はじめに
競プロ(AtCoder)をやっていると、配列の要素数や検索回数が大きい場合、重複削除目的ではなく高速化のために、配列(Array, List)をSetやMap(Rubyの場合Hash)に変換することはよくあります。
さて、実業務ではどうでしょうか?
実際に扱う配列の要素数、検索回数が$10^6$程度ということはそんなにないかもしれません。
むしろ、要素数や検索回数が100未満ということが多いのではないでしょうか?
では、この場合に、配列をSetやMap(or Hash)に変換する価値はあるのでしょうか?
もちろん、Set, Map(or Hash)になったものを、検索する速度が速いことはわかります。
しかし、SetやMap(or Hash)に変換するにもコストがかかります。
境界はどこでしょうか?
今回、Ruby, Javascript, Kotlinで、Set, Map(or Hash)の使用は要素数・検索回数がどれくらいだとArray(or List)より速いのか検証しました。
結論
検索値が数値の場合で以下に記載した条件の場合の結論です
JavascriptはBunで実行しています
実行環境や検索する値の型によっても境界は異なります
Set, Map(or Hash)に変換する意味がありそうな境界値
| 言語 | class#method | 配列の要素数 | 検索回数 |
|---|---|---|---|
| Ruby | Set#include? | 30 | 100 |
| Ruby | Hash#[] | - | 10 |
| Javascript | Set#has | - | 100 |
| Javascript | Map#get | - | 30 |
| Kotlin | Set#contains | 30 300 |
100 30 |
| Kotlin | Map#[] | 10 100 |
100 30 |
環境
- PC:MacBook Air M1 2020, メモリ 16GB, OS 14.6.1
- Ruby 3.2.2
- Bun 1.1.26(Javascriptの実行環境)
- Kotlin 1.8.20, SDK corretto18
- IntelliJ IDEA 2024.2.1 (Community Edition)
計測
方法
-
要素数 × 検索回数 の組み合わせに対し、それぞれ10回計測し、平均値をとりました
-
10回の計測は連続では行わず、かつその都度新たな
Array(orList)と検索値を作成しました -
Set,Map(orHas)に関しては、Array(orList)からの変換の時間も含めています -
Ruby,JavascriptはVSCodeのターミナルで、KotlinはIntelliJ IDEAで実行しました -
Javascriptの実行環境にはBunを使用しました1例:配列の要素数100個, 検索回数100回の場合のイメージ(10回実行し平均を取る)const array = [...Array(100)].map((_, i) => i); // Arrayの時間計測開始 for(let i = 0; i < 100; i++) { array.includes(i + 100); } // Arrayの時間計測終了 // Setの時間計測開始 const set = new Set(array); for(let i = 0; i < 100; i++) { set.has(i + 100); } // Setの時間計測終了 -
Array(orList) vsSet- 検索する値は配列の要素に存在しない値としました
- 配列の要素を数値(Integer)としました
- 配列の要素に重複なし
-
Array(orList) vsMap(orHash)- 検索する値は配列の要素に存在しない値としました
- 配列の要素に重複なし
- 配列の要素を以下のようなDTOとし、検索値をvalueとしました
Ruby
TargetObj = Struct.new(:value)Javascript{ "value": number }Kotlindata class TargetObj(val value: Int)
各言語の対象メソッドと計測ライブラリ
Ruby
対象メソッド
計測ライブラリ
-
benchmarkライブラリのBenchmark.realtimeを使用
Javascript
対象メソッド
計測ライブラリ
-
perf_hooksモジュールのperformance.nowを使用
Kotlin
対象メソッド
ArrayよりListを使用することが多いためListとの比較としました
計測ライブラリ
- measureNanoTime関数を使用
解析
-
Array(orList)の実行時間に対するSetorMap(orHash)の実行時間の比で表しました -
1未満の値であれば
SetorMap(orHash)の方がArrayより速いことになります - 解析には、
Python 3.11.9でpandas,matplotlib,seaborn等を用いました
結果
記載した条件のもと行った結果です
実行環境や検索する値の型によっても結果は変わります
Ruby
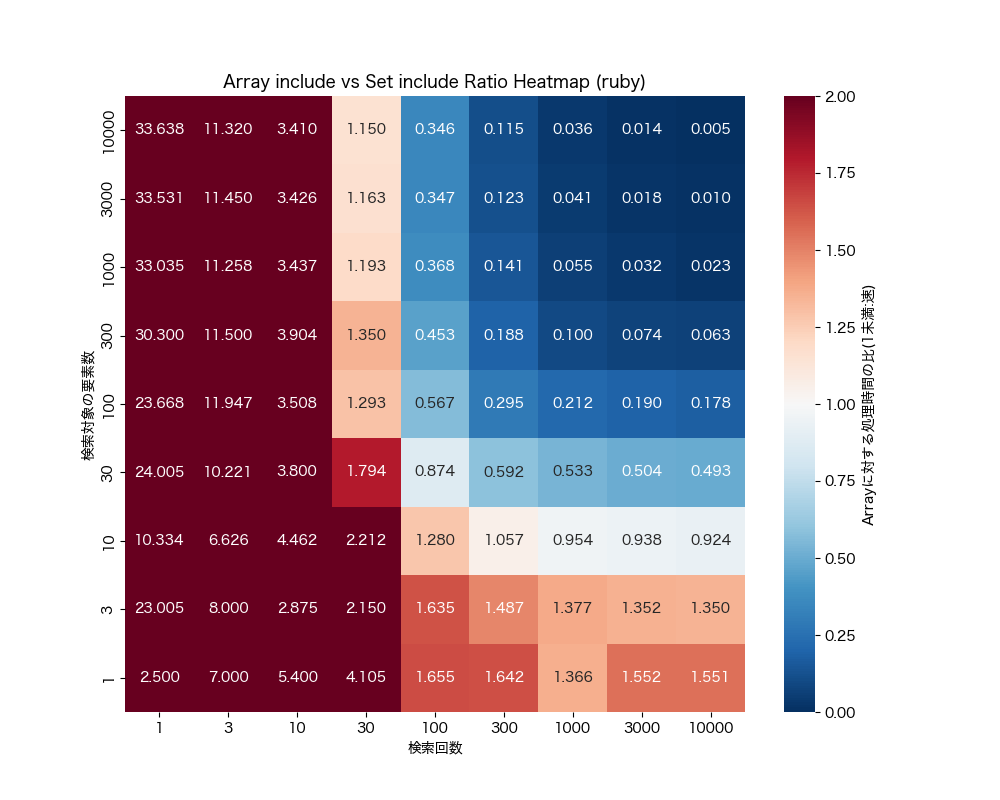
Array#include? vs Set#include?
- 配列の要素数が30以上、かつ検索回数が100回以上であれば
Setに変換しても良さそう
Array#find vs Hash#[]
- 10回以上検索するなら、
Hashに変換する方が良さそう
![array_find_vs_hash_[]_ratio_heatmap_ruby.png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F2493295%2Fe9b808e0-ce82-da1f-b1f4-6d567e7b29ec.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=62dc12cd749e9e4aff19c8d79f5b5639)
Javascript
Bun 1.1.26 で実行
Array#includes vs Set#has
- 検索回数が100回以上であれば配列の要素数に関係なく、
Setに変換する方が良さそう -
Setに変換した後での存在確認は当然ArrayよりもSetの方が断然速い


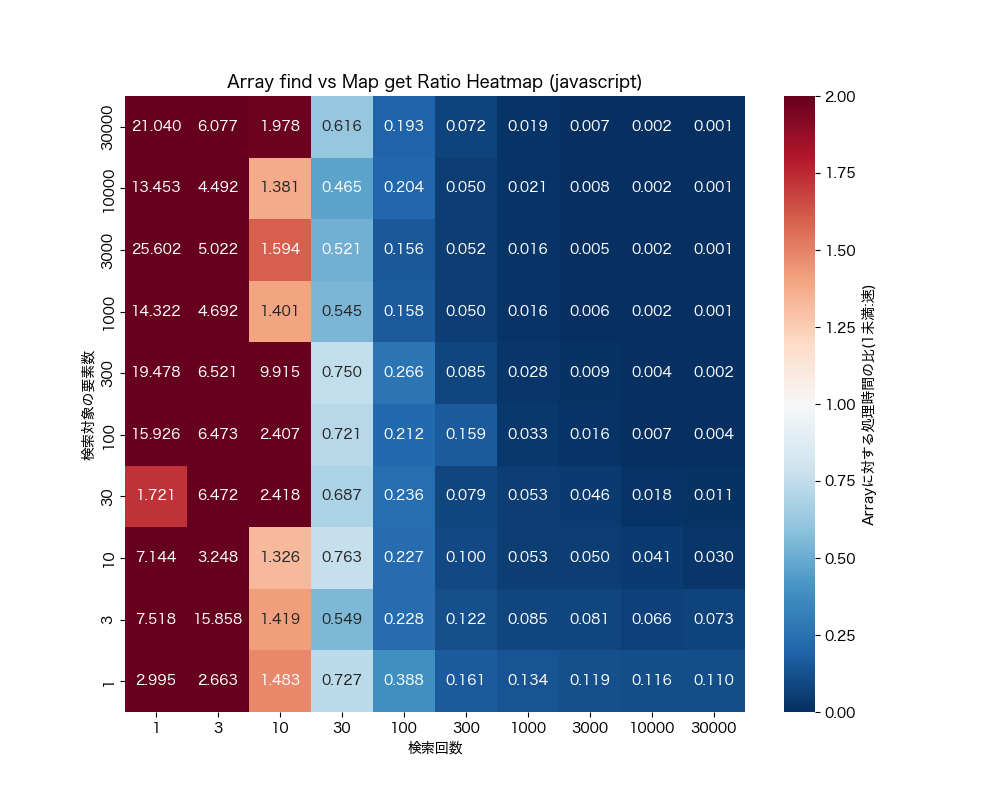
Array#find vs Map#get
- 30回以上検索するなら配列の要素数に関係なく、
Mapに変換する方が良さそう
Kotlin
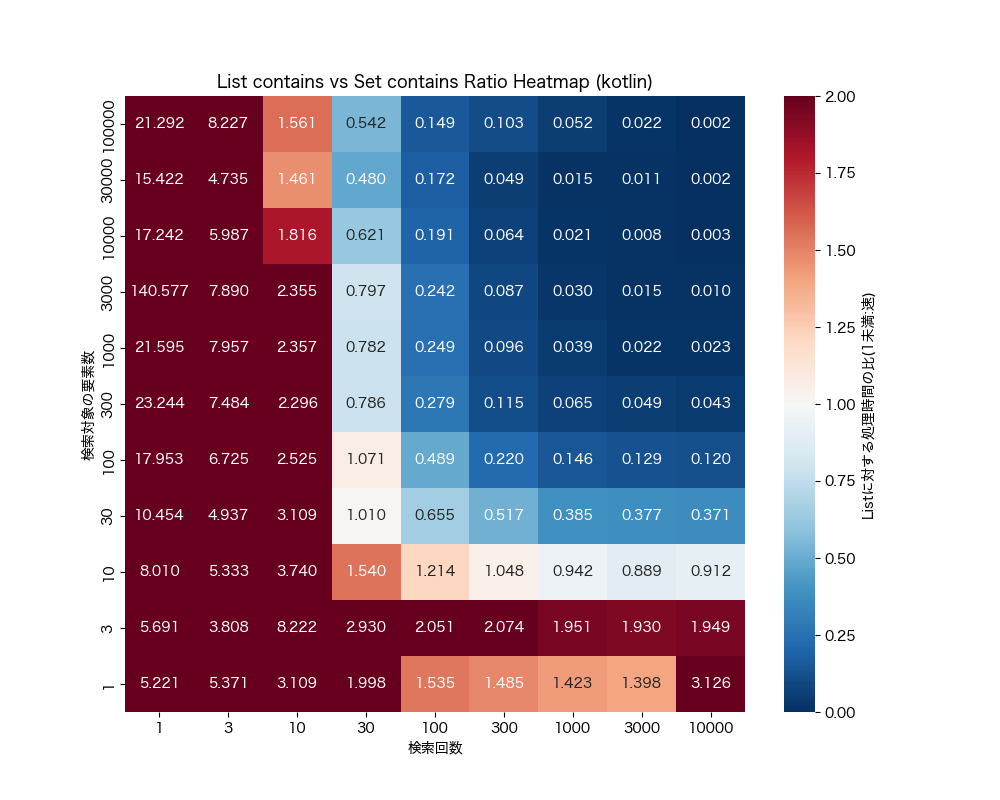
List#contains vs Set#contains
- 配列の要素数が30以上で検索回数が100回以上であれば、
Setに変換した方が良さそう - 配列の要素数が300以上であれば、検索回数が30回以上でも、
Setに変換した方が良さそう
List#find vs Map#[]
- 配列の要素数が10以上で検索回数が100回以上であれば、
Mapに変換する方が良さそう - 配列の要素数が100以上であれば検索回数が30回以上でも
Mapに変換する方が良さそう
![list_find_vs_map_[]_ratio_heatmap_kotlin.png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F2493295%2F4bd7f7bd-8297-3ee8-d0f7-2dcabf3382f9.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=59a7a3b8132ec29ae65abced0f07ff38)
感想・問題点
- 処理時間の絶対値は小さな差異でも比としては大きく見えるので注意が必要ですね
-
JavascriptをNodeで実行すると、注釈1に記載した通り誤差が大きかったのでBunで行ったのですが、そのことに関しては、また別の機会に - 今回はvalueを数値にしましたが、文字列にした場合言語によっては少し結果が異なりました
- 対応のないt検定で有意差があるところを境界にしようかと思い行いましたが、多重検定の問題もあるしあまり意味がないかと思いやめました
- 競プロでは、なんでも
SetやMapに変換していましたが、実業務ではスケールを考えて使い分けようと思いました
-
配列数30,000、検索回数10,000で
Array#includesをNode v20.10.0で実行すると、10回(配列は毎回変更、検索値は配列に存在しない値)の試行中最大4桁の差異が出ました。一方、Bun 1.1.26は誤差が小さかったため選択しました ↩ ↩2