PDFから文字情報を抽出するために
環境構築
Dockerfile
FROM python:3.6
ENV LC_ALL C.UTF-8
ENV LANG C.UTF-8
RUN apt-get -y update && \
apt-get install -y --fix-missing \
build-essential \
software-properties-common \
poppler-utils && \
apt-get clean && \
rm -rf /tmp/* /var/tmp/* && \
mkdir /api
WORKDIR /api
COPY requirements.txt /api/requirements.txt
RUN pip3 install --upgrade pip && \
pip3 install --upgrade -r requirements.txt
EXPOSE 8888
ENTRYPOINT jupyter notebook --ip=0.0.0.0 --allow-root --no-browser
requirements.txt
pandas==0.24.2
pillow==7.0.0
opencv-python==3.4.2.16
pdfminer==20191125
jupyter==1.0.0
$ docker build -t pdfminer -f ./Dockerfile .
$ docker run -it -v `pwd`:/api -p 8888:8888 --name pdfminer pdfminer bash
PDFから文字情報を抜き出す
コンテナの作成に成功したら、自動でジュピターが立ち上がるため、pythonファイルを作成します。
下記設定は最低限文字情報を抜き出して、テキストファイルに保存するコードです。
今回は金融庁のPDFをtest.pdfとしました。
https://www.fsa.go.jp/news/30/wp/supervisory_approaches_revised.pdf
test.py
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams, LTContainer, LTTextBox, LTTextLine, LTChar
from pdfminer.pdfinterp import PDFPageInterpreter, PDFResourceManager
from pdfminer.pdfpage import PDFPage
def pdfminer_config(line_overlap, word_margin, char_margin,line_margin, detect_vertical):
laparams = LAParams(line_overlap=line_overlap,
word_margin=word_margin,
char_margin=char_margin,
line_margin=line_margin,
detect_vertical=detect_vertical)
resource_manager = PDFResourceManager()
device = PDFPageAggregator(resource_manager, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
return (interpreter, device)
def find_textboxes(layout_obj):
if isinstance(layout_obj, LTTextBox):
return [layout_obj]
if isinstance(layout_obj, LTContainer):
boxes = []
for child in layout_obj:
boxes.extend(find_textboxes(child))
return boxes
return []
def find_textlines(layout_obj):
if isinstance(layout_obj, LTTextLine):
return [layout_obj]
if isinstance(layout_obj, LTTextBox):
lines = []
for child in layout_obj:
lines.extend(find_textlines(child))
return lines
return []
def find_characters(layout_obj):
if isinstance(layout_obj, LTChar):
return [layout_obj]
if isinstance(layout_obj, LTTextLine):
characters = []
for child in layout_obj:
characters.extend(find_characters(child))
return characters
return []
def write_text(text_file, text):
text_file.write(text)
text_file = open('output.txt', 'w')
with open("./test.pdf", 'rb') as f:
interpreter, device = pdfminer_config(line_overlap=0.5, word_margin=0.1, char_margin=2, line_margin=0.5, detect_vertical=True)
for page in PDFPage.get_pages(f):
interpreter.process_page(page) # ページを処理する。
layout = device.get_result() # LTPageオブジェクトを取得。
boxes = find_textboxes(layout)
for box in boxes:
write_text(text_file, box.get_text().strip())
text_file.close()
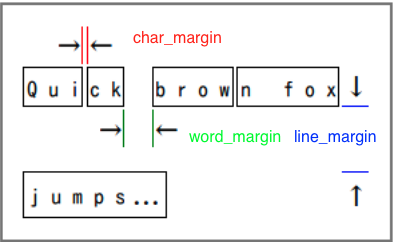
laparamsによる調整
テキストが思うように取得できない場合は、laparamsのパラメーターを調整します。char_margin, word_margin, line_marginを変えることで、グルーピングされる文字が変わります。
detect_vertivcalは日本語のように縦書きの文章がある場合は、Trueにします。
test.py
interpreter, device = pdfminer_config(line_overlap=0.5, word_margin=0.1, char_margin=2.0, line_margin=0.5, detect_vertical=False)
boxesの中身
上のコードで入手できたboxesには様々な情報が詰まっています。
- 文字情報
- 文字の位置情報(単位はptなので、opencvなどで加工する場合は、ptからpixelへの単位変換が必要)
print(boxes[0])
# >> <LTTextBoxHorizontal(0) 92.160,755.000,524.296,766.952 'かし、従来は金融庁の国際部門は国際規制の導入負担ができるだけ小さくなるよう交\n'>
print(boxes[0].get_text())
# >> かし、従来は金融庁の国際部門は国際規制の導入負担ができるだけ小さくなるよう交
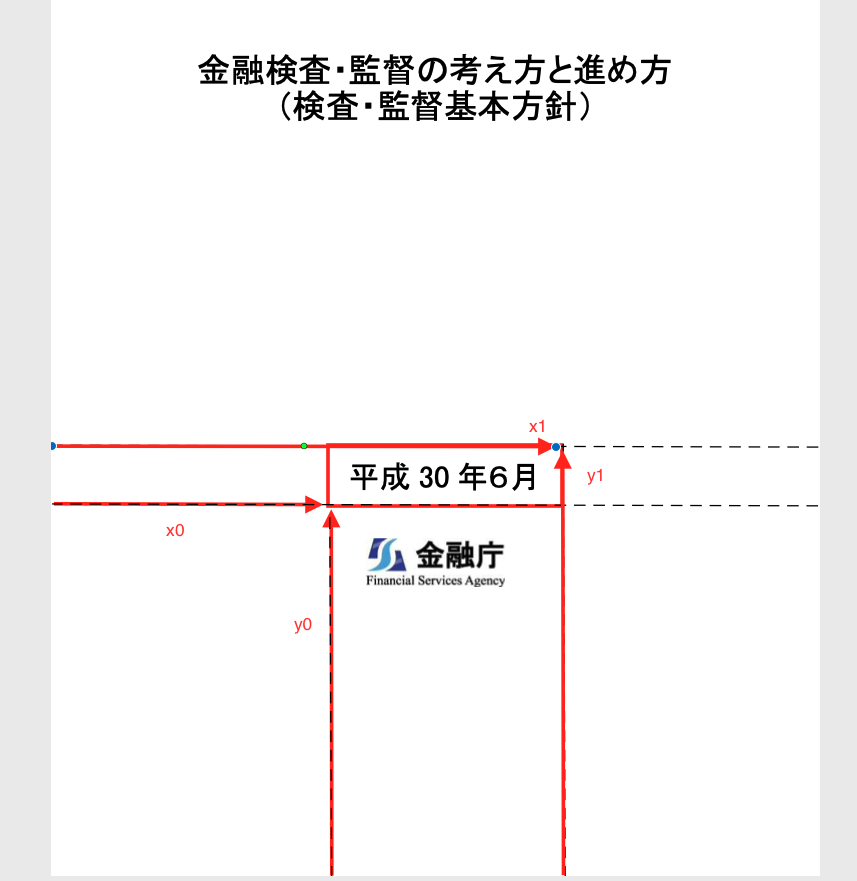
print(boxes[0].bbox)
# >> (92.15997480600001, 754.9998879965001, 524.2961793060001, 766.9523361965001)
# >> タプルの中は(x0, y0, x1, y1)の順になっており、示す位置は画像のようになっています。
linesの中身
boxの中には、LTTextLineがリストとして並んでいます。そのため、先ほどのコードでは使用しなかったfind_textlineを使って、LTTextLineを取得してみましょう。
test.py
lines = find_textlines(boxes[0])
print(lines[0])
# >><LTTextLineHorizontal 92.160,755.000,524.296,766.952 'かし、従来は金融庁の国際部門は国際規制の導入負担ができるだけ小さくなるよう交\n'>
print(lines[0].get_text())
# >> かし、従来は金融庁の国際部門は国際規制の導入負担ができるだけ小さくなるよう交
print(lines[0].bbox)
# >> (92.15997480600001, 754.9998879965001, 524.2961793060001, 766.9523361965001)
charactersの中身
さらにlinesの中には、LTCharがリストとして並んでいます。その中には、文字情報や位置情報の他にも、fontなども詰まっています。
test.py
characters = find_characters(lines[0])
print(characters[0])
# >><LTChar 92.160,755.000,104.160,766.952 matrix=[12.00,0.00,0.00,12.00, (92.16,756.68)] font='AHTYXM+MS-PGothic' adv=1.0 text='か'>
print(characters[0].get_text())
# >> か
print(characters[0].bbox)
# >> (92.15997480600001, 754.9998879965001, 104.16042480600001, 766.9523361965001)
時間ができれば、取得できた部分の色を変えるなども紹介したいと思います。