はじめに
普段30msでレスポンスを返しているリクエストがたまに100msで返す、
こういったレスポンス遅延に関して勘違いしていました。
その誤った知識でphp-fpmのプロセス調整を行っていたことが分かったので、
そのことに関して書きます。
この遅延があったことにより、
11: Resource temporarily unavailable
というエラーが発生してしまっていました。
インフラまわりに携わっている方で自分のような勘違いをされている方は少ないかもしれませんが、
自分の戒めのためにも記録しておこうと思います。
構成
webアプリケーションを以下のような形で運用しています(簡略化しています)
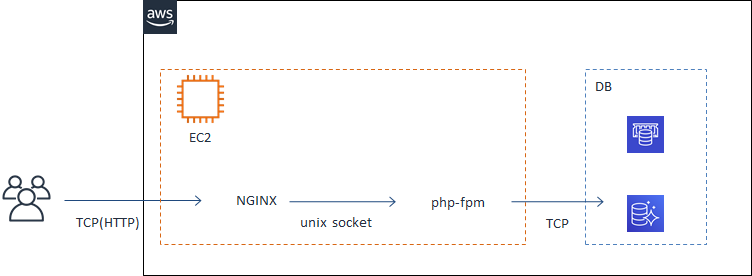
以下たびたびプロセスと言っているのはphp-fpmの子プロセスのことです。
スレッドでもほとんど同じような状況になるとは思っていますが、ここではプロセスのお話です。
勘違いしていた認識
レスポンスの遅延には大まかに分けて2つパターンがあると考えています。
- 単一リクエストの遅延
- 並列で処理を受けることによる遅延
単一のリクエストの遅延は処理するデータ量やネットワーク周りの影響によるものだと考えています。
要因としては、例えば
- DBのデータ量増加による問い合わせの性能劣化
- APIリクエストエラー時の再送処理による性能劣化
- ネットワーク障害による通信遅延
- DBから受け取ったデータ量によりアプリケーションの性能が変化する場合
といったところでしょうか。
今回勘違いしていたところは、並列で処理を受けることによる遅延の方です。
どのように認識していたかというと、
- クライアントから見た場合遅延が発生する
- リクエストがプロセスに割り当てられてからの処理に遅延は発生していない
という認識でした。図(表)にすると以下のような感じです。
縦が時間の経過、横が1リクエスト(プロセス)、表の内容がそのリクエスト(プロセス)がどういう状態にあるか、を書いています。
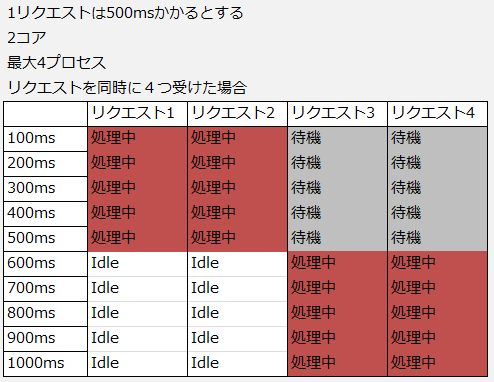
リクエスト1,2は正常にレスポンスが返り、リクエスト3,4はコアが2つしかないので遅延が発生するという考えです。
もう少し詳しく言うと、
- リクエストを同時に受けた場合php-fpmは子プロセスにリクエストを割り当てる
- 先に受けたリクエストを処理するためリクエスト3,4は待機状態となりCPUが空いたら実際の処理が開始される
- CPUが割り当てられるまでの待機時間 + 処理時間により待機時間分だけ遅延が発生する
といったところです。
最初に処理中となるまでアプリケーションは処理時間の計測を開始しないから、
複数同時にプロセスに割り当てられても処理時間は変わらないと考えていました。
認識を改めた後
まあ、要するに、タイムスライスのことをすっかり忘れていたという話です。
正しかった方の認識を図にするとこんな感じです
(もちろん100msでスライスされることはあり得ないのでイメージ図です)
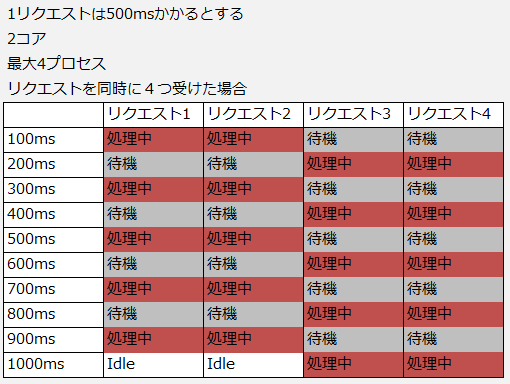
- リクエストを同時に受けた場合php-fpmは子プロセスにリクエストを割り当てる(listenしているソケットでacceptしたタイミング)
- 割り当てられたプロセスはCPUに処理が割り当てられる
- プロセスの数だけ単位時間当たりの1プロセスに割り当てられるCPU時間が減るためレスポンスの遅延が発生する
勘違いしていたころは500msの時点でプロセスがidleになり新たなリクエストを受け付けられますが、認識を改めた後では900ms経過しないと新しいリクエストを受け付けられないということになります。
つまりCPUに割り当てが必要なプロセス数が増えれば増えるほど新しくリクエストが受けられるまで時間がかかるということになります。
勘違いにより何が起こっていたか
冒頭でもお話しした通り、Resource temporarily unavailableというエラーが発生してしまっていました。
プロセス数が増えすぎてリクエストを受けきれず、listenのbacklogを使いつくしたということです。
そしてこの原因特定にかなりの時間がかかりました。
ありもしないネットワークの障害を疑ったり、DBのデータの量を計測したり、
スロークエリのログを確認したり、といった無駄なことをしていました。
自分の勘違いによると、アプリケーションの処理時間は普段と変わらない想定なので、
アプリケーションのパフォーマンスのグラフを見てタイムスライスの影響を疑えませんでした。
プロセス数足りないから動的に追加しておいた、というログは出ていたので、
php-fpmの初期プロセス数を増やすということをしていましたが、
単位時間当たりのCPU割り当て時間が減るだけで、新たにリクエストが受けられず、
全くの逆効果だったというわけです。
この遅延を発生させないために
遅延は起こっていてもエラーが発生していなかったり、
遅延が許容範囲内であれば問題はありません。
この遅延が問題となっている場合に取りうる対処は主に3つかなと思います。
- アプリケーションのパフォーマンスを改善する
- 1コアあたりのタイムスライス頻度を減らす方法
- レスポンスが速ければ速いほどCPUが処理しなければならない時間は少なく済みます
- CPUのコア数を増やす
- 1コアあたりに割り当たるプロセス数を減らす方法
- コアの数が少ないからプロセスが使えるCPU時間が減るのでこれを増やします
- 起動するプロセス数を少なくしてlisten時のbacklogを増やす
- idleなプロセスができるまでacceptを待つ方法
- listenで指定できるbacklog数まではリクエストを待機できる
- もともと自分の認識していた遅延の状態に近いもの
今回は手っ取り早くCPUのコア数を増やして対処しました。
これからまた調整していく予定です。
まとめ
プロセス数を調整した値が実際は使い物にならなかったということなので、
認識を新たに再度調整していきたいと思います。
なんでこんな勘違いをずっとしていたんでしょうね。
おそらくパフォーマンスの劣化をハードウェアで補うようなパワープレーばかりしていて、
あんまり深く考えてなかったからかな。
理解が深まったのは良しとして、雰囲気で運用していたことはエンジニアとして反省します。