はじめに
お久しぶりです。約1ヶ月ぶりの投稿です。
今僕は絶賛夏休み中で、愛知県のとあるWeb会社に毎日インターンとして通っているのですが、インターン先で僕のことをお世話してくださっている社員さんに、土日のうちに何か作ってきたら〜なんて言われてしまったので、今回はlinebotに挑戦してみました。
昔、一度作ろうとして挫折してしまっていたので、今回こそはしっかりやろうと決意して、なんとかリリースにまでに至りました。
作りたいもの
今回作りたいのは、国語辞書botです。
linebotって、現状どんなのがあるんだろうと調べていたところ、どうやら他言語翻訳系のbotなどは存在するのですが、国語辞書botを見つけることができなかったので、辞書系botのパイオニアになるべく、とりあえずは国語辞書botを作ってみることにしました。
国語辞書って意外と作りにくい
僕は基本的にpython教ですので、pythonで国語辞書APIみたいなのがないかを調べてみたところ、全然ない...。
リリースが終了していたり、有料のデータベースだったり。英語翻訳や英単語帳みたいなのを作っている人はよく見かけるけど、国語辞書を作っている人がなかなかいなかったのはこれが原因か...。
しかしながらこんなことで僕は諦めません。ないなら作ればいいのです。
かといって、広辞苑の1ページ目から順に手打ちで辞書を入力してくのは頭が悪すぎます。ということで、web上で使える無料の国語辞書をスクレイピングしちゃえ、という思考にたどり着くわけですね。今回はWeblioさんの辞書をスクレイピングさせていただきました。(念のため利用規約を確認しましたが、スクレイピングを禁止するような決まりは見当たりませんでした。)
とりあえず、作ったもの

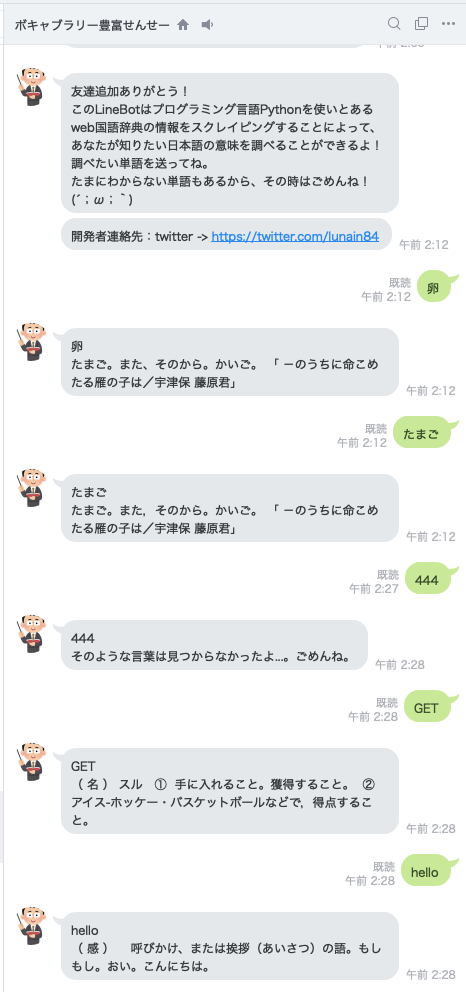
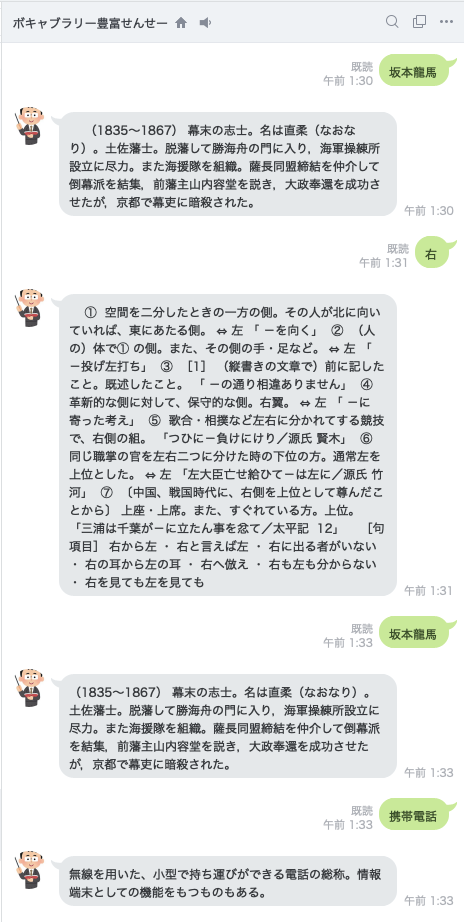
アカウント追加QR

環境
・MacBook Air (macOS Mojave)
・Python 3.6.8
工程
- linebotを作るのに必要なアカウント作成や、botの雛形のようなものん設定をLine developerから行う。
- Herokuの登録、環境構築
- pythonによる開発
- herokuにデプロイ
- テスト、調整
- qiitaを書く <-イマココ!!
いざ、bot作成開始!
やり方を詳しく書いてもよかったのですが、僕が参考にした記事で、僕より断然わかりやすい説明があるので、詳しくはこちらを読んでください(笑)
僕が詰まったところと、スクレイピング 部分だけをこの記事で解説しておきたいと思います。
参考にさせていただいた記事
PythonでLine bot 作ってみた
基本的には、すべてこの記事通りに作っています。スクレイピング部分は自作しました。
詰まったところ
環境変数のところ
環境変数にAccess Token とChannel Secretを設定する部分があったかと思います。
これらを環境変数に設定してからプログラム内で呼び出す理由は、pythonコード上に自分のAccess TokenやChannel Secretを書かなくていいということです。
誰かがプログラムを覗き見した時に、これらのkeyがむき出しで書かれていたら悪用されかねません。特に、有料版を使っている場合、悪用されるのは必ずさせたいところです。
このようなセキュリティの観点から、アクセスキーのようなものは環境変数に設定することが推奨されます。
しかしながら、今回僕は、何が悪いのか環境変数を全く読み込んでもらえず、使い物になりませんでした。
したがって、今回は仕方なくプログラム内に直書きしました。そうした場合該当箇所はこのようになります。
# YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"]
# YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"]
YOUR_CHANNEL_SECRET = "YOUR_CHANNEL_SECRET"
YOUR_CHANNEL_ACCESS_TOKEN = "YOUR_CHANNEL_ACCESS_TOKEN"
["YOUR_CHANNEL_SECRET"] や ["YOUR_CHANNEL_ACCESS_TOKEN"] の部分はご自分のものに変えてくださいね。
herokuの設定のところ
herokuの設定に関して、create <アプリケーション名>とする部分があるかと思います。
この部分で、僕は最初create line_japanese_dicとしていました。どうやら数字とアルファベット以外は使ってはいけないようです。
したがって今回はcreate linejapanesedicとしました。分かりにくいですけどね(笑)。
デプロイのところ
今回はスクレイピングを行うということで、参考サイトよりも使うライブラリが多いので、requirements.txtの内容を示しておきます。
Flask==0.12.2
line-bot-sdk==1.5.0
beautifulsoup4==4.7.
soupsieve==1.6.1
urllib3==1.24.1
lxml==4.3.4
加えて、git push heroku masterを打ち込んでコードをデプロイする時に、僕の場合はエラーが出ました。
$ git push heroku master
fatal: 'heroku' does not appear to be a git repository
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
こんな感じのエラーが出るときは、gitがリモートのリポジトリを参照できていない可能性が高いです。
vim や nano を使って、.git/configをのぞいてみると、
[remote "origin"]
url = https://hoge@bitbucket.org/hoge/hoge.git
fetch = +refs/heads/*:refs/remotes/origin/*
[branch "master"]
remote = origin
merge = refs/heads/master
こんな感じで、 remoteの参照先にherokuがないことがわかります。
したがって、リモートにherokuを追加しましょう。
コマンドで追加するのが簡単でいいかと思います。
git remote add heroku https://git.heroku.com/アプリケーション名.git
これで僕の場合はうまくいきました。
僕の出番。スクレイピング部分について
いよいよオリジナリティの部分です。
全体のコードは最後に載せますね。解説がいらなそうなら最後まで飛ばしてください。
スクレイピングとはいっても、今回はそんなに難しい処理はしていません。キーワードはCSSセレクタです。
スクレイピングの手順
- Lineから入力を受け取る
- 受け取った入力を追加したURLからrequestsでhtmlソースを取ってくる
- 取得したhtmlに対してCSSセレクタで言葉の定義部分を指定して切り出す
- 返信する
kwsk
さて、「おうむ返しbotを作ってみた」のような記事はたくさんありますが、実際どの部分で入力が受け取れるのか、どこで返信する言葉を指定するのかを明示的に説明している記事はあまり見受けられませんでした。ここがわかれば、皆さんも開発がしやすくなるのではないでしょうか。
今回のスクレイピング処理はあんまり長くならなかったので、すべてhandle_message()関数の中に入れてしまいました。その部分を示します。
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
word = event.message.text
url = "https://www.weblio.jp/content/" + word
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'}
r = requests.get(url, headers=headers)
html = r.text
bs = BeautifulSoup(html, 'lxml')
try:
meanings = bs.select_one("#cont > div:nth-child(6) > div > div.NetDicBody").text
except AttributeError:
meanings = "そのような言葉は見つからなかったよ...。ごめんね。"
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=word + '\n' + meanings.lstrip()))
そんなに変なことはしていないので、読めばわかる方も多いのではないでしょうか。
入力を受け取ってるのはword = event.message.textの部分です。僕もほとんどコードリーディングしていないので、詳しい仕組みはわかりませんが、今はevent.message.textに受け取った入力が格納されていると考えてください。
urlにはスクレイピング先のurlが入ります。 Weblioのurl構造は、https://www.weblio.jp/content/<調べたい単語>になっています。
したがって、受け取った入力を最後に挿入してあげるだけでOKです。
headerに関しては、指定しなくてもいいかもです。User Agentをヘッダーに乗せないとスクレイピングできないサイトもあるので、今後の開発の際、覚えておくと問題解決が早まるかもです。
r = requests.get(url, headers=headers)
html = r.text
bs = BeautifulSoup(html, 'lxml')
この部分で実際にサイトにリクエストを送ってhtmlコードを取得しています。今回はCSSセレクタを指定して該当部分をスクレイピングするのでBeautifulSoupを使っています。
try:
meanings = bs.select_one("#cont > div:nth-child(6) > div > div.NetDicBody").text
except AttributeError:
meanings = "そのような言葉は見つからなかったよ...。ごめんね。"
単語によっては検索に失敗する場合があるので、そこはtry-exceptで対処しています。
スクレイピングにおいては、たまにサイトのhtml構造が変わって、指定したクラスやセレクタが存在しない場合というのがよくありますので、例外処理は簡単でいいのでしておくことをお勧めします。今回のようなlinebotだと、スクレイピングが失敗すると答えは永遠に送られてこないので、答えが検索できなかった場合というのはしっかりと用意しておきましょう。
CSSセレクタについて
さっきからCSSセレクタという言葉を何度か発しましたが、CSSセレクタはスクレイピングにおいて取ってきたい要素をダイレクトに指定できるのですごく便利です。
CSSセレクタ取得手順 (Google Chrome)
- 取得したい要素のあるページを開く
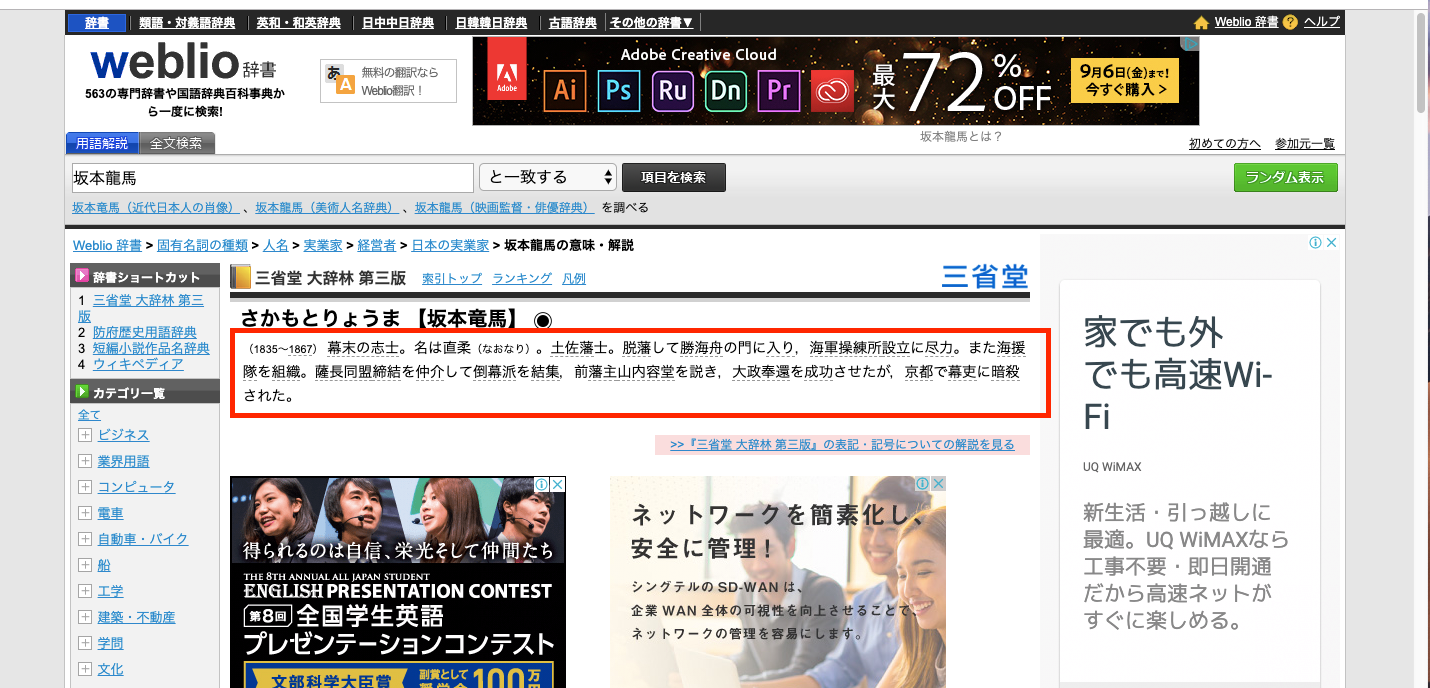
今回は赤で囲った部分を取得することを目指します。
2.デベロッパツールを開く
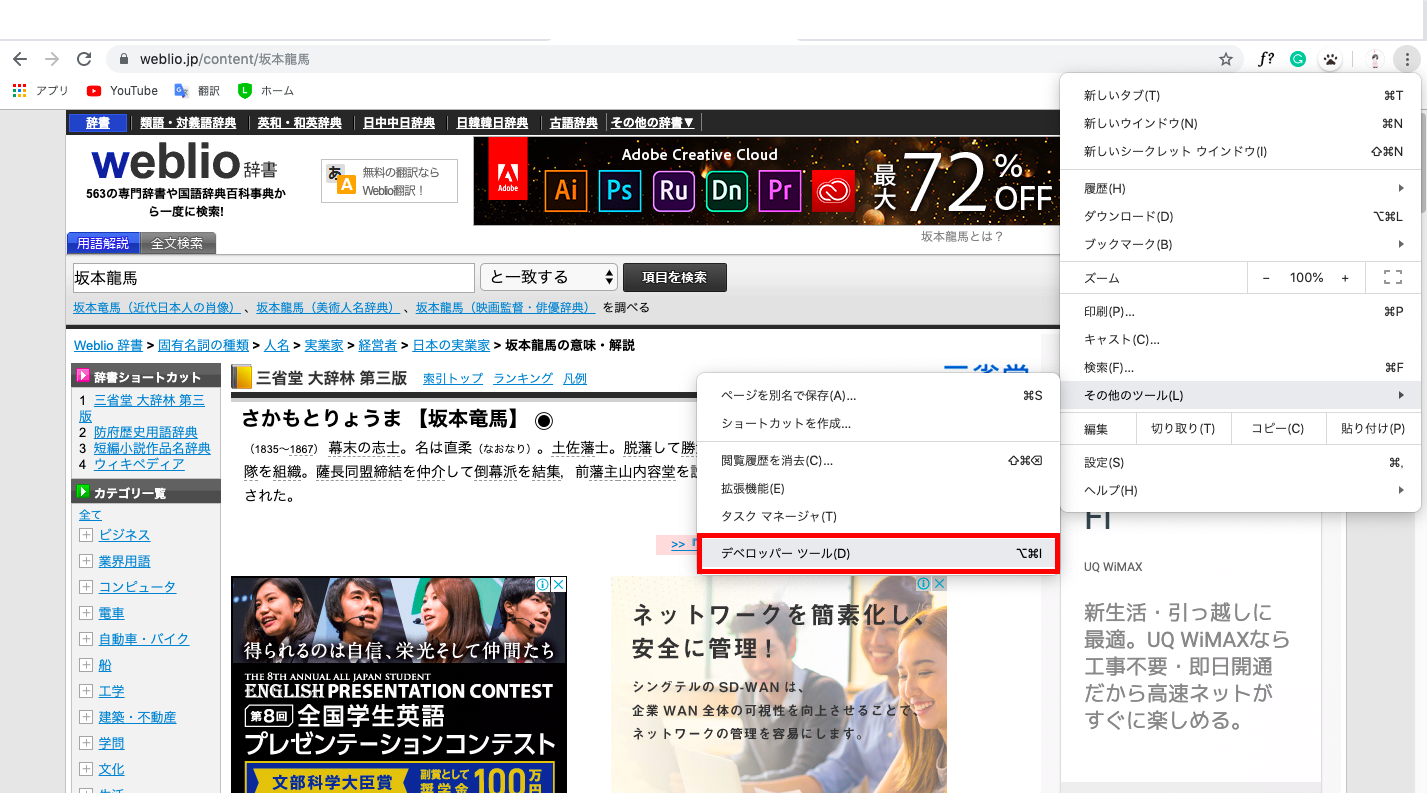
3. elementからスクレイピング部分のhtmlコードを探す
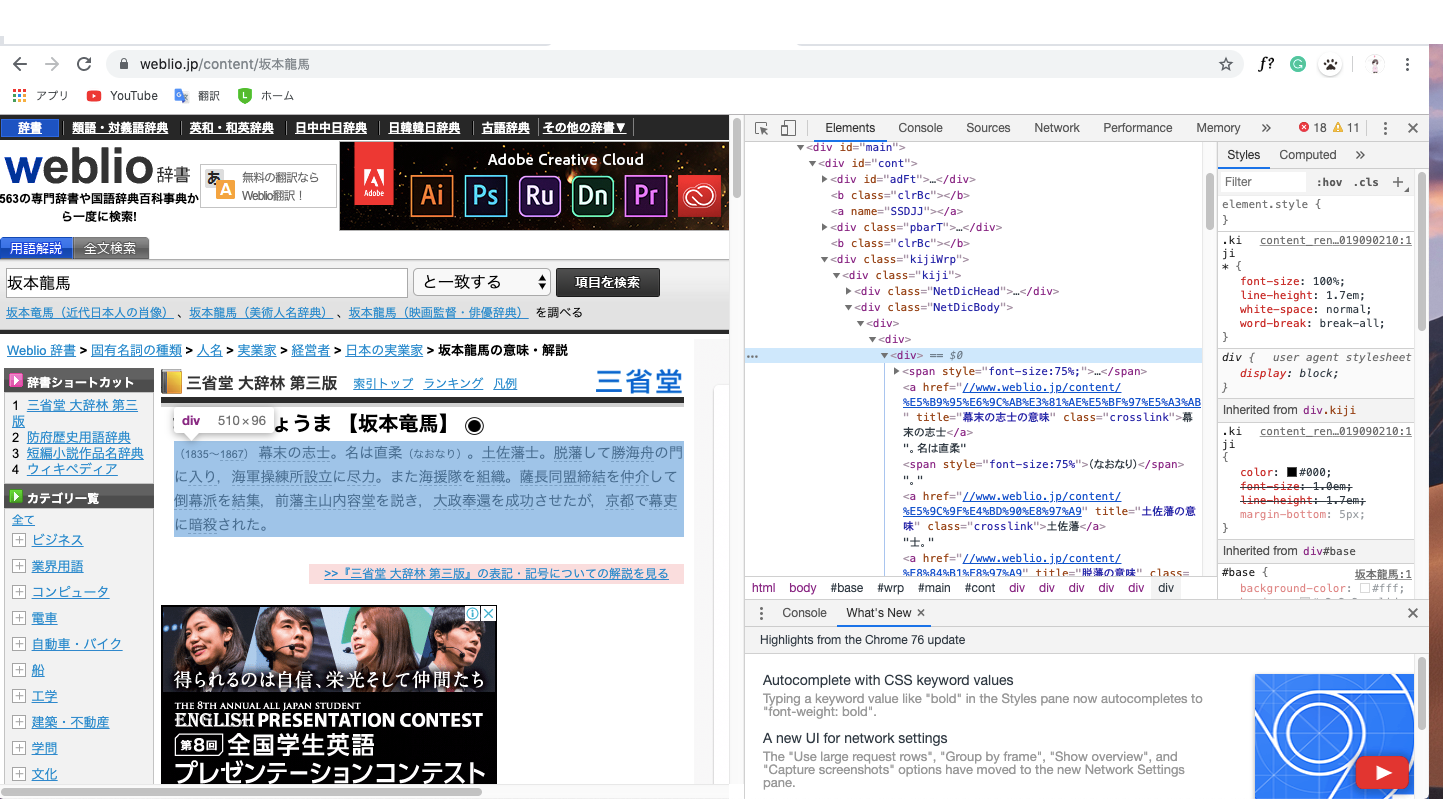
4.Copy -> Copy selectorでCSSセレクタをコピー
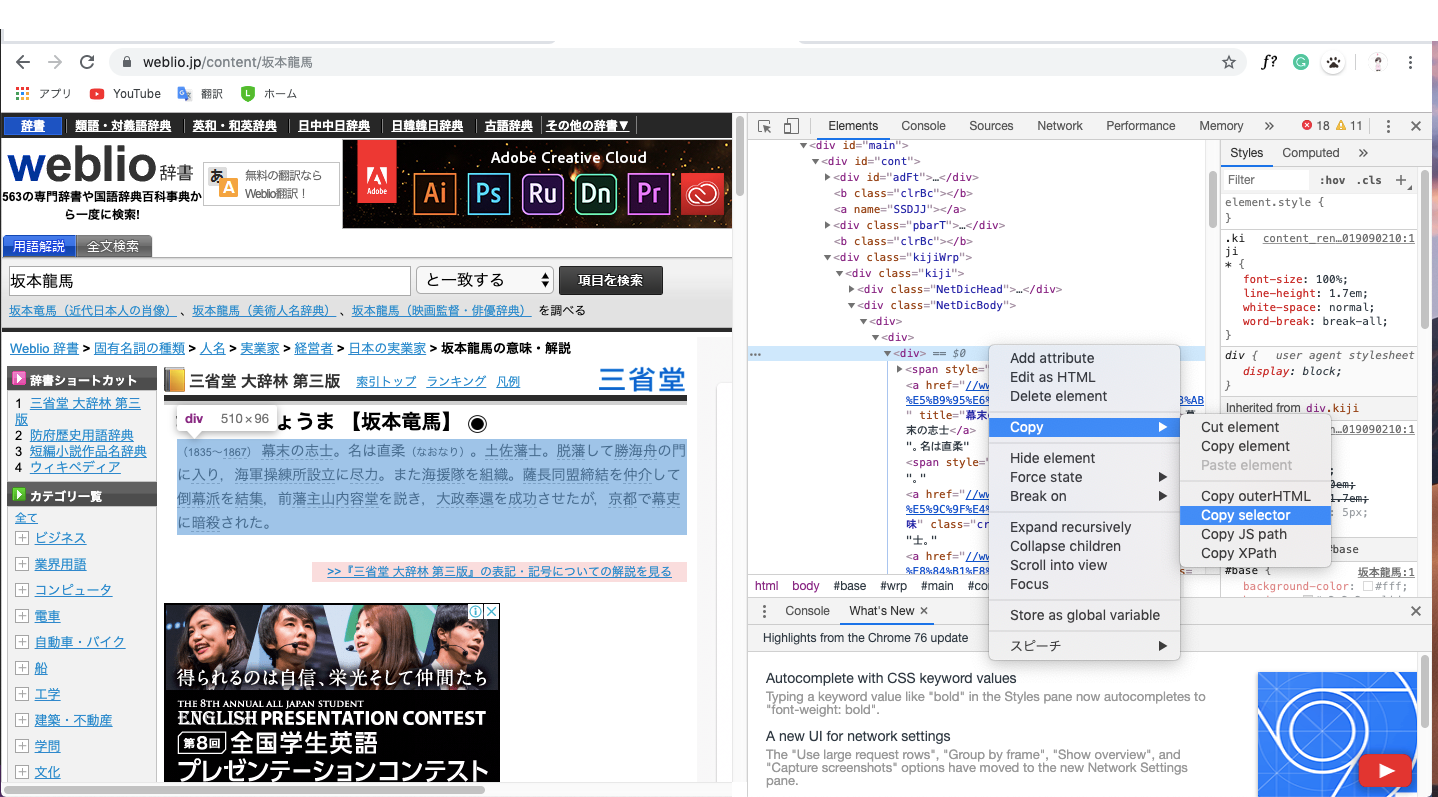
これでクリップボードにコピーされたはずです。
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=word + '\n' + meanings.lstrip()))
最後に、取得した単語の説明文を送信します。
送信する文章はTextSendMessage()関数内のパラメータtextに渡してあげましょう。
改行コードなどもちゃんと認識してくれます。
meanings.lstrip()部分は、スクレイピングした文章の先頭に空白が入ってしまっていたのでlstrip()関数で取り払っています。
これでうまく動かすことができました!
最後に
初めてのlinebot開発でしたが、調べながらの開発でもせいぜい3〜4時間くらいで開発完了したので、初心者の方でpythonで何か形になるものを作ってみたい方には適度な難易度なのではないでしょうか。
次は何かwebアプリを作ってみたいと考えています。
コメント、アドバイス、拡散、twitterのフォローよろしくお願いします!
国語辞書Linebot「ボキャブラリー豊富せんせー」作りました!
— ひろすぐ (@lunain84) September 2, 2019
技術的なこと👇https://t.co/BZG1XOjmcE
参考文献
PythonでLine bot 作ってみた (再掲)
Herokuにpush時にdoes not appear to be a git repository出た時の対処