はじめに
運用保守で必要だと思われるコマンドをまとめてみました。
この記事は、個人的な記事なため、参考程度にしていただけたら幸いです。
運用作業はコマンドの動作を理解してから、コマンドを実行することを強くお勧めします
例ですがgzipコマンドは圧縮元のファイルを削除されるため、仮にシスログを圧縮しようとして
gzipコマンドを使用したところ、シスログが自体が消えてしまうことがあります。注意してください。
運用作業する際に私が心がけてる事は、障害対応で一人でサーバーに入って調査する場合、最初にサーバーのipアドレスを確認した後に、コマンド実行前に2回確認して実行しています。操作を疑いながらコマンドを実行し、記憶に頼らない様にしています。
また、慣れないコマンドを実行する際は、検証環境で一度コマンドを実行して確認する様にしてます。
障害対応でログの確認のため、root権限が必要な場合、コマンド実行時のみroot権限を使用するsudoコマンドを使用しています。
一般ユーザーで確認できるログは、一般ユーザーを使用した方が安全です。
rootユーザーに昇格するのは、必要最小限にすることが良いと思います。
TeraTermなどのターミナルの操作ログは、何かあった時のため出力する様にしています。
以下の参考にしました。
LPIC小豆本201「Linux教科書 LPICレベル2 Version4.5対応」を参考にしました。
また、以下で学びました。
infracollege
https://infracollege.vamdemicsystem.black/linux/
rootユーザーに切り替える場合
/etc配下などのログは、rootの権限が必要になります。
※rootはサーバーを再起動出来てしまうため、操作する際は注意が必要です。
サーバーの障害対応でログのみを確認したい場合は、
コマンド実行時のみに、root権限を使用するsudoコマンドがお勧めです。
以下のサイトが参考になりました。
https://wa3.i-3-i.info/word11269.html
$ sudo <コマンド>
実行例
$ sudo tail -n 5 /var/log/messages
運用作業する場合は、rootユーザーに昇格します。
$ sudo su -
以下は出力例です。
$ whoami ※今のユーザーを確認
test
$ sudo su - ※rootに昇格
[sudo] password for test: ※rootのパスワード入力
Last login: Wed Aug 17 20:51:17 JST 2022 on pts/0
#
# whoami ※今のユーザーを確認
root
プロンプト表示
作業する際に、事故を防ぐためにプロンプトを見る様にした方が良いです。
※作業手順書に、コマンドの先頭にプロンプト#又は$を記載したら、
作業する方が一般ユーザー又はroot権限でコマンドを実行するのか判断できるため、記載した方が良いです。
以下の表示であればrootユーザー
#
以下の表示であれば一般ユーザー
$
サーバーログイン時に使用するコマンド
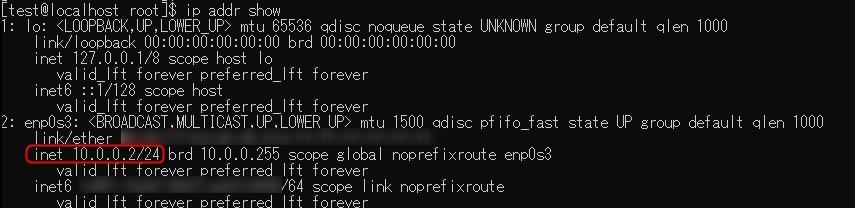
ip addr showコマンド
ログインしたサーバーが合っているかIPアドレスを確認します。
以下のサイトが参考になりました。
https://atmarkit.itmedia.co.jp/ait/articles/1709/22/news019.html
ip aは以下のQiitaの記事が参考になりました。
https://qiita.com/jinnai73/items/26865da11f667f57c5e4
$ ip addr show
以下のコマンドは「ip addr show」と同じコマンドです
$ ip a
uname -n コマンド
ホスト名を確認するコマンド
ログイン時にホスト名が正しいか確認する。
以下のQiitaの記事が参考になりました。有難うございます。
https://qiita.com/masato930/items/f50ad3df302290d1f544
$ uname -n
localhost.localdomain
whoamiコマンド
ユーザー名を確認するコマンドです。
$ whoami
以下は出力例です
[test@localhost ~]$ whoami
test
[test@localhost ~]$
良く使われるログの確認用のコマンド
※/etc/と/var/log配下はroot権限が必要なため、コマンドのプロンプトを#で記載してます。
lessコマンド
「less」コマンドが良く使われるため、一番操作に慣れた方が良いコマンドです。
一画面づつ表示されます。編集できないコマンドのため、安全です。
以下のサイトが勉強になりました。
https://www.wakuwakubank.com/posts/343-linux-less/
# less <ログファイル>
catコマンド
catコマンドは全行表示されるコマンドです。
以下の場合は、ログファイルの全行をパイプで渡して、grepで文字列を検索しています。
障害発生時に、ログからerror分のみ抽出する以下のコマンドも良く使われます。
覚えていた方が良いです。
grep iオプションは、大文字と小文字を区別せずに検索するオプションです。
$ sudo cat <ログファイル> | grep -i "<検索する文字列>"
以下は出力例です。
$ sudo cat /var/log/messages | grep -i "error"
Aug 6 10:20:29 localhost kernel: BERT: Boot Error Record Table support is disabled. Enable it by using bert_enable as kernel parameter.
Aug 6 10:20:30 localhost kernel: [drm:vmw_host_log [vmwgfx]] *ERROR* Failed to send host log message.
Aug 6 10:20:30 localhost kernel: [drm:vmw_host_log [vmwgfx]] *ERROR* Failed to send host log message.
ログファイルの全行を表示するのに、catコマンドは使われます。
view コマンド
「view」コマンドはviの読み取り専用モード一で一画面づつ表示するコマンドです。
編集できてしまうため、ログ確認に使うのはお勧めできません。
# view <ログファイル>
※catとviewを間違えて使った経験があります。catはログを全行表示するコマンドです。
viewは、一画面に収まる行のみ表示されるコマンドのため、間違わない様に注意が必要です。
tail -n コマンド
行末から指定した行までログを表示するコマンドです。
※最新のログが行末に出力されるため、業務でログを確認する際にもよく使用されます。
以下のサイトを参考にしました。
https://wa3.i-3-i.info/1minute/word11187.html
$ sudo tail -n <行を指定> ログファイル名
以下は、行末から5行目まで表示されてます。
※補足ですが、ミスが許されないサーバーであれば、rootに昇格せずに、ログの確認のみの作業は、
以下の様に、sudoコマンドを使用して確認します。
$ sudo tail -n 5 /var/log/messages
Aug 17 20:31:07 localhost NetworkManager[636]: <warn> [1660735867.5452] dhcp6 (enp0s3): request timed out
Aug 17 20:31:07 localhost NetworkManager[636]: <info> [1660735867.5453] dhcp6 (enp0s3): state changed unknown -> timeout
Aug 17 20:31:07 localhost NetworkManager[636]: <info> [1660735867.5482] dhcp6 (enp0s3): canceled DHCP transaction, DHCP client pid 1291
Aug 17 20:31:07 localhost NetworkManager[636]: <info> [1660735867.5482] dhcp6 (enp0s3): state changed timeout -> done
Aug 17 20:31:35 localhost su: (to root) test on pts/0
head -n コマンド
行頭から指定した行までログを表示するコマンドです。
以下のサイトを参考にしました。
https://webkaru.net/linux/head-command/
$ sudo head -n <行を指定> ログファイル名
以下は、行頭から5行目まで表示されてます。
$ sudo head -n 5 /var/log/messages
Aug 14 10:48:01 localhost rsyslogd: [origin software="rsyslogd" swVersion="8.24.0-55.el7" x-pid="992" x-info="http://www.rsyslog.com"] rsyslogd was HUPed
Aug 14 11:01:01 localhost systemd: Started Session 4 of user root.
Aug 14 11:08:01 localhost systemd: Removed slice User Slice of root.
Aug 14 11:10:09 localhost su: (to root) test on pts/0
Aug 14 12:01:01 localhost systemd: Created slice User Slice of root.
ログ管理
ログ(/var/log/messages)
/var/log/messagesは、OSのログで「シスログ」と呼ばれます。
現場でよく使う言葉のため、覚えていた方が良いです。
障害発生時にOSで何が起きたか確認する時に、このログを確認します。
※障害が発生した際は一番最初に確認することが多いです。
以下のログは、OSの再起動が発生した際のログです。
※grep -iは大文字小文字を区別しません。
$ sudo cat /var/log/messages | grep -i "Kernel"
May 30 07:30:36 localhost kernel: Kernel command line: BOOT_IMAGE=/vmlinuz-3.10.0-1160.el7.x86_64 root=/dev/mapper/centos-root ro crashkernel=auto spectre_v2=retpoline rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet LANG=ja_JP.UTF-8
May 30 07:30:36 localhost systemd[1]: Listening on udev Kernel Socket.
May 30 07:30:36 localhost systemd[1]: Starting Apply Kernel Variables...
May 30 07:30:36 localhost systemd[1]: Started Apply Kernel Variables.
May 30 07:30:36 localhost systemd: Starting udev Kernel Device Manager...
May 30 07:30:36 localhost systemd: Started udev Kernel Device Manager.
May 30 07:30:38 localhost systemd: Stopping udev Kernel Device Manager... ※カーネルの停止
May 30 07:30:38 localhost systemd: Stopped Apply Kernel Variables.
May 30 07:30:38 localhost systemd: Stopped udev Kernel Device Manager.
May 30 07:30:38 localhost systemd: Closed udev Kernel Socket.
May 30 07:30:38 localhost systemd: Started Remount Root and Kernel File Systems.
May 30 07:30:38 localhost systemd: Starting udev Kernel Device Manager...※カーネルの起動
May 30 07:30:38 localhost systemd: Started udev Kernel Device Manager.
ログ(/var/log/boot.log)
OS起動時のログです。
個人的には、あまり閲覧したことがなく、ログ発生した際の日時が表示されないため、分かりにくいです。
以下のログを理解するにはある程度、スキルが必要だと思いました。
# less /var/log/boot.log
[ESC[32m OK ESC[0m] Started Show Plymouth Boot Screen.
[ESC[32m OK ESC[0m] Reached target Paths.
[ESC[32m OK ESC[0m] Started Forward Password Requests to Plymouth Directory Watch.
[ESC[32m OK ESC[0m] Reached target Basic System.
ESC%G[ESC[32m OK ESC[0m] Found device /dev/mapper/centos-root.
Starting File System Check on /dev/mapper/centos-root...
[ESC[32m OK ESC[0m] Started File System Check on /dev/mapper/centos-root.
[ESC[32m OK ESC[0m] Started dracut initqueue hook.
[ESC[32m OK ESC[0m] Reached target Remote File Systems (Pre).
[ESC[32m OK ESC[0m] Reached target Remote File Systems.
Mounting /sysroot...
ログ(/var/log/cron)
cronが実行されたときに出力されるログです。
cronについては、以下の記事にまとめてます。良かったら参考にしてください。
※cronの起動時刻に、サーバーの停止を伴う作業をしない様に注意した方が良いです。
https://qiita.com/gama1234/items/2df167899ebdd6c1c983
# less /var/log/cron
Aug 7 08:41:01 localhost run-parts(/etc/cron.daily)[1502]: starting man-db.cron
Aug 7 08:41:07 localhost run-parts(/etc/cron.daily)[11369]: finished man-db.cron
Aug 7 08:41:07 localhost anacron[1497]: Job `cron.daily' terminated
Aug 7 09:01:01 localhost anacron[1497]: Job `cron.weekly' started
Aug 7 09:01:01 localhost anacron[1497]: Job `cron.weekly' terminated
ログ(/var/log/secure)
ユーザー認証時に出力されるログです。
ホストOS「192.168.0.14」からゲストOSにsshした際のログです。
その後、rootに昇格しました。
# less /var/log/secure
#ssh接続のログ
Aug 14 10:35:05 localhost sshd[1353]: Accepted password for test from 192.168.0.14 port 53164 ssh2
Aug 14 10:35:05 localhost sshd[1353]: pam_unix(sshd:session): session opened for user test by (uid=0)
Aug 14 10:35:26 localhost sudo: test : TTY=pts/0 ; PWD=/home/test ; USER=root ; COMMAND=/bin/less /var/log/secure
#rootに昇格のログ
Aug 14 10:35:26 localhost sudo: pam_unix(sudo:session): session opened for user root by test(uid=0)
httpdのアクセスログ(/etc/httpd/logs/access_log)
webインターフェースにアクセスした場合は、このアクセスログに出力されます。
よくwebのアクセスログを確認する際に、以下のログを確認します。
※/etc配下のため、sudoコマンドを使用しています。
$ sudo less /etc/httpd/logs/access_log
出力例 10.0.0.1のサーバーからnagios「https://192.168.0.3/test1/」にアクセスしているログです。
10.0.0.1 - nagiosadmin [14/Aug/2022:12:21:46 +0900] "GET /nagios/side.php HTTP/1.0" 200 4735 "https://192.168.0.3/test1/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
以下は(/etc/httpd/logs/error_log)のhttpdエラーログです。
$ sudo less /etc/httpd/logs/error_log
出力例です。
[Sun Aug 21 11:28:48.080692 2022] [mpm_prefork:notice] [pid 866] AH00163: Apache/2.4.6 (CentOS) PHP/7.3.33 configured -- resuming normal operations
[Sun Aug 21 11:28:48.080794 2022] [core:notice] [pid 866] AH00094: Command line: '/usr/sbin/httpd -D FOREGROUND'
例 nagios
以下のサイトにアクセス
nagiosのWEBインターフェースにログインした際に、以下のログが出力されたことを確認した
[root@localhost tmp]# tail -n 30 /etc/httpd/logs/access_log | grep "16/Oct/2022"
127.0.0.1 - - [16/Oct/2022:07:59:02 +0900] "GET / HTTP/1.0" 200 71412 "-" "check_http/v2.3.3 (nagios-plugins 2.3.3)"
127.0.0.1 - - [16/Oct/2022:08:04:02 +0900] "GET / HTTP/1.0" 200 71412 "-" "check_http/v2.3.3 (nagios-plugins 2.3.3)"
127.0.0.1 - - [16/Oct/2022:08:09:02 +0900] "GET / HTTP/1.0" 200 71412 "-" "check_http/v2.3.3 (nagios-plugins 2.3.3)"
127.0.0.1 - - [16/Oct/2022:08:14:02 +0900] "GET / HTTP/1.0" 200 71412 "-" "check_http/v2.3.3 (nagios-plugins 2.3.3)"
127.0.0.1 - - [16/Oct/2022:08:19:02 +0900] "GET / HTTP/1.0" 200 71412 "-" "check_http/v2.3.3 (nagios-plugins 2.3.3)"
192.168.40.113 - - [16/Oct/2022:08:23:25 +0900] "GET /naigos HTTP/1.1" 404 204 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"
192.168.40.113 - - [16/Oct/2022:08:23:25 +0900] "GET /favicon.ico HTTP/1.1" 404 209 "http://192.168.40.116/naigos" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"
192.168.40.113 - - [16/Oct/2022:08:23:31 +0900] "GET /naigos/ HTTP/1.1" 404 205 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"
127.0.0.1 - - [16/Oct/2022:08:24:02 +0900] "GET / HTTP/1.0" 200 71412 "-" "check_http/v2.3.3 (nagios-plugins 2.3.3)"
192.168.40.113 - - [16/Oct/2022:08:24:06 +0900] "GET /naigos/ HTTP/1.1" 404 205 "-" "Mozilla/5.0 (Windows NT 10.0; Win64;
ユーザーのログインを確認するコマンド
wコマンド
現在ログインしているユーザーを確認する。
以下のサイトが参考になりました。
https://atmarkit.itmedia.co.jp/ait/articles/1807/26/news009.html
以下は出力例です。
$ w
11:00:46 up 1:25, 1 user, load average: 0.00, 0.01, 0.02
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
test pts/0 192.168.0.14 10:35 6.00s 0.01s 0.00s w
lastコマンド
過去にログインした履歴を確認する
以下のサイトが参考になりました。
https://atmarkit.itmedia.co.jp/ait/articles/1903/22/news031.html
以下は出力例です。
$ last
test pts/0 192.168.0.14 Sun Aug 14 10:35 still logged in
test pts/0 192.168.0.14 Sun Aug 14 09:36 - 10:34 (00:58)
reboot system boot 3.10.0-1160.el7. Sun Aug 14 09:35 - 10:54 (01:18)
root pts/0 192.168.0.14 Tue Aug 9 20:55 - crash (4+12:39)
reboot system boot 3.10.0-1160.el7. Tue Aug 9 20:55 - 10:54 (4+13:59)
root pts/2 10.0.0.1 Sun Aug 7 07:21 - 07:22 (00:00)
root pts/1 10.0.0.1 Sun Aug 7 07:19 - 07:40 (00:21)
test pts/0 192.168.0.14 Sun Aug 7 07:02 - 10:05 (03:02)
lastlogコマンド
ユーザーの最終ログイン情報です。
過去にユーザーがログインしたことがあるかどうかを確認出来るコマンドです。
以下のサイトを参考にしました。
https://atmarkit.itmedia.co.jp/ait/articles/1903/29/news046.html
$ lastlog
Username Port From Latest
root pts/0 Sun Aug 14 09:36:19 +0900 2022
bin **Never logged in**
daemon **Never logged in**
adm **Never logged in**
lp **Never logged in**
sync **Never logged in**
shutdown **Never logged in**
halt **Never logged in**
mail **Never logged in**
operator **Never logged in**
games **Never logged in**
ftp **Never logged in**
nobody **Never logged in**
systemd-network **Never logged in**
dbus **Never logged in**
polkitd **Never logged in**
sshd **Never logged in**
postfix **Never logged in**
chrony **Never logged in**
test pts/0 192.168.0.14 Sun Aug 14 10:35:05 +0900 2022
nginx **Never logged in**
apache **Never logged in**
障害発生時に確認するコマンド
uptimeコマンド
CPUのロードアベレージの確認とOSが前回何時間前に停止したか確認できる。
私はよくサーバーが直近で再起動したか確認する際に、uptimeコマンドを使用します。
以下のサイトが参考になりました。
https://wa3.i-3-i.info/word11667.html
以下の例では、1時間36分間システムが稼働しています。
$ uptime
11:12:21 up 1:36, 1 user, load average: 0.00, 0.01, 0.02
11:12:21は現在の時刻 システムの稼働時間(1時間36分) user接続中のユーザー ロードアベレージ
以下のサイトが参考になりました。
https://wa3.i-3-i.info/word11667.html
ロードアベレージについて
実行待ちのプロセス数(1分/5分/15分)
上記の数値がCPUコア数とCPU数を超えて入れば何らかの処理待ちが発生している
2コアのCPUが2個ある場合は、ロードアベレージが4を超えたら、何らかの待ちが発生している
上記からCPUの負荷状態が分かります。
以下のサイトでCPUのコア数の確認方法が参考にしました。
https://access.redhat.com/ja/solutions/2159401
以下はCPUコア数等を確認した際の実行例です。
#論理プロセッサの数(有効なプロセッサーの数)
$ cat /proc/cpuinfo | grep processor
processor : 0
#物理CPU数
$ cat /proc/cpuinfo | grep physical.id
physical id : 0
#CPUコア数
$ cat /proc/cpuinfo | grep "core"
core id : 0
cpu cores : 1
TOPコマンド
プロセスの状態とCPUとメモリの負荷状態を確認出来るコマンドです。
よく業務で使用されるため、覚えていた方が良いです。
1.システム稼働時間
現在の時間/稼働時間(以下のエビデンスでは、2分稼働)/ログイン中のユーザー数
※稼働時間を確認したら、OSが前回何時間前又は日数前に再起動したか確認できる。
2.負荷状態
実行待ちのプロセス数(1分/5分/15分)
上記の数値がCPUコア数とCPU数を超えて入れば何らかの処理待ちが発生している
2コアのCPUが2個ある場合は、ロードアベレージが4を超えたら、何らかの待ちが発生している
3.スワップとは、メモリがいっぱいになった際に使用されます。
TOPコマンドの実行例です。
説明を追記しました。※説明書きに記載間違いがあったら申し訳ありません。
topコマンドは、以下のサイトが参考になりました。
https://atmarkit.itmedia.co.jp/ait/articles/1706/30/news018.html
$ top
※システム稼働時間、負荷状態
top - 08:46:10(現在の時刻) up 35 min(システム稼働時間), 2 users(ユーザー数), load average: 0.00(1分負荷), 0.01(5分負荷), 0.01(15分負荷)
※プロセスの状態
Tasks: 104 total(総合プロセス数), 2 running(プロセス実行数), 102 sleeping, 0 stopped, 0 zombie
※CPU状態
%Cpu(s): 0.0 us(ユーザープロセス割合), 0.0 sy(カーネル割合), 0.0 ni(優先度変更したプロセス割合),100.0 id(アイドル割合), 0.0 wa(ディス久IO割合), 0.0 hi(ハードウェア割り込み割合), 0.0 si(ソフトウェア割り込み割合), 0.0 st(ゲストOS未割当割合)
※メモリの状態
KiB Mem : 1014756 total(全部物理メモリ容量), 712528 free(空きメモリ容量), 175808 used(使用中メモリ容量), 126420 buff/cache(バッファとキャッシュサイズ)
KiB Swap: 839676 total(総合スワップ容量), 839676 free(空きスワップ容量), 0 used(使用中のスワップ容量). 700784 avail Mem(メモリ不足時に利用できるメモリ量)
※プロセスの状態
PID USER PR NI VIRT(仮想メモリ使用量) RES(実メモリ使用量) SHR S %CPU %MEM TIME+ COMMAND
1430 root 20 0 162084 2224 1560 R(実行可能状態) 0.3 0.2 0:00.28 top
1 root 20 0 125352 3880 2584 S(実行待ち状態) 0.0 0.4 0:00.65 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
5 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kworker/u2:0
6 root 20 0 0 0 0 S 0.0 0.0 0:00.06 ksoftirqd/0
7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
TOPコマンドの動作確認のため、負荷を与えるコマンドは以下です。
yesをひたすら出力するコマンドです。
$ yes >> /dev/null
TOPコマンドを確認したところ、yesプロセスがCPU使用率が99%になっています。
$ top
top - 12:07:01 up 2:31, 2 users, load average: 1.82, 0.57, 0.22
Tasks: 111 total, 2 running, 109 sleeping, 0 stopped, 0 zombie
%Cpu(s): 95.7 us, 4.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1014756 total, 771064 free, 162808 used, 80884 buff/cache
KiB Swap: 839676 total, 839676 free, 0 used. 736536 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1582 root 20 0 108056 616 520 R 99.0 0.1 1:27.24 yes
1511 root 20 0 0 0 0 D 0.3 0.0 0:00.21 kworker/0:1
1 root 20 0 125352 3896 2584 S 0.0 0.4 0:02.14 systemd
dfコマンド
ディスク使用率を確認できるコマンドです。
$ df -h
ファイルシス サイズ 使用 残り 使用% マウント位置
devtmpfs 484M 0 484M 0% /dev
tmpfs 496M 0 496M 0% /dev/shm
tmpfs 496M 6.8M 489M 2% /run
tmpfs 496M 0 496M 0% /sys/fs/cgroup
/dev/mapper/centos-root 6.2G 1.6G 4.7G 25% /
/dev/sda1 1014M 137M 877M 14% /boot
tmpfs 100M 0 100M 0% /run/user/1000
大きなファイルを作成してみて、サイズが変わることを確認しました。
以下のコマンドは1Gのファイルを作成します。
bs(ブロックサイズ)/if(入力ファイル /dev/zeroのため空)/of(出力ファイル)を指定する
$ dd if=/dev/zero of=1gfile bs=1M count=1024
$ ls -ltr /tmp/1gfile
-rw-r--r-- 1 root root 1073741824 8月 14 11:39 /tmp/1gfile
再度、df -hコマンドを実行した。
マウント位置「/」の使用が1.6Gから2.6Gに増えました
$ df -h
ファイルシス サイズ 使用 残り 使用% マウント位置
devtmpfs 484M 0 484M 0% /dev
tmpfs 496M 0 496M 0% /dev/shm
tmpfs 496M 6.8M 489M 2% /run
tmpfs 496M 0 496M 0% /sys/fs/cgroup
/dev/mapper/centos-root 6.2G 2.6G 3.7G 41% /
/dev/sda1 1014M 137M 877M 14% /boot
tmpfs 100M 0 100M 0% /run/user/1000
psコマンド
ps -efはすべてのプロセスを階層表示するコマンドです。
実行したコマンドもプロセスに表示されることを理解しておいてください。
以下のサイトが参考になりました。
https://atmarkit.itmedia.co.jp/ait/articles/1603/28/news022.html
以下のコマンドは、すべてのプロセスの状態をパイプで渡して、プロセス名またはスクリプト名で検索します。
使用例ですが、スクリプトの処理が途中で中断しないために、サービスを再起動する前に、
スクリプトが動いてないか確認するために以下のコマンドを使うことがあります。
$ ps -ef | grep <プロセス名 or スクリプト名>
以下はnginxのプロセスが実行中であることを確認しました。
$ ps -ef | grep nginx
root 1009 1 0 21:22 ? 00:00:00 nginx: master process /usr/sbin/nginx
nginx 1010 1009 0 21:22 ? 00:00:00 nginx: worker process
root 1266 1244 0 21:23 pts/0 00:00:00 grep --color=auto nginx
watchコマンド
以下のサイトが参考になりました。
https://atmarkit.itmedia.co.jp/ait/articles/1806/29/news037.html
以下のコマンドは、秒毎にwatchコマンドで、検索したプロセスが実行中であることを確認します。
grepコマンドのプロセスの表示は不要なため、grep -vで非表示にしています。
$ watch -n <秒> "ps -ef | grep <プロセス名 or スクリプト名> | grep -v grep"
以下のコマンドは、1秒ごとにnginxのプロセスが実行中であることを確認するコマンドです。
$ watch -n 1 "ps -ef | grep nginx | grep -v grep"
以下は実行結果です。

補足です。
以下は、1秒ごとにnagiosプロセスが実行中であることを確認するコマンドです。
watchコマンドは繰り返しコマンドを実行する際に便利です。
$ watch -n 1 "ps -ef | grep nagios | grep -v grep"
実行したpsコマンドのみ表示されたため、nagiosのプロセスは実行中ではありません。

nagiosプロセスが実行中の場合は、以下の様に表示されます。

サービスの状態の確認
サービスが起動しているか確認する
$ systemctl status <サービス名>
以下は出力例 Activeになっているため、httpdサービスは起動中です
[root@localhost ~]# systemctl status httpd
● httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2022-08-21 11:25:39 JST; 1min 12s ago
Docs: man:httpd(8)
man:apachectl(8)
Main PID: 984 (httpd)
Status: "Total requests: 0; Current requests/sec: 0; Current traffic: 0 B/sec"
CGroup: /system.slice/httpd.service
├─ 984 /usr/sbin/httpd -DFOREGROUND
├─1032 /usr/sbin/httpd -DFOREGROUND
├─1033 /usr/sbin/httpd -DFOREGROUND
├─1034 /usr/sbin/httpd -DFOREGROUND
├─1035 /usr/sbin/httpd -DFOREGROUND
└─1036 /usr/sbin/httpd -DFOREGROUND
Aug 21 11:25:38 localhost.localdomain systemd[1]: Starting The Apache HTTP Server...
Aug 21 11:25:39 localhost.localdomain systemd[1]: Started The Apache HTTP Server.
httpdサービスの自動起動設定の確認
httpdサービスが起動していない場合は、以下のコマンドを実行して
サービスが再起動した際に、httpdサービスが自動起動する設定になっているか確認する
以下のサイトが参考になりました。
https://www.server-memo.net/centos-settings/centos7/systemctl-enable.html
$ systemctl is-enabled httpd
enabled
httpdのバージョン確認
以下のサイトが参考になりました。読んでください
https://weblabo.oscasierra.net/apache-version/
$ httpd -v
Server version: Apache/2.4.6 (CentOS)
Server built: Mar 24 2022 14:57:57
phpのバージョン確認
以下のサイトが参考になりました。
https://www.php.net/manual/ja/features.commandline.options.php
$ php -v
PHP 7.3.33 (cli) (built: Nov 16 2021 11:18:28) ( NTS )
Copyright (c) 1997-2018 The PHP Group
Zend Engine v3.3.33, Copyright (c) 1998-2018 Zend Technologies
rpmコマンド パッケージの確認
パッケージが入っているか確認するコマンド
$ rpm -qa | grep <パッケージ名>
以下は出力例です。
$ rpm -qa | grep httpd
httpd-tools-2.4.6-97.el7.centos.5.x86_64
httpd-2.4.6-97.el7.centos.5.x86_64
yum list installedコマンド
インストール済みのパッケージを確認するためのコマンドです。
沢山出力されるため、lessに渡して一画面づつ表示しています。
以下のサイトが参考になりました。
https://www.webolve.com/server/check-packages-installed-with-yum/
$ yum list installed | less
※出力結果を一部記載
Repodata is over 2 weeks old. Install yum-cron? Or run: yum makecache fast
Installed Packages
GeoIP.x86_64 1.5.0-14.el7 @base
NetworkManager.x86_64 1:1.18.8-1.el7 @anaconda
NetworkManager-libnm.x86_64 1:1.18.8-1.el7 @anaconda
NetworkManager-team.x86_64 1:1.18.8-1.el7 @anaconda
NetworkManager-tui.x86_64 1:1.18.8-1.el7 @anaconda
NetworkManager-wifi.x86_64 1:1.18.8-1.el7 @anaconda
acl.x86_64 2.2.51-15.el7 @anaconda
aic94xx-firmware.noarch 30-6.el7 @anaconda
alsa-firmware.noarch 1.0.28-2.el7 @anaconda
alsa-lib.x86_64 1.1.8-1.el7 @anaconda
ssコマンド 開いているポートを確認する
以下のサイトが参考になりました。
https://atmarkit.itmedia.co.jp/ait/articles/1710/06/news014.html
以下のコマンドは、tcpソケットでポート番号を数字のまま表示しました。
$ ss -t -n
※出力結果 22ポートが開いています
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 192.168.0.3:22 192.168.0.14:50840
historyコマンド
コマンドの実行履歴です。
以下のサイトが参考になりました。
https://linuxfan.info/history
私は作業が完了したら、いつもコマンド履歴を確認してサーバーをログアウトしています。
$ history
※出力結果
1 sudo su -
2 ip a
3 exit
4 history
hisotoryのコマンド履歴が保存されるファイル
$ cat ~/.bash_history
※出力結果
sudo su -
ip a
exit
exitコマンド
サーバーのssh接続を切断(ログアウト)するコマンドです
以下のサイトが参考になりました。
https://eng-entrance.com/linux-command-exit
$ exit
logout
Connection to 192.168.0.3 closed.
test@DESKTOP-0S2U0NI:~$
rmコマンド
rmコマンドは削除するコマンドです。
誤って別のフォルダで作業することを防ぐために、絶対パス指定で、削除コマンドを実行する
ファイル数が多くなければ、
オプション i(削除する前に確認するオプション)をつけてコマンドを実行する
コマンドを実行する前に、フォルダ指定が誤ってないか確認してください 特に*を使用する場合は注意してください
以下のサイトが参考になりました。
https://atmarkit.itmedia.co.jp/ait/articles/1606/06/news013.html
●ファイルを削除する場合
※ログインしたユーザーと異なるユーザーのホームディレクトリを表示する場合は、sudoを付ける。
削除前
$ sudo ls -tlr /home/test/*
total 420
-rw-r--r-- 1 root root 312968 Aug 23 2019 net-tools-2.0-0.25.20131004git.el7.x86_64.rpm
-rw-r--r-- 1 root root 113274 Oct 2 08:39 details
-rw-r--r-- 1 root root 0 Oct 16 07:49 test
-rw-r--r-- 1 root root 0 Oct 16 07:49 test.tar.gz
-rw-r--r-- 1 root root 0 Oct 16 07:49 test1.tar.gz
-rw-r--r-- 1 root root 0 Oct 16 07:49 test2.tar.gz
[root@localhost test]#
※ /etc/配下又は別のユーザーの権限のファイル又はフォルダを削除する場合は、sudoを付ける
[root@localhost test]$ sudo rm -i /home/test/*.tar.gz
rm: remove regular empty file '/home/test/test.tar.gz'? y
rm: remove regular empty file '/home/test/test1.tar.gz'? y
rm: remove regular empty file '/home/test/test2.tar.gz'? y
削除後
$ ls -tlr /home/test/*
-rw-r--r-- 1 root root 312968 Aug 23 2019 /home/test/net-tools-2.0-0.25.20131004git.el7.x86_64.rpm
-rw-r--r-- 1 root root 113274 Oct 2 08:39 /home/test/details
-rw-r--r-- 1 root root 0 Oct 16 07:49 /home/test/test
[root@localhost test]#
●フォルダを削除する場合
削除前
$ sudo ls -ltr /home/test
total 420
-rw-r--r-- 1 root root 312968 Aug 23 2019 net-tools-2.0-0.25.20131004git.el7.x86_64.rpm
-rw-r--r-- 1 root root 113274 Oct 2 08:39 details
-rw-r--r-- 1 root root 0 Oct 16 07:49 test
drwxr-xr-x 2 root root 6 Oct 16 07:57 test2
※ /etc/ファイルの権限又は別のユーザーの権限のファイル又はフォルダを削除する場合は、sudoを付ける
$ sudo rm -r -i /home/test/test2
rm: remove directory '/home/test/test2'? y
削除後
$ sudo ls -ltr /home/test
total 420
-rw-r--r-- 1 root root 312968 Aug 23 2019 net-tools-2.0-0.25.20131004git.el7.x86_64.rpm
-rw-r--r-- 1 root root 113274 Oct 2 08:39 details
-rw-r--r-- 1 root root 0 Oct 16 07:49 test
mvコマンド
ファイル又はフォルダを移動させるコマンドです。
誤って別のフォルダで作業することを防ぐために、絶対パスで指定する。
念のため、上書き前に確認表示されるiオプションを付ける
rmと同様に誤操作すると影響が大きいため、コマンドを実行する際は注意してください
以下のコマンドの説明が参考になりました。
https://atmarkit.itmedia.co.jp/ait/articles/1606/13/news024.html
●ファイルとフォルダの移動
移動前
$ ls -ltr /home/test
total 420
-rw-r--r-- 1 root root 312968 Aug 23 2019 net-tools-2.0-0.25.20131004git.el7.x86_64.rpm
-rw-r--r-- 1 root root 113274 Oct 2 08:39 details
-rw-r--r-- 1 root root 0 Oct 16 07:49 test
※ファイルの移動
$ mv -i /tmp/*.tar.gz /home/test
※フォルダの移動
$ mv -i /tmp/test2 /home/test
移動後
$ ls -tlr /home/test
total 420
-rw-r--r-- 1 root root 312968 Aug 23 2019 net-tools-2.0-0.25.20131004git.el7.x86_64.rpm
-rw-r--r-- 1 root root 113274 Oct 2 08:39 details
-rw-r--r-- 1 root root 0 Oct 16 07:49 test
-rw-r--r-- 1 root root 0 Oct 16 08:05 test1.tar.gz
-rw-r--r-- 1 root root 0 Oct 16 08:05 test2.tar.gz
drwxr-xr-x 2 root root 6 Oct 16 08:05 test2
grepコマンド 一致した行の後の行を表示する
以下のサイトがとても参考になりました。
https://atmarkit.itmedia.co.jp/flinux/rensai/linuxtips/137greplineplus.html
grepコマンドで一致した行から後の行を表示
以下のコマンドは指定したキーワード(iオプション 大文字小文字区別しない)とnオプション(一致した行数を表示)
Aオプション(該当した行の後の何行表示するか指定する)
コマンド cat ログファイル | grep -A ●行 -n -i "キーワード"
testというキーワードが検索された行の後の5行を表示する
# cat /var/log/messages | grep -A 5 -n -i "test"
※testキーワードが含まれる行
124:Oct 23 23:28:51 localhost kernel: atomic64 test passed for x86-64 platform with CX8 and with SSE
125-Oct 23 23:28:51 localhost kernel: pinctrl core: initialized pinctrl subsystem
126-Oct 23 23:28:51 localhost kernel: RTC time: 14:28:50, date: 10/23/22
127-Oct 23 23:28:51 localhost kernel: NET: Registered protocol family 16
128-Oct 23 23:28:51 localhost kernel: cpuidle: using governor haltpoll
129-Oct 23 23:28:51 localhost kernel: ACPI: bus type PCI registered
grepコマンド 一致した行の前の行を表示する
grepコマンドで一致した行から、指定した前の行を表示
以下のコマンドは指定したキーワード(iオプション 大文字小文字区別しない)とnオプション(行数を表示)
Bオプション一致した行の前の何行表示するか指定する)
コマンド cat ログファイル | grep -B ●行 -n -i "キーワード"
testというキーワードが検索された行の前の5行を表示する
# cat /var/log/messages | grep -B 5 -n -i "test"
[root@localhost log]# cat /var/log/messages | grep -B 5 -n -i "test"
119-Oct 23 23:28:51 localhost kernel: devtmpfs: initialized
120-Oct 23 23:28:51 localhost kernel: x86/mm: Memory block size: 128MB
121-Oct 23 23:28:51 localhost kernel: EVM: security.selinux
122-Oct 23 23:28:51 localhost kernel: EVM: security.ima
123-Oct 23 23:28:51 localhost kernel: EVM: security.capability
※testキーワードが含まれる行
124:Oct 23 23:28:51 localhost kernel: atomic64 test passed for x86-64 platform with CX8 and with SSE
コマンド行と空白を非表示にする
先頭に#が入っている行と何も値がない行は非表示(grep -v)にするコマンドです。
以下のサイトを参考にさせていただきました。
https://ex1.m-yabe.com/archives/3689
# cat <ログ又は設定ファイル> | grep -v ^# | grep -v ^$
実行例
# cat nrpe.cfg | grep -v ^# | grep -v ^$
#と空白行は表示されていないため、設定ファイルが見やすくなります。
log_facility=daemon
debug=0
pid_file=/run/nrpe/nrpe.pid
server_port=5666
nrpe_user=nrpe
nrpe_group=nrpe
allowed_hosts=127.0.0.1,::1,192.168.40.61
dont_blame_nrpe=1
allow_bash_command_substitution=0
command_timeout=60
connection_timeout=300
disable_syslog=0
command[check_users]=/usr/lib64/nagios/plugins/check_users -w $ARG1$ -c $ARG2$
command[check_load]=/usr/lib64/nagios/plugins/check_load -w $ARG1$ -c $ARG2$
command[check_disk]=/usr/lib64/nagios/plugins/check_disk -w $ARG1$ -c $ARG2$ -p $ARG3$
command[check_procs]=/usr/lib64/nagios/plugins/check_procs -w $ARG1$ -c $ARG2$ -s $ARG3$
コマンド行と空白を非表示にする(別のコマンド)
.で空白行を非表示をパイプで渡して#が含まれていない設定ファイル情報を表示
grep '.' <ファイル名> | grep -v "#"
実行例
# grep '.' httpd.conf | grep -v "#"
出力結果を一部抜粋
コメントと空白行が表示されていないです。
ServerRoot "/etc/httpd"
Listen 80
Include conf.modules.d/*.conf
User apache
Group apache
ServerAdmin root@localhost
インストール可能なパッケージ名・バージョン・レポジトリを取得
以下のサイトを参考にしました。
https://orebibou.com/ja/home/201609/20160912_001/
yum --showduplicates list <パッケージ名>
nrpeはリポジトリepelからインストール出来ることが分かります。
実行例
[root@localhost ~]# yum --showduplicates list nrpe
Failed to set locale, defaulting to C
Loaded plugins: fastestmirror, product-id, search-disabled-repos, subscription-manager
This system is not registered with an entitlement server. You can use subscription-manager to register.
Loading mirror speeds from cached hostfile
* base: ftp.jaist.ac.jp
* epel: mirrors.tuna.tsinghua.edu.cn
* extras: ftp.jaist.ac.jp
* remi-safe: mirror.team-cymru.com
* updates: mirror.vodien.com
Available Packages
nrpe.x86_64 4.0.3-6.el7 epel
[root@localhost ~]#
アクセスログを取得する際の圧縮コマンド
ログファイルを取得する際にログのサイズが大きいと圧縮が必要になります。
gzipコマンドは圧縮する元のファイルが削除されます。
tarコマンドでアーカイブして圧縮した方が元ファイルが消えないため安全です
gzipコマンド
圧縮前のファイル
[root@localhost tmp]# ls -l file*
-rw-r--r--. 1 root root 0 5月 6 19:43 file1
圧縮後のファイル
[root@localhost tmp]# gzip file1
[root@localhost tmp]# ls -l file*
-rw-r--r--. 1 root root 26 5月 6 19:43 file1.gz ※元ファイルのfile1が消えた
tarコマンド
/tmp配下にてアクセスログの圧縮したアーカイブファイルを作成するコマンド
# cd /var/log
# tar cvzf /tmp/アクセスログファイル名.tar.gz ./アクセスログファイル
圧縮前
[root@localhost tmp]# ls -l file2*
-rw-r--r--. 1 root root 0 5月 6 19:43 file2
圧縮後
[root@localhost tmp]# tar cvzf file2.tar file2
[root@localhost tmp]# ls -ltr file2*
-rw-r--r--. 1 root root 0 5月 6 19:43 file2
-rw-r--r--. 1 root root 109 5月 6 19:52 file2.tar
[root@localhost tmp]#
ログ出力中のアクセスログをtarコマンド実行後に、
「file changed as we read it」というメッセージ出力されるのはアーカイブ中に対象ファイルが変わってしまった際に出力されます。
サーバーのログの場合はリアルタイムにログを出力されているため、上記のメッセージが出るという事をご認識ください。
まとめ
不足しているコマンドがあるかもしれませんが、この記事に一通り、必要なコマンドを記載しました。
経験が浅い場合は、障害が発生した際に確認するログと何のコマンドを使用したら良いかは
すぐに出てこないことがあるため、ログの在処とコマンド集を準備しておいた方が良いと個人的に思いました。
経験したアラートのナレッジを付ける事で、誰でも対応出来る様になると思いました。
未知なアラート対応は、スキルが必要なため、勉強が必要だと思いました。
この記事を参考にして頂けたら幸いです。