※BitNetそのものを検証した記事ではなく,BitNetで使われているレイヤーを使った簡単なNNモデルを作成し検証しています.
はじめに
今回はBitNetの紹介になります.BitNetは量子化を考慮した学習を行うアーキテクチャとなっており,他の量子化手法と比べ競争力のある性能を保ちつつ,メモリ消費量を大幅に抑えています.
今回の検証ではBitNetで使われているBitLinearレイヤーを使いLanguage Modelではなくテーブルデータのための簡単なNNモデルを作り学習を行えるか検証しています.
記事に誤り等ありましたらご指摘いただけますと幸いです。
目次
1. BitNet
ライセンス:MIT
リポジトリ:https://github.com/kyegomez/BitNet
(今回検証に用いた実装であり,公式の実装ではないです)
論文:https://arxiv.org/abs/2310.11453
BitNetは8bit量子化やFP16 Transformerなどの量子化を行う新しいアプローチであり,Language Modelにおける実験の結果,メモリ消費を大幅に削減しつつ,従来の量子化手法に比べ競争力のある性能レベルを達成しています.
要点
- 主な貢献はBitLinearというレイヤーであり,それをMulti-Head AttentionおよびFeed-Forward Networkにも適用して作成したものがBitNet
- 8bitで順伝搬と逆伝播を計算し,重みの更新時は[-1,0,1]の値を使う
- 行列計算を乗算を使わずに加減算のみで計算を行う
- BitNetは量子化を考慮した学習方法となっており,従来の量子化のアプローチである学習済みのモデルを量子化する方法と異なり,今回の結果は量子化を考慮した学習方法の可能性を示している
- スケーリング則にも従うため今後はさらにBitNetをスケールアップしていく予定
実装
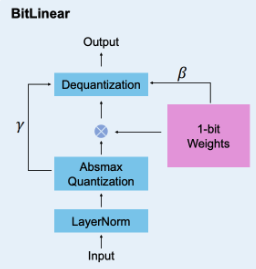
- BitLinear
BitLinearの計算フロー,具体的な計算方法は論文を参照してください.
from bitnet import BitLinear
layer = BitLinear(512, 400)
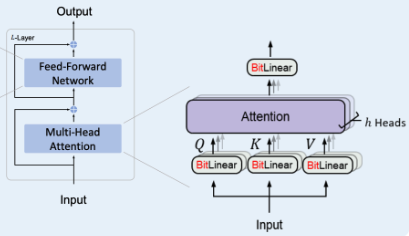
- BitNetTransformer
BitNetのMulti-Head Attention部分のアーキテクチャおよびコードです.
from bitnet import BitNetTransformer
bitnet = BitNetTransformer(
num_tokens=20000,
dim=512,
depth=6,
dim_head=64,
heads=8,
ff_mult=4,
)
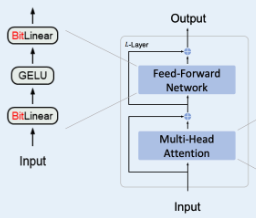
- BitFeedForward
BitNetのFeedForward部分のアーキテクチャおよびコードです.
from bitnet.bitffn import BitFeedForward
ff = BitFeedForward(512)
- BitNetのモデルの推論
通常のPytorchのモデルと同様に保存および呼び出しを行うことができます.
from bitnet import BitNetInference
bitnet = BitNetInference()
bitnet.load_model('../model_checkpoint.pth') #Download model
output_str = bitnet.generate("The dog jumped over the ", 512)
print(output_str)
2. BitLinearの検証
今回はTitanicデータセット(テーブルデータ)でBitNetの全結合層(BitLinear)を使い学習ができるかを検証しました.すぐに試したい方はColabのリンクから実行してみてください
![]()
以下のコマンドでインストール
pip install bitnet
必要なパッケージ
import seaborn as sns
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from torch.utils.data import DataLoader, TensorDataset
# 今回必要なもの
from bitnet import BitLinear
データセットの前処理.TitanicデータセットをNNモデルに入力できる形式に変更します.この辺りは特に工夫などしていません.
df = sns.load_dataset('titanic')
df = df[['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'fare']]
df['sex'] = df['sex'].map({'male': 0, 'female': 1})
df.dropna(inplace=True)
X = df.drop('survived', axis=1).values
y = df['survived'].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
X_train_tensor = torch.tensor(X_train, dtype=torch.float)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
X_test_tensor = torch.tensor(X_test, dtype=torch.float)
y_test_tensor = torch.tensor(y_test, dtype=torch.long)
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
BitNetを使った簡単なNNモデルの実装です.以下のようにBitLinearの層を追加することで簡単に組み込むことができます.
class BitNetModel(nn.Module):
def __init__(self):
super(BitNetModel, self).__init__()
self.fc1 = BitLinear(6, 64) # BitLinearのレイヤー
self.relu = nn.ReLU()
self.fc2 = BitLinear(64, 2) # BitLinearのレイヤー
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
model = BitNetModel()
以下のコードで学習を行います.今回は100エポックで学習を回しました.
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 100
for epoch in range(num_epochs):
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
with torch.no_grad():
correct = 0
total = 0
outputs = model(X_test_tensor)
_, predicted = torch.max(outputs.data, 1)
total += y_test_tensor.size(0)
correct += (predicted == y_test_tensor).sum().item()
print(f'Accuracy: {100 * correct / total:.2f}%')
以下は結果になります.特徴量作成などしっかり行っておらず特に工夫していなかったので精度は77%ぐらいになりました.BitNetも同じぐらいの精度が出ており通常のモデルと同様に学習が行えることが確認できました.
- 通常のNNモデルのAccuracy:77.62
- BitLinearに置き換えたNNモデルのAccuracy:76.22
4. おわりに
今回はBitNetの紹介と簡単な検証を行いました.今回紹介したOSSのBitNet(BitLinear)はPytorchのNNモデルの実装に簡単に組み込むことができ,通常のモデルと同じように学習を行うことができました.今後はLanguage Modelなどを実装し,どれぐらいの精度を出すことができるか検証していければと考えています.
最後までお読みいただきありがとうございます.記事に誤り等ありましたらご指摘いただけますと幸いです。