はじめに
ナイーブベイズ分類器によるテキスト分類について理論を勉強した内容を以前の記事(ナイーブベイズ分類器(Naive bayes classifier)を用いたテキスト分類を理解する(理論編))でまとめました。今回はそのアルゴリズムを用いてニュース記事分類タスクをやってみます。また可能な限りライブラリを用いず、自力で実装することを目指します。
参考
ナイーブベイズの理解と実装に当たって下記を参考にさせていただきました。
- 言語処理のための機械学習入門 (自然言語処理シリーズ) 高村 大也 (著), 奥村 学 (監修) 出版社; コロナ社
- ナイーブベイズを用いたテキスト分類
- sklearnのナイーブベイズについてのドキュメント
- ニュース記事の分類を機械学習で予測する
ナイーブベイズを自力実装する
今回使用するデータ
データセットは「livedoor ニュースコーパス」を使用させていただきます。データのフォーマットは各記事ごとに下記のようになっており、テキストデータとしてダウンロードして使用できます。
1行目:記事のURL
2行目:記事の日付
3行目:記事のタイトル
4行目以降:記事の本文
今回は各記事がどのニュースサイトの記事であるのか分類するタスクに挑戦したいと思います。
まずサイトからフォルダをダウンロードして解凍します。
そのフォルダがカレントディレクトリに存在するとして、下記を実行してデータフレームに落とし込みます。
import pandas as pd
import numpy as np
import os
import pathlib
import glob
import re
p_temp = pathlib.Path('text')
article_list = []
# フォルダ内のテキストファイルを全てサーチ
for p in p_temp.glob('**/*.txt'):
#第二階層フォルダ名がニュースサイトの名前になっているので、それを取得
media = str(p).split('/')[1]
#テキストファイルを読み込む
with open(p, 'r') as f:
#テキストファイルの中身を一行ずつ読み込み、リスト形式で格納
article = f.readlines()
#不要な改行等を置換処理
article = [re.sub(r'[\n \u3000]', '', i) for i in article]
#ニュースサイト名・記事URL・日付・記事タイトル・本文の並びでリスト化
article_list.append([media, article[0], article[1], article[2], ''.join(article[3:])])
df = pd.DataFrame(article_list)
df.head()
するとこのような形で出力されます。

こちらのデータを利用してテキスト分類を行います。
理論編の復習
ナイーブベイズ分類器を利用するに当たって最終的に求めるのは下記でした。
\newcommand{\argmax}{\mathop{\rm arg~max}\limits}
\newcommand{\argmin}{\mathop{\rm arg~min}\limits}
\argmax_{cat} \Bigl( \log P(cat) + \displaystyle \sum_i \log p_{word_i,cat}^{n_{word_i,doc}} \Bigr)
- $ \log P(cat)$はその文書がカテゴリ$cat$である確率の対数を取ったもの
- $\displaystyle \sum_i \log p_{word_i,cat}^{n_{word_i,doc}} $は単語$word$がカテゴリ$cat$である時に$n$回出現する確率の対数を取り、各単語に関してそれを計算して全て足し合わせたもの。
詳細な解説は前回の投稿に記載しています。
それでは、上記を計算するプログラムを組んでいきます。
ナイーブベイズの実装
データの前処理
データをナイーブベイズ分類器にかけるに当たって、まずデータの前処理を行います。
前処理自体はsklearnのナイーブベイズ分類器を使用する際も同様に必要となります。
from datetime import datetime
# ニュース記事の本文を分かち書きする
l = []
for i, row in df.iterrows():
text = ' '.join(tkn.tokenize(row[4], wakati = True))
l.append([i, row[0], row[2], text])
df_wakati = pd.DataFrame(l)
# 日付で条件を絞るためにdatetime型に変換する
df_wakati[2] = pd.to_datetime(df_wakati[2])
# 2011年のニュース記事のみ抽出する
df_2011 = df_wakati[(df_wakati[2] >= datetime(2011, 1, 1)) & (df_wakati[2] < datetime(2012, 1, 1))]
自力実装
下記がナイーブベイズ分類器を自力実装した結果です。
sklearnのナイーブベイズに比べてかなり遅いのと、完全に同様の構造は再現できませんでした...
勉強したものをそのままコードに落とし込んだ勉強メモ程度のものになっていますが、ご了承ください。
class NB:
def __init__(self):
self.wordcount = None
self.category_count = None
self.wordlog_df = None
self.log_proba = None
self.result = None
def fit(self, x, y):
#単語数をカウントしてベクトル化する工程だけsklearnを使用
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(x)
#ベクトル化した単語をデータフレームの形式に落とし込む
df_words = pd.DataFrame(X.toarray(), columns = vectorizer.get_feature_names())
self.wordcount = pd.concat([df_words, pd.Series(y.reset_index(drop = True), name = 'カテゴリ分類')], axis = 1)
#分類する各カテゴリにどれくらいのデータ数があるのかをカウントする
category_count = pd.DataFrame(pd.Series(y, name = 'カテゴリ分類').value_counts())
#各カテゴリ数の割合を対数にとる
category_count['log'] = np.log(category_count['カテゴリ分類']/category_count['カテゴリ分類'].sum())
self.category_count = category_count
#各カテゴリにそれぞれの単語が何回出現するのかをデータフレームに落とし込む
x = []
for i in category_count.index:
all_words_count = self.wordcount[self.wordcount['カテゴリ分類']==i].sum().drop('カテゴリ分類').sum()
x.append([i ,all_words_count])
self.category_count = category_count.join(pd.DataFrame(x).set_index(0)).rename(columns = {1:'全単語数'})
import math
ddf = pd.DataFrame()
for i in self.category_count.index:
#各カテゴリのそれぞれの単語数をseries形式で表し、全ての単語数に1を足す。
df_temp = self.wordcount[self.wordcount['カテゴリ分類']==i].sum().drop('カテゴリ分類')+1
#各カテゴリのそれぞれの単語数+1をその総計で割り、対数を取る
temp = (df_temp/df_temp.sum()).apply(lambda x: math.log(x))
temp.name = i
ddf = pd.concat([ddf, temp], axis = 1)
self.wordlog_df = ddf
def predict(self, X):
dic_all = {}
X = X.reset_index(drop = True)
#予測したいそれぞれの文書がどのカテゴリに当たるのか、教師データを基に計算していく。
for x in range(len(X)):
dic = {}
for cate in nb.category_count.index:
x_list = re.findall(r'\b\w+\b', X.iloc[x])
try:
score = ddf[cate].loc[x_list].sum()
except:
score = 0
dic[cate] = score
if (x % 100) == 0:
print(x)
dic_all[x]=dic
self.log_proba = pd.DataFrame(dic_all).sort_index() .T + nb.category_count['log'].sort_index()
self.result = self.log_proba.T.idxmax()
def score(self, y):
#このアルゴリズムの精度を算出
self.score = (self.result == y).sum() / len((nb.result == y))
検証
上記の自力実装のモデルと、sklearnの結果が一致しているか検証します。
自力実装の結果
今回は「livedoor ニュースコーパス」の2011年度記事を教師データとし、2012年6月以降ニュース記事分類を行おうと思います。
nb = NB()
nb.fit(df_2011[3], df_2011[1])
df_other = df_wakati[df_wakati[2] >= datetime(2012, 6, 1)].reset_index(drop = True)
nb.fit(df_2011[3], df_2011[1])
nb.score(df_other[3], df_other[1])
print(nb.socre_)
するとこのように出力されます。
0.30748519116855144
正解率30%程度ということですね。精度自体は非常に微妙です。。。
sklearnの結果
sklearnのライブラリを用いて、ナイーブベイズ分類器を実装してみます。
from sklearn.feature_extraction.text import CountVectorizer
# 単語を出現回数でベクトル化するまでは一緒
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(df_2011[3])
rom sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB()
# 2011年度の記事データを教師データとして投入
clf.fit(X, df_2011[1])
test_X = vectorizer.transform(df_other[3])
# 正解率スコアを算出
print(clf.score(test_X, df_other[1]))
出力結果はこちら。
0.3139472267097469
0.4%ほど自力実装の結果と異なります。。
なぜ異なる結果が出るのか確認するため、計算過程の値を比較してみました。
# 各単語の各毎での出現確率を対数取ったもの(自力実装の方)
self_df = nb.wordlog_df.T.sort_values(by = '00').T
# 各単語の各毎での出現確率を対数取ったもの(sklearnの方)
sk_df = pd.DataFrame(clf.feature_log_prob_, columns = vectorizer.get_feature_names()).sort_values(by = '00').T
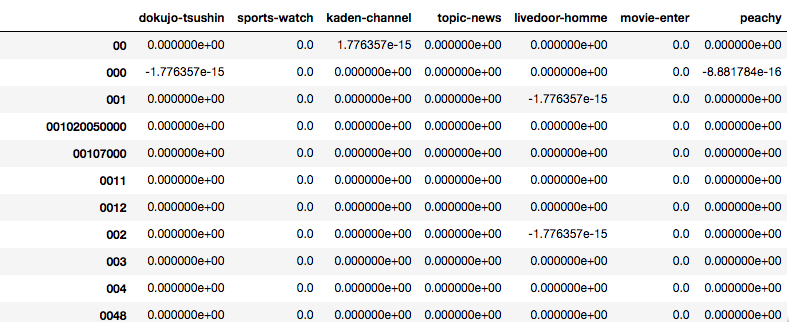
sk_df-self_df
データフレームを出力するとこんな感じです。
差がある値もありますが、小数点第15位レベルの差で丸め誤差かなと思います。
ちなみにこんな感じで入力しても。
print((abs(sk_df-self_df) > 0.0000000000001).sum())
出力はこんな感じです。
dokujo-tsushin 0
sports-watch 0
kaden-channel 0
topic-news 0
livedoor-homme 0
movie-enter 0
peachy 0
dtype: int64
Next
ほぼ、skelarnの処理を再現することができました。文書分類系のアルゴリムに興味があるので、他も色々勉強していこうと思います。