はじめに
これは,OpenCV Advent Calendar 2015の記事です.関連記事は,リンク先に目次としてまとめられています.
デスクトップでもモバイルでもマルチコアが常識となった今では,並列処理,並列化は,効率的なプログラムを作るために必要不可欠な技術です.この並列化をサポートするために,古くはforkやpthreadにより自らスレッド,プロセスを管理したり,MPIでPCクラスタを管理して並列化していました.また,現在では,様々な並列化環境が用意されています.
- OpenMP(良く知られたディレクティブ形式の並列化)
- Cilk Plus(Intelの配布するディレクティブ形式の並列化.gcc,iccで使える.visual studioで使えるまでずっと待ってるけど出ない.)
- Intel TBB(Intelの配布するクラスライブラリ形式の並列化.LGPLのフリー版もある.)
- Concurrency(Visual Studioに内蔵されるクラスライブラリ形式の並列化)
- OpenCL(マルチコア環境のための言語.実はCPUでも動く.ただし遅い.)
- Cuda(GPUのための言語)
- OpenACC(GPU用のディレクティブ.今後に期待)
OpenCVの並列化環境
当然,OpenCVでも並列化に対応しています.OpenCVではOSやライブラリに依存しないように開発環境に応じて適切に並列化環境を提供することを目的としたライブラリ構築をしています.以下にOpenCVがサポートしている並列化環境とその優先順位(1から高い)を示します.このように複数の並列化環境のいづれかが使えるように有効化されます.
/* IMPORTANT: always use the same order of defines
1. HAVE_TBB - 3rdparty library, should be explicitly enabled
2. HAVE_CSTRIPES - 3rdparty library, should be explicitly enabled
3. HAVE_OPENMP - integrated to compiler, should be explicitly enabled
4. HAVE_GCD - system wide, used automatically (APPLE only)
5. WINRT - system wide, used automatically (Windows RT only)
6. HAVE_CONCURRENCY - part of runtime, used automatically (Windows only - MSVS 10, MSVS 11)
7. HAVE_PTHREADS_PF - pthreads if available
*/
cv::ParallelLoopBodyとparallel_for_
実際の並列プログラムは上記バックエンドの並列化ライブラリをスイッチするように作られたクラスであるcv::ParallelLoopBodyを定義し,それを並列実行するプログラムcv::parallel_for_を呼び出すことで実行されます.
このような形の並列化プログラムの書き方は,Intel TBBの書き方とほとんど同じです.ただし,parallel_for_の最後のアンダーパーを忘れずに.TBBはアンダーパー無しのparallel_forで呼び出します.
実際には下記のようなイメージになります.関数オブジェクトクラスとなる cv::ParallelLoopBodyを継承したParallelClassを宣言し,それを引数にもつparallel_for_関数を呼び出して並列化します.
parallel_for_の引数は,並列化は帯状に行われるイメージで,引数は,画像の縦の長さの範囲,関数オブジェクト,分割数の順に入れます.
//実際に並列化する関数オブジェクト
ParallelClass body;
//引数は,画像の縦の長さの範囲,関数オブジェクト,分割数
parallel_for_(Range(0, src.rows), body, numThreads);
実際のcv::ParallelLoopBodyを見てみましょう.このように#ifdefでバックエンドで使うライブラリをスイッチしながら定義されています.そのため,ただひとつの並列化ライブラリしか有効化されません.つまり,後の実験で用いるように複数のライブラリを使った並列化の効果を検証するためには,いくつもコンパイルしなおしてlibとDLLを作る必要があります.
このcv::ParallelLoopBodyはほぼ関数オブジェクトであり,その中のメソッドであるoperator()で1コアで実行したい命令を書きます.またコンストラクタには1コア内で共有したい変数をセットします.上級者向けとしてデストラクタにリダクション処理を書くことも出来ます.詳しくはマルチコアを用いた画像処理を参考にして下さい.
# ifdef CV_PARALLEL_FRAMEWORK
class ParallelLoopBodyWrapper
{
public:
ParallelLoopBodyWrapper(const cv::ParallelLoopBody& _body, const cv::Range& _r, double _nstripes)
{
body = &_body;
wholeRange = _r;
double len = wholeRange.end - wholeRange.start;
nstripes = cvRound(_nstripes <= 0 ? len : MIN(MAX(_nstripes, 1.), len));
}
void operator()(const cv::Range& sr) const
{
cv::Range r;
r.start = (int)(wholeRange.start +
((uint64)sr.start*(wholeRange.end - wholeRange.start) + nstripes/2)/nstripes);
r.end = sr.end >= nstripes ? wholeRange.end : (int)(wholeRange.start +
((uint64)sr.end*(wholeRange.end - wholeRange.start) + nstripes/2)/nstripes);
(*body)(r);
}
cv::Range stripeRange() const { return cv::Range(0, nstripes); }
protected:
const cv::ParallelLoopBody* body;
cv::Range wholeRange;
int nstripes;
};
# if defined HAVE_TBB
class ProxyLoopBody : public ParallelLoopBodyWrapper
{
public:
ProxyLoopBody(const cv::ParallelLoopBody& _body, const cv::Range& _r, double _nstripes)
: ParallelLoopBodyWrapper(_body, _r, _nstripes)
{}
void operator ()(const tbb::blocked_range<int>& range) const
{
this->ParallelLoopBodyWrapper::operator()(cv::Range(range.begin(), range.end()));
}
};
# elif defined HAVE_CSTRIPES || defined HAVE_OPENMP
typedef ParallelLoopBodyWrapper ProxyLoopBody;
# elif defined HAVE_GCD
typedef ParallelLoopBodyWrapper ProxyLoopBody;
static void block_function(void* context, size_t index)
{
ProxyLoopBody* ptr_body = static_cast<ProxyLoopBody*>(context);
(*ptr_body)(cv::Range((int)index, (int)index + 1));
}
# elif defined WINRT || defined HAVE_CONCURRENCY
class ProxyLoopBody : public ParallelLoopBodyWrapper
{
public:
ProxyLoopBody(const cv::ParallelLoopBody& _body, const cv::Range& _r, double _nstripes)
: ParallelLoopBodyWrapper(_body, _r, _nstripes)
{}
void operator ()(int i) const
{
this->ParallelLoopBodyWrapper::operator()(cv::Range(i, i + 1));
}
};
# else
typedef ParallelLoopBodyWrapper ProxyLoopBody;
# endif
cv::parallel_for_は上記で定義したクラスを引数にとり,どれくらい並列化するのかを定義してクラスを呼び出す関数です.これも同じようにifdefで切り替えられて作られています.
void cv::parallel_for_(const cv::Range& range, const cv::ParallelLoopBody& body, double nstripes)
{
# ifdef CV_PARALLEL_FRAMEWORK
if(numThreads != 0)
{
ProxyLoopBody pbody(body, range, nstripes);
cv::Range stripeRange = pbody.stripeRange();
if( stripeRange.end - stripeRange.start == 1 )
{
body(range);
return;
}
# if defined HAVE_TBB
tbb::parallel_for(tbb::blocked_range<int>(stripeRange.start, stripeRange.end), pbody);
# elif defined HAVE_CSTRIPES
parallel(MAX(0, numThreads))
{
int offset = stripeRange.start;
int len = stripeRange.end - offset;
Range r(offset + CPX_RANGE_START(len), offset + CPX_RANGE_END(len));
pbody(r);
barrier();
}
# elif defined HAVE_OPENMP
#pragma omp parallel for schedule(dynamic)
for (int i = stripeRange.start; i < stripeRange.end; ++i)
pbody(Range(i, i + 1));
# elif defined HAVE_GCD
dispatch_queue_t concurrent_queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dispatch_apply_f(stripeRange.end - stripeRange.start, concurrent_queue, &pbody, block_function);
# elif defined WINRT
Concurrency::parallel_for(stripeRange.start, stripeRange.end, pbody);
# elif defined HAVE_CONCURRENCY
if(!pplScheduler || pplScheduler->Id() == Concurrency::CurrentScheduler::Id())
{
Concurrency::parallel_for(stripeRange.start, stripeRange.end, pbody);
}
else
{
pplScheduler->Attach();
Concurrency::parallel_for(stripeRange.start, stripeRange.end, pbody);
Concurrency::CurrentScheduler::Detach();
}
# elif defined HAVE_PTHREADS_PF
parallel_for_pthreads(range, body, nstripes);
# else
# error You have hacked and compiling with unsupported parallel framework
# endif
}
else
# endif // CV_PARALLEL_FRAMEWORK
{
(void)nstripes;
body(range);
}
実際の書き方,チュートリアルは @dandelion1124 さんの記事やこの記事を参考にして下さい.(もう少し詳細なチュートリアルは,余裕があったら書きます.)
異なる並列化ライブラリをサポートしたOpenCVのlib,DLL生成
OpenCV出実装されているかなりの数の関数がcv::ParallelLoopBodyとcv::parallel_for_によって並列化されています.つまり,並列化のバックエンドを変えるとそれらの関数の性能も変わります.
ここでは,Windows環境においてどの環境が優れているか評価します.比較対象は,TBB, Concurrency, OpenMP, CSTRIPESです.
まず始めに,これらをサポートするOpenCVのlibとdllをcmakeによって作る必要があります.
TBB
IBBをダウンロードしてcmakeのTBBを有効化すれば出来ます.どんな環境でもOpenCVはTBB最優先で使おうとします.
Concurrency
配布されているOpenCV3.0Windows版は,Vsual StudioについてくるConcurrencyによって並列化されています.(UnixだとおそらくOpenMPかPthreadでしょう.androidだとPthreadが動くそうです.)
C=(しーすとりっぷす)http://www.hoopoesnest.com/cstripes/cstripes-sketch.htm
C=はコンパイルして使ってみても並列化が有効化しなかった(Windows+Visual Studio 2013).
そのため評価には加えなかった.これは,ライブラリの最終更新が古い(2013年8月)し,もしかしたら,テストされてないのかもしれない.C=はダウンロードするとChromeにいいの?ほんとうにダウンロードしてもいいの??と言われるくらい使われていない模様.

OpenMP
OpenMPはほとんどのコンパイラがデフォルトに対応している並列化モジュールで,現代では動作しない環境のほうが珍しいくらいです.
このOpenMPもcmakeによって有効化できます(WITH_OPENMPにチェックを入れてcmake.).しかし,優先順位が低いため,Windowsだと改造なしには有効化できません.(強制的にConcurrencyが使われます.)そこで以下のようにcmakeのファイルをさくっと削除してファイル変更します.
opencv/sources/cmake/OpenCVFindLibsPerf.cmakeの中身の以下をさくっと削除.
103 # --- Concurrency ---
105 if(MSVC AND NOT HAVE_TBB AND NOT HAVE_CSTRIPES)
106 set(_fname "${CMAKE_BINARY_DIR}${CMAKE_FILES_DIRECTORY}/CMakeTmp/concurrencytest.cpp")
107 file(WRITE "${_fname}" "#if _MSC_VER < 1600\n#error\n#endif\nint main() { return 0; }\n")
108 try_compile(HAVE_CONCURRENCY "${CMAKE_BINARY_DIR}" "${_fname}")
109 file(REMOVE "${_fname}")
110 else()
111 set(HAVE_CONCURRENCY 0)
112 endif()
実験結果
計算時間
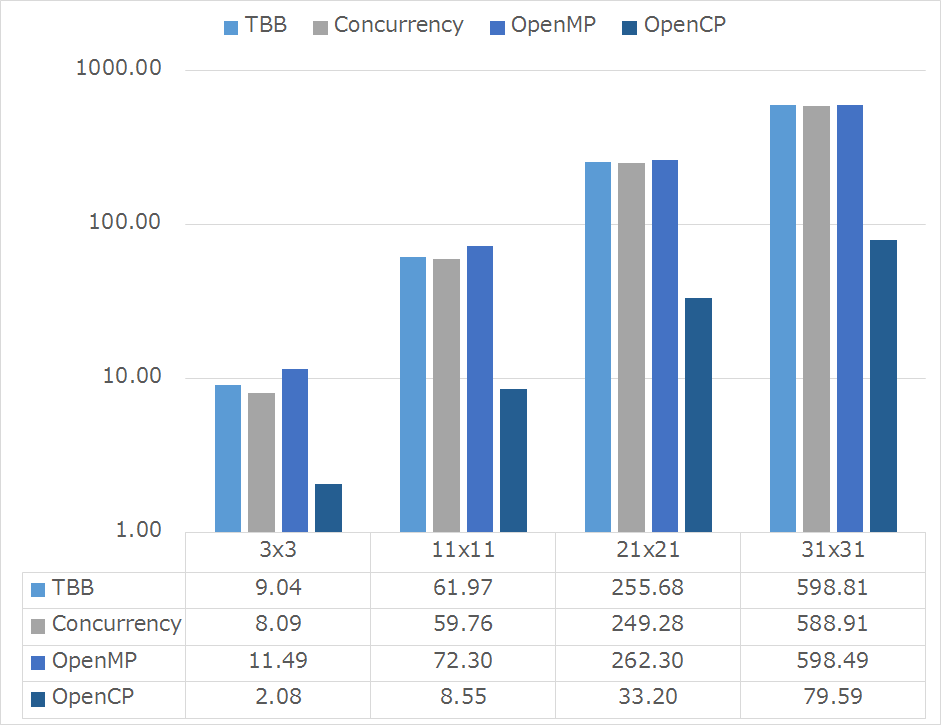
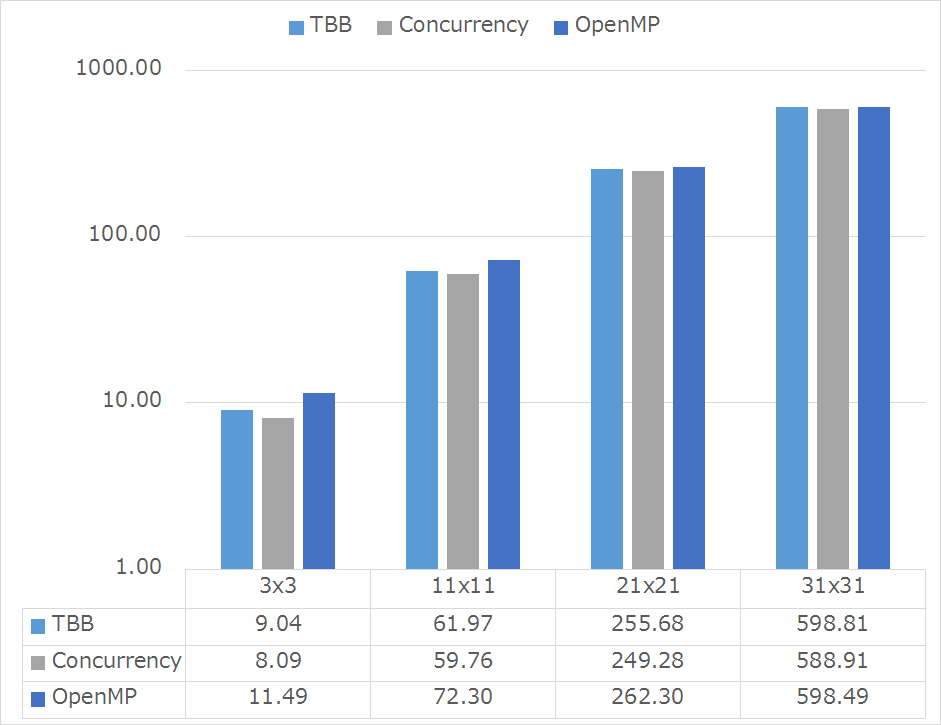
バイラテラルフィルタ(cv::bilateralFilter)を使って計測しました.カーネル半径を5,11,21,31と広げていき,どの実装が効率的に動いたか,安定的に動いたかを評価します.(横軸の単位はms)
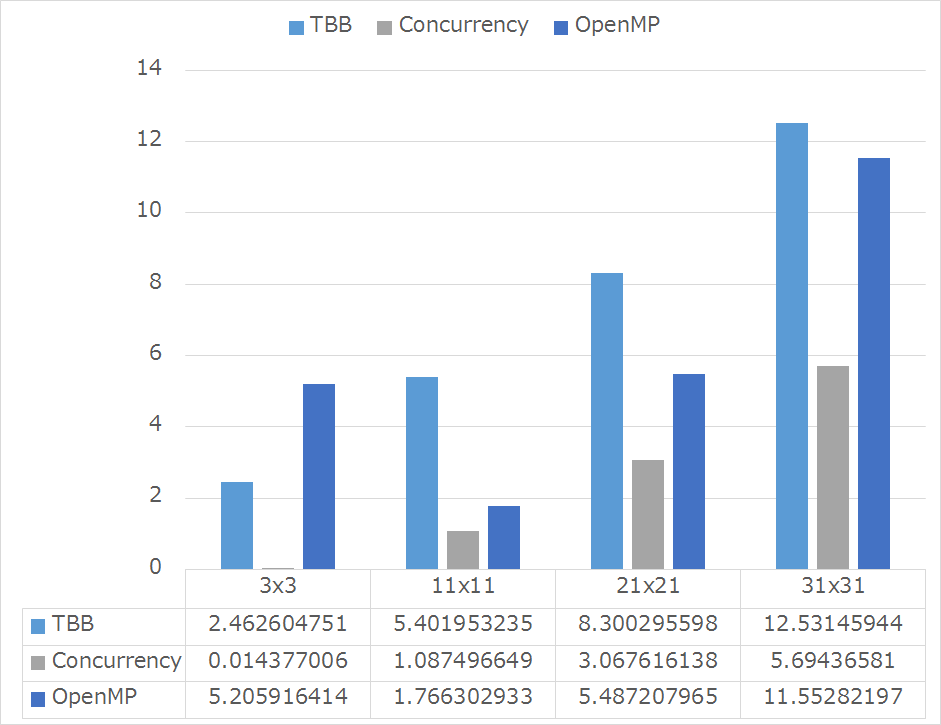
標準偏差
また,計算時間の標準偏差を示します.計算結果の安定性もconcurrencyが高いことが分かります.
まとめ
並列化環境の紹介と比較をしました.
実験の結果Windows環境では,Concurrencyが安定かつ最速であり,しかもデフォルトで入っているということが分かりました.これまではIntelのTBBが無条件にもっとも良いかと思っていたため意外な結果でした.
また,OpenMPは自分で並列化コードを書く場合は,どんな環境でも動くコードを書くことが出来,ディレクティブを使う並列化のため,単純な機構の並列化は非常に簡単に行えるためちょっと試すには都合がよいものです.しかし,OpenMPは,予想通り遅い結果になりました.これは,TBBやConcurrencyなどのディレクティブ形式ではないライブラリは,スレッドプールの管理やタスクスケジューラなどにより,より高速にかつ効率的に並列化できる可能性が高く,逆にコンパイラディレクティブは,スレッドを起こし,管理する機能をOpenMPで持つことが難しいため低速になりやすいためです.クラスを継承して並列化するOpenCVの並列化クラスにおいて,ディレクティブというOpenMPの利便性は完全に殺されているためあえてOpenMPを使う必要は無いでしょう.
今後の課題として,関数ひとつしか評価していないため,もっと他の関数でも評価する必要はあります.また,TBBはもっと速いはずです.おそらくOpenCVのbilateralFilter関数呼び出しの並列化数の管理の出来がわるいため遅くなったのかと思われます.もう少しいろいろな条件や環境でテストしてみたいと思います.もしかしたら,Visual Studio使う上ではConcurrencyが最速なのかもしれない(要確認)
おまけ
ついでに私の作っているライブラリOpenCPも比較対象として比べてみましょう.
下記グラフから,OpenCVにくらべて圧倒的に高速化されていることが分かります(数倍は速くなっています).これは,OpenCVの関数の並列ベクトル化のやり方が余り賢くないため,キャッシュの使い方や効率的なベクトル化をおこなうことで高速化に成功しました.
このライブラリ,マニュアルが無いため,まともに使える状態ではないですが,ヘッダを見て使いたい関数があればテストはそれなりにしているので使ってみてください.