やること
Ubuntu 18.04(WSL)上にpysparkを試すための環境をさくっと用意する。
anacondaやpyenvは使用しないので、使いたい方は随時対応してください。
前提環境
Windows 10 Home
Ubuntu 18.04 LTS (WSL) インストールしたばかりの状態から開始
作る環境
Spark 2.4.6
Hadoop 2.7
Python3.6.9
jupyter-notebook
手順
まずはSparkのインストール
jdkをインストール
sudo apt-get update
sudo apt-get install -y openjdk-8-jdk
sparkをインストール
入れたいバージョンに応じて、各所変更すると吉。
wget http://ftp.riken.jp/net/apache/spark/spark-2.4.6/spark-2.4.6-bin-hadoop2.7.tgz
tar zxvf spark-2.4.6-bin-hadoop2.7.tgz
sudo mv spark-2.4.6-bin-hadoop2.7 /usr/local/
sudo ln -s /usr/local/spark-2.4.6-bin-hadoop2.7 /usr/local/spark
環境変数追加
あとで~/.bashrcの末尾に追記推奨。
ターミナル起動時に毎回追加なくて済む。
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
動作確認
spark-shell --master local[*]
こんな表示が出ればOK
Ctrl + D で脱出
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_252)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
次にPython3のインストールと設定
python3 インストール
既にあれば省略
/usr/bin/python3がパスになっている想定
sudo apt install python3
環境変数の設定
これもあとで~/.bashrcの末尾に追記推奨。
export PYSPARK_PYTHON=/usr/bin/python3
動作確認
pyspark --master local[*]
こんな表示が出ればOK
これでpysparkが使える。
Ctrl + D で脱出
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Python version 3.6.9 (default, Apr 18 2020 01:56:04)
SparkSession available as 'spark'.
>>>
jupyterのインストールと設定
pip3のインストール
既にあれば省略
sudo apt install python3-pip
jupyter-notebookをインストール
既にあれば省略
sudo apt install jupyter-notebook
環境変数の設定
あとで~/.bashrcの末尾に追記推奨。
ipは好きに変えてOK。
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS='notebook --ip=127.0.0.1' pyspark
動作確認
pyspark --master local[*]
jupyter-notebookが起動して、アクセスできたらOK
適当なpython3ノートブックを作成して下記を実行してみる。
spark
下記のようになれば成功。
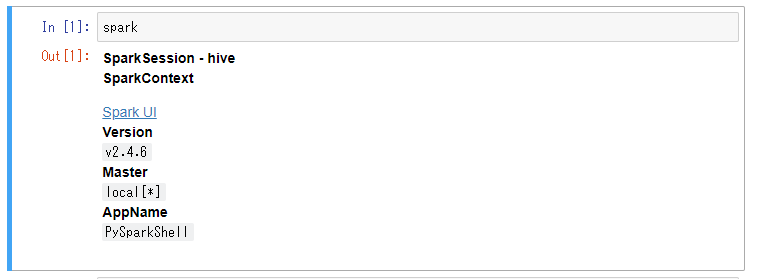
完了!
各環境変数の設定を~/.bashrcの末尾に追記しておくと今後が楽。
思う存分pysparkを試せばよい。