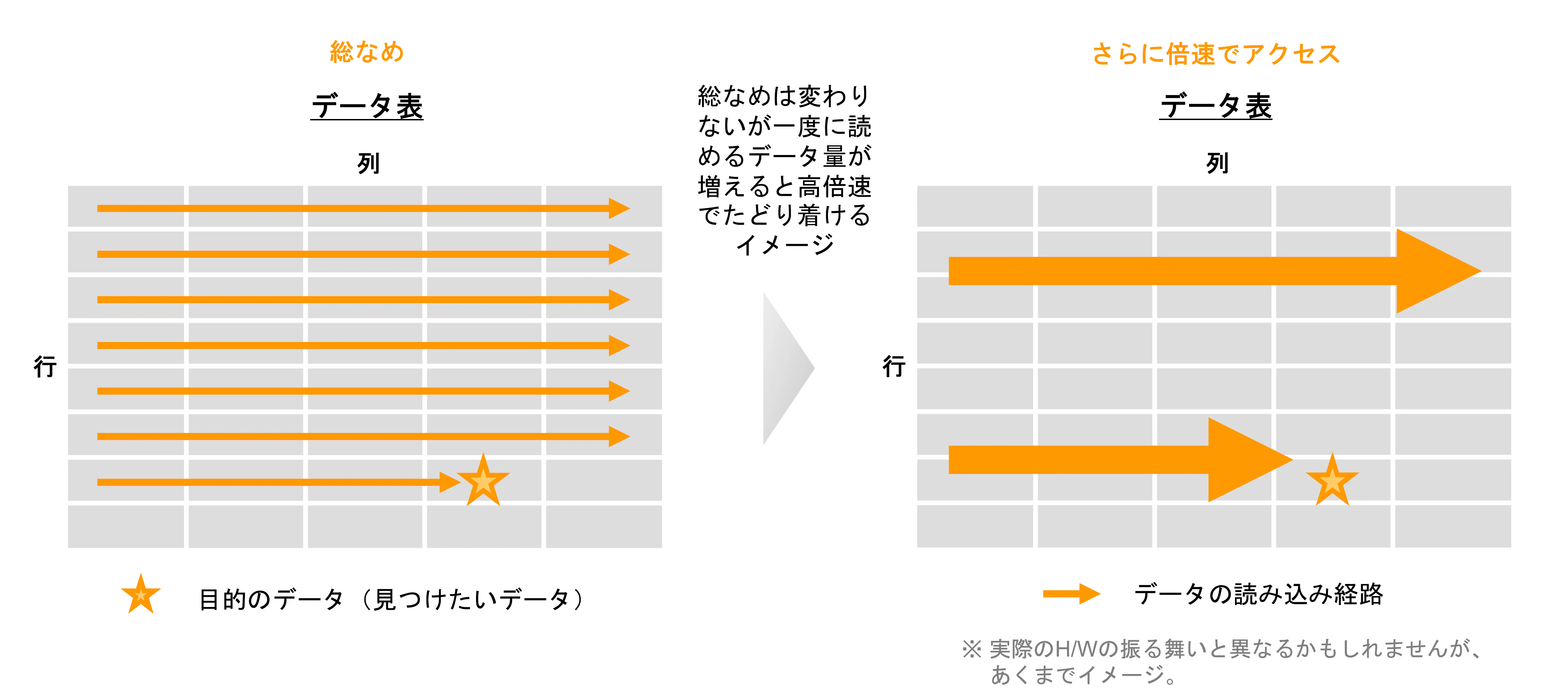
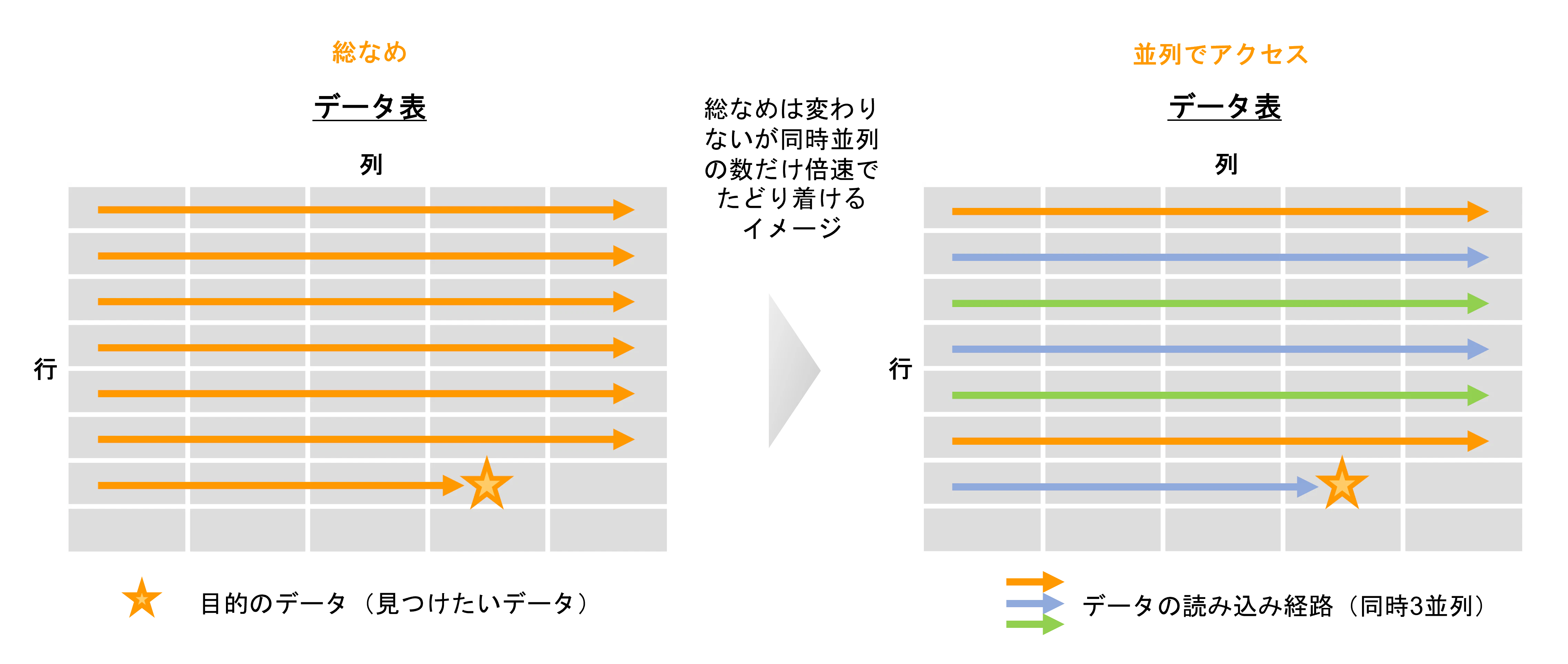
10. 並列処理 / MPP (Massively Parallel Processing)
前述のようなハードウェアの特性を活かす以外にも、プログラミング的に出来る事もあります。同時に複数のプロセスやスレッドを使ってデータにアクセスすることで、マシーンリソースが許す限りは同時並列の数だけ倍速でデータを読み込むことができます。こういった並列アクセス手法はデータベース製品自体に備わっている場合もありますし、他にもアプリケーション側から重複なく検索範囲を区切ったクエリを複数同時(下の図は3並列のイメージ)に発行することで実現することも可能です。
また、次節のクラスタリングと説明が重なるところはありますが、この並列アクセスを大規模に行う手法 MPP (Massively Parallel Processing) というワードもデータベース製品のガイドでよく登場します。
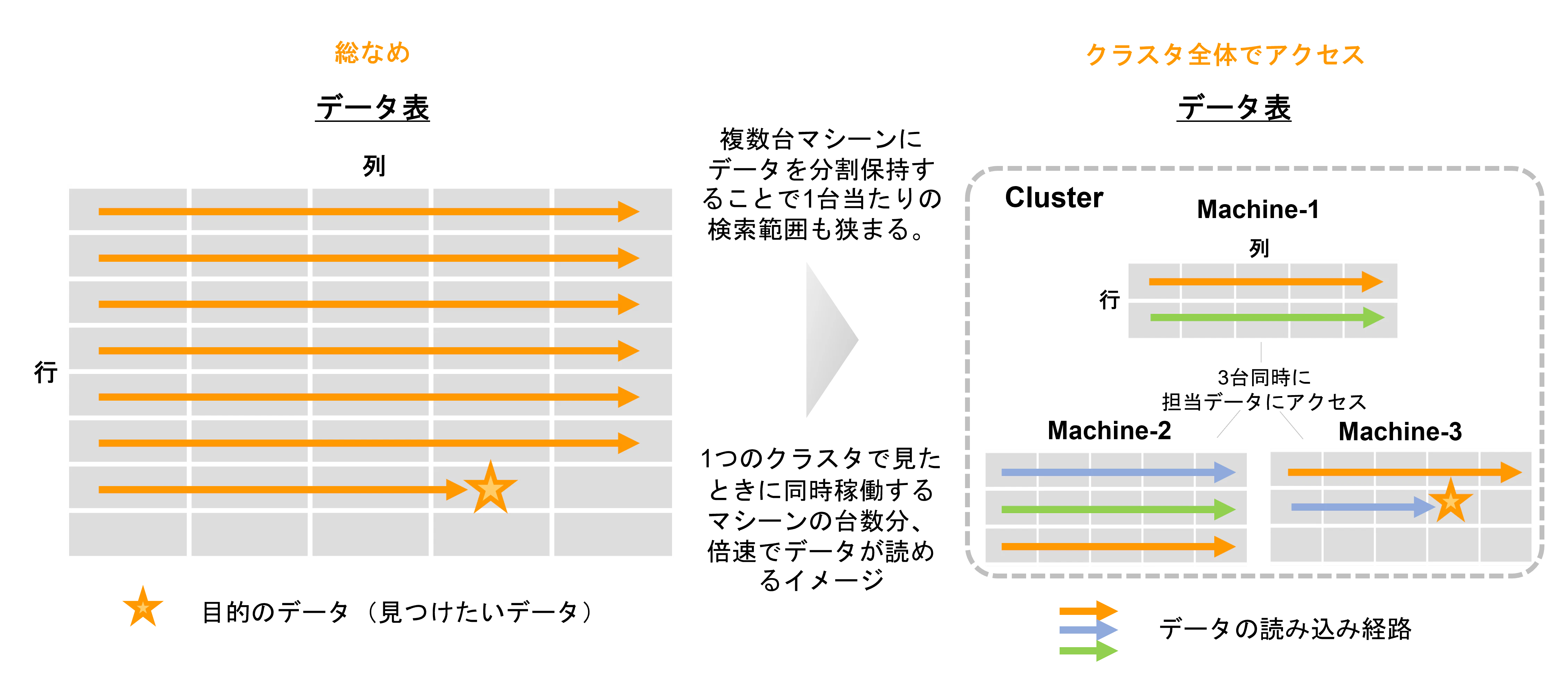
11. クラスタリング
Hadoop の登場以降、もはや一般的になってきた手法。1台のマシーンだけでは保持できないような非常に大きなデータを分割して複数のマシーンに分散配置し、それらのマシーンが協調動作することで、クラスタと呼ばれるあたかも1つの大きなデータベースとして振る舞います。これにより、クラスタ内の各1台のマシーンにおいては検索範囲を小さくすることができ、かつクラスタ内の複数台のマシーンが束となって同時に検索を走らせることで、マシーンの台数分 倍速でデータにアクセスできます。複数台のマシーンを活用して大規模に 「パーティショニング + 並列処理」 をかけるようなイメージになります。
まとめ
当記事では、各データベース製品が提供している検索を高速化するための手法について、自分自身が知っている範囲でご紹介してきました。検索を高速化するためのアプローチとしては、よりピンポイントに効率的にアクセスする近道系のアプローチと、マシーンリソースを最大限活用する力技系のアプローチとに分けて紹介してきました。挿絵のイメージ図はあくまで概念的な振る舞いとして作成しましたが、参考になったら幸いです。