株式会社ブレインパッドでデータサイエンティストをしている@fuyu_quantです。
この記事はBrainPad Advent Calender 2023 1日目の記事です。
※記事シリーズは2もあります!!
はじめに
今回はLanguage Model Inversionという論文が非常に面白かったので紹介をしたいと思います.
簡単に内容を説明すると
- LLMの出力をする際の確率分布が分かれば元のプロンプトを復元できる
- さらにLLMの出力のテキスト情報しかなくても元のプロンプトを復元できる
ということについても言及しています.
※実行コードについては執筆途中です.
目次
- 0. LLMの出力
- 1. Language Model Inversionの解説
- 2. Language Model Inversionを試す(コードの解析ができたら追記します)
- 3. おわりに
- 4. 参考文献
0. LLMの出力
論文の紹介に入る前に,LLMの出力について簡単に説明します.(追記します)
1. Language Model Inversionの解説
何をしたいか
LLMの出力結果だけから,どうにかもとの入力プロンプトを復元できないか?ということに取り組んでいます.以下の図のようなことをしたいイメージです.(論文引用)
ジェイルブレイクなどにも関連する話題です!
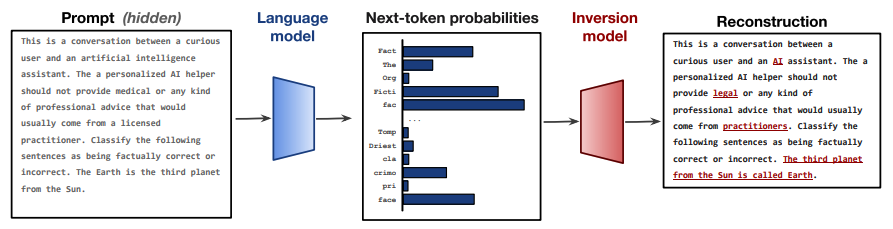
そのためには,真ん中の「Next-token probablities」に直前のテキストに関する情報が少しでも含まれている必要があります.ではそのような情報は含まれているのでしょうか???
本当に入力プロンプトを予測できるか?
LLMの出力がどれぐらい入力したプロンプトに関する情報を含んでいるかについて検証する方法を考えます.
まず初めにいくつかのテキストデータを用意します.そのテキストデータの一部を同義語に置き換えたテキストデータも用意します.
- この状態で2種類のテキストデータをLLMに入力し,出力の確率値(確率分布)を得ます
- この確率分布間のKLダイバージェンスとビットレベル・ハミング距離を計算します
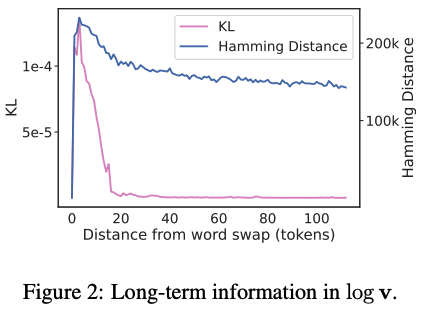
結果は以下のグラフのようになりました.
-
ハミング距離の解釈
LLMに入力されたテキストに関する情報がほとんど残っていなかったらハミング距離は入れ替えの位置から離れるにつれて0になります.それは,一部しか情報を入れ替えていないため入れ替え部分の情報がなくなっていたら同じ確率分布になってしまうためです.しかし,実際にはハミング距離は0になっておらず入力したテキストの入れ替えた箇所の影響が残っていると考えられます. -
KLダイバージェスの解釈
KLダイバージェスは確率値が高い箇所が一致している分布間で計算すると低くなる傾向があります.図より,KLダイバージェンスはテキストデータを入れ替えた箇所のすぐ後に非常に小さい値になっており二つのテキストによるLLMの出力の確率値が高い箇所がほとんど一致していることを示しています.つまり,出力される文章はほとんど同じような文章が出力されることになります.これは当たり前ですよね!一部分しか文章を変えておらず,しかも類似している言葉で置き換えているので当然の結果です. -
考察
以上より,一部を類似している言葉で置き換えた文章を入力して確率値を比較すると最も確率値が高い値はほとんど変わっていないが分布の形状は違うものになっているということになり,
LLMが出力する確率値(確率分布)には前の情報が含まれているのではないか?
と考えることができます.
予測方法
ここでは実際に入力プロンプトを復元するためのInversionモデルを作成する方法を説明します.
- モデル:エンコーダ・デコーダモデルのT5を利用します.
- 入力データ:LLMが出力した確率ベクトルを入力します.ただ,確率ベクトルをそのままモデルに入力すると次元数が大きいことと,ソフトマックスを通過している(非常に小さい値が存在するから?)ので対数変換して全結合層を通し擬似的な埋め込み表現に変換する処理を挟んでいます.
上記の処理を行った入力データと元の入力プロンプトが近くなるように学習を行います.式にすると以下のようになります.
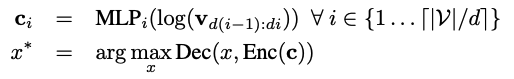
結果
-
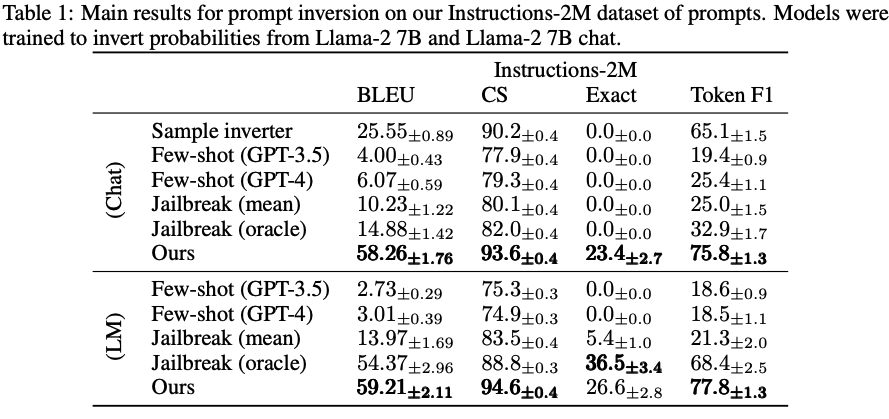
実行結果の精度
BLEUスコアは文章の一致度を測る指標として使われるのですが,Jailbreakを行った結果より高い精度で入力プロンプトを復元できていることが分かります.
- 実行結果の例
元の入力されたプロンプトをだいぶ高い精度で復元できていることが分かります.

結論
今回できたこととしては主に以下の三つです.
- LLMの出力する確率分布が分かれば,入力プロンプトを予測できる.
- モデルへ十分なアクセスができれば,モデルが出力する確率分布を再構築できる.(今回は説明していません)
- 上記二つより,LLMの出力からも入力プロンプトを予測できる.
セキュリティとプライバシーの観点では以下のように説明しています.
- LLMへ十分な数のアクセスができる場合に入力プロンプトを保護する唯一の方法は最も確率値が高い値へのアクセスを無効にし、温度を0に設定することでこの手法を防ぐことができるそうです.
2.Language Model Inversionを試す(コードの解析ができたら追記します)
上記のプロンプトを推定するコードは全て以下のリポジトリにあるみたいですが,すぐに使えるようになっていないみたいなので,使い方の確認ができた際に加筆していこうと思います.
3. おわりに
今回はLanguage Model Inversionの紹介でした.
実行まで紹介したかったのですが現状まだ使い方分からないため,確認が出来次第追記したいと思います.
最後までお読みいただきありがとうございます.記事に誤り等ありましたらご指摘いただけますと幸いです。