アーキテクチャ
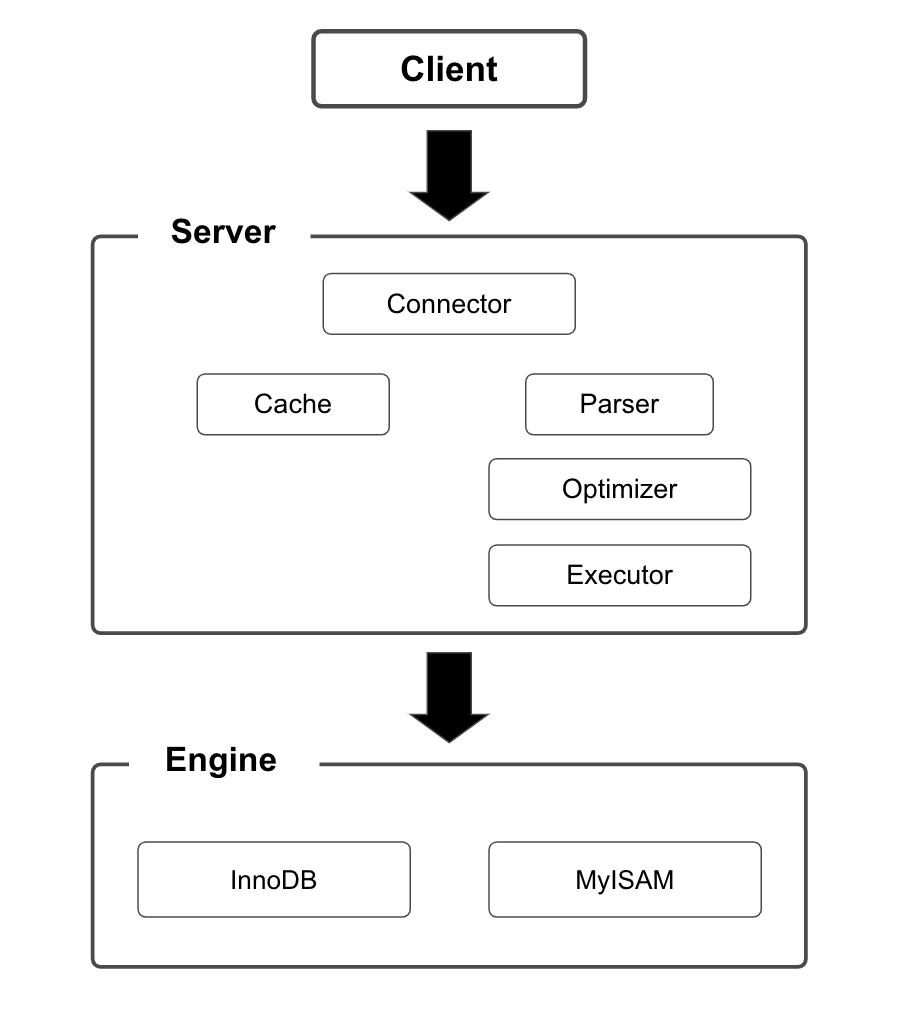
アーキテクチャは大きくサーバーとエンジンに分かれる。
サーバーはMySQLの本体であり、その機能や組み込み関数が実装されている。
エンジンはデータベースに対してデータを保存・取得する機能が実装されている。ストレージエンジンとも言う。
1. Connector
クライアントとMySQLの接続コネクションを管理するもの。
下記コマンドでコネクションを確認することができる。
$ mysql> show processlist;
+----+-----------------+-----------+------+---------+--------+------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------+------+---------+--------+------------------------+------------------+
| 7 | event_scheduler | localhost | NULL | Daemon | 282221 | Waiting on empty queue | NULL |
| 18 | root | localhost | NULL | Query | 0 | init | show processlist |
+----+-----------------+-----------+------+---------+--------+------------------------+------------------+
2 rows in set (0.01 sec)
2. Parser
SQLを解析するもの。
字句解析と構文解析を行う。
字句解析: 文字の並びを解析し、言語的に意味のある最小の単位(トークン)に分解する処理
構文解析: 構文規則に基づいて、字句解析されたトークン同士の関係性を解析する処理
MySQLでは、ここで文法上の問題発見とアクセス先のテーブルの存在確認も行う。
3. Optimizer
実行に最適なクエリ計画を行うもの。
アクセス経路、インデックスの有無などのパラメーターから、最もコストの低いクエリを計画する。
実行したいSQLの前にexplainを付けると、クエリ計画を確認できる。
mysql> select name from workflows where id = 1;
+-------------------------+
| name |
+-------------------------+
| test |
+-------------------------+
1 row in set (0.00 sec)
mysql> explain select name from workflows where id = 1;
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | test | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
partitions:分割されたテーブルのうち、どれを検索対象にするか。
possible_keys : MySQL がこのテーブル内の行の検索に使用するために選択できるインデックス。
key : MySQL が実際に使用することを決定したキー (インデックス)。
rows : MySQL がクエリーを実行するために調査する必要があると考える行数。
4. Executor
エンジン(ストレージエンジン)のインタフェースを利用して、コマンドを実行する。
ログシステム
SQL実行時の重要なログとして、
・bin log
・redo log
の2種類が存在する。
bin logはサーバーが、redo logはエンジン(InnoDBエンジン)がデータベース更新時に出力するログ。
| ログ名 | 出力 | 用途 | ログ内容 | ログファイル |
|---|---|---|---|---|
| binlog | サーバー | DBデータの復元 レプリケーション |
データの変更内容を記録 | 可変 |
| redo log | エンジン | 更新データの一時保存 クラッシュ時のデータ復元 |
SQL文 更新前後のレコード内容 |
固定 |
binlog
レコードの更新内容 or SQL文を保持。謝って削除したデータを復元する際に利用する。
バックアップが存在する場合は、バックアップ ~ 指定時点のbinlogを適用することで、指定時点のデータを復元することができる。
マスタスレーブ構成など2つ以上のデータベースが存在する場合は、マスタからスレーブにbinlogを転送することでデータの同期を行う。
redo log
ディスクI/Oコストを削減するために設計されたログ。
メモリ上でレコードを更新し、redo log bufferに記録。その後、システムが空いている時にディスクに反映させる。
redo logのサイズは固定されており、サイズが足りなくなったらディスクに反映した上でログを上書きする。
DB自体に異常があった場合、メモリ上にあるredo logを使用することでデータの復旧を行うことができる。
実行プロセス
- 更新対象レコードを取得
- レコードがメモリ上に存在しない場合はディスクから取得する
- メモリ上でレコードを更新
- redo logを出力 ステータスはprepared
- binlogを出力
- redo logのステータスをcommitに変更
クラッシュによってMySQLが再起動した場合、まずredo logを確認する。
redo logのステータスがcommitであれば、redo logに記述された更新内容をコミットする。
redo logのステータスがpreparedであれば、binlogの状態を確認する。該当のbinlogが出力されていない場合はredo logの更新内容をロールバックする。binlogが出力されている場合は、redo logの変更内容をコミットする。