ふと思い立ったので( ˘ω˘)
- ヘッドレスchromeのpuppeteerでページを読み込み
- querySelectorで対象のDOMのテキスト内容を取得
- jsonとして返却
の3つの流れになるのかなと。
やることはシンプルです。
いざ実装
web-to-json.js
const puppeteer = require('puppeteer');
const runPuppeteer = async (pageUrl, querySelector) => {
const browser = await puppeteer.launch({ args: ['--no-sandbox'] });
const page = await browser.newPage();
await page.goto(pageUrl);
const list = await page.$$(querySelector);
// mapにするとエラーになるので気をつける
const listTexts = [];
for (let i = 0; i < list.length; i++) {
const textContentProp = await list[i].getProperty('textContent');
const textContent = await textContentProp.jsonValue();
listTexts.push(textContent);
}
await browser.close();
return listTexts;
};
こんな感じでしょうか。
取得したいURLと項目の場所を指定したquerySelectorを設定して、対象のテキストを取得。
一覧データとして返却してあげています。
yahooのニュースの一覧を取得してみる
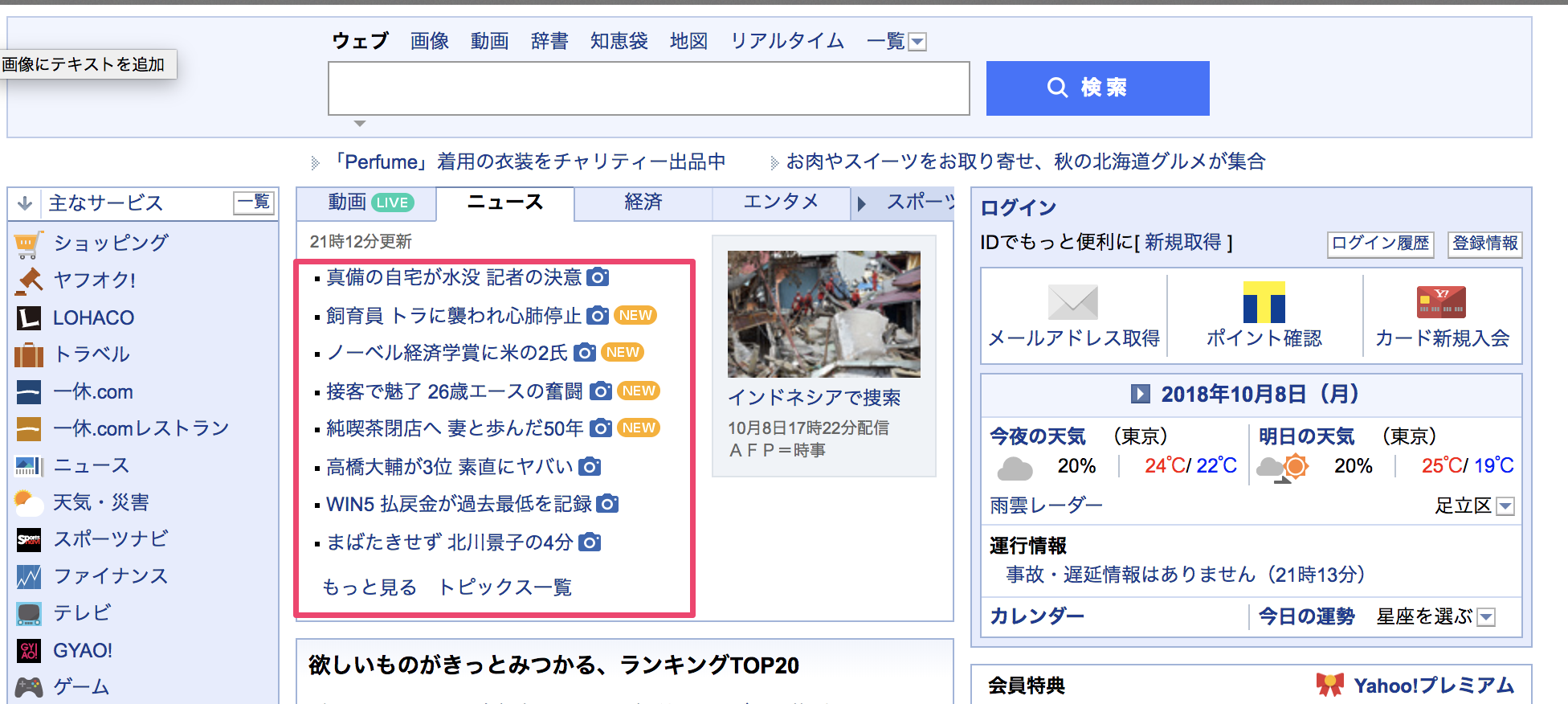
ここの部分を取得してみます。
run_yahoo.js
runPuppeteer("https://www.yahoo.co.jp/", "ul.emphasis li")
.then(console.log)
.catch(console.error);
/*
[ '正恩氏の訪露調整か 高官協議NEW',
'飼育員 トラに襲われ心肺停止写真',
'ノーベル経済学賞に米の2氏写真',
'純喫茶閉店へ 妻と歩んだ50年写真NEW',
'接客で魅了 26歳エースの奮闘写真NEW',
'高橋大輔が3位 素直にヤバい写真',
'WIN5 払戻金が過去最低を記録写真',
'まばたきせず 北川景子の4分写真' ]
*/
上手く取得できました![]()
Qiitaの動的な項目を取得してみる。
yahooの場合はサーバサイドレンダリングされているのもあって、DOMの文字列さえあれば取得することは可能でした。
なので、次はQiitaのページ読み込み後に動的に作成されている部分を対象にしてみます。
(HyperAppで画面読み込み後にDOMを構築しているっぽいので、ページのソースを開く、とやってみても対象のDOMが存在しないようです。)
今回は、「いいね」された数の一覧を取得してみようと思います。
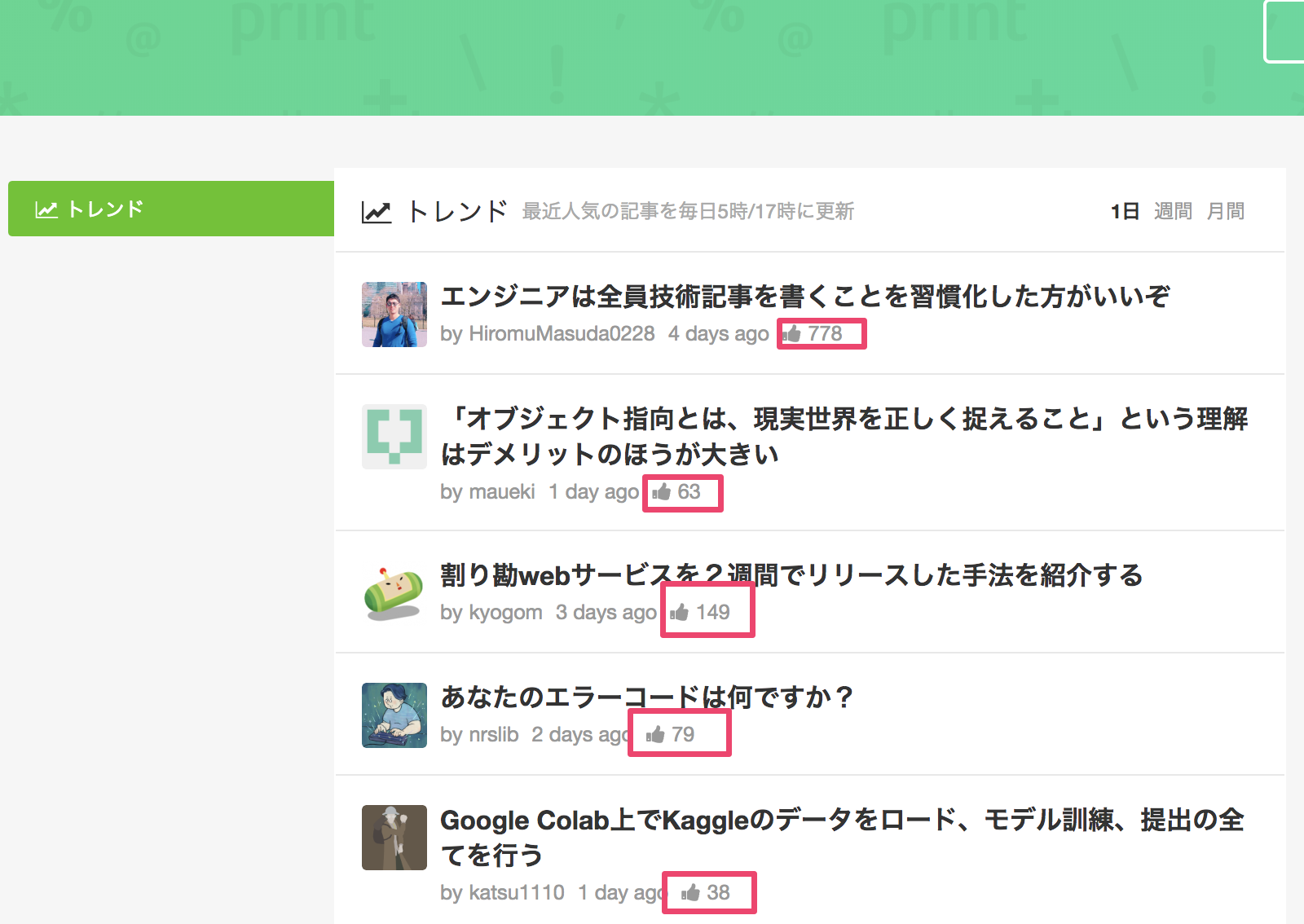
run_qiita.js
runPuppeteer("https://qiita.com/", ".tr-Item_likeCount")
.then(console.log)
.catch(console.error);
/*
[ '777',
'63',
'149',
'79',
'38',
'39',
'32',
'33',
'37',
'23',
'71',
'33',
'418',
'37',
'15',
'18',
'15',
'56',
'15',
'17' ]
*/
これも上手く取得できました![]()