本稿では、KerasベースのAttention付きSeq2seqモデルによって構築したチャットボットを、Twitterから取得した大量の会話データを用いて訓練し、応答文生成の精度向上を図ります。
1. はじめに
前回の投稿で、Twitterからの会話データ収集ツールを準備しましたので、収集したデータからエンコーダ/デコーダ入力、およびラベルデータを生成して、以前チャットボット用に作成したKerasベースのAttention付きSeq2seqモデルを訓練し、応答文生成の精度が向上するかどうか、見てみます。
前回は名大会話コーパスなどを訓練データに使用しましたが、応答文の精度は今一つでした。その原因は訓練データのボリューム不足にあると考え、今回はTwitterから会話データを大量に入手することでボリューム面の課題解決を図ります。
2. 本稿のゴール
以下の通りです。
- Twitterから取得した会話データから、訓練用のエンコーダ/デコーダ入力、およびラベルデータを生成します
- 作成した訓練データを使って、チャットボットを訓練します
また、、本稿の前提となるソフトウェア環境は、以下の通りです。
- Ubuntu 16.04 LTS
- Python 3.6.4
- Anaconda 5.1.0
- TensorFlow-gpu 1.3.0
- Keras 2.1.4
- Jupyter 4.4.0
なお、後述の訓練処理が非常に重いので、ハードウェア環境としては、GPUマシンか、クラウドサービスの利用を推奨します。
3. 訓練データ生成
3-1. Twitter会話データの収集
こちらの記事の内容にしたがって、Twitterから会話データを収集します。実行したいフォルダに実行ファイルconvercation_py3.pyを置き、ツイートデータの格納用フォルダtweetを作成したうえで、以下のように実行してください。
$ python conversation_py3.py です
「です」というのは引数です。何か適当な検索ワードを指定してください。
十分なデータが収集できるまで、動作させたままにしておきます。指定する検索ワードにも依りますが、1日当たり、20万~30万対の会話データを収集できます。
3-2. 品詞分解
京大黒橋・河原研究室のJUMAN++を使用します。
名大会話コーパス等から訓練データを生成した時には、V1.02を使用しましたが、この版は動作が遅く、20万会話対を収納したファイルの品詞分解が、24時間では終了しませんでした。
そこで、こちらの記事を参考に、最新版を導入します。2018年11月時点の最新版は2.0.0-rc2で、まだ「開発版」の扱いですが、背に腹は代えられません。
ちょっと手間はかかりますが、無事インストールが済んだら、実行します。実行手順は前の版と同じです。すると、驚くようなスピードで、それこそあっという間に処理が終了しました。
出来上がった品詞分解結果ファイルは、「juman」という名前のフォルダを作成して、そこに格納しておきます。
3-3. 単語リスト作成
JUMAN++の出力結果は、デリミタが半角スペースのCSVファイルの形態をとっています。これに対し、
- 1列目を取り出す
- 「@」で始まる行(同音異義語)や「EOS」の行を削除する
- 「REQ」+「:」、「RES」+「:」を、それぞれ「REQREQ」、「RESRES」に置き換える
という加工をします。3つ目の処理は、ツイート収集時に文の切れ目の目印として付与した「REQ:」「RES:」がjuman++によって分解されてしまったため、入れた処理です。
これらの処理によって得た単語を、出現順にリストにします。
コードは以下の通りです。
# coding: utf-8
# **********************************************************************************
# *
# juman++の品詞分解結果をリストに書き出し *
# *
# **********************************************************************************
def genarate_npy(source_csv ,list_corpus) :
with open(source_csv, 'r') as f :
df2 = csv.reader(f,delimiter=' ')
mat = [ v for v in df2]
print(len(mat))
j=0
#補正
for i in range(0,len(mat)):
if len(mat[i]) != 0 :
if mat[i][0] != '' :
if mat[i][0] != '@' and mat[i][0] != 'EOS' and mat[i][0] != ':' and mat[i][0][0] != '\\' :
if mat[i][0] == 'REQ' and mat[i+1][0] == ':' : #デリミタ「REQ:」対応
list_corpus.append('REQREQ')
elif mat[i][0] == 'RES' and mat[i+1][0] == ':' : #デリミタ「RES:」対応
list_corpus.append('RESRES')
else :
list_corpus.append(mat[i][0])
if i % 1000000 == 0 :
print(i,list_corpus[j])
j += 1
print(len(list_corpus))
del mat
return
# **********************************************************************************
# *
# メイン処理 *
# *
# **********************************************************************************
if __name__ == '__main__':
import numpy as np
import csv
import glob
import re
import pickle
file_list = glob.glob('juman/*')
print(len(file_list))
n_words = 0
for j in range(0,len(file_list)) :
print(file_list[j])
generated_list=[]
genarate_npy(file_list[j],generated_list)
#コーパスリストセーブ
with open('list_corpus/list_corpus'+str(j)+'.pickle', 'wb') as g :
pickle.dump(generated_list , g)
n_words += len(generated_list)
print(n_words)
del generated_list
スクリプトを実行するフォルダ配下に、Juman++の品詞分解結果が入ったjumanフォルダと、単語リストファイルを格納するlist_corpusフォルダを準備したうえで、以下のようにコマンド起動します。
$ python generate_word_list.py
入力の品詞分解結果ファイルの単位に処理を行い、単語リストファイルもその単位で作成します。最初は単一の単語リストにしようとしたのですが、リストのサイズが大きくなりすぎたのか、途中で処理が進まなくなったので、現行の処理方式としています。
3-4. 辞書および単語インデックス配列作成
前節で作成した単語リストを入力に、単語にインデックスを付与して、両引きができる辞書と、単語リストの単語の並び順にインデックスを配した1次元配列を生成します。今回は、全データを単一の1次元配列にまとめます。
インデックス0は、ニューラルネットワークのMasking用に予約したいので、これに単語がアサインされないよう、辞書ファイルに、単語ソート時に必ず先頭に来る「\t」(タブ)を追加します。
単語数は、チャットボットを構成するニューラルネットワークの入出力次元になります。これが大きいと、学習コストの割に予測精度が上がらないので、出現頻度の低い単語は思い切って、十把一絡げに不明単語を表す文字列「UNK」に置き換えます。
コードは以下の通りです。以下の例では、「UNK」置き換えのしきい値を10にしてあります。これにより、今回の場合の単語数は10万程度になりました。
# coding: utf-8
def generate_mat() :
file_list = glob.glob('list_corpus/*')
print('ファイル数 =',len(file_list))
mat=[]
for i in range (0,len(file_list)) :
with open(file_list[i],'rb') as f :
generated_list=pickle.load(f) #生成リストロード
mat.extend(generated_list)
print(i)
del generated_list
mat.append('REQREQ')
print(len(mat))
words = sorted(list(set(mat)))
cnt = np.zeros(len(words))
print('total words:', len(words))
word_indices = dict((w, i) for i, w in enumerate(words)) #単語をキーにインデックス検索
indices_word = dict((i, w) for i, w in enumerate(words)) #インデックスをキーに単語を検索
#単語の出現数をカウント
for j in range (0,len(mat)):
cnt[word_indices[mat[j]]] += 1
#出現頻度の少ない単語を「UNK」で置き換え
words_unk = [] #未知語一覧
for k in range(0,len(words)):
if cnt[k] <= 10 :
words_unk.append(words[k])
words[k] = 'UNK'
print('words_unk:',len(words_unk)) # words_unkはunkに変換された単語のリスト
#低頻度単語をUNKに置き換えたので、辞書作り直し
words = list(set(words))
words.append('\t') #0パディング対策。インデックス0用キャラクタを追加
words = sorted(words)
print('new total words:', len(words))
word_indices = dict((w, i) for i, w in enumerate(words)) #単語をキーにインデックス検索
indices_word = dict((i, w) for i, w in enumerate(words)) #インデックスをキーに単語を検索
#単語インデックス配列作成
mat_urtext = np.zeros((len(mat),1),dtype=int)
for i in range(0,len(mat)):
if mat[i] in word_indices : #出現頻度の低い単語のインデックスをunkのそれに置き換え
mat_urtext[i,0] = word_indices[mat[i]]
else:
mat_urtext[i,0] = word_indices['UNK']
print(mat_urtext.shape)
#作成した辞書をセーブ
with open('word_indices.pickle', 'wb') as f :
pickle.dump(word_indices , f)
with open('indices_word.pickle', 'wb') as g :
pickle.dump(indices_word , g)
#単語ファイルセーブ
with open('words.pickle', 'wb') as h :
pickle.dump(words , h)
#コーパスセーブ
with open('mat_urtext.pickle', 'wb') as ff :
pickle.dump(mat_urtext , ff)
if __name__ == '__main__':
import numpy as np
import pickle
import glob
generate_mat()
コードの実行は、3-3節と同じフォルダ上で、以下のようにコマンド起動します。
$ python generate_index_matrix.py
3-5. 訓練データ生成
前節で作成した単語インデックス配列から、Seq2Seqモデル用のエンコーダインプット、デコーダインプット、およびラベルを生成します。これらがニューラルネットワークでどのように使われるのかについては、こちらをご覧ください。
エンコーダインプットは、単語インデックス配列の、デリミタ「REQREQ」から「RESRES」までを取り出して生成します。また、デコーダインプットは、これと対になる「RESRES」から「REQREQ」までを取り出して生成します。
ラベルデータは、応答文から生成します。どちらも同じものから生成しますが、デコーダーは入力単語の1つ先の単語を予測するように訓練しますので、この2つは1単語分ずれています。
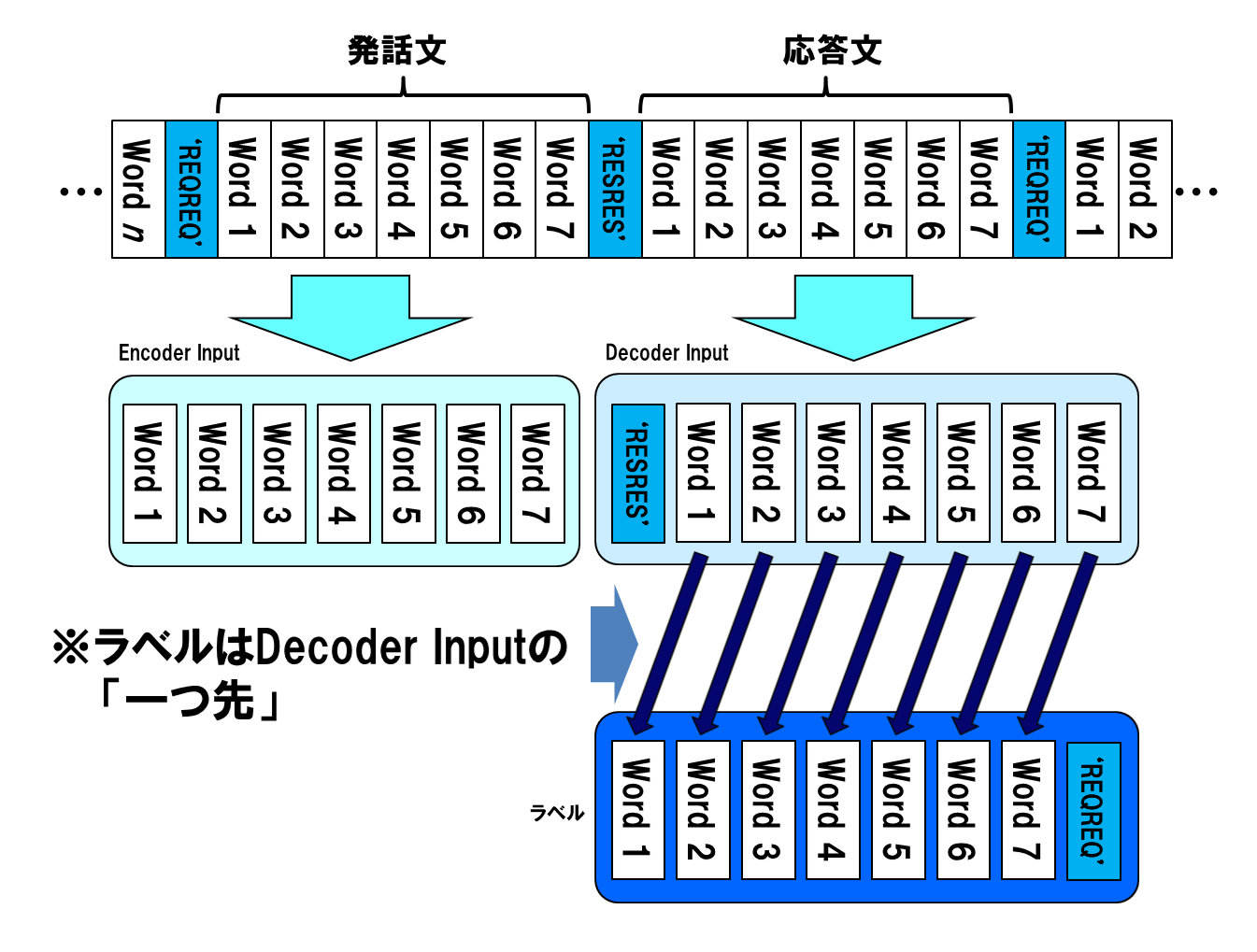
発話文と応答文の対が同一の行になるように、エンコーダインプット、デコーダインプット、およびラベルにデータを詰め込んでいきます。
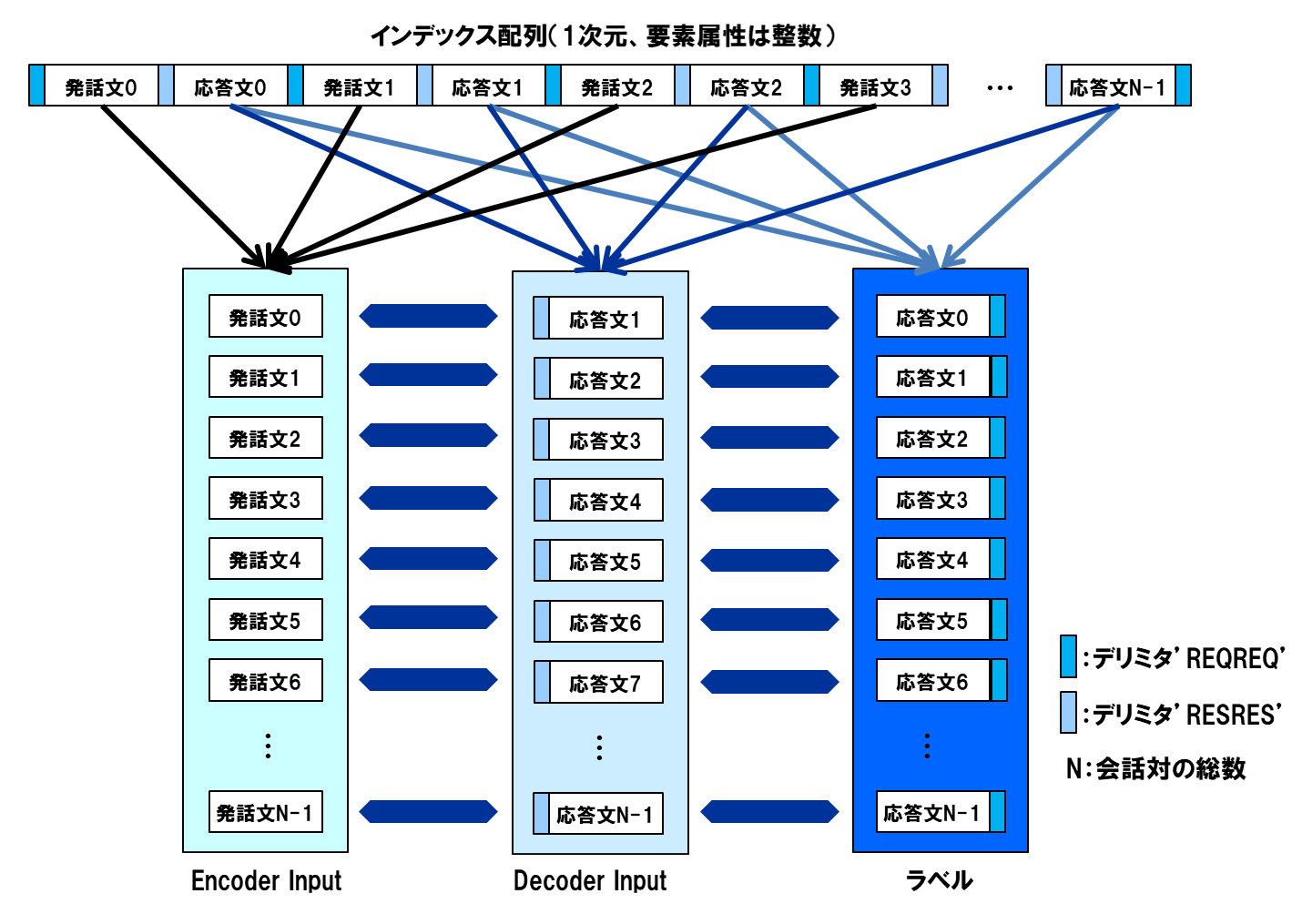
以下にコードを示します。発話文と応答文は必ず対になるように、ツイート取得処理を作ってありますが、まれに発話-応答の組が崩れていることがあるので、そのような場合のスキップ処理を入れてあります。
# coding: utf-8
# *******************************************************************************
# *
# 訓練データ/ラベルテンソル作成処理 *
# *
# *******************************************************************************
def generate_tensors(maxlen_e,maxlen_d) :
#--------------------------------------------------------------------------*
# *
# 単語配列、コーパス配列、辞書のロード *
# *
#--------------------------------------------------------------------------*
#単語ファイルロード
with open('words.pickle', 'rb') as f :
words=pickle.load(f)
#作成した辞書をロード
with open('word_indices.pickle', 'rb') as f :
word_indices=pickle.load(f)
with open('indices_word.pickle', 'rb') as g :
indices_word = pickle.load(g)
#コーパスロード
with open('mat_urtext.pickle', 'rb') as ff :
mat_urtext = pickle.load(ff)
#--------------------------------------------------------------------------*
# *
# コーパスをエンコーダ入力、デコーダ入力応答文のテンソルに変換 *
# *
#--------------------------------------------------------------------------*
req = word_indices['REQREQ']
res = word_indices['RESRES']
delimiters = []
#コーパス上のデリミタの位置を特定する
for i in range(0,mat_urtext.shape[0]) :
if mat_urtext[i,0] == req or mat_urtext[i,0] == res:
delimiters.append(i)
if i % 10000000 == 0 :
print(i)
print(len(delimiters))
n=len(delimiters) // 2
#入力、ラベルテンソルの初期値定義(0値マトリックス)
enc_input = np.zeros((n,maxlen_e))
dec_input = np.zeros((n,maxlen_d))
target = np.zeros((n,maxlen_d))
#デリミタを目印に、コーパスから文章データを切り出して入力/ラベルマトリックスにコピー
j = 0
err_cnt = 0
for i in range(0,n) :
index1=2*i+err_cnt # 「REQREQ」のインデックス
index2=2*i+1+err_cnt # 「RESRES」のインデックス
index3=2*i+2+err_cnt # 次の「REQREQ」のインデックス
if index3 >= n :
break
#発話/応答の組が崩れていた時はスキップする
if mat_urtext[delimiters[index1],0] != req or mat_urtext[delimiters[index2],0] != res :
print('シーケンスエラー ',i)
print(index1,index2)
print(delimiters[index1],delimiters[index2])
print(mat_urtext[delimiters[index1] ,0], mat_urtext[delimiters[index2],0])
print(mat_urtext[delimiters[index1]:delimiters[index3],0])
err_cnt += 1
continue
len_e = delimiters[index2] - delimiters[index1] - 1
len_d = delimiters[index3] - delimiters[index2]
#系列長より短い会話のみ、入力/ラベルマトリックスに書き込む
if len_e <= maxlen_e and len_d <= maxlen_d :
enc_input[j,0:len_e] = mat_urtext[delimiters[index1]+1:delimiters[index2],0].T
dec_input[j,0:len_d] = mat_urtext[delimiters[index2]:delimiters[index3],0].T
target[j,0:len_d] = mat_urtext[delimiters[index2]+1:delimiters[index3]+1,0].T
j += 1
if i % 1000000 == 0 :
print(i)
#会話文データを書き込んだ分だけ切り出す
e = enc_input[0:j,:].reshape(j,maxlen_e,1)
d = dec_input[0:j,:].reshape(j,maxlen_d,1)
t = target[0:j,:].reshape(j,maxlen_d,1)
print(e.shape,d.shape,t.shape)
# シャッフル処理
z = list(zip(e, d, t))
nr.seed(12345)
nr.shuffle(z) #シャッフル
e,d,t=zip(*z)
nr.seed()
e = np.array(e).reshape(j,maxlen_e,1)
d = np.array(d).reshape(j,maxlen_d,1)
t = np.array(t).reshape(j,maxlen_d,1)
print(e.shape,d.shape,t.shape)
#--------------------------------------------------------------------------*
# *
# 作成したエンコーダ/デコーダ入力テンソル、ラベルテンソルをセーブ *
# *
#--------------------------------------------------------------------------*
#Encoder Inputデータをセーブ
with open('e.pickle', 'wb') as f :
pickle.dump(e , f)
#Decoder Inputデータをセーブ
with open('d.pickle', 'wb') as g :
pickle.dump(d , g)
#ラベルデータをセーブ
with open('t.pickle', 'wb') as h :
pickle.dump(t , h)
#maxlenセーブ
with open('maxlen.pickle', 'wb') as maxlen :
pickle.dump([maxlen_e, maxlen_d] , maxlen)
# *******************************************************************************
# *
# メイン処理 *
# *
# *******************************************************************************
if __name__ == '__main__':
import numpy.random as nr
import pickle
import numpy as np
import sys
args = sys.argv
#args[1] = 50 # jupyter上で実行するとき用
#args[2] = 50 # jupyter上で実行するとき用
generate_tensors(int(args[1]) ,int(args[2]))
コードの実行は、3-3節、3-4節と同じフォルダ上で、以下のようにコマンド起動します。
今回は引数があります。エンコーダ系列長、デコーダ系列長を指定するようになっていますので、適当な値を指定してください。以下の例では、双方とも20を指定してあります。
$ python generate_data.py 20 20
系列長というのは、入力文章長の最大値です。この値以下のデータを、エンコーダインプット等に右詰めで設定します。
系列長を絞り込んだため、訓練データサイズは小さくなります。今回の場合、もともとのデータ量は100万以上の会話対がありましたが、出来上がった訓練データは約30万対です。
ここまでの処理で、ニューラルネットワーク訓練のためのデータが、すべてそろいました。
4. 訓練
準備したデータを使って、ニューラルネットワークを訓練します。対象となるニューラルネットワークは、こちらの記事のものです。
ただし、そのままだとメモリが足りなくてResourceExhaustedErrorが発生するので、3-2-4節のバッチサイズbatch_size と隠れ層の次元n_hiddenを、以下のように変更しました。
batch_size = 80
n_hidden = int(vec_dim*1.5 ) #隠れ層の次元
次元を変更しましたので、以前作成したパラメータファイルがあると、次元不一致でエラーになります。以前のファイルはリネームするか、削除してください。
今回のケースでは、出力次元が10万を超え、また、訓練データ量も多いので、1epochあたりの処理時間がだいぶ大きくなっています。筆者の場合、1epochに5000秒ほどかかりました。
5. 学習結果
上記のとおり、系列データ長20、埋め込みベクトル次元400、隠れ層次元600という条件のもとで、訓練を実施しました。
応答文生成処理を実行するにあたっては、訓練データの文の切れ目を表すデリミタを、3-5節で変更しましたので、処理を記述するこちらのコードのdef response(self,e_input,length) :の中にある以下の行を
target_seq[0, 0] = word_indices['SSSS']
以下のように修正してください。
target_seq[0, 0] = word_indices['RESRES']
また、その少し先にある以下の行を、
if sampled_char == 'SSSS' :
以下のように修正してください。
if sampled_char == 'REQREQ' :
以下は28epoch訓練後の結果です。延べ36時間以上かかりました。
>> おはよう!
おはようサーンです!
>> こんにちは。
こんにちは。️。️。️。️。️。️。️
>> ご飯食べた?
私もご飯食べたい!
>> 今何してる?
私もキャッチャーしました!
>> それでは御免蒙りまするでござります。
私も混ぜてください。
前よりマシになったように見えます。
6. おわりに
以上、訓練データの量的拡大による応答文生成精度改善の試みについて、記述しました。訓練データ量を大きくすることにより、応答文作成精度は向上するように見えますが、以下のファクターにより、より多くの訓練時間を必要とするようになりました。
- 1エポックあたりのデータ量が多い
- 単語数が多くなるため、入出力次元が大きくなる
- メモリ制約から、バッチサイズを小さくする必要がある
引き続き訓練を継続して、さらなる精度改善を図るとともに、訓練時間を短縮する方法が無いか、検討してみます。
変更履歴
| 項番 | 日付 | 変更箇所 | 内容 |
|---|---|---|---|
| 1 | 2018/12/15 | - | 初版 |
| 2 | 2019/8/27 | 5章 | デリミタ変更に伴う、応答文生成処理の修正について追記 |