初めに
このシリーズでは、機械学習や数理最適化などの数理モデルのざっくりとした理論と実装コードを紹介します.
今回紹介するのは,TabPFNというテーブルデータのためのTransformerモデルです.論文では「小さな表形式データに対して1秒以内に教師あり分類タスクを実行でき,ハイパーパラメータのチューニングがいらない高精度のモデル」と紹介されています.精度としてはOpenML-CC18というデータセットの中の30個のデータセットでGBDTの性能を上回ったほか,AutoMLに対して同等の精度を70倍の速度で達成したそうです.
論文:TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
目次
1. 概要
PFN(Prior-Data Fitted Networks)をもとに構築されており,ベイジアンニューラルネットワークと構造的因果モデルに基づき表形式データの根底にある複雑な特徴量の依存性と潜在的な因果構造をモデル化する事前分布を作り出すそうです.
1回のフォワードパスで新しい事前分布を確率的に推定するように事前に訓練されたTransformerで,小規模の分類タスク(サンプル数<1000,特徴量数100,10クラス)を1秒未満で解き,高い精度を達成しました.また,ニューラルネットワークやGBDTの帰納バイアスはL2正則化や木の深さの調整などのパラメータに依存しますが,TabPFNではそのような設定は不要だそうです.
実験結果では,XGBoost,LightGBM,CatBoostなどの分類アルゴリズムより精度が高く,AutoMLが5〜60分で達成できる性能と同等の性能を示したそうです.
「誰も信じてくれなさそうだから,オープンソースにするよー」だそうです.ありがとうございます!!
テーブルデータのNNモデルは結局GBDTには勝てないみたいなモデルがたくさんありましたからね〜
2. ざっくり理論
考え方
教師あり学習のベイズ的な枠組みでは,事前分布は入力$x$と出力ラベル$y$の関係に関する仮説(hypotheses)$\Phi$の空間を定義するそうです.また,仮説空間の各仮説$\phi\in\Phi$は,データセットを形成するサンプルを抽出するためのデータ分布を生成する機構とみなすことができるそうです.
構造的因果モデル(SCM:Structural Causal Models)に基づく事前分布を与えた場合,$\Phi$は構造的因果モデルの空間,仮説$\phi$は特定のSCM,データセットはSCMを通じて生成されたサンプルから構成されるものと考えられます.
また,$x_{test}$の事後予測分布(PPD:Posterior Predictive Distribution)は以下の式により,分類先のラベルに対する確率を与えるそうで
p\left(\cdot \mid x_{\text {test }}, D_{\text {train }}\right)
と表せます.ここで$D_{\text {train }}:=[(x_1, y_1), \ldots,(x_n, y_n)]$は学習データセットです.
このPPDは以下の式
p(y \mid x, D) \propto \int_{\Phi} p(y \mid x, \phi) p(D \mid \phi) p(\phi) d \phi
により求めることができるそうです.このPPDを求めることは一般的に困難なそうですが,PFNはサンプリングが可能な任意の事前分布を与えられるとPPDを近似的に求めることができるそうです.この時に構造的因果モデルに基づく事前分布を使うそうです.
SCMとPPDをしっかり理解していないとちゃんと理解できなさそうですね....
学習の方法
Synthetic Prior-fitting(合成事前適合?)
事前学習ではPFNは,生成メカニズム(仮説)を$\phi \sim p(\phi)$でサンプリングを行い,続いて$D \sim p(D \mid \phi)$で合成データセットのサンプリングが行われます.このような合成データセットを繰り返しサンプリングし,残りのデータセットの予測を行いその誤差を考慮してPFNのパラメータ$\theta$を最適化してい来ます.損失関数は分類問題なのでいつも通りクロスエントロピーを使います.
\mathcal{L}_{P F N}=-\underset{\left(\left\{\left(x_{\text {test }}, y_{\text {test }}\right)\right\} \cup D_{\text {train }}\right) \sim p(D)}{\mathbb{E}}\left[\log q_\theta\left(y_{\text {test }} \mid x_{\text {test }}, D_{\text {train }}\right)\right]
以下の図は論文にある学習の様子になります.
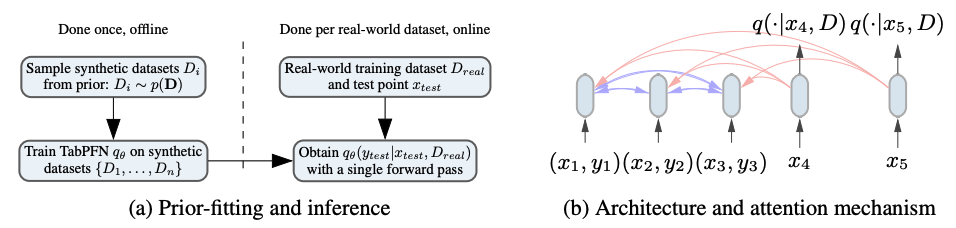
(a)はofflineで与えられた事前分布のPPDを近似し,onlineで一回のフォワードパスで新しいデータセットに対する予測している様子です.
(b)は学習の様子で,3つの学習データ${\left(x_1, y_1\right), \ldots,\left(x_3, y_3\right)}$をそれぞれトークンにし,互いにアテンションさせています,また予測するデータは学習データにのみアテンションするそうです.
生成メカニズムのサンプリング?など,まだよく分からないので理解が進んだら詳しく書き直したいと思います.
とにかく,GBDTやニューラルネットワークの学習とはかなり違い,ベイズ統計的な理論をベースに考えられたモデルみたいです.
3. 実装
実装例はGitHubにも公開しています.
実行環境は以下のような設定で行いました.公式のrequirements.txtを参考にしています.
!pip install tabpfn
!pip install torch==1.9.0
!pip install scikit-learn==0.24.2
!pip install numpy==1.21.2
今回はアヤメのデータセットを使い分類をしていこうと思います.TabPFNの利用は非常に簡単でsklearnのように実装していくことができます.
import numpy as np
import pandas as pd
import torch
from sklearn import datasets
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import train_test_split
# TabPFNに必要なのは以下の一行
from tabpfn.scripts.transformer_prediction_interface import TabPFNClassifier
学習データセットの用意
ris = datasets.load_iris()
x = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=3655)
TabPFNの学習
# GPUが使える場合は"cuda"を指定すると速くなる
device = "cuda" if torch.cuda.is_available() else "cpu"
# モデルの定義
# N_ensemble_configurationsは平均化された推定値の数(特徴量×クラス数で制限される)
# アンサンブル数を多くすると精度が高くなるが遅くなる
TabPFN_classifier = TabPFNClassifier(device = device, N_ensemble_configurations=4)
TabPFNを使った予測
# TabPFNの予測
y_pred = TabPFN_classifier.predict_proba(X_test)
出力結果
roc_auc_score(y_test, y_pred, multi_class = 'ovr')
# 0.99830745235157
# ハイパラチューニングをしていないLightGBMの結果
roc_auc_score(y_test, y_pred, multi_class = 'ovr')
# 0.9949223570547101
今回は,LightGBMより高い精度が出ていましたが他のデータセットではどのような結果になるのか分からないので試してみたいですね.より詳細な実験結果は論文を確認してみてください!
モデルの構造がGBDTやNNモデルとはかなり異なると考えられるため,学習した際に異なるデータの構造を捉えている可能性が高いと考えられます.なのでkaggleなどのコンペで分類タスクがあった際にアンサンブルの候補として使うとスコアが上がるかもしれません.
4. おわりに
最後までお読みいただきありがとうございます.今回はTransformerを使ったテーブルデータの分類用のモデルであるTabPFNの紹介でした.記事に誤り等ありましたらご指摘いただけますと幸いです.