概要
本記事はarXivに投稿されている論文
SecureBERT: A Domain-Specific Language Model for Cybersecurity
の内容の紹介です。
各章ごとにざっくりした内容を紹介します。
この論文は2022/4/6に公開されたものであり、この記事は2024/1/23に書いています。
論文リンク
SecureBERT: A Domain-Specific Language Model for Cybersecurity
0. Abstract
脅威インテリジェンスなどの分野でも自然言語処理が注目をされています。
本論文ではSecureBERTというサイバーセキュリティ特化の自然言語処理モデルを提案しており、このモデルを使用することでサイバーセキュリティのタスクを効率的に推進することができます。
SecureBERTは効率的に再学習を行うために以下の方法を用いています。
- カスタマイズされたトークトークナイザ
- 事前学習された重みに対する調整
また、SecureBERTの性能はMasked Language Modeと他2つのタスクで評価します。
本論文の評価によればSecureBERTはサイバーセキュリティの重要なタスクを解決する能力が他のモデルを上回っています。
1. Introduction
近年、世の中の情報量が大量に増加しており、その情報を守るためのセキュリティソリューションや人への投資もどんどん増えています。
プロダクトの数もどんどん増え、脆弱性も日々多く公開されており、迅速に脆弱性を特定し、防御手段を提供するようなシステムが求められています。
自然言語処理技術は自然言語と機械の理解できる量的な表現をうまいこと変換しており、ELMO、GPT、BERTなどは様々なタスクで高性能を出しています。
これらのモデルをベースラインとして、ドメイン特化にファインチューンできれば、一般的な英語の能力とドメイン知識を持ったモデルができると仮定されます。
サイバーセキュリティなどの分野は非常にセンシティブであり、ロバストで信頼性の高いフレームワークが必要ですが、専門用語は多いし、ドメインによって意味の異なる単語があったりします。
標準的な英語を扱うモデルではうまく語彙を理解できないかもしれません。
この研究ではBERTをファインチューニングしたSecureBERTを導入します。フィッシング検知、マルウェア解析、侵入検知など様々なサイバーセキュリティのタスクに適用することができます。
SecureBERTはニュースや論文などから得た1.1億単語を用いて再学習されています。
サイバーセキュリティの語彙をうまく処理しながら一般的な英語の語彙も保持するトークナイザの開発し、pre-trainedの重みにランダムノイズを入れることで再学習手順を最適化する方法も利用して再学習を行っています。
評価には
- Masked Language Model
- 感情分析
- 固有表現認識
を用いておりSecureBERTがサイバーセキュリティと一般的な英語の入力をどれほど効果的に処理できるかを実証しています。
2. Overview of BERT Language Model
BERTはTransformeベースの双方向型トレーニングを行うモデルで前後周囲の文脈に基づいて単語の意味を理解することができます。
BERTでは
- Masked Language Model
- Next Sentence Prediction
の2つの工夫でモデルの学習が行われており、pre-tarainにBooks Corpus(800M単語)とEnglish Wikipedia(2,500M単語)が用いられておりGLUEスコアやStanford Question Answering Datasetでの精度がめっちゃいいです。
BERTのよりロバストな派生としてはRoBERTaがあり、MLMの能力が拡張されています。
SecureBERTはRoBERTaをベースにしています。
※わたしの声
BERTやRoBERTaの理解には以下の動画がお勧めです。
【深層学習】BERT - 実務家必修。実務で超応用されまくっている自然言語処理モデル【ディープラーニングの世界vol.32】
【深層学習】RoBERTa - データと学習方法だけで XLNet を超えたモデル【ディープラーニングの世界vol.35】
3. Data Collection
筆者らは本やブログや論文などなどから平均512語の220万文書に分割した11億単語のコーパスを作成しました。
以下はSecureBERTのpre-trainに使われたデータセットです。
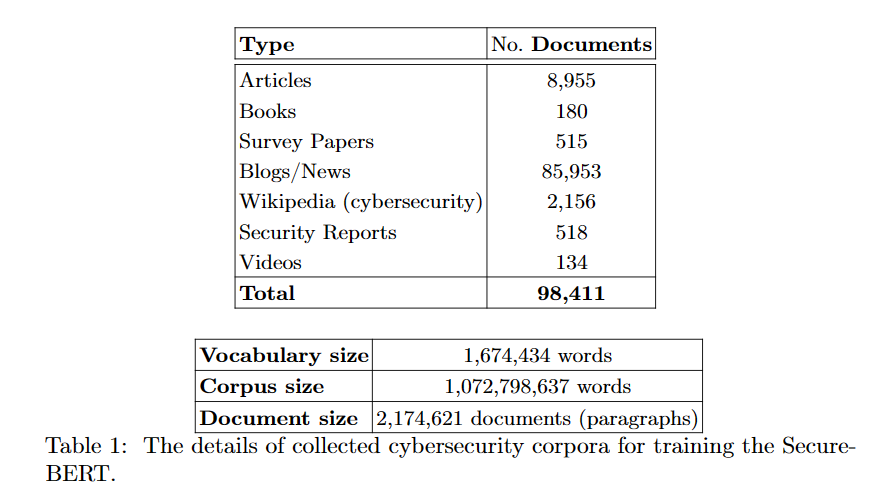
このコーパスには様々なサイバーセキュリティ関連のテキストが含まれています。
以下はソースの一覧です。

4. Methodology
このセクションではドメイン特化言語モデルをトレーニングするための2つのアプローチを紹介します。
4.1 Customized Tokenizer
トークナイザは単語や文章をトークンと呼ばれる分析の単位に分割し、機械が理解できる形式にエンコードします。
トークンには一意のインデックスが付与されており、BERTモデルはインデックスに基づいて単語の重みを返します。
そのため、事前学習のトークナイザと特化型の学習をするためのトークナイザは単語に対するインデックスが一致している必要があります。
本論文ではトークナイザにはByte Pair Encodingを用いています。
Byte Pair EncodingはSub-Word Embeddingという手法の一種で文字のペアの出現頻度をカウントしその出現頻度の高い文字ペアもトークン化することによってサブワードという単語単位とは別の語彙を学習することができます。
特化型のモデルのためには、RoBERTaのトークナイザですでに保持しているトークンは維持しつつ、サイバーセキュリティに関する新たなトークンを組み込む必要があります。
初期トークンの語彙の数ΨはSecureBERTとRoBERTaで一致させ50,265とします。そのうち32,592トークンは同じ語彙であり、SecureBERTの残り17,673トークンはfirewall, breach, crack, ransomwareなどのサーバーセキュリティに関する語彙です。
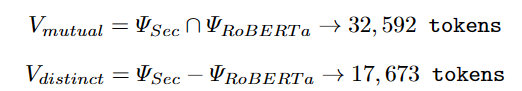
上記のVmutualのトークンはRoBERTaとSecureBERTで同じインデックスを持つようにし、SecureBERTの残りのトークンにはランダムなインデックスを付与します。
WeightもVmutualのトークンはRoBERTaとSecureBERTで同じWightを返し、SecureBERTの残りのトークンはランダムなWightを返すようにします。
4.2 Weight Adjustments
RoBERTaのモデルには一般的な英語の語彙が学習されていますが、サイバーセキュリティの分野では同じ単語でも意味の異なるものが存在します。
adversary, virus,worm, exploit, crackなんかがそれにあたります。
RoBERTaの重みをすべて踏襲して再学習をかけてしまうと、重みはほぼ変わらず、過学習の状態になります。
この場合はモデルの学習時にノイズを導入することによって過学習を防ぐことができます。
モデルをスクラッチで学習するような場合には隠れ層に、再学習の場合には入力データにノイズを導入するのが一般的です。
SecureBERTの学習時にはRoBERTaのWeightにノイズを導入したものを初期Weightとしました。これによって、もとの語彙からは逸脱しすぎないが、文脈によってサイバーセキュリティ的な語彙でトークンをとらえられるようになります。
RoBERTaと共有していない新しいトークンに対してはXavier weight initialization algorithmで初期Weightを付与しています。
SecureBERTを構築するために使用したRoBERTaベースのモデルは12の隠れTransformer層およびAttention層、入力層で構成されています。
サイバーセキュリティの語彙はあまり多様性はないため、使いやすくて学習コストの低い小さなモデルで十分と考えられます。
各入力トークンは768次元であり、正規分布に従うガウシアンノイズでノイズを導入します。
Wtはトークンtの埋め込みベクトルです。

Wtkはベクトルのk番目の要素でN(μ,σ)を正規分布とするとノイズを導入したWk'は以下で定義されます。
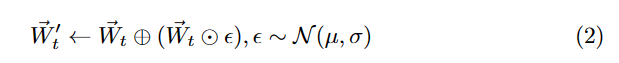
εはノイズの値で、〇に+と〇に・はそれぞれ要素ごとの足し算、掛け算です。
SecureBERTは12の隠れ層と12のAttention Headをもち、隠れ状態は768次元です。入力は512次元でこればRoBERTaと同じです。RoBERTaの重みの平均と分散はそれぞれ−0.0125と0.0173であり、ノイズは平均、分散をμ=0,σ=0.01で生成します。オリジナルの重みはこのノイズを含んだ式(2)であらわさられる重みに置換されます。
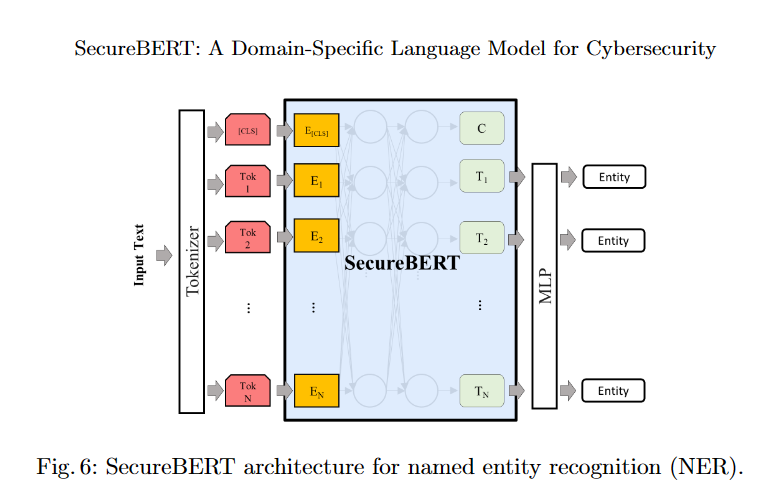
SercureBERTのアーキテクチャは以下の図のようになります。
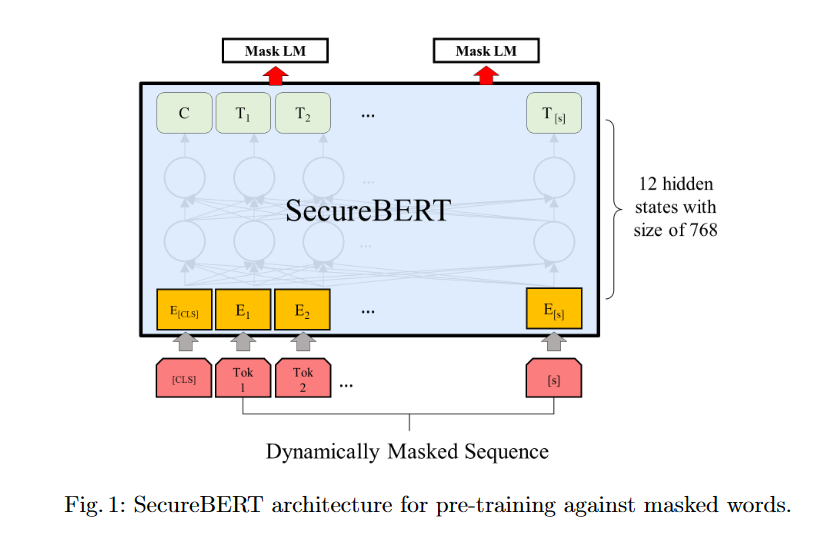
5. Evaluation
- トレーニング環境
- 250,000stepを100時間
- Tesla V100GPU 8枚
- バッチサイズ18
- 評価方法
- Masked Language Modeling
- 感情分析
- 固有表現認識
5.1 Masked Language Model (MLM)
一部がマスクされた文章を入力とし、マスクされた部分を予測するタスクでSecureBERTの評価を行います。
データセットはMITREからサイバーセキュリティに関する文章を抜き出したもので、トレーニングに使用されていない文章です。
サイバーセキュリティに関する文脈を読み取ってほしいので、マスクする単語は動詞か名詞の実にします。
データは17,341個あり、そのうち12,721は名詞をマスクし、4,620は動詞をマスクしました。
以下は予測の結果ですが、SecureBERTはサイバーセキュリティの単語の予測において他の優れたモデルを常に上回っていました。
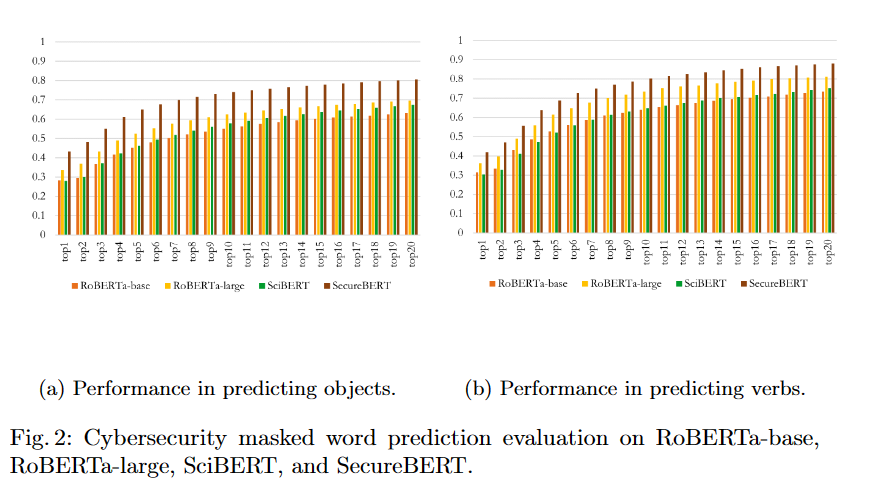
特にRoBERTa-Largeは大きく優れたモデルで、一般的にはとても優秀ですがサイバーセキュリティの文脈では間違った予測を返します。
以下は一例ですが、reconnaissance、hijacking、DdoSなどサイバーセキュリティでよく用いられえる単語もSeucreBERTであればうまく予測することができますが、RoBERTaは間違った予測を返してしまいます。

5.2 Ablation Study
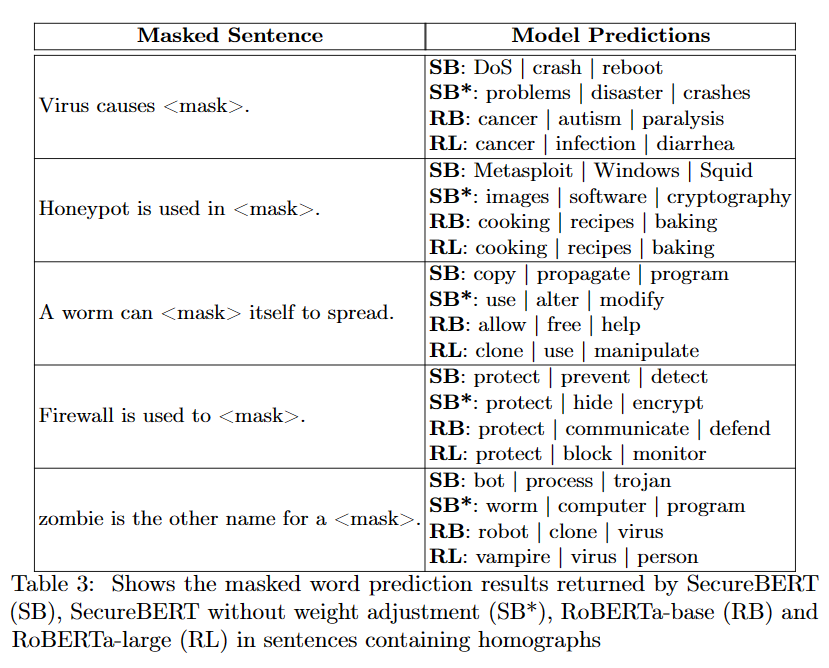
本論文では、同形異義語をうまく理解するために重みに対してわずかにノイズを導入し調整を行いました。
その効果を評価するためによく知られた同形異義語を用いた文章の予測タスクを実施しました。
使用したモデルは
- SB (SecureBERT)
- SB* (SecureBERT trained without weightadjustment)
- RB (RoBERTa-base)
- RL (RoBERTa-large)
の4つです。
以下はその結果ですが、例えば"Virus causes"という文章に対して、RBやRLはガンなど一般的なウイルスに関する単語を返し、SB*は問題、災害などRBなどとは違うもののまだサイバーセキュリティの文脈に沿っているとはいいづらい単語も返しています。
それに対しSBはDoSやrebootも含みサイバーセキュリティを関係のある単語を返しています。これば重み調整が有効であることを示しています。
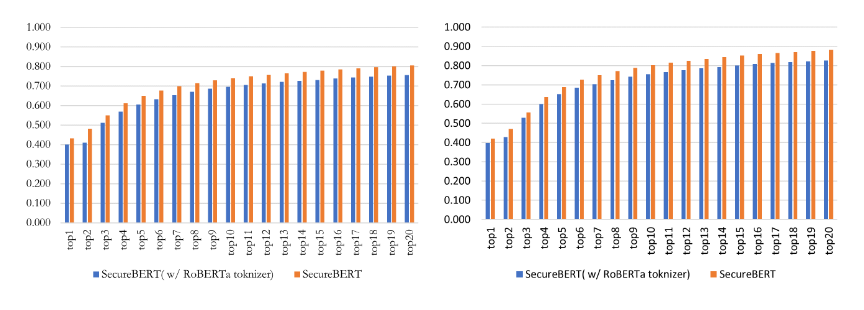
さらにカスタムトークナイザの有効性も検証します。
以下は重み調整をしたうえで、カスタムトークナイザを利用した場合としない場合にMLMのタスクを実施した比較です。
明らかにカスタムトークナイザを利用した方がヒット率が高くなっています。
5.3 Fine-tuning Tasks
SecureBERTの一般的な自然言語処理タスクの能力を感情分析と固有表現認識を用いて検証しました。
Task1: Sentiment Analysis
感情分析の形式で一般的な英語の理解を評価します。
評価には多くのフレーズが格納されたRotten Tomatoes datasetを利用し、各フレーズに対して
- negative
- somewhat negative
- neutral
- somewhatpositive
- positive
の5段階の感情に分類を行います。
モデルには分類層として1層の多層パーセプトロン(MLP)を付けます。
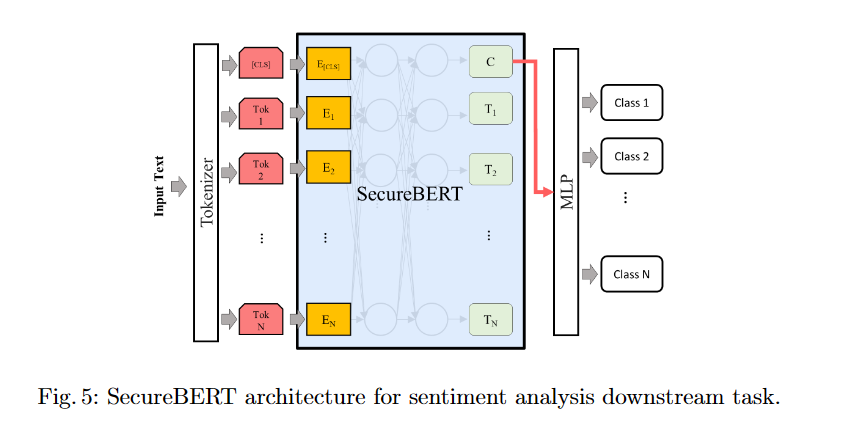
評価には2つのSecureBERTを用意しました。
1つ目はraw SecureBERTと呼び、カスタムトークナイザを重み調整の手法を持ちいてトレーニングしたモデル。
2つ目はmodifiedSecureBERTと呼び、オリジナルのRoBERTaを学習率1e-5、バッチサイズ32、1500ステップでサイバーセキュリティのコーパスで学習したものです。オプティマイザはAdamで活性化関数はSoftmax関数です。
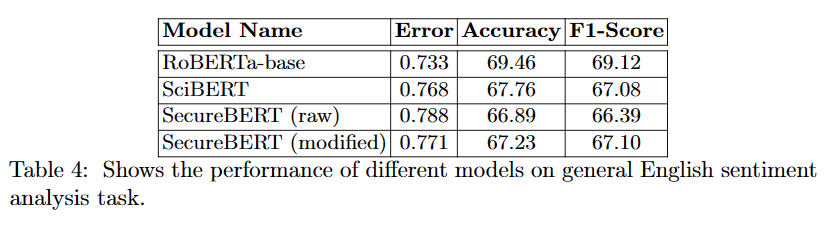
以下に感情分析の結果の比較を載せます。
ここから、広範なドメインのデータで学習されているモデル(SciBERT)に対して、SecureBERTも同等に一般的な英語を理解できていることがわかります。
正解率とF1スコアを見るとmodifiedのSecureBERTの方がよい制度を出しています。
Task2: Name Entity Recognitio
次に固有表現認識の評価を行います。
固有表現認識(NER)は非構造なテキストから、人名、組織、場所など事前に定義されたエンティティを抽出するタスクです。
評価のためのデータセットにはMalwareTextDBのデータセットを用いました。
このデータセットのNERバージョンとして文章に以下のアノテーションがされています。
- Action: イベント
- Subject: アクションを起こす人(モノ)
- Object: アクションを起こされる人(モノ)
- Modifier: 接続後
- O: 上記以外のすべての単語に対するダミーフラグ
評価のためにモデルの最後の層からは各トークンの隠れ状態を取得し、これらのトークンはエンティティの数と同様のN個の出力を持つ全結合層によって処理されます。
モデルは3エポック、学習率2e-5、バッチサイズ8、オプティマイザはAdam、活性化関数はSoftmax関数で学習されています。
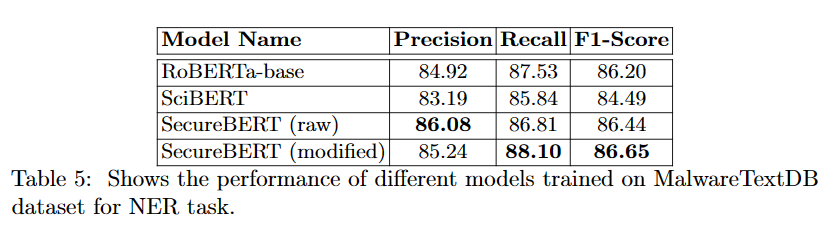
以下は評価の結果となります。
こちらでも、一般的な英語の文章が多く含まれているにもかかわらずSecureBERTが高い精度を出しています。
6. Related Works
-
科学ドメイン特化のNLPモデル
Beltagy, I., Lo, K., Cohan, A.: Scibert: A pretrained language model for scientifictext. arXiv preprint arXiv:1903.10676 (2019) -
バイオメディカル特化のNLPモデル
Lee, J., Yoon, W., Kim, S., Kim, D., Kim, S., So, C.H., Kang, J.: Biobert: apre-trained biomedical language representation model for biomedical text mining.Bioinformatics36(4), 1234–1240 (2020) -
臨床テキストで学習されたモデル
Alsentzer, E., Murphy, J.R., Boag, W., Weng, W.H., Jin, D., Naumann, T.,McDermott, M.: Publicly available clinical bert embeddings. arXiv preprintarXiv:1904.03323 (2019) -
ICSデバイスからサイバーセキュリティの情報を分類するモデル
Ameri, K., Hempel, M., Sharif, H., Lopez Jr, J., Perumalla, K.: Cybert: Cyber-security claim classification by fine-tuning the bert language model. Journal ofCybersecurity and Privacy1(4), 615–637 (2021) -
サイバーセキュリティの脆弱性や弱点を階層的に分類するモデル
Das, S.S., Serra, E., Halappanavar, M., Pothen, A., Al-Shaer, E.: V2w-bert: Aframework for effective hierarchical multiclass classification of software vulnerabili-ties. In: 2021 IEEE 8th International Conference on Data Science and AdvancedAnalytics (DSAA). pp. 1–12. IEEE (2021) -
などなど・・・
7. Conclusions and Future Works
本論文ではサイバーセキュリティドメイン特化のNLPモデルであるSecureBERTを紹介しました。
筆者らはNLPがサイバーセキュリティの文脈を理解するための、カスタムトークナイザを重み調整の2つの実用的な方法を提案しました。
SecureBERTはサイバーセキュリティに関する11億の単語から学習されており、MLM、固有認識表現のタスクを評価することでサイバーセキュリティに関する文脈理解の有望な結果を示すことができました。
最後に
セキュリティとAIに関する論文の紹介を進めるほか、Hack The Boxのwriteupなども投稿しています。
皆さんの学習の一助になれば幸いです。
なお、論文の理解に間違いがある場合はどんどんご指摘いただきたく思います。
よろしくお願いいたします。