俺です。
Couchbase Advent Calendar 2015の12/21エントリです
自分の知見を元にAWS上でCouchbase Serverを稼働させるための設計&実装メモです。
バッドノウハウだと気づいたところや、アプリケーションの実装までは踏み込めてませんが、
今後修正/追加していければと思います。
対象Edition/Version
※2015/12時点
- Couchbase Server Community Edition 3.0.1
この記事ではCommunity Editionが対象です。Enterprise Editionで同様の実装もできますが、
Enterprise Editionの機能で解決できる課題がいくつかあります。
全体図
ざっくりとこんな感じ
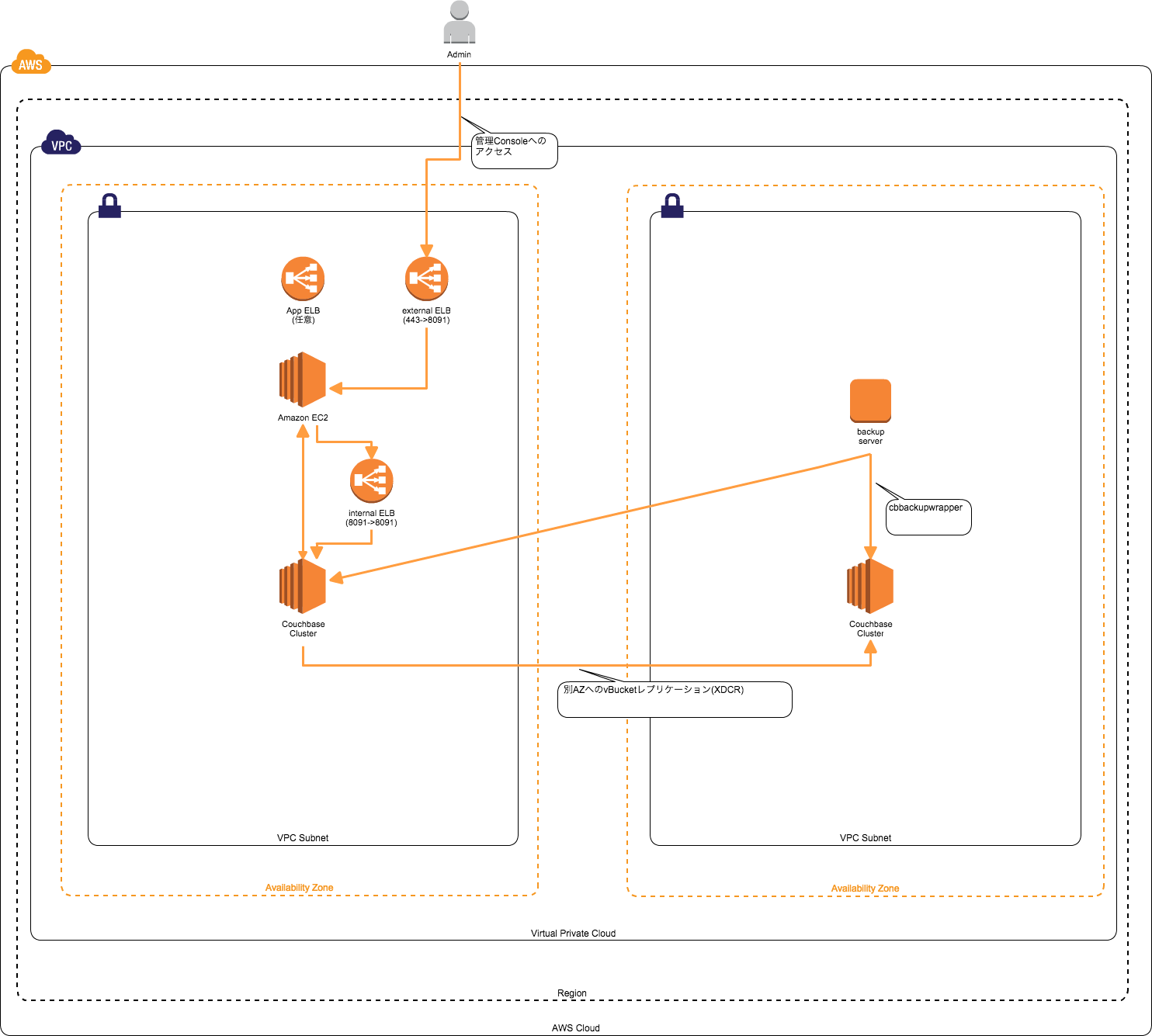
各コンポーネントについて
AWS
VPC
Subnet
- EC2はMulti-AZ配備しない。
- bucket(データストア)へのレプリケーション(書き込み)が水平分散されるため, AZ間のレイテンシー(2msec)がボトルネックになる。
- ※Enterprise EditionならRack Awareness でロケーション毎に負荷分散可能(´;ω;`)
- バッドノウハウ臭がしてるので、要ベンチマーク
- 2 Subnet用意しておく
| サブネット | 用途 |
|---|---|
| Primary Subnet | アプリケーション・サーバーが参照するCouchbase用EC2を配備するサブネット |
| Backup Subnet | バックアップサーバ or XDCR用EC2を配備するサブネット |
Network ACL & Security Group
- Inbound
内部ツーツー状態にするか、アプリケーション・サーバーからアクセスできるように、以下ポートを空けとけばよいです
| 用途 | ポート番号 | 備考 |
|---|---|---|
| REST API port | 8091 | |
| bucket listen port | 1121X | Couchbase BucketのListen port |
- Outbound
特に制限なければ内部ツーツーにしておく
内部DNS(Option)
- 必須ではないが推奨
- Couchbaseはサーバ固有の情報を自ノードのIPアドレスをキーに持ちます。
- サーバを使いまわしたい時は内部DNSでアクセスするように
ELB
2つ準備する。
クライアントからCouchbaseへの接続は、クラスタ内いずれかのノードの8091ポートへ接続した後、
全Couchbaseノードの1121Xポートへ、リダイレクト接続されるので、internal ELBが活かせる
| 種類 | 用途 |
|---|---|
| external ELB | Couchbase Server ConsoleへアクセスするためのELB.ELBでSSL terminateできるので最高 |
| internal ELB | アプリケーション・サーバーがCouchbase Serverへアクセスするためのエンドポイント. |
EC2
インスタンスタイプ
- スペック
Couchbaseの推奨リソースは結構ヘビーです。
| 種類 | 推奨値 |
|---|---|
| CPU | 4core(XDCRを使う場合は6core) |
| RAM | 16GB |
| Storage | SSD, EBS, iSCSI storage.NFSとCIFSは非推奨 |
EC2 Instance Typeは以下のシリーズが合致します
- m4.xlarge以上のm4シリーズ
- r3.xlarge以上のr3シリーズ
※Couchbaseはスケールアウト戦略を取るべきソフトウェアです。
1 node内のbucketデータ件数を抑えるため、m4 or r3.4xlarge/8xlargeを並べるよりも、
m4 or r3.2x以下のインスタンスを分散配備したほうが、負荷分散, リバランスやWarmupを高速化できます。
起動オプション
- EBS Optimizedをtrue
Couchbaseは非同期でRAMの情報をDiskへ書き込みます。
WriteHeavyなのでEC2とEBSの帯域とスループットを最適化するEBS Optimizedはtrueにしておきます。
c4/m4系はデフォルトtrueですが、r3系を選択する場合は忘れずに..
EBS
-
最低1本以上
-
Write Heavyなので本番環境でOSとCouchbaseを同じEBSに同居させるのはやめておいたほうがよいです
-
CouchbaseのViewとIndex機能を使う場合はData用EBSとIndex用EBSはわけておいたほうが良いです。
- デフォルトでは
/opt/couchbase/var/lib/couchbase/dataに保存されます - データストアパスの変更はドキュメント参照
- デフォルトでは
-
IOPS確保のため、gp2を選択します。
- IOPSがいくつあればよいかは負荷試験次第かと..
-
異常停止したEC2インスタンスはFull Recovery(後述)で再構成するのであれば、インスタンスストアを選択するのもありだと思います
OS
AWSの場合Amazon Linuxを使います.
メリット
- SR-IOVが標準サポートされているインスタンスタイプで起動すると自動的にSR-IOVが有効化される
CentOSがええんやという方はCentOSを選定すると良いと思います。
Launch後のセットアップ
以下実装例
| 種類 | 値 |
|---|---|
| OS | Amazon Linux 2015.03 |
事前準備
Couchbase Serverの異常停止を防ぐために最低限やっとくこと
スワップ利用を無効化
OOM Killer食らって即死しないように1でも良いと思うな。
$ sudo echo 0 > /proc/sys/vm/swappiness
$ sudo echo "vm.swappiness = 0" >> /etc/sysctl.conf
Transparent huge pageの無効化
touch /var/lock/subsys/local
# transparent huge pages never
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
ネットワーク処理の最適化(RPS/RFS/XPS)
@saitaraさんのLinuxでのネットワーク処理負荷を適正化する(RPS/RFS/XPS)
インストール
どちらかの手順で導入。
自分はrpmをダウンロードしてインストールしました。
- rpmのダウンロードページへ移動
- Community Edition 3.0.1を選択してダウンロード
$ sudo yum localinstall -y <rpm package>
※自動的に起動される
$ sudo service couchbase-server on
自動起動On
$ sudo chkconfig on couchbase-server
リブート
$ sudo shutdown -r -y now
参考:ソースコードからのmake
試せてない。
Enterprise Editionの機能を使える(はず)なので、ビルドして利用するのがよさそう。
ノード操作
過去に書いたブログ参照
サイジング
- サイジングガイドライン 読む
- アプリケーションのデータをロードして負荷をかける
-
YCSBのベンチマーク値を参考にする
- なんと最近のYCSBはCouchbase driverを取り込んでくれてます
- cbworkloadgenで負荷をかける
Couchbase Serverの機能とか
ドキュメントが超わかりやすいのでドキュメント参照が一番。。
データストレージ
Couchbaseはbucketというデータストアを提供している。
バケットの種類はCouchbsaeとmemcachedの二種類がある。
詳しくはドキュメントのデータストレージ参照desu
| バケット | 用途 |
|---|---|
| Couchbase | memcached 100%互換のストレージ.永続化とレプリケーションをサポートします |
| memcached | memcachedです |
RAM Quota
メモリ割り当てクオータ
この2種類で制御可能。
EC2インスタンスタイプを変更したらServer/BucketQuotaを変更すること
- Server Quota
- Couchbaseが1サーバで利用できるメモリ量
- EC2の搭載メモリ量の60% - 65%ぐらいが目安かな
- Server QuotaはNode単位ではなくCluster単位の設定になる
- Bucket Quota
- Bucketが利用できる最大メモリ量
あくまでもbucketにたいするクオータなので、大きく設定しすぎないことに注意。
bucketのRAM以外に、Erlang VM等のメモリ領域が必要になります。
Replica
バケットのコピー数。0から3まで設定可能。
ノードが異常停止した場合は明示的にFailoverするか、
Auto Failoverを発動させることでReplicaがActiveになり、
Couchbaseの処理を継続できます。
※Failoverさせないとbucketへの書き込みができないままになります。
レプリカを設定すると、その分Operationが増えます。少ない台数でレプリカ数を増やすのは得策ではありません。
最適なレプリカ数は負荷試験やベンチマーク等で選定するとよいです。
| レプリカ数 | 停止許容台数 | 負荷(Couchbase Serverへのオペレーション数) |
|---|---|---|
| 0 | フェイルオーバーできないためクラスタが機能しなくなる | ops*1 |
| 1 | 1台フェイルオーバーまで許容する | ops*2 |
| 2 | 2台フェイルオーバーまで許容する | ops*3 |
| 3 | 3台フェイルオーバーまで許容する | ops*4 |
Rebalance
- 動的にCouchbase Cluster内のサーバを追加/削除する機能
- バケットデータの再分散が行われる
- リバランス中は負荷高め
- オフピーク or メンテ入れして実行すること
- リバランスは中断可能(間違ってリバランス走らせても安心..?)
Delta RecoveryとFull Recovery
リバランスには二つの機能があります。
Delta Recovery
- 差分リバランスです
- 異常停止/RemoveしたEC2をリバランスしてCouchbase Clusterへ復帰させる場合、停止時点のバケットデータを元にリバランスします
- リバランス時間はFull Recoveryより高速です
Full Recovery
- 完全リバランスです
- 異常停止/RemoveしたEC2をリバランスしてCouchbase Clusterへ復帰させる場合、全てのデータ同期行います
- 新規サーバ追加時のリバランスもFull Recovery扱いになる(はず)
Remove
- 安全なスケールインを提供する機能
- Remove後にリバランスを実行すると、Clusterからサーバが削除される
FailoverとAutoFailover
- Couchbaseノードをクラスタから切り離す機能。
- 切り離したクラスタに存在していたbucketデータは参照できなくなるが、代わりにReplicaがActiveになる。
- Failover後はすみやかにインスタンスを復旧 or 追加してリバランスしましょう。
Failoverの利用タイミング
- Status Check 1/2
- Status Check 0/2
- インスタンスパフォーマンス(NW, EBS等)異常時の切り離し
Auto Failover
- デフォルトOff
- 1台停止した場合、停止したCouchbaseノードをクラスタから切り離す機能。デフォルトでは停止後120secでフェイルオーバーする。
- 最小30secに設定可能。
- Auto Failoverは2台目の停止時には発動しないので、2台以上の同時/連続障害を考慮する場合は、俺俺フェイルオーバーの実装が必要です
- EC2とEBSのSLAは99.95%です。たまーに落ちるので、Onにしておいたほうがよいです
Compaction
バケットへのデータ更新が発生すると、ディスクへ非同期書き込みされますが、削除や更新は論理的な扱いです。
物理的に削除(空き領域を開放)するにはCompactionが必要です。
Auto-Compaction
- デフォルトはデータベース/View断片化の割合が30%を超えたら実行されます
- Compaction実行中はWrite Opsが上昇するので、オフピーク時に実行するのがよいです。
- Compaction自体は途中キャンセルできます
起動時のWarmup
Couchbase ServerにはWarmup機能があります。
Couchbase Serverプロセス起動時に、bucketのキーに対するアクセスログをチェックし、Key/Valueをロードします。
Warmup中はアクセスできません。
Warmup完了の時間は1nodeあたりに格納されるデータ件数、サイズに応じます。
- プロセス起動
- Warmup
- アクセス受け付け
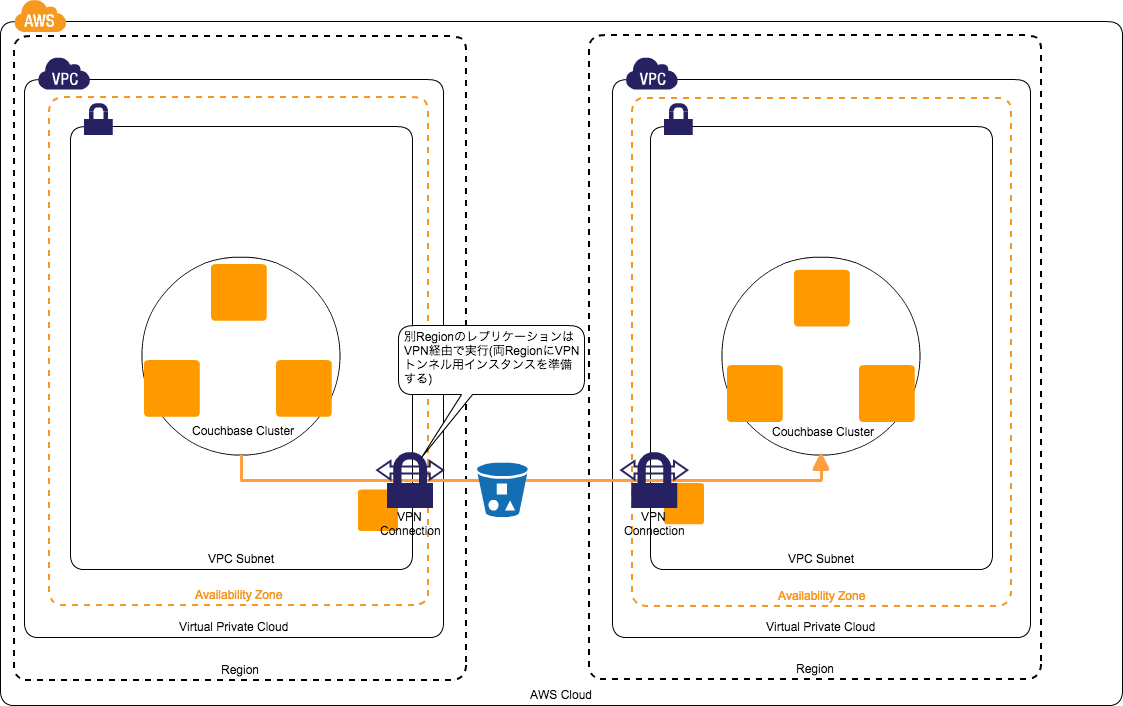
XDCR
クロスデータセンタレプリケーション(XDCR)
Community Editionの場合、XDCRは暗号化できないので
リージョン間通信はVPNインスタンスを立ててVPN経由でレプリケーションさせるか、Stunnelでトンネル作ってレプリケーションすること
バックアップとリストア
Couchbase Serverのバックアップは一貫性がありません。
リストアポイントは、バックアップ開始から完了時点までのポイントとなります。
cbbackup/cbrestoreユーティリティ
- bucketのバックアップを取得するユーティリティです。
- 3.0.1はcbbackupユーティリティにバグがあり、backupサーバがCPU使用率100%に陥る地獄があるのでcbbackupwrapperを使うとよいです
XDCR + cbbackup
検証レベルですが、
Couchbase-> Couchbase Backup ServerへXDCRを実行しておき、
定期的に切り離してcbbackupwrapperを実行するパターン。
モニタリング
ログ
ログのフォーマットはErlang形式です。あららーん
自動的にログローテーションが行われる。
| 種類 | 値 |
|---|---|
| ディレクトリ | /opt/couchbase/var/lib/couchbase/logs |
| 標準出力ログ | info.log |
| デバッグ | debug.log |
| メトリクス | stats.log |
| consoleアクセスログ | http_access.log |
メトリクスモニタリング
監視ツール
Couchbase Serverコンソールから閲覧可能。ただしメトリクスデータの保存はできません。
- min
- hour
- day
- month
恒久的に保存/分析に利用したい時はcbstatsを使えばよいです。
@Ijokarumawakさんのブログに書かれているのを使えば良いかなと思います。
自分はdatadogを使用しています。
Sensu
bucket-quotaのプラグインがある。
上記以外の情報をチェックしたい, graphiteにメトリクスとして飛ばしたい場合は自作しないとダメ
datadog
標準Integrationでdatadog agentがサポートしている。おすすめ
チェックしておくとよいメトリクス
全体
- CPU Utilization
- RAM Free
- swap
- diskspace usage
- network in/out
- EBS Queue Length
Couchbaseのメトリクス
※ Active bucketとReplica bucketそれぞれ別の統計値として提供されてます(vb_active_meta_data_memory, vb_replica_meta_data_memory等)
以下Couchbase Consoleに従ってざっくり見てるところを記載
Summary
Active docs resident%は下がる傾向にある
Cache miss raitoが右肩上がりになってないかチェック
- ops per second
- get|sets|delete per sec
- 毎秒発生するオペレーションの割合
- Active docs resident%
- インメモリなドキュメントの割合
- cache miss raito
- キャッシュミスの割合
VBUCKET RESOURCES
- Resident%(vb_active(replica)_resident_items_raito)
- Active(Replica)bucketのデータがキャッシュされている割合
- Activeのみ100%であればスケールアウトしない、とかするとか
- failover時も考慮してreplicaのResidentも100%じゃないと許容しないとか
- memory used, high water mark
- High walter markに達するとアクセス頻度の低いデータがキャッシュアウトされる
- user data/meta data in ram
- userデータとメタデータの割合, メタデータの割合が高い場合はスケールアウトを行うこと
DISK QUEUES
itemsが右肩上がりになってないかチェック(書き込み詰まり発生してないか)
- items
- fill rate
- drain rate
DCP QUEUES
- items remaining
- items drain rate/items/sec
俺俺運用メモ
EC2 Status Check 0/2のダメージを軽減する方法
- 1台までならAuto Failover OnにしておけばOK
- ダウンタイムは30sec
- Failover発生後はRebalanceして復旧すること
- 2台同時落ちはAutofailoverが発動せず泣くしかないので、オペレーションを自動化するには
couchbase-cli failoverを使って切り捨てるためのディスカバリスクリプトを書く
EC2 System Maintenanceを回避する方法
スワップリバランスでEC2を入れ替えちゃう。
- 新規EC2をAddする
- メンテナンス対象のEC2をRemoveする
- リバランスして交換する
リバランス時の負荷(poem)
体感ベースでアレですが、、、
- アプリケーションのレスポンスがなくなる/非常に遅くなる
- 気軽にできるようなものではない。メンテ入れ or オフピークが吉
EBSパフォーマンス障害時の対応(poem)
幸い(?)経験していない。想定作業のメモ。
- EBSパフォーマンス障害が発生すると、QueueLengthが上昇する
- CouchbaseのDiskメトリクスfill rate, drain rateが上昇する
- Removeしてリバランスをすると、転送対象のデータが転送できず、リバランスがハングアップするリスクが考えられるので、フェイルオーバーで切り離してしまうほうがよさそう