この投稿はOpenCV Advent Calendar 2017の11日目の記事です。
概略
CPUは年々アップデートされ,クロック数,コア数,ベクトル長など演算能力は日々進化しています.
「OpenCVもその恩恵にあずかれているのでしょうか?」
いろんな関数のベンチマークを通して,どれくらい恩恵にあずかれているかを見ていきます.
使用した計算機とベンチマークの関数群
使用した計算機一覧
実験では以下の計算機を用いました.
- Core i7 990Xもどき(Xeon 5690) 第1世代 ※以下参照
- 3.46 GHz 6コア SSE
- Core i7 3970X 第2世代
- 3.5 GHz 6コア AVX
- Core i7 4960X 第3世代
- 3.6 GHz 6コア AVX
- Core i7 5960X 第4世代
- 3.0 GHz 8コア AVX2
- Core i7 6950X 第5世代
- 3.0 GHz 10コア AVX2
※990Xが用意できなかったので同スペックのXeonを使用.最大メモリバンド幅だけ違うが,990Xとメモリは合わせました.この実験のためだけにデュアルソケットCPUを一つ外しました.(手がシリコングリスまみれに...)
これらのCPUの,第1世代からの理論FLOPSの速度向上比を以下に示します.演算性能だけに関係するならこの分の速度向上が期待できるはずです.
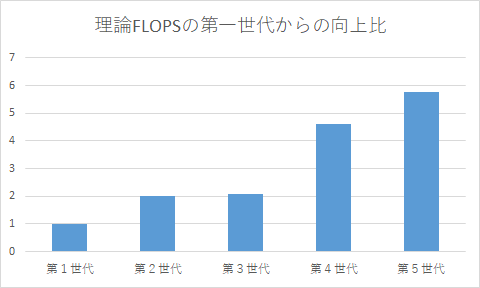
なお,IntelのCPUは以下のように分類でき,その中でコンシューマ最上位モデルを選別しています.
- Atom: 省電力用
- Pentium, Celeron: 廉価,時々ノートPC用
- Core i3:廉価だけど上よりは速い.
- Core i5:ミドルレンジ.だいたいこれで十分.ハイパースレッディングがない.
- Core i7:上位モデル:だいぶ速い.
- Core i7/9X:最後にXとかつくコンシューマ最上位モデル.半分Xeonと変わらない.メモリのバンド幅が通常の倍.
- Xeon:サーバー用.家庭用で使うお値段ではありません.(現状最上位のXeonは28コアx8ソケットが付きます.最強環境にするとお値段は,ディープラーニングに定評があるGeforce 1080が100枚くらい買えそうです.)
各アーキテクチャの詳しい情報は以下のリンクを見てください.
Intel CPU年表(コンシューマ向け最上位モデル)
関数群
演算の種類(マップ,ステンシル,スキャン,リダクション,混合)に応じて関数をいくつか選択しました.これらの演算の種類分別の詳細は以下を参照してください.
使用した関数群は以下になります.太字は,IPPの関数ではないものです.(divなど要検証なものもありますが.)OpenCVの基礎的な関数はかなりの割合でIPP(Intel Performance Primitive)がコールされています.下記ベンチマーク関数もほとんどIPPの関数となっています.
- マップ
- add
- add 32f
- mul
- mul 32f
- div
- div 32f
- threshold
- threshold 32f
- cvtColor YUV
- cvtColor HSV
- ステンシル
- Filter2D
- Filter2D 32f
- Bilateral
- Bilateral 32f
- Bilateral Color
- Bilateral Color 32f
- Gaussian
- Gaussian 32f
- Resize Cubic
- Median
- スキャン
- Box
- Box 32f
- Box Color
- Box Color 32f
- Dilate
- Domain Transform
- FFT
- リダクション
- Mean
- Mean Std
- MinMax
- Histogram
- 混合
- Canny
- Guided Filter
- SLIC
- Stereo Block Matching
- Face Detection
IPP対応関数一覧
以下,OpenCV3.3.1のコードからCV_IPP_CHECKのある関数をgrep抽出した結果です.
おそらくOpenCV側で呼んでいないだけだと思いますが,IPPのコードにあるのに以下のリストにない関数もあるため,もしかしたら漏れがあるかもしれません.
MAP処理
- copyTo
- set
- convertTo
- Add, MUL (divはないかも?)
- CMP
- NOT, AND, OR, XOR
- ABSDIFF
- MIN, MAX
- threshold
- accumulate:destにsrcをたす
- accumulateSquare:二乗を足す
- accumulateProduct:src1とsrc2の積を足す
- accumulateWeighted:重み付き平均(addweighted)で足す
- cvtColor(BGR2RGB,BGR2Gray,BGR2YUV,BGR2YCrCb,BGR2XYZ,BGR2HSV,BGR2Lab)
入れ替え
- transpose
- split
- merge
- sort (radix sort)
Stencil処理
- resize:ranczos以外をサポート
- distanceTransform
- warpAffine
- warpPerspective
- remap
- getRectSubpixel
- polarToCart
- Sobel
- Laplacian
- filter2D
- medianFilter
- GaussianFilter
- bilateralFilter(グレイだけ?)
- morphologyEx
- erode
- dilate
- open
- close
- gradient
- tophat
- blackhat
リダクション
- sum
- mean
- meanStdDev
- minMaxLoc(最大最小)
- countNonZero
- norm
- reduce:列または行単位の平均,合計,最大,最小
- Histogram
- pyrdwon
- pyrup
- matchTemplate
スキャン
- boxFilter
- integral
- DFT
- DCT
混合
- HoughLines
- HaarClassifier
- Canny
その他ユーティリティ
- String getIppVersion
- setUseIPP
- useIPP
- useIPP_NE
- setUseIPP_NE
ベンチマーク結果
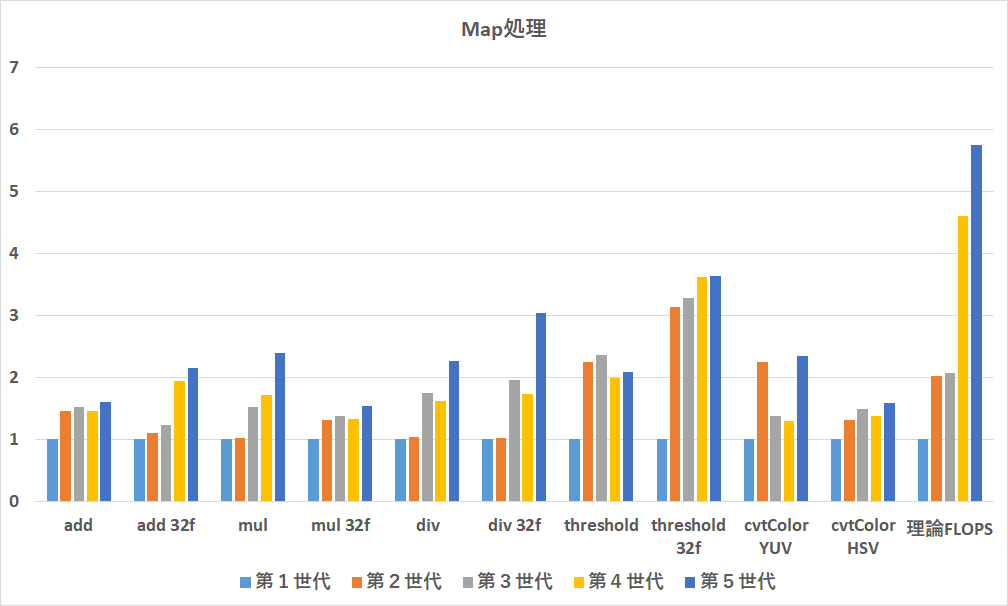
Map処理
画像サイズ1024x768でのベンチマーク結果です.右端にある理論FLOPSの結果があるので,演算優位ならここまで伸びるはずという風に見てください.
ただし,Map処理はメモリIOが優位になりやすいためあまりはやくなりません.
YUV変換だけ第2世代が異常に速いという変わった挙動をしていますが,概ね妥当な結果です.
一部閾値処理だけ速くなっています.
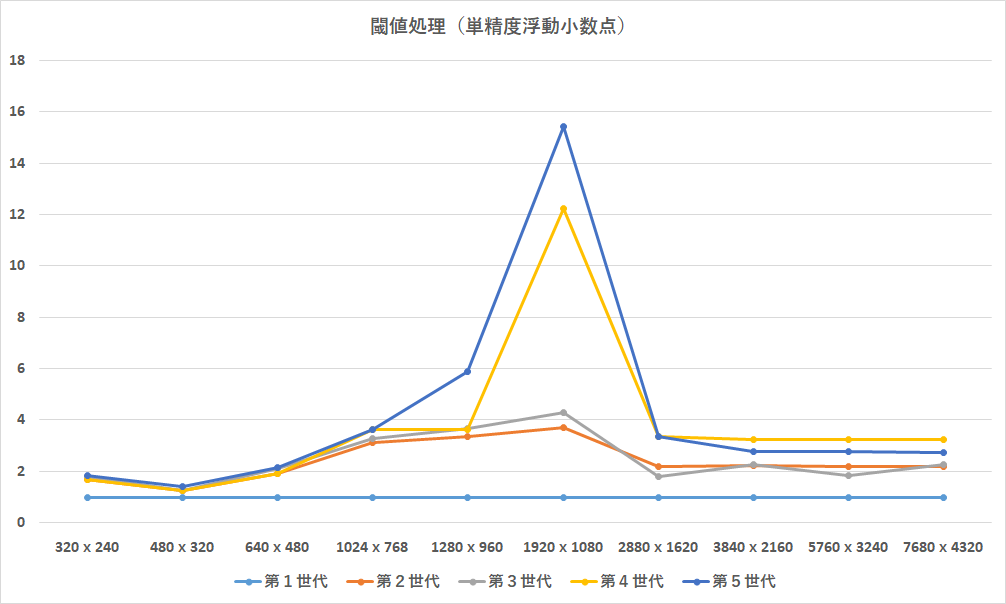
閾値処理だけ詳しく見てみます.
横軸が画像サイズ,縦軸が第1世代に比べてどれだけ速くなったかの倍率です.特定の倍率だけ以上に速くなっているのがわかると思います.
これは,おそらくキャッシュサイズの違いから,ちょうどキャッシュに乗り切るデータの幅の違いにより,メモリIOの差が劇的に出たためだと思われます.
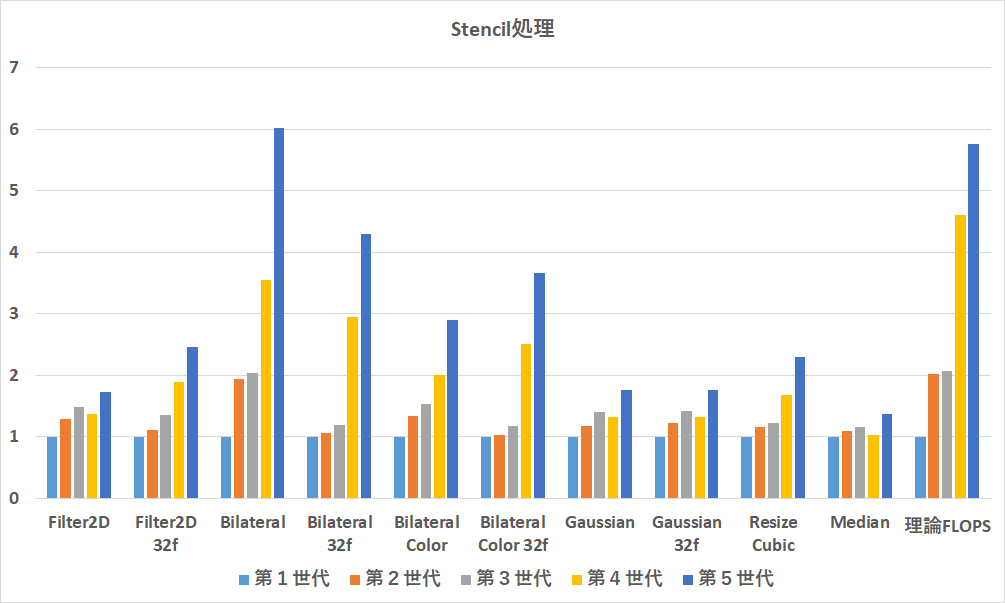
Stencil処理
Stencil処理はMapよりも演算強度が高いためより演算速度の向上の影響が高いことが期待できます.以下の図が結果です.特に整数画像に対するバイラテラルフィルタは理論FLOPSの向上比くらいまで高速化できています.
しかしながら,他の結果は軒並み期待以下です.これはコードを書きなおしたほうが良いでしょう...少なくてもFilter2Dはバイラテラルフィルタ級の速度向上比がでてもおかしくありません.ガウシアンもそれなりに速くなるはずです.
Stencil処理(バイラテラル特化)
カラーのバイラテラルの浮動小数点の結果がいまいち遅いのが気に食わなかったので,バイラテラルフィルタを考えつく最大レベルまでチューニングしました.第1世代のCPUでOpenCV(IPP)の整数での実行速度(これが最速だった)が610msだったのが,浮動小数点演算の実装で300ms程度と,OpenCV実装よりも2倍以上の速度になっています.結果は以下のようになりました.
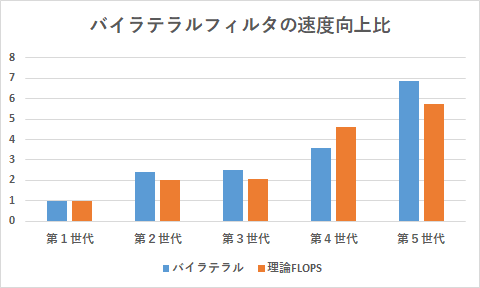
カラーの浮動小数点のバイラテラルフィルタも理論FLOPS以上の性能効果をだいたい得ることができました.第5世代のバイラテラルフィルタはOpenCV実装の5~6倍以上の速度が出ています.
第4世代は多少遅いですが,Gather命令が遅いのとFMAとMul-Addの発行比率をもうちょっと考慮してコードを書けばもう少し頑張れるかもしれません.
この実装の詳細は以下にあります.
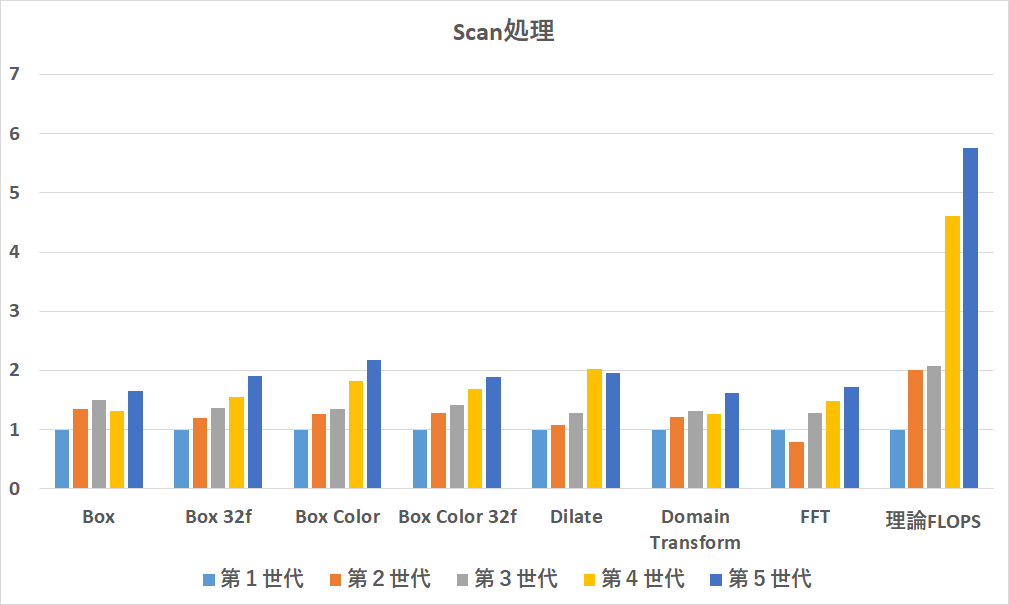
Scan処理
Scan処理の結果です.Map処理よりも軒並みおもったほどの速度が出ていません.Scan処理もメモリ律速しやすいため実装を頑張る必要があるでしょう.特にFFTはもっと速いと思っていました.2のべき乗で再チャレンジ必須かもしれません.
なお,DomainTransformは,IPPにない初出の関数です.アルゴリズム的にはバイラテラルフィルタよりも速いのですが,並列ベクトル化やメモリアクセスのチューニングがうまく行っていないためバイラテラルフィルタよりも遅くなっています.せっかくの高速なエッジ保存平滑化フィルタなので頑張って最適化したいところです.(ximgprocに別実装があるのでそちらを試してみてもいいかもしれません.)
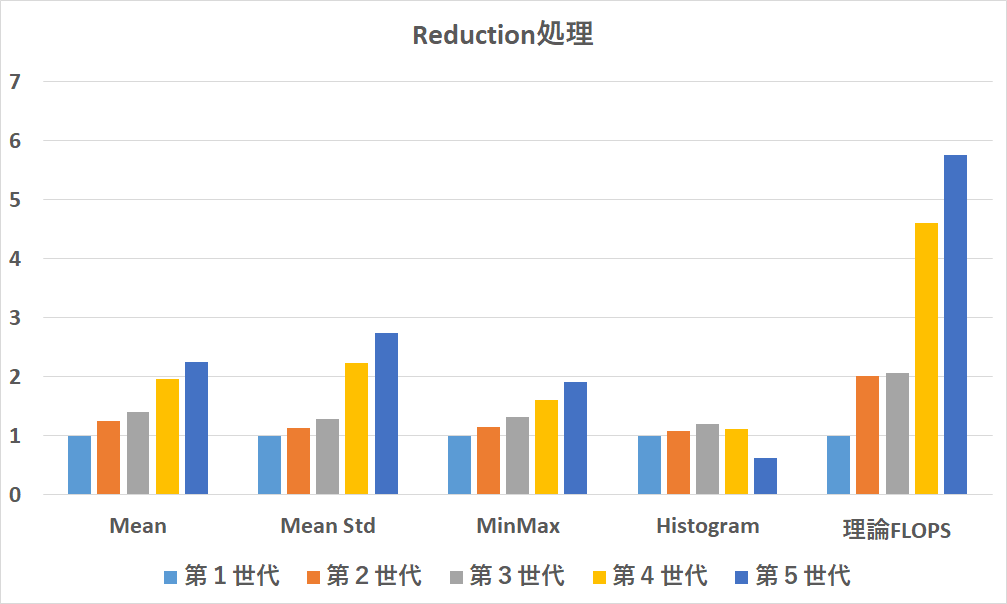
Reduction処理
Reductionは,平均分散を同時に計算するものだけ演算強度が高いためましですが,ほかはScan処理と大して変わりません.ヒストグラム演算に至っては速度が落ちています.(再計測必須?)
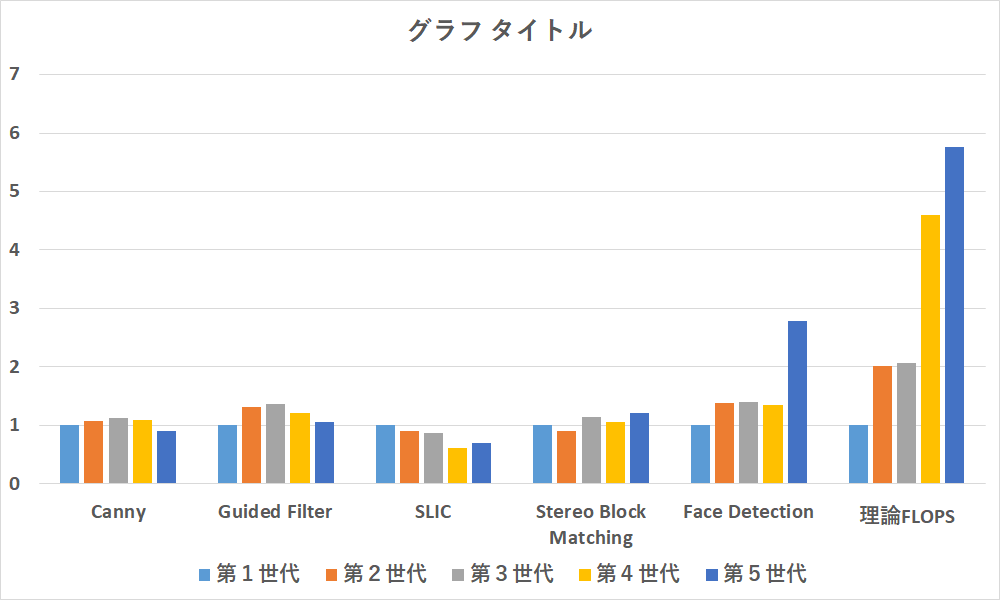
統合
様々の処理が統合された画像処理のチェインになる処理です.
ippにある顔認識だけ唯一効果が認められます.看板となる処理だけにチューニングを頑張ったのでしょうか.
Cannyに至っては,最新版で大幅劣化しています.きっとマルチコア並列化が掛かっていないのでしょう.また,SLICは並列実装していないため世代ごとにどんどん劣化していっています.
まとめ
OpenCVの関数群をCPUのマイクロアーキテクチャごとにベンチマークしました.
結果としては,ステンシル処理以外は思ったよりも速くなっていないという結果になりました.
IPPが使われているため,ものすごく速くなっていると妄信してましたが,OpenCVの関数はそれほど速くなく,必要なら自前でコーディングする必要がありそうです.(ただし,高速化のに慣れていない人のコードよりはだいぶ速いです.)特に,複雑なチェインになる画像処理の場合は,OpenCVの関数使わずに,よく考えて最適な実装をしたほうが良いでしょう.
Halideを使うともっと簡単に画像処理を速くできるはずです.一緒に研究する人を募集しています!
なお,使ったコードは以下のリンクに公開しています.また計算結果のRAWデータをGoogleスプレッドシートに上げました.
もし古いCPUをお持ちでゴミに捨てる寸前のかたがいらっしゃったら送っていただければベンチマーク回します(笑)
あとがき
第6世代のマシンもベンチマークする予定でしたが,発注したマシンがまだ届かないため到着したらいろいろ見直して(行列演算もあるといいかもと思うのでその辺も合わせて)もう一度やってみようかなと思います.
あと,コードをGitHubで公開しようとしたらクライアントソフトウェアが入っていないことに初めて気づきました.マシンを変えてから,1年は立っているのですが,それまでずっとコードを外に公開していないという事実に驚愕...うちの研究室の鬼チューンしたコードが公開できるように,メンテナンスの仕組みづくりをもう少し頑張りたいです.個人としての時間は限界来ているのでなんとかしたいところ.
もいっこ追記で,頑張れHPC!
もしおかしなところがあったり,ベンチマークを追加したい方がいらっしゃれば,@fukushima1981まで連絡をください.修正します.