モチベーション
どんなときにSchedulerが複数いるのか?
事前学習済みモデルをヘッドだけ変えてファインチューニングするときなど,
バックボーンは細かい学習率でwarmupしたい.
でもヘッドはスクラッチだから最初から大きな学習率にしたい!!
よって,例えば次のように複数のSchedulerを使いたくなります.
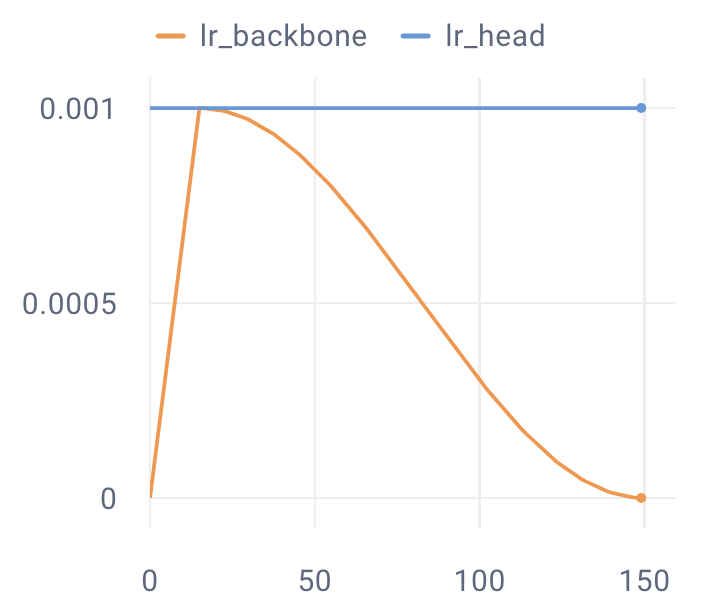
バックボーン:Warmup Cosine Decay LR Scheduler
ヘッド:Constant LR Scheduler
そこで便利なのがtorch.optim.lr_scheduler.LambdaLRです!
これを使うとパラメータグループごとに異なるstep関数を定義できるため,上記のニーズを満たすことが出来ます.
実装例
モデル
今回はbacknoneとheadをパラメータにもつModelを定義します.
import pytorch_lightning as pl
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.backbone = ...
self.head = ...
def forward(self, x):
x = self.backbone(x)
x = self.head(x)
return x
Lambdaの定義
LambdaLRに渡す各スケジューラに対応するstep関数を用意します.
今回は,
configure_warmup_cosine_decay_lambdaでWarmup Cosine Decayのstep
constant_lambdaでConstant LRのstep
を行う関数を実装します
def configure_warmup_cosine_decay_lambda(total_steps, warmup_steps):
def warmup_cosine_decay_lambda(current_step):
if current_step < warmup_steps:
# Linear warm-up
return float(current_step) / float(max(1, warmup_steps))
else:
# Cosine decay
progress = float(current_step - warmup_steps) / float(max(1, total_steps - warmup_steps))
return 0.5 * (1.0 + math.cos(math.pi * progress))
return warmup_cosine_decay_lambda
def constant_lambda(current_step):
return 1.0
OptimizerとSchedulerの作成
Optimizerはbackboneとheadで分割したパラメータグループを渡して作成します.
次に,各パラメータグループで使いたいstep処理として先ほど作った関数でbackbone_lambdaとhead_lambdaを作ります
最後にLambdaLRのlr_lambda引数にパラメータグループの順番に合わせて,lambdaをリストで指定したらSchedulerの完成です!
# モデル初期化
model = MyModel()
# Optimizer作成
backbone_lr = 1e-3
head_lr = 1e-2
optimizer = torch.optim.SGD(
[
{'params': model.backbone.parameters(), 'lr': backbone_lr},
{'params': model.head.parameters(), 'lr': head_lr}
],
momentum=0.9,
weight_decay=1e-4
)
# backbone用のstep関数を定義
total_steps = MAX_STEP
warmup_steps = int(0.1 * total_steps)
backbone_lambda = configure_warmup_cosine_decay_lambda(total_steps, warmup_steps)
# head用のstep関数を定義
head_lambda = constant_lambda
# schedulerを作成
scheduler = LambdaLR(
optimizer,
lr_lambda=[backbone_lambda, head_lambda]
)