TL;DR
TorchScriptモデルをオーディオプラグイン(VST3)に組み込みます。今回はローパスフィルターを実行するだけのTorchScriptモデルを作成してみます。深層学習フレームワークであるPyTorchを使用していますが、最早AI関係無くなっている点はご了承ください。
検証環境
Windows 10 Home
TorchScriptモデル
学習はPythonを使いたいが、推論はPythonに依存しない環境で行いたいというケースがあります。TorchScriptモデルはC++で実装したアプリケーションに組み込むことが出来ます。Pythonプロセスを使用しないため、Global Interpreter Lockの制約を受けない等のメリットがあります。
ローパスフィルター
今回は5000Hz付近で高周波を遮断するようなローパスフィルターを作成します。今回はscipyでフィルタの係数を取得します。フィルタの種類はたくさんありますが今回はタップ数51の最小二乗フィルタを採用します。
>>> from scipy import signal
>>> signal.firls(51, [0, 5000-20, 5000+20, 22050], [1, 1, 0, 0], fs=44100)
array([-0.01095562, -0.01301457, -0.00864677, 0.0005175 , 0.0102943 ,
0.01579406, 0.01378698, 0.00447676, -0.0082376 , -0.01828739,
-0.02019103, -0.01184368, 0.00399447, 0.0203711 , 0.02891885,
0.02370415, 0.00451808, -0.02194032, -0.0437657 , -0.04803294,
-0.02597099, 0.02291523, 0.08953591, 0.15745786, 0.20805562,
0.22675413, 0.20805562, 0.15745786, 0.08953591, 0.02291523,
-0.02597099, -0.04803294, -0.0437657 , -0.02194032, 0.00451808,
0.02370415, 0.02891885, 0.0203711 , 0.00399447, -0.01184368,
-0.02019103, -0.01828739, -0.0082376 , 0.00447676, 0.01378698,
0.01579406, 0.0102943 , 0.0005175 , -0.00864677, -0.01301457,
-0.01095562])
TorchScriptモデルの作成
ローパスフィルターを実行するTorchScriptモデルを作成します。畳み込み(conv1d)の重みは学習と通して獲得するものですが、先ほどのフィルタの係数を重みとして使用します。
import torch
from scipy import signal
class FIRLS(torch.nn.Module):
def __init__(self, coeffs:torch.Tensor):
super().__init__()
self.register_buffer('weight', coeffs[None, None, :])
self.register_buffer('buffer', torch.zeros((2, 1, coeffs.size(0)-1)))
def forward(self, input:torch.Tensor) -> torch.Tensor:
input = torch.cat((self.buffer, input), dim=2)
output = torch.nn.functional.conv1d(input, weight=self.weight)
self.buffer = input[:,:,-self.buffer.size(2):]
return output
coeffs = signal.firls(51, [0, 5000-20, 5000+20, 22050], [1, 1, 0, 0], fs=44100)
coeffs = torch.from_numpy(coeffs).to(dtype=torch.float32)
model = FIRLS(coeffs)
model_ts = torch.jit.script(model)
torch.jit.save(model_ts, 'firls.pt')
inputとoutputの長さを合わせるため過去のinputをbufferに保持します。LチャンネルとRチャンネルの処理は独立しているため、1チャンネルの音声をバッチサイズ=2だと思って畳み込むことにします。
VST3とは
VSTとは「Virtual Studio Technology」の略称です。Digital Audio Workstation(DAW)と連携可能なプラグインの規格で、エフェクターやシンセサイザー等を自由に実装することが出来ます。
プラグインの配置
以下のパスに配置するのが慣習となっていますのでそれに従うことにします。
| ビルド | パス |
|---|---|
| x64 | C:\Program Files\Common Files\VST3 |
| x86 | C:\Program Files (x86)\Common Files\VST3 |
TorchScriptモデル(firls.pt)はバイナリリソースとしてプラグイン本体に組み込むことも可能ですが、今回は組み込まずはプラグイン本体と同階層に置くことにします。
C:\Program Files\Common Files\VST3
└─advent_calendar_2022.vst3
advent_calendar_2022.vst3 <-- プラグイン本体(これから作成する)
firls.pt <-- TorchScriptモデル
プラグイン本体の拡張子が「vst3」ですが、中身はDLLです。
実装
LibTorchを使ってTorchScriptモデルをVST3プラグインに組み込みます。実装するにあたって重要なところだけを抜粋して説明します。
因みにLibTorchのDLL群はプラグイン本体と同階層に配置すれば良いと思っていたのですがダメでした。LibTorchのDLL群は環境変数のPATHに通しておく必要があります。
プラグイン本体は明示的リンクなのでロード可能なのですが、LibTorchのDLL群は暗黙的リンクであり、プラグイン本体と同階層のDLLは検索の対象外のため見つけられません。
TorchScriptモデルのロード
音声処理が始まる前にTorchScriptモデルを事前にロードしておく必要があります。コンストラクタでロードするのが良いでしょう。
AdventCalendar2022Processor::AdventCalendar2022Processor()
{
// firls.ptの絶対パスを取得する(gPathにはプラグイン本体の絶対パスが格納されている)
auto pt_path = std::filesystem::path(gPath).parent_path() / "firls.pt";
// TorchScriptモデルをロードする
this->module = torch::jit::load(pt_path.string());
this->module.eval();
setControllerClass(AdventCalendar2022ControllerUID);
}
TorchScriptモデルで推論
音声処理ではDAW側がひたすらprocess関数を呼んできます。Tensorのインスタンスを作成して入力bufferをTensorにコピー⇒推論実施⇒推論結果を出力bufferにコピーします。
tresult PLUGIN_API AdventCalendar2022Processor::process(ProcessData& data)
{
if (data.numSamples > 0) {
// make input tensor
at::Tensor input = torch::empty({ 2, 1, data.numSamples }, torch::dtype(torch::kFloat32));
float_t* float_input_data_ptr = static_cast<float_t*>(input.data_ptr());
memcpy(float_input_data_ptr, data.inputs[0].channelBuffers32[0], data.numSamples * (sizeof float_t));
memcpy(float_input_data_ptr + data.numSamples, data.inputs[0].channelBuffers32[1], data.numSamples * (sizeof float_t));
// predict
torch::NoGradGuard guard;
at::Tensor output = this->module.forward({ input }).toTensor();
// copy output data
float_t* float_output_data_ptr = static_cast<float_t*>(output.data_ptr());
memcpy(data.outputs[0].channelBuffers32[0], float_output_data_ptr, data.numSamples * (sizeof float_t));
memcpy(data.outputs[0].channelBuffers32[1], float_output_data_ptr + data.numSamples, data.numSamples * (sizeof float_t));
}
return kResultTrue;
}
音声処理は低負荷であることに越したことはないので、メモリの割り当てや解放が走るような処理は極力避けた方が良さそう。
動作確認
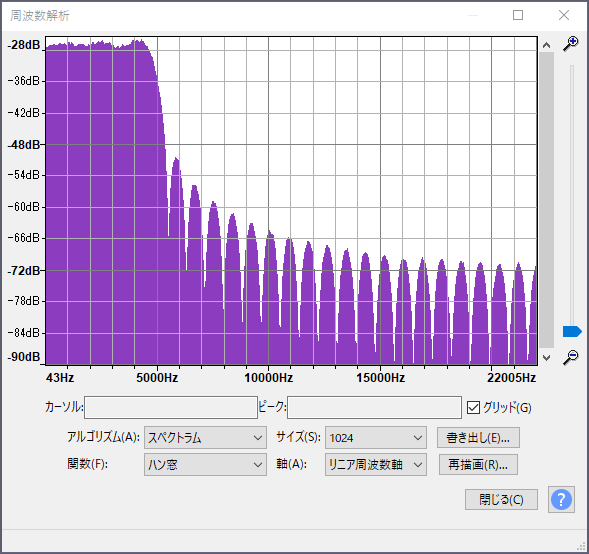
Audacityで今回のプラグインをホワイトノイズに適用し、5000Hz付近で遮断されているかを確認します。
プラグイン実行
今回のプラグインはパラメータ数が0個のため外観は寂しい感じです(独自UI無しの場合はパラメータの数だけスライダー等が配置されます)。今回は「適用」ボタンを押してオフライン処理を行います。因みに「プレビュー」ボタンを押すことによりリアルタイム処理も可能です。
実行結果
適用後にスペクトル解析を行ったところ、期待通り5000Hz付近で遮断されていることが確認出来ました。