はじめに
Google CloudのVertex AIにあるAutoMLで売上予測(需給予測)を行ってみたので、実際の手順を画面キャプチャ載せながら使い方を解説するよ。AutoMLのチュートリアル的な記事が少なくて、1年前の記事だと画面が違っていたり、海外のブログを探さなきゃいけなかったりで大変だったので、興味ある人はこの記事を見ながらやってみてちょ。
Vertex AIとは
Google Cloudが提供するフルマネージドの機械学習(ML)プラットフォーム。MLモデルの構築、デプロイ、スケーリングを高速化できちゃうサービス。
今回の記事ではその中でもMLモデルを構築するAutoMLについて書くよ。AutoMLはデータセットだけ与えれば、良い感じのMLモデルが作成され、ある程度素人でもMLモデルが作れてしまい、需給予測なんかができてしまうよ(機械学習について、社内には詳しい人がいっぱいいるけど、筆者は専門外だったりする)。
費用について
Vertex AIのAutoMLを行うと数千円単位の費用がかかるよ。金額感としては、モデル作成が最低約3,000円、作ったモデルを使ってバッチ予測を行うと約1,000円かかるイメージ。
用意するデータセット
Google Cloud Marketplaceにある【Iowa Liquor Retail Sales】を利用するよ。
下記URLの【データセットを表示】のボタンを押すとBigQueryに飛ぶので、データが見えるよ。
https://console.cloud.google.com/marketplace/details/iowa-department-of-commerce/iowa-liquor-sales?project=pray-ground
BigQueryで、以下のSQLでデータを表示して、CSV出力ボタンで出力する。
SELECT store_number, city, county, sum(sale_dollars) as sum_sale_dollars, date_trunc(date, MONTH) as month
FROM `bigquery-public-data.iowa_liquor_sales.sales`
WHERE city is not null
AND county is not null
AND date_trunc(date, MONTH) >= parse_date('%Y%m%d', '20201001')
AND date < parse_date('%Y%m%d', '20221001')
AND county in ('ADAIR', 'ADAMS', 'ALLAMAKEE', 'APPANOOSE', 'AUDUBON', 'BENTON', 'BLACK HAWK' )
GROUP BY store_number, city, county, month
ORDER BY county, city, store_number, month
データセットの解説
元々のデータは、2012年1月1日以降にアイオワ州で小売業者が個人向けに販売した酒類の卸売購入履歴で、各店舗での日ごとの商品の売上が登録されているよ。これを、データ量を絞るために特定の群だけにして、月ごとに集計したデータセットに変更したよ。
店舗の売上は属する市や群のその他の店舗の売上との相関がある可能性が考えられたので、これらのカラムもデータセットに入れておくよ。
| カラム名 | 説明 |
|---|---|
| store_number | 店舗ID |
| city | 市 |
| county | 群 |
| sum_sale_dollars | 月の売上高の合計 |
| month | 年月 |
Vertex AIでAutoMLを行う手順の大まかな流れ
1. データセットをVertex AIに取り込む
2. モデルを作成する
3. 作ったモデルで予測を行う
1. データセットをVertex AIに取り込む
1. 左ペインにある【データセット】をクリックし、画面上部の【作成】をクリックする。
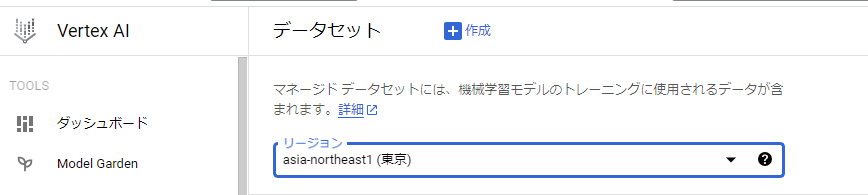
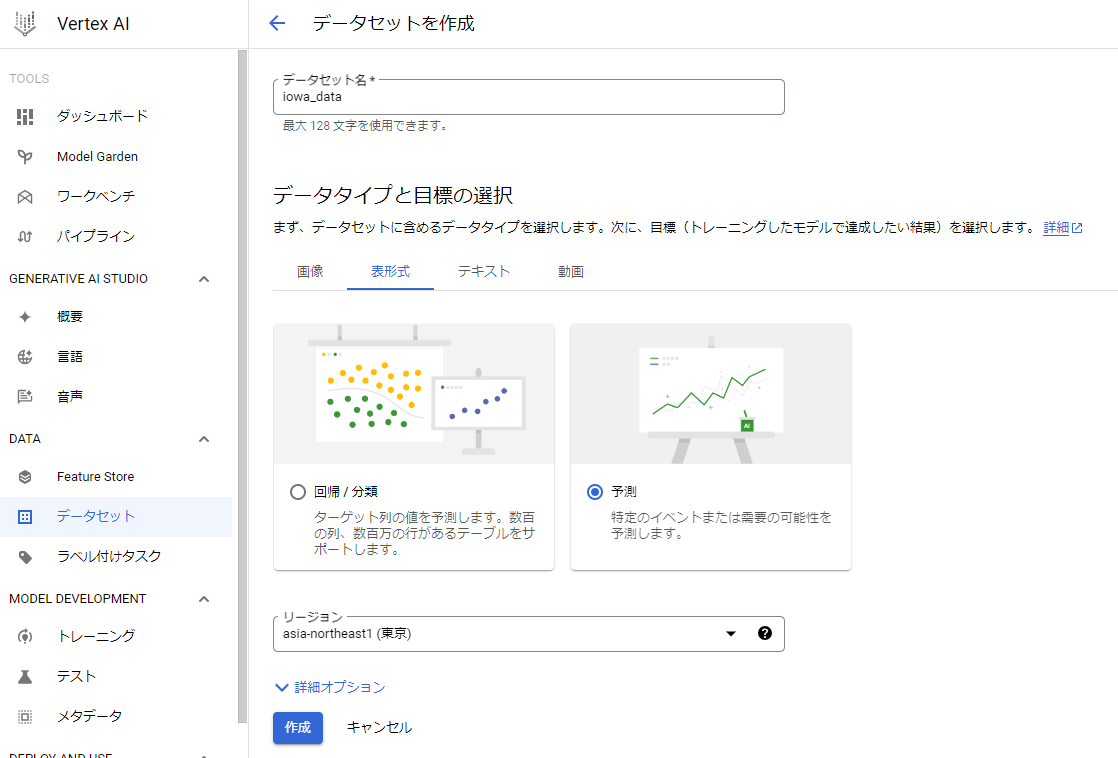
2. 【データセット名】には任意の名前を入力。【表形式】タブの【予測】を選択。リージョンは任意で、【作成】をクリックする。
3. 「用意するデータセット」でBigQueryから取得したCSVをGoogle Storageにアップロードして、そのファイルを選択して【続行】をクリックする。
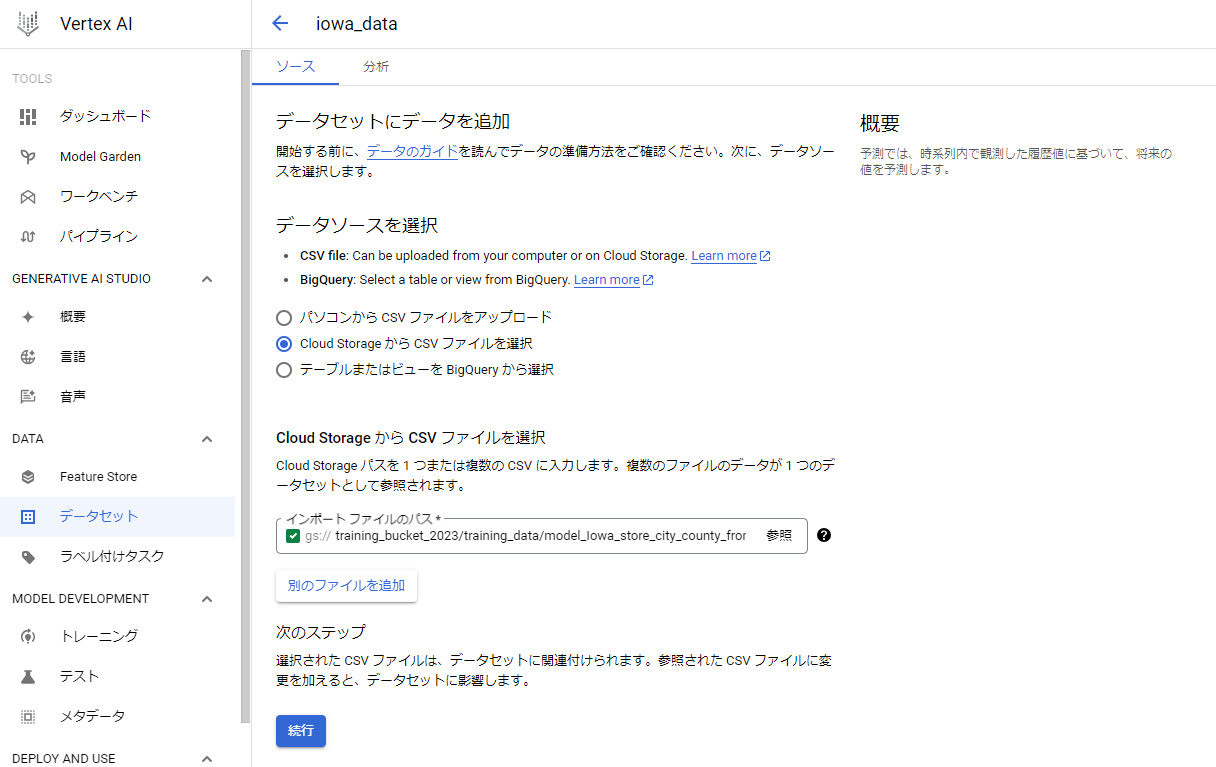
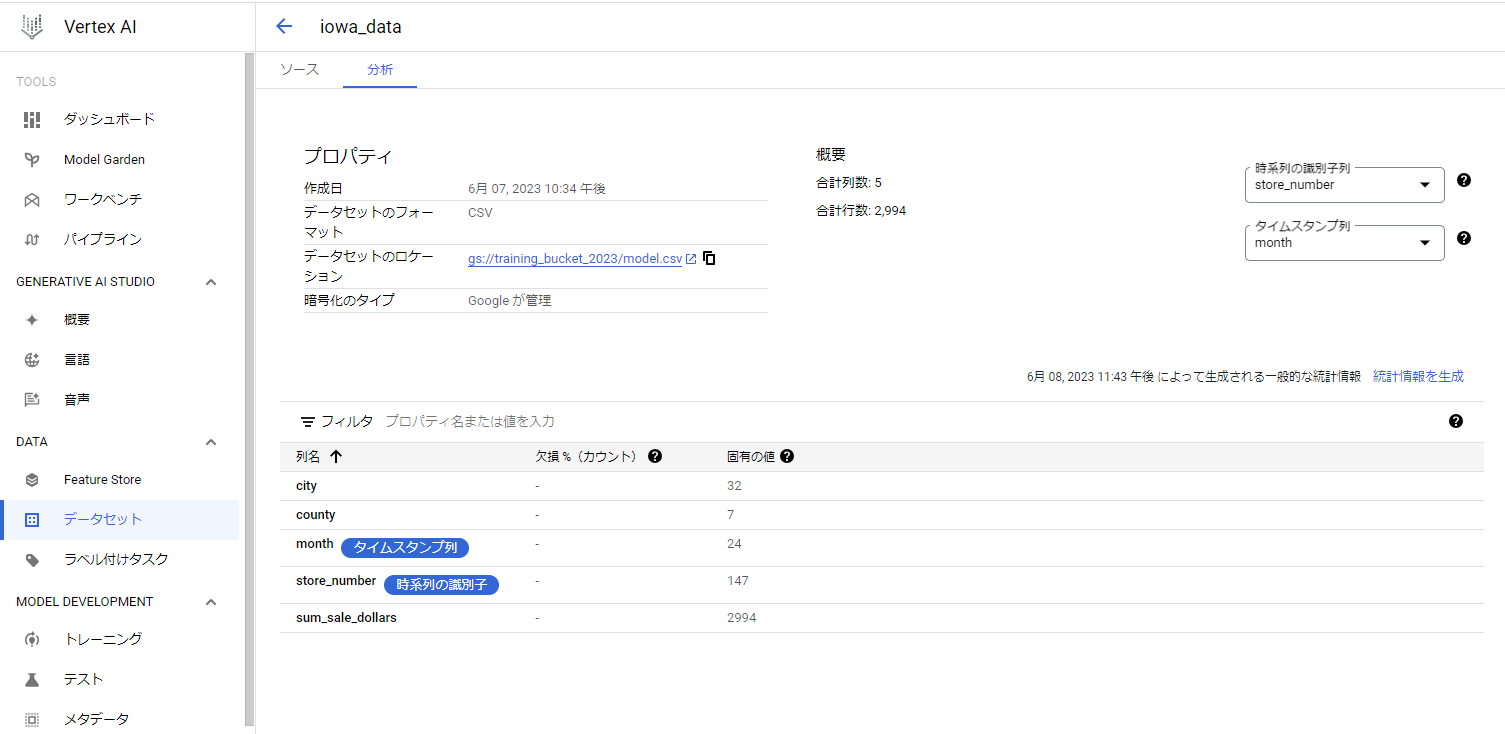
4. 下記の画面が表示される。
・【統計情報を生成】を押すと、下段のテーブルの欠損や固有の値がセットされる。ただし約15分かかる。
※欠損%(カウント)や固有の値が何を指しているかはカラム名の横にある「?」を見てみてね。
2. モデルを作成する
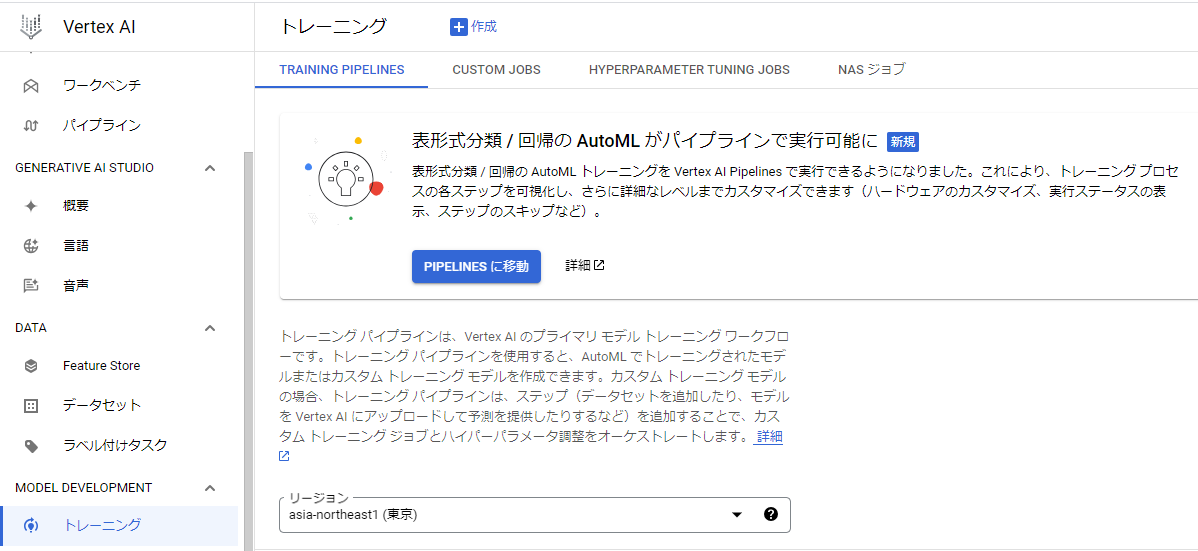
1. 左ペインの【トレーニング】をクリックし、表示された画面の上部の【作成】をクリックする。
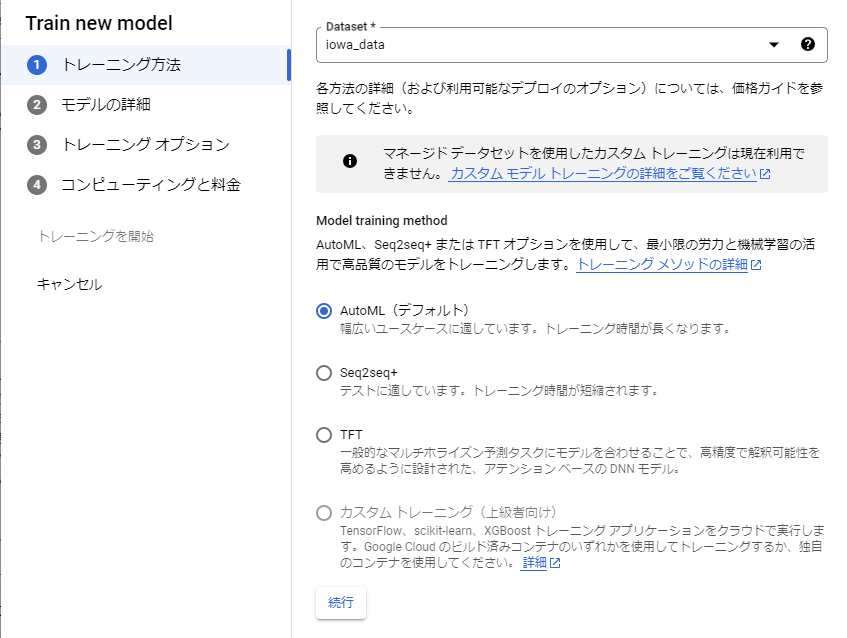
2. 【Dataset】は先ほど作成したデータセットを選択する。AutoML(デフォルト)を選択して【続行】をクリックする。
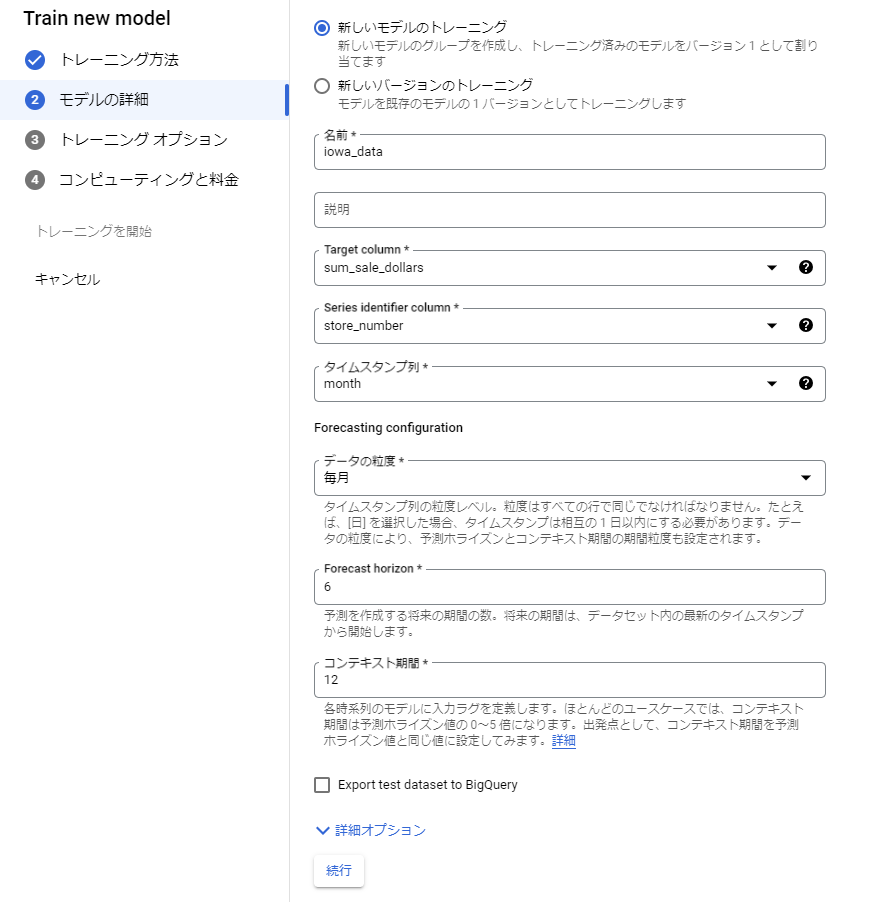
3. 以下のキャプチャのように各値をセットする。【Target colum】が今回の予測するターゲット。
※【コンテキスト期間】はもっと値を探る必要がありますが、今回はとりあえず、【Forcast horizon】の2倍で行ったよ。
4. 以下のキャプチャのように各値をセットする。
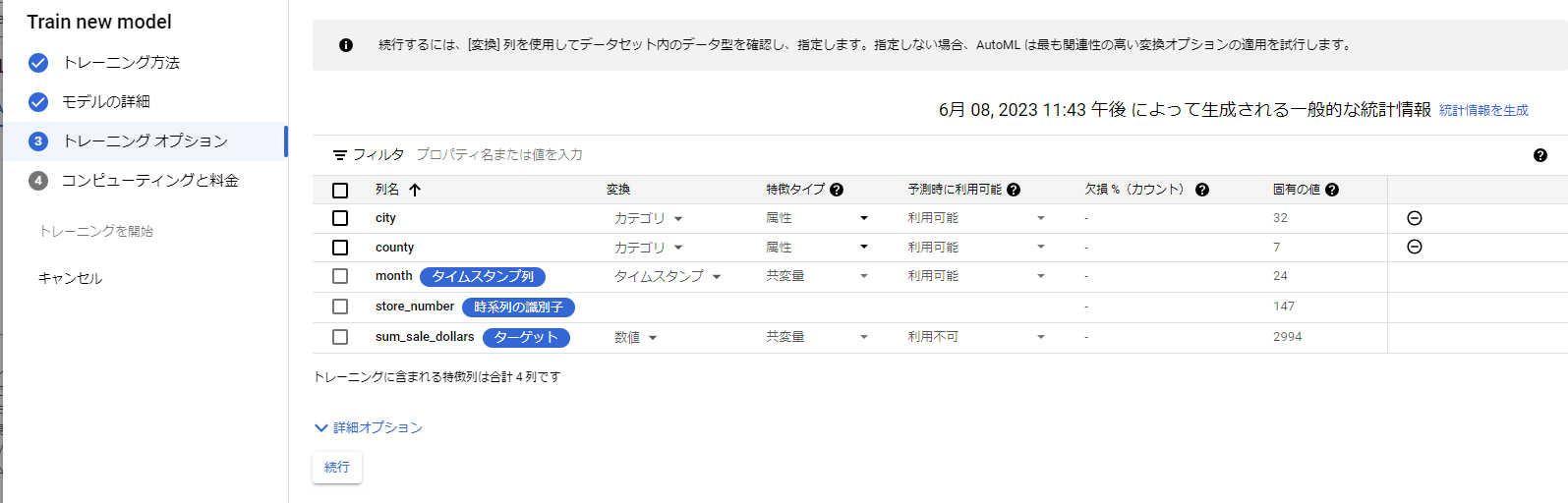
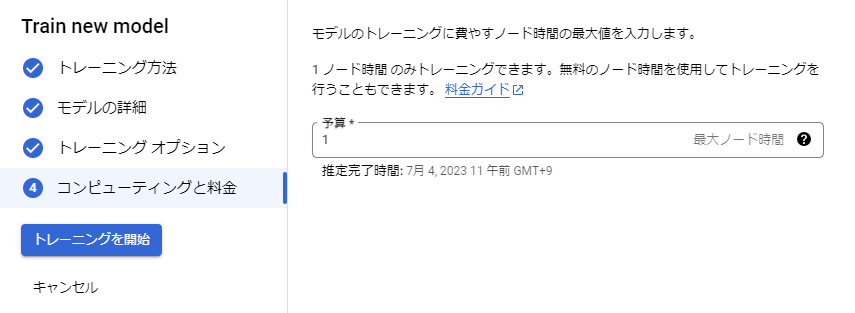
5. 【予算】は1をセットし、【トレーニングを開始】をクリックする。2時間半後くらいトレーニングが完了するのでそれまで休憩。
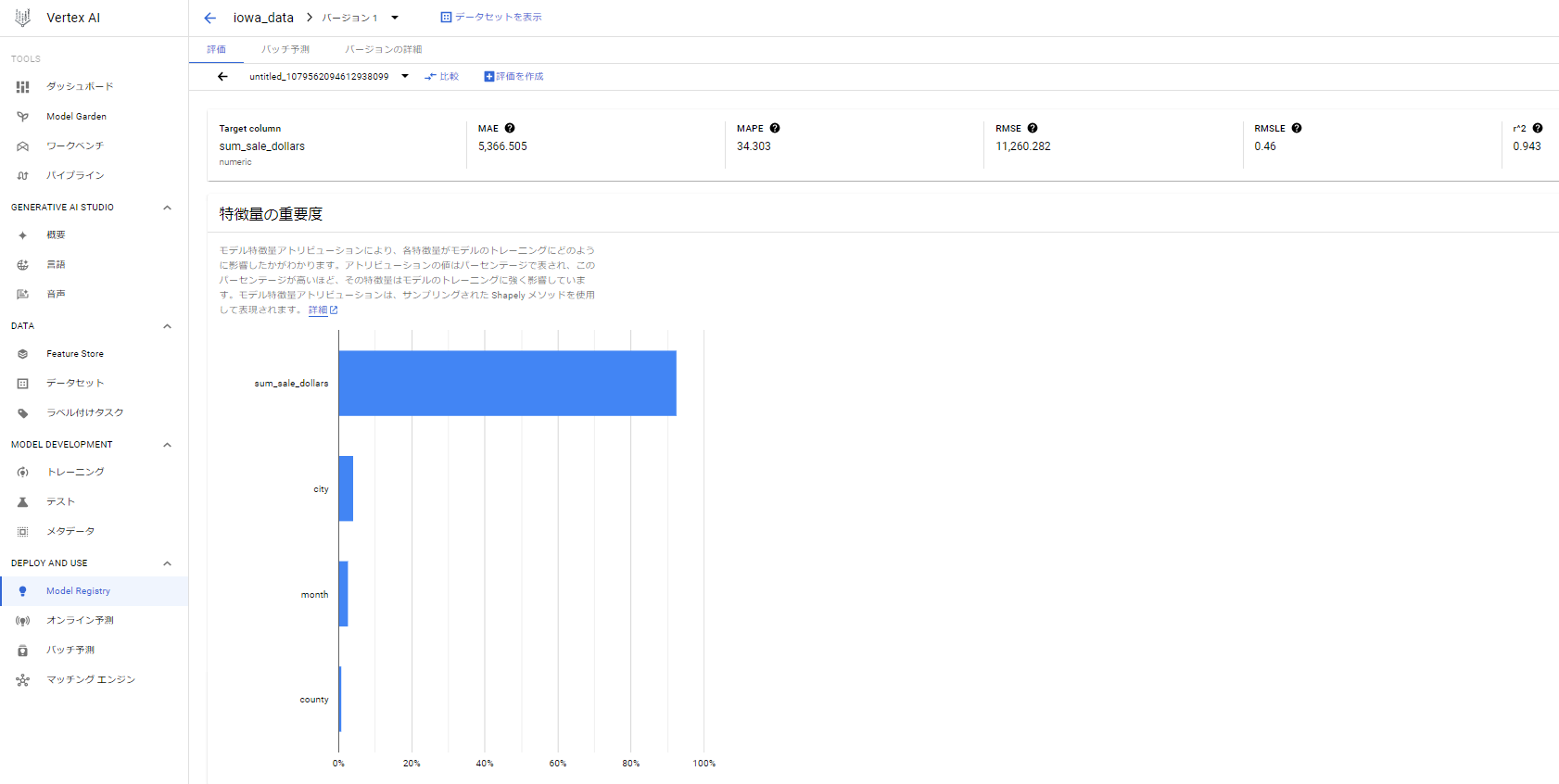
6. トレーニング完了後は下記のようになるよ。r^2=0.943と中々良いモデルが出来たと思われる。
3. バッチ予測を行う
作ったモデルを使って、countyが「BLACK HAWK」のデータの未来を予測するよ。
1. 事前にバッチ予測のためのファイルを作成するよ。
store_number,city,county,month,sum_sale_dollars
2572,CEDAR FALLS,BLACK HAWK,2020-10-01,235546.6
2572,CEDAR FALLS,BLACK HAWK,2020-11-01,111767.31
2572,CEDAR FALLS,BLACK HAWK,2020-12-01,149247.93
2572,CEDAR FALLS,BLACK HAWK,2021-01-01,98284.37
2572,CEDAR FALLS,BLACK HAWK,2021-02-01,165989.78
2572,CEDAR FALLS,BLACK HAWK,2021-03-01,84129.3
2572,CEDAR FALLS,BLACK HAWK,2021-04-01,107314.89
2572,CEDAR FALLS,BLACK HAWK,2021-05-01,89426.06
2572,CEDAR FALLS,BLACK HAWK,2021-06-01,113249.7
2572,CEDAR FALLS,BLACK HAWK,2021-07-01,107321.88
2572,CEDAR FALLS,BLACK HAWK,2021-08-01,96670.62
2572,CEDAR FALLS,BLACK HAWK,2021-09-01,133039.36
2572,CEDAR FALLS,BLACK HAWK,2021-10-01,223808.78
2572,CEDAR FALLS,BLACK HAWK,2021-11-01,92153.44
2572,CEDAR FALLS,BLACK HAWK,2021-12-01,150451.51
2572,CEDAR FALLS,BLACK HAWK,2022-01-01,80624.09
2572,CEDAR FALLS,BLACK HAWK,2022-02-01,182422.51
2572,CEDAR FALLS,BLACK HAWK,2022-03-01,46200.93
2572,CEDAR FALLS,BLACK HAWK,2022-04-01,76854.84
2572,CEDAR FALLS,BLACK HAWK,2022-05-01,75498.26
2572,CEDAR FALLS,BLACK HAWK,2022-06-01,127620.9
2572,CEDAR FALLS,BLACK HAWK,2022-07-01,74243.45
2572,CEDAR FALLS,BLACK HAWK,2022-08-01,98805.75
2572,CEDAR FALLS,BLACK HAWK,2022-09-01,122401.88
2572,CEDAR FALLS,BLACK HAWK,2022-10-01,
2572,CEDAR FALLS,BLACK HAWK,2022-11-01,
2572,CEDAR FALLS,BLACK HAWK,2022-12-01,
2572,CEDAR FALLS,BLACK HAWK,2023-01-01,
2572,CEDAR FALLS,BLACK HAWK,2023-02-01,
2572,CEDAR FALLS,BLACK HAWK,2023-03-01,
必要なのは過去12か月分のデータと、未来の6か月分の日付のデータだよ。
「pred.csv」には24か月分あるけど、実際には12か月分しか使われないよ。また未来7か月分以上の日付を用意しても6か月分しか予測されないよ。未来6か月は連続じゃなくても良くて、例えば最後の「2023-03-01」が「2023-04-01」でも予測されるよ。
2. 左ペインから【バッチ予測】を選択して、【作成】をクリックする。
3. 以下のキャプチャのように各値をセットする。【転送先のパス】のcsvは事前にGoogle Cloudにアップロードしてちょ。
出力形式を【BigQueryテーブル】にした場合、事前にBigQueryにデータセットを作成する必要があり。「projectId.datasetId」で指定しないと最後に【作成】を行ったときにエラーが出るのでご注意を(なぜか出力されるテーブル名は決められない)。
【このモデルの特徴のアトリビューションを有効にする】にチェックを入れると、予測結果でどの項目が効いたかの重みが表示されるよ。ただ費用もかかるみたいなので必要に応じてチェックを入れてちょ。
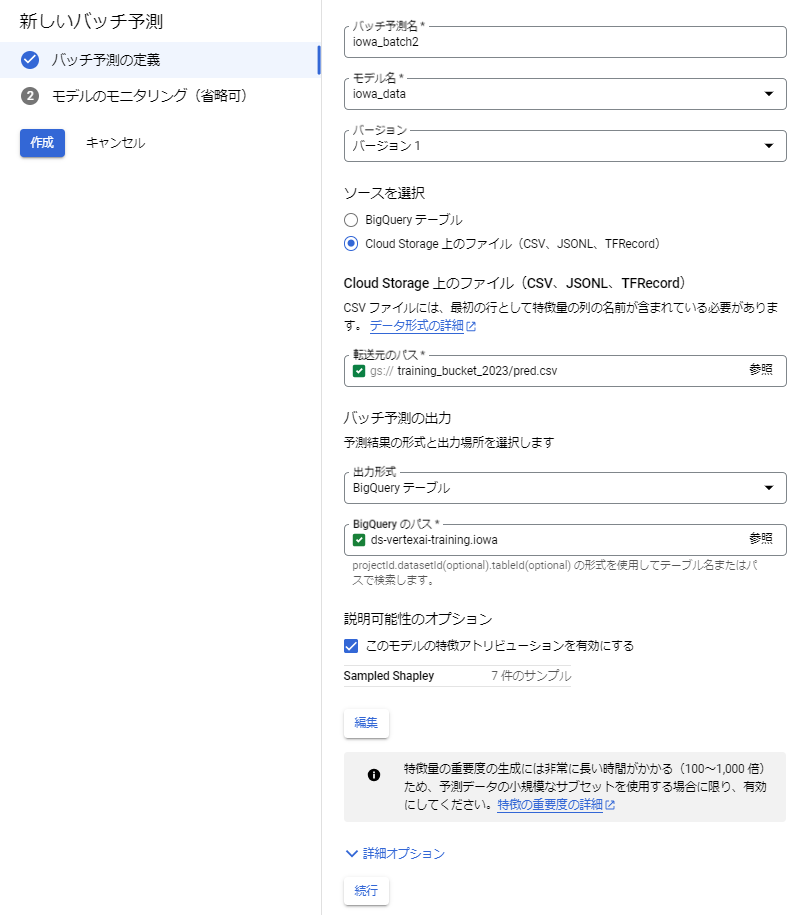
4. 以下のキャプチャのようにラジオボタンは有効にしなくて良い。こちらは筆者も使い方不明。最後に【作成】をクリックするとバッチ予測が始まる。約30分かかるよ。
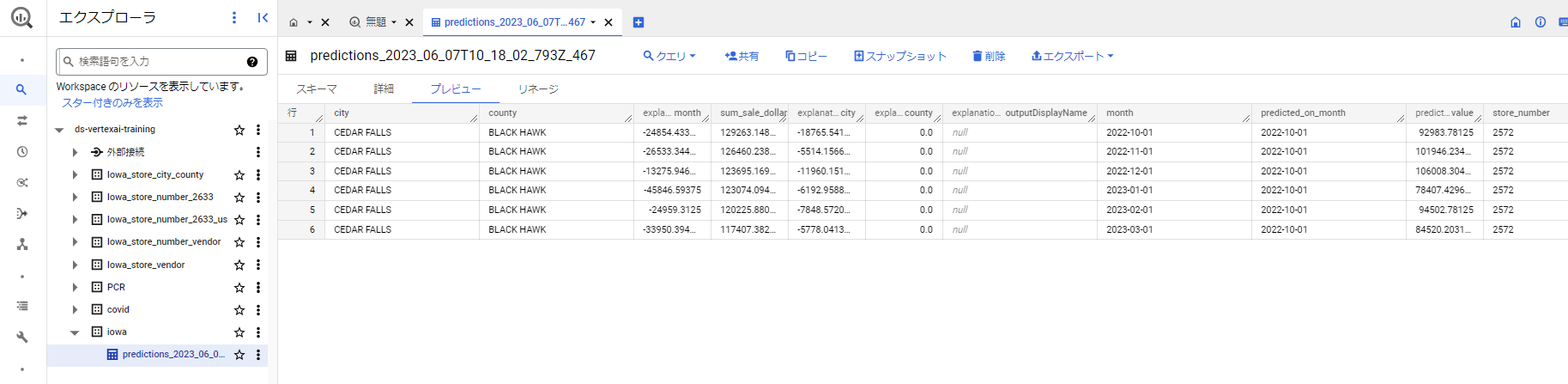
5. こんな結果になるよ。右から二つ目の【predicted_sum_sale_dollars.value】が予測値になるよ。
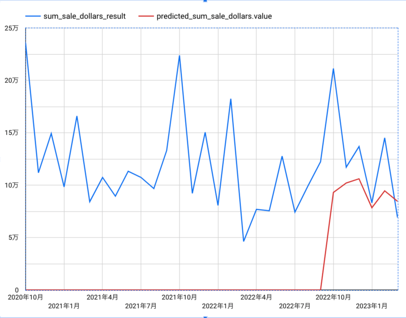
【補足】予測値と実績値をグラフで比較してみた
Looker Studioを使って予測値と実績値をグラフにしてみたよ(やり方は省略)。
青線が実績の値、赤線がバッチ予測で取得した値だよ。グラフにすると未来の傾向は掴めていそうと言った結果かな。
【補足】1店舗の日ごとの売上予測を行いたいときはどうすれば?
データのイメージとしては下記のSQL。行いたいデータセットにstore_numberが無いと言う場合には、任意の固定値を入れてCSVファイルにする必要があるよ。その固定値を入れたカラムを、モデル作成時の【Series identifier column】にセットする必要があるためだよ。
SELECT store_number, sum(sale_dollars) as sum_sale_dollars, date as date
FROM `bigquery-public-data.iowa_liquor_sales.sales`
WHERE date_trunc(date, MONTH) >= parse_date('%Y%m%d', '20201001')
AND date < parse_date('%Y%m%d', '20221001')
AND store_number = '2633'
GROUP BY store_number, date
ORDER BY store_number, date
バッチ予測のCSVファイルも、dataset_sample.sqlで作成したCSVの一番下の行に、「2633,,2023-10-01」「2633,,2023-10-02」・・・(予測したい日数分の日付)を追加するだけでOKよ。
感想
店舗と市や群との相関はほとんど無さそうで残念。ただし多変量での時系列モデルが作れるので用途は広がる。
精度としては高いモデルが作成されたので、お手軽にある程度のモデルができるイメージでした。
みんなで未来を予測しよう!