はじめに
こんにちは、fuyu-quantです.
今回はScikit-LLMの紹介になります.Scikit-LLMはLLMをscikit-learnのように実装し扱うことができます.特に,In-Context Learningなどが非常に簡単に実装することができるようになります.
目次
1. Scikit-LLM

LLMをscikit-learnのように使うことができるOSSです.現在の実装だと文章分類,文章埋め込み,文章要約に対応しているみたいです.文章分類はZero shotでの文章分類が実装されていますが,今後はFew shotでの文章分類も実装されるそうです.また.GPTのFine-tuningも実装予定だそうです.
以下のコマンドでインストールします.
pip install scikit-llm
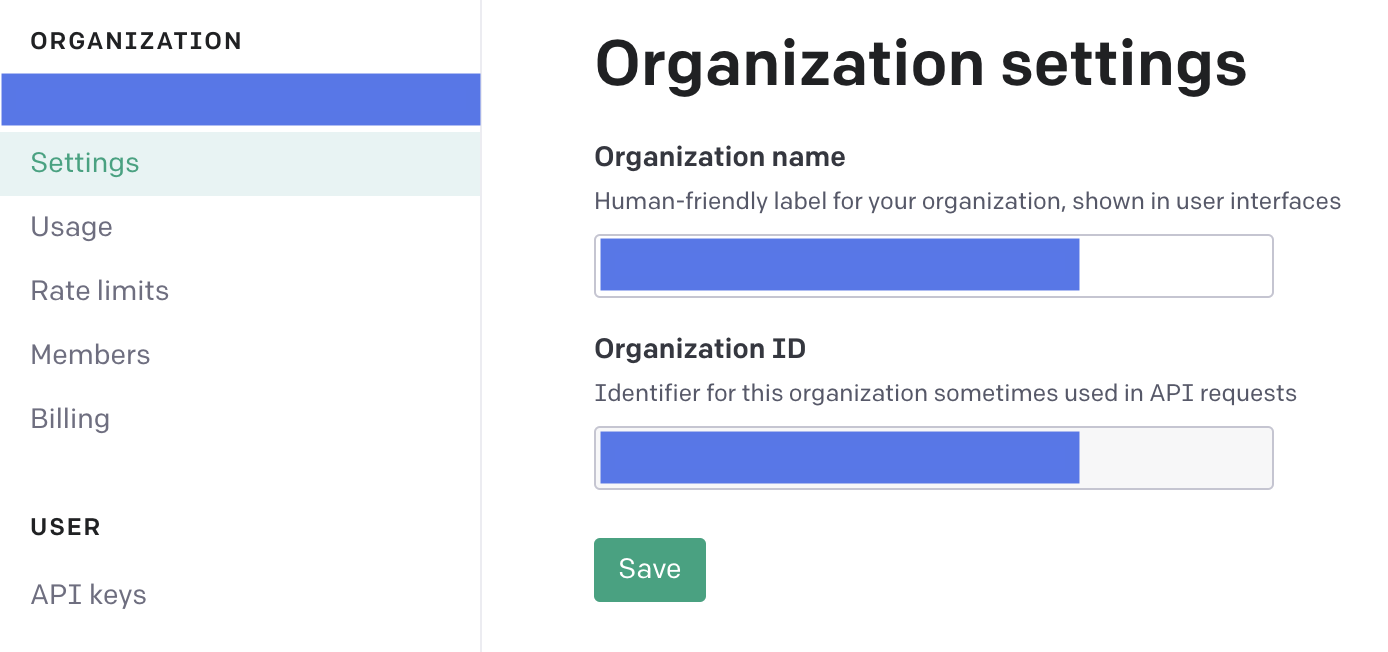
OpenAI APIのkeyだけでなく,Oraganization IDも必要になります.
from skllm.config import SKLLMConfig
SKLLMConfig.set_openai_key("YOUR_API_KEY")
SKLLMConfig.set_openai_org("YOUR_ORG_ID")
Oraganization IDはここから確認することができると思います.
2. 文章分類
![]()
実装例
現在はZeroShotGPTClassifierとMultiLabelZeroShotGPTClassifierが実装されています.
ZeroShotGPTClassifier(ラベルあり)
パラメータを変えるような学習をせずに,入力されたデータとそのラベルからIn-Context Learningにより新しく入力されたデータのラベルを予測します.
from skllm import ZeroShotGPTClassifier
from skllm.datasets import get_classification_dataset
# データセットの用意
X, y = get_classification_dataset()
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2, random_state=42)
clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
clf.fit(train_X, train_y)
labels = clf.predict(test_X)
print(test_y)
print(labels)
#['neutral', 'negative', 'neutral', 'negative', 'positive', 'positive']
#['neutral', 'negative', 'neutral', 'negative', 'positive', 'positive']
ZeroShotGPTClassifier(ラベルなし)
In-Context Learningをせずに設定したラベルのどれに近いかを予測します.内部でプロンプトにより分類するように指示を出していると考えられます.
clf = ZeroShotGPTClassifier()
clf.fit(None, ["positive", "negative", "neutral"])
labels = clf.predict(test_X)
print(test_y)
print(labels)
#['neutral', 'negative', 'neutral', 'negative', 'positive', 'positive']
#['neutral', 'negative', 'neutral', 'negative', 'positive', 'positive']
MultiLabelZeroShotGPTClassifier(ラベルあり)
ZeroShotGPTClassifier(ラベルあり)同様に入力データとそのラベルを与え,In-Context Learningにより新しく入力されたデータのラベルを予測します.Multi-Labelなので複数のラベルがついている場合にも使うことができます.
与える最大のラベル数も設定することができます.
from skllm import MultiLabelZeroShotGPTClassifier
from skllm.datasets import get_multilabel_classification_dataset
# データセットの用意
X, y = get_multilabel_classification_dataset()
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2, random_state=42)
clf = MultiLabelZeroShotGPTClassifier(max_labels=3)
clf.fit(train_X, train_y)
labels = clf.predict(test_X)
print(test_y)
print(labels)
#[['Price', 'Quality', 'User Experience'], ['Delivery', 'Product Information']]
#[['Quality', 'Price', 'User Experience'], ['Delivery', 'Product Information']]
MultiLabelZeroShotGPTClassifier(ラベルなし)
ZeroShotGPTClassifier(ラベルなし)同様にIn-Context Learningせずに,データを与えるとそれに該当するラベルを設定したものの中から選びます.学習データがなくても好きなラベルを付与できるのでさまざまなシチュエーションで使えそうです.
与える最大のラベル数も設定することができます.
# 分類したいカテゴリーを設定
candidate_labels = [
"Quality",
"Price",
"Delivery",
"Service",
"Product Variety",
"Customer Support",
"Packaging",
"User Experience",
"Return Policy",
"Product Information",
]
clf = MultiLabelZeroShotGPTClassifier(max_labels=3)
clf.fit(None, [candidate_labels])
labels = clf.predict(test_X)
print(labels)
#[['Quality'], ['Quality'], ['Product Information'], ['Quality', 'Product Information'], ['Quality', 'Price'], ['Product Information']]
3. 文章埋め込み
![]()
実装例
入力されたテキストデータをベクトル化するだけです.
from skllm.preprocessing import GPTVectorizer
from skllm.config import SKLLMConfig
model = GPTVectorizer()
X = 'At the moment Scikit-LLM is only compatible with some of the OpenAI models. Hence, a user-provided OpenAI API key is required.'
vectors = model.fit_transform(X)
vectors
# 出力
array([[ 0.01540808, -0.01377206, 0.02419162, ..., -0.01770119,
-0.0189215 , -0.01774142],
[-0.01505723, -0.0093344 , 0.00871663, ..., -0.00832968,
-0.01054278, -0.00487086],
[-0.00680274, -0.03093406, 0.0051005 , ..., -0.01835304,
-0.01905268, 0.01175644],
...,
[-0.00259624, -0.02183674, 0.00317355, ..., -0.00505743,
-0.00448011, -0.00915603],
[ 0.00032323, -0.00951257, 0.00050189, ..., -0.01357419,
-0.00487926, -0.01633955],
[-0.00875203, -0.01686207, 0.00510972, ..., 0.00230101,
-0.02155253, -0.00867342]])
4. 文章要約
![]()
実装例
入力されたテキストを要約します.現状だとすごく要約に時間がかかる気がするのでLangChainなどでいいかもしれません.また,要約の最大単語数を設定することができ,出力結果を見る限りでは守られていると感じます.
from skllm.preprocessing import GPTSummarizer
from skllm.config import SKLLMConfig
from skllm.datasets import get_summarization_dataset
text = get_summarization_dataset()
summary_model = GPTSummarizer(openai_model = 'gpt-3.5-turbo', max_words = 15)
summaries = summary_model.fit_transform(text)
summaries
# 出力
array(['OpenAI launches GPT-4, a powerful language model for complex tasks.',
'John bought groceries and made a fruit salad for a get-together with friends.',
"NASA's 1996 Mars Pathfinder project successfully launched the first Mars rover, Sojourner.",
'Regular exercise improves memory and cognitive function in older adults, recommends 30 minutes daily.'])
summary_model = GPTSummarizer(openai_model = 'gpt-3.5-turbo', max_words = 100)
summaries = summary_model.fit_transform(text)
summaries
# 出力
array(['OpenAI has released GPT-4, a transformer-based language model that can perform complex tasks
like generating human-like text, translating languages, and answering questions. It is claimed to be
more powerful and versatile than its predecessors.',
'John bought groceries in the morning for a small gathering at his house, including apples,
oranges, and milk. He used the fruit to make a fruit salad for his guests in the evening.'])
5. おわりに
今回はScikit-LLMの紹介でした.データ分析をする上で使うこと多そうなシチュエーションでのGPT-3/4を使った実装が簡単にでき非常に使いやすいと思いました.特に文章分類(In-Context Learning)についてはプロンプトを書いたりせずにそのままの機械学習で使うようなデータセットを入力できるのでとてもいいと思いました.文章要約についてはどうしても処理時間が長い気がしたので今後アップデートしてほしいです.