はじめに
可視化力を高めたい
kaggleのカーネルを読み込んでいると、皆さんデータを上手く可視化することで、重要な特徴量の発見や特徴量エンジニアリングに活かされています。自分もこんな感じでパッとかっこよくデータを可視化したい!!ということでseabornのライブラリを読み込んで使えそうなものをまとめてみました。
今回の範囲
seabornのcatplotというメソッドに絞ってまとめています。
kaggleのタイタニック生存問題のカーネルを読み込んでいると、非常に頻繁に出てくるため、有用なメソッドと判断しました。
参考
下記のseabornのドキュメントを参考にしています。
https://seaborn.pydata.org/generated/seaborn.catplot.html
データは下記のタイタニック問題のものを用いています。
https://www.kaggle.com/c/titanic/kernels?sortBy=voteCount&group=everyone&pageSize=20&competitionId=3136
catplot
catplotについて
catplotは質的変数(カテゴリカル変数)と量的変数の関係を上手く描画するためのインターフェイスになります。
様々なグラフの種類があるため、多様な表現が可能です。
また様々な属性のグラフを一気に描画するFacetGridというメソッドが既に組み合わされているため、
非常な簡単なコードで、多様かつ多数のグラフを表出することが可能です。
catplotの主な引数
| 引数 | 引数の説明 |
|---|---|
| x,y | プロットするデータを指定する。変数名を与える。 |
| hue | x,yで指定したデータのplotを、同一グラフ内でhueで指定したデータに分けてplotする。英語で色相を意味する。 |
| col | データのplotをcolに指定したデータに分け、横方向に別のグラフに分けてplotする。 |
| data | 参照するデータを指定する。DataFrame形式でもarray形式でもOK |
| kind | グラフの種類を指定、詳細は下記 |
主な引数はこんな感じです。
グラフ毎にそれぞれ固有の引き数があったりします。
catplotで描画できるグラフの種類
catplotで描画できるグラフは下記になります。
主に種別として「散布図」・「分布図」・「推定値の描画」の3つに分けられます。
Categorical scatterplots(散布図)
・stripplot() (with kind="strip"; the default)
・swarmplot() (with kind="swarm")
Categorical distribution plots:(分布図)
・boxplot() (with kind="box")
・boxenplot() (with kind="boxen")
・violinplot() (with kind="violin")
Categorical estimate plots(推定値の描画)
・barplot() (with kind="bar")
・countplot() (with kind="count")
・pointplot() (with kind="point")
以下それぞれのグラフの説明を行います。
catplotで描画できるグラフの説明
Categorical scatterplots(散布図)
主に、質的変数(カテゴリカル変数)と量的変数の二軸の散布図をplotする際に用いられるグラフ群です。
stripplot
stripplotでは1つのカテゴリに属するすべての点が量的変数の軸に対応してplotされます。
kindを指定しない場合、デフォルトでこちらのplotがなされます。
今回は例として、タイタニック生存問題のデータを用いて可視化します。
下記は質的変数としてチケットのクラスを、量的変数として年齢を指定してplotします。
sns.catplot(x = 'Pclass', y = 'Age', data = train, kind = 'strip')
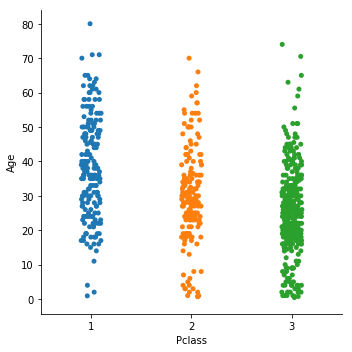
このような感じでplotされます。
データポイントが多くなる箇所は重なって見にくくなってしまいます。
swarmplot
基本はstripplotと同じですが、各データポイントが重ならないようにplotするものです。
形状が蜂の巣に似ていることから、"beeswarm(蜜蜂)"と呼ばれることもあるらしいです。
sns.catplot(x = 'Pclass', y = 'Age', data = train, kind = 'swarm')
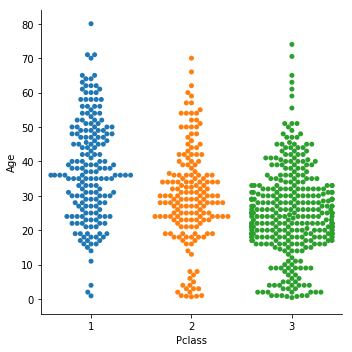
stripplotよりも各年齢でのボリューム層の違いが分かりやすくなっています。
チケットのクラスが良いほど年齢もあがっていく様子が見て取れます。
Categorical distribution plots:(分布図)
主に、質的変数(カテゴリカル変数)と量的変数の二軸の分布をplotする際に用いられるグラフ群です。
boxplots(箱ひげ図)
箱ひげ図のplotです。外れ値と四分位数を明示的にplotします。髭は第1四分位点と第3四分位点の間(四分位範囲)の距離を取り、箱の上下端からその長さの1.5倍をとった範囲をまで伸ばされます。
こちらもタイタニック生存問題のデータを使い、
質的変数としてチケットのクラスを、量的変数として年齢を指定してplotします。
sns.catplot(x = 'Pclass', y = 'Age', data = train,kind = 'box')
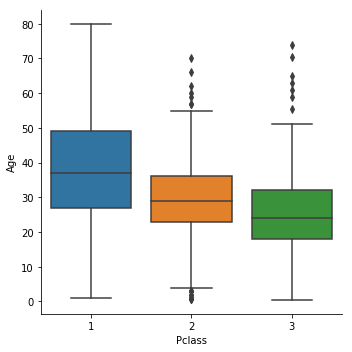
外れ値や中央値がわかりやすく見えるようになりました。
boxenplot
こちらは箱ひげ図の亜種のようなplotになります。
箱ひげ図より多くの分位数がplotされるので箱ひげ図よりも分布の形状について多くの情報を得ることができます。
(ただどの分位数でplotされているのかよくわらからず。。。ご存知の方、教えてください。)
sns.catplot(x = 'Pclass', y = 'Age',data = train, kind = 'boxen')
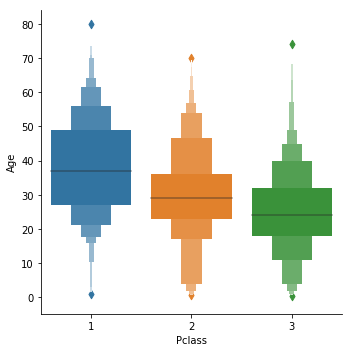
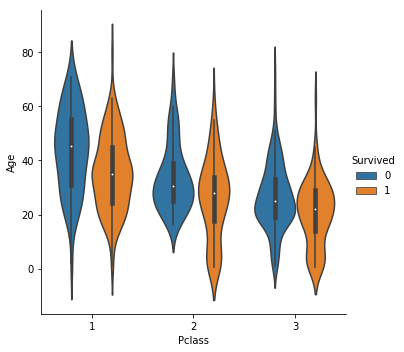
violinplots
こちらは、箱ひげ図にカーネル密度推定の値を組み合わせたplotになります。
カーネル密度推定のplotは軸上のデータポイントの密度を幅で表現してplotしたものです。
今回は変数hueにSurvivedを加えてみます。
sns.catplot(x = 'Pclass', y = 'Age',hue = 'Survived',data = train, kind = 'violin')
引数に「split = True」を加えることでもっと見易くすることができます。
sns.catplot(x = 'Pclass', y = 'Age',hue = 'Survived', split = True,data = train, kind = 'violin')
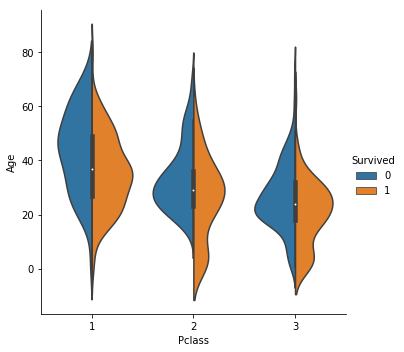
タイタニックで生き残った人と、死んでしまった人の年齢のボリュームゾーンの違いが明らかになりました。チケットのクラスによって分布の形が異なるという発見もできました。
Categorical estimate plots
各カテゴリ内の分布の表示ではなく、値が取る傾向の推定値を表示する際に用いられます。
barplot(棒グラフ)
x軸で指定されたカテゴリ毎の、y軸で指定された量的変数の推定値を取得します。
その推定値はデフォルトでは平均値を取り、引数で指定することで中央値など、他の値も取ることもできるようです。また、デフォルトではブートストラップ法という手法で推定値の信頼区間を求めているようです。棒線でその信頼区間が表現されます。
| 引数 | 引数の説明 |
|---|---|
| estimator | 推定値の種類を指定(デフォルトは平均値) |
| ci | 信頼区間の推定に関する引数。"sd"と指定すれば、ブートストラップ法を用いず、標準偏差の値が範囲としてplotされる。 |
今回はタイタニックデータを用い、チケットクラスのデータと、生存可否データを入れています。
こちらで、チケットクラスごとの生存率がplotされます。
sns.catplot(x = 'Pclass', y = 'Survived',data = train, kind = 'bar')
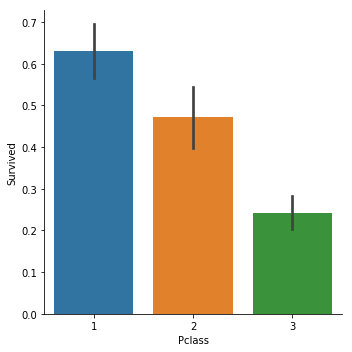
countplot
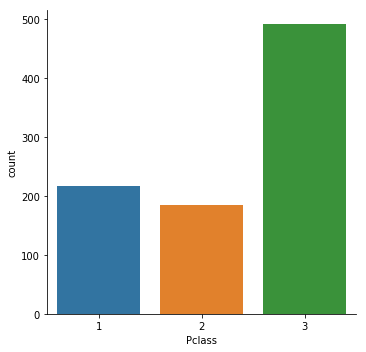
各カテゴリの数を観測したい場合に使用するplotです。
ヒストグラムに似たような形でplotされます。
カウント数をplotするので、与えるデータは1種類(x又はy)になります。
各チケットのクラスの数をplotします。
sns.catplot(x = 'Pclass', data = train, kind = 'count')
pointplot
barplotと同様に、x軸で指定されたカテゴリ毎の、y軸で指定された量的変数の推定値を取得します。
各カテゴリの推定値を点で繋ぐことで、値の違いをより明示的にします。
また、hueにデータを追加した時の比較がよりわかりやすくなります。
今回はboxplotに与えた変数に加えて、hueに性別データを加えて可視化します。
sns.catplot(x = 'Pclass', y = 'Survived', hue = 'Sex', data = train, kind = 'point')
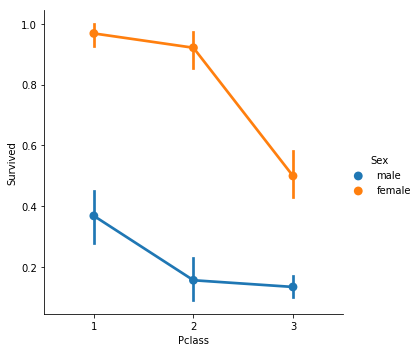
チケットクラスによらず、女性の方が生存率が高いことが見て取れます。
また、チケットのクラスが3になると女性でも大幅に生存率が低下することもわかります。
Next
色々なライブラリを理解し、自分の中で瞬時に書けるグラフのストックを増やしていく同時に、
グラフからデータの色んな特徴を発見できるようになっていきたいと思います。