こちらの記事は、2020年3月5日 The Cloudflare Blog に投稿された The History of the URLの翻訳記事になります。
うまく日本語に意訳できていない部分が多々あるので,ぜひ修正リクエスト投げていただけると嬉しいです。(リアルな英語難しい...)
The History of the URL (URLの歴史)
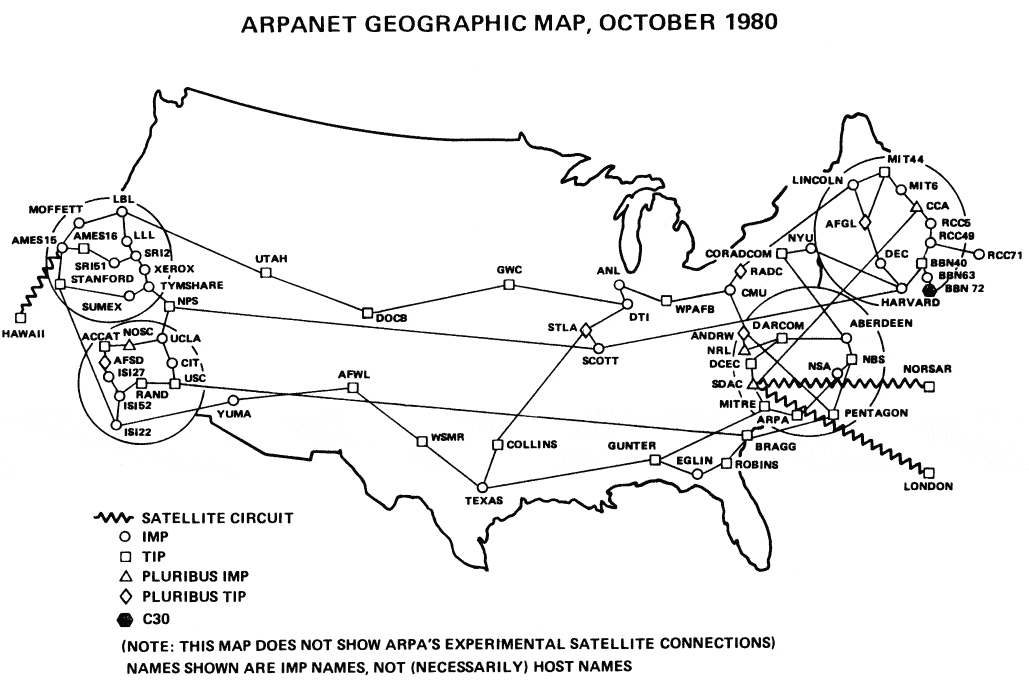
1982年1月11日、22人のコンピューター科学者が集まり「コンピューターメール」(現在のEメール)の問題について議論をしました。(参加者は、Sun Microsystemsの開発者、Zorkの開発者、NTPの人、政府にUnixの支払いを説得する人など)
問題はシンプルで、ARPANET(アーパネット)に455台のホストがあり、それらが制御不能になっていたことでした。

この問題はARPANETがNCPプロトコルから、(現在インターネットと呼んでいる)TCP/IPプロトコルに切り替えようとしているために発生しており
これには「相互に接続された多数のネットワークがあり、ARPANETが独自のドメインを解決し、他のネットワークがそれらを解決する」といった「より階層的な」ドメインシステムが必要になります。
当時の他のネットワークには、「COMSAT」「CHAOSNET」「UCLNET」「INTELPOSTNET」などの名前があり、全米の大学や企業のグループによって運営されていました。

元のARPANETの設計では、中央ネットワークインフォメーションセンター(NIC)が、ネットワーク上のすべてのホストをリストするファイルを管理していました。
このファイルはHOSTS.TXTファイルと呼ばれ、現在のLinuxまたはOS Xシステムの/etc/hostsファイルに似ています。
これはネットワークが変更される度に、NICがネットワーク上のすべてのホストにFTP接続する必要があり、インフラに大きな負荷がかかります。
もちろん、インターネット上のすべてのホストに単一のファイルリストがあれば、無限に拡張することはできません。
ただし、今日の主なアドレス指定の課題であったため、優先度はEメールとなりました。
このような背景から、「必要なドメインまたはドメインのセットだけを外部システムに照会できる階層システムを作成する」という結論に至りました。
議論に参加した彼らの言葉:
結論としては、現在の「user@host」メールボックス識別子を「user@host.domain」に拡張する必要があり、このとき「domain」はドメインの階層になります。」
このようにして、ドメインが誕生しました。
「この決定はドメイン名の将来的な使われ方を見越していた」と思うかもしれませんが、そのイメージは払拭しておきたいところです。
実際のところ、彼らが選んだ解決策は、「既存のシステムの難易度が最も低いもの」がほとんどでした。
たとえば、「電子メールアドレスを<user>.<host>@<domain>の形式にする」といった提案がありましたが
これはユーザー名に「.」文字が含まれていなかった場合は、「zack.cloudflare@com」にメールを送信する可能性があります。
UUCP and the Bang Path
OSの主な機能は、同じオブジェクトに対して複数の異なる名前を定義することなので、異なる名前すべての関係を追跡するのに忙しいことがあると言われています。ネットワークプロトコルにも、いくつか同じ特徴が見られるようです。
— David D. Clark, 1982
別の失敗に終わった提案では、感嘆符(!)でドメインコンポーネントを分離する必要がありました。
たとえば、ARPANET上のISIAホストに接続するには、!ARPA!ISIAに接続します。
その後、ワイルドカードを使用してホストを照会できるため、!ARPA!*はすべてのARPANETホストに戻ります。
このアドレス指定方法は、標準とはまったく異なるものではなく、むしろそれを維持するための試みでした。
感嘆符で区切られたホストのシステムは、1976年に作成されたUUCPと呼ばれるデータ転送ツールにまでさかのぼります。
OS XまたはLinuxコンピューターを使用している読者は、uucpはおそらく端末にインストールされており、利用することができるはずです。
ARPANETは1969年に導入され、(アクセスできる少数の大学や政府機関の間で)すぐに強力なコミュニケーションツールになりましたが
私たちが知っているインターネットは、22年後の1991年まで研究機関の外で公に利用できるようにはなりませんでした。
しかし、それはコンピューターユーザーが通信していないという意味ではありません。

インターネット以前の時代では、一般的なコンピューター間の通信方法は、直接的なポイントツーポイントのダイヤルアップ接続でした。
たとえば、ファイルを送信したい場合は、モデムからモデムを呼び出して、ファイルを転送します。
これを一種のネットワークに作り上げるために、UUCPが生まれました。
このシステムでは、各コンピューターに、認識しているホスト、電話番号、そのホスト上のユーザー名とパスワードをリストしたファイルがあります。
次に、現在のマシンから目的地への「パス」を作成します。このとき、各ホストは次のホストへの接続方法を知っています。
sw-hosts!digital-lobby!zack

このアドレスは、ファイルを送信したり、コンピューターに直接接続したりするだけでなく、電子メールアドレスにもなります。
「メールサーバー」の前のこの時代では、もし受信側のコンピューターの電源がOFFだった場合、送信者はメールを送信できていませんでした。
ARPANETの使用は一流の大学に限定されていましたが、UUCPは私たちのために偽造インターネットを作成しました。
そしてそれはUsenetとBBSシステムの両方の基盤を形成することになりました。
DNS
1983年には、現在も使用されているDNSシステムが提案されます。
たとえば、現在digツールを使用してDNSクエリを実行すると、次のような応答が表示されると思います。
;; ANSWER SECTION:
google.com. 299 IN A 172.217.4.206
これにより、google.comに172.217.4.206でアクセスできることがわかります。
ご存知かもしれませんが、Aはこれが「アドレス」レコードであり、ドメインをIPv4アドレスにマッピングすることを通知しています。
299は「存続可能時間」であり、この値が再度照会されるまでに有効な秒数を通知します。
しかし、INはどういう意味でしょうか。
INは「インターネット」の略です。
このように、この分野は、相互運用が必要な(競合する)コンピューターネットワークがいくつかあった時代にさかのぼります。
その他の潜在的な値は、CHAOSNETのCHまたはAthenaシステムのネームサービスであるHesiodのHSでした。
CHAOSNETは長い間使われていませんが、今日までMITの学生はAthenaの開発が進んだバージョンを使用しています。
DNSクラスのリストはIANAウェブサイトで見つけることができますが、現在では一般的に使用されている潜在的な値は1つだけです。
TLDs (Top Level Domain)
他のTLDが作成されることはほとんどありません。
— John Postel, 1994
ドメイン名を階層的に配置することが決まると、その階層のルートにあるものを決める必要が生じました。
そのルートは伝統的に単一の「.」で表されます。
実際、すべてのドメイン名を「.」で終了することは正しい意味を持ち、Webブラウザーで完璧に機能します。
google.com.
最初のTLDは.arpaでした。
これにより、ユーザーは移行中に古いARPANETホスト名に対処できました。
たとえば、自分のマシンが以前にhfnetとして登録されていた場合、新しいアドレスはhfnet.arpaになります。
それは一時的なものであり、移行中、サーバー管理者は非常に重要な選択を行いました。
5つのTLDのうち、どれを想定しますか?
「.com」「.gov」「.org」「.edu」または「.mil」。
DNSが階層的である場合、たとえば、.comを.comネームサーバーに変え、次にgoogle.comにアクセスする方法を教える一連のルートDNSサーバーがあります。
インターネットのルートDNSゾーンは、13のDNSサーバークラスターで構成されています。
1つのUDPパケットに収まるのはそれだけなので、サーバークラスターは13個しかありません。
歴史的に、DNSはUDPパケットを介して動作してきたため、リクエストへの応答は512バイトを超えることはできません。
; This file holds the information on root name servers needed to
; initialize cache of Internet domain name servers
; (e.g. reference this file in the "cache . "
; configuration file of BIND domain name servers).
;
; This file is made available by InterNIC
; under anonymous FTP as
; file /domain/named.cache
; on server FTP.INTERNIC.NET
; -OR- RS.INTERNIC.NET
;
; last update: March 23, 2016
; related version of root zone: 2016032301
;
; formerly NS.INTERNIC.NET
;
. 3600000 NS A.ROOT-SERVERS.NET.
A.ROOT-SERVERS.NET. 3600000 A 198.41.0.4
A.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:ba3e::2:30
;
; FORMERLY NS1.ISI.EDU
;
. 3600000 NS B.ROOT-SERVERS.NET.
B.ROOT-SERVERS.NET. 3600000 A 192.228.79.201
B.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:84::b
;
; FORMERLY C.PSI.NET
;
. 3600000 NS C.ROOT-SERVERS.NET.
C.ROOT-SERVERS.NET. 3600000 A 192.33.4.12
C.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2::c
;
; FORMERLY TERP.UMD.EDU
;
. 3600000 NS D.ROOT-SERVERS.NET.
D.ROOT-SERVERS.NET. 3600000 A 199.7.91.13
D.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2d::d
;
; FORMERLY NS.NASA.GOV
;
. 3600000 NS E.ROOT-SERVERS.NET.
E.ROOT-SERVERS.NET. 3600000 A 192.203.230.10
;
; FORMERLY NS.ISC.ORG
;
. 3600000 NS F.ROOT-SERVERS.NET.
F.ROOT-SERVERS.NET. 3600000 A 192.5.5.241
F.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2f::f
;
; FORMERLY NS.NIC.DDN.MIL
;
. 3600000 NS G.ROOT-SERVERS.NET.
G.ROOT-SERVERS.NET. 3600000 A 192.112.36.4
;
; FORMERLY AOS.ARL.ARMY.MIL
;
. 3600000 NS H.ROOT-SERVERS.NET.
H.ROOT-SERVERS.NET. 3600000 A 198.97.190.53
H.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:1::53
;
; FORMERLY NIC.NORDU.NET
;
. 3600000 NS I.ROOT-SERVERS.NET.
I.ROOT-SERVERS.NET. 3600000 A 192.36.148.17
I.ROOT-SERVERS.NET. 3600000 AAAA 2001:7fe::53
;
; OPERATED BY VERISIGN, INC.
;
. 3600000 NS J.ROOT-SERVERS.NET.
J.ROOT-SERVERS.NET. 3600000 A 192.58.128.30
J.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:c27::2:30
;
; OPERATED BY RIPE NCC
;
. 3600000 NS K.ROOT-SERVERS.NET.
K.ROOT-SERVERS.NET. 3600000 A 193.0.14.129
K.ROOT-SERVERS.NET. 3600000 AAAA 2001:7fd::1
;
; OPERATED BY ICANN
;
. 3600000 NS L.ROOT-SERVERS.NET.
L.ROOT-SERVERS.NET. 3600000 A 199.7.83.42
L.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:9f::42
;
; OPERATED BY WIDE
;
. 3600000 NS M.ROOT-SERVERS.NET.
M.ROOT-SERVERS.NET. 3600000 A 202.12.27.33
M.ROOT-SERVERS.NET. 3600000 AAAA 2001:dc3::35
; End of file
ルートDNSサーバーは、ロックされたケージ内の金庫で動作しています。
時計は金庫の上にあり、カメラフィードがループしないようにします。
DNSSECの実装がどれほど遅いかを考えると
これらのサーバーに攻撃することで、攻撃者は一部のインターネットユーザーのすべてのインターネットトラフィックをリダイレクトできます。
これは、もちろん、これまでにない最高の強盗映画になります。
当然のことながら、トップレベルのTLDのネームサーバーは実際それほど頻繁には変更されません。
ルートDNSサーバーが受信するリクエストの98%はエラーです。
ほとんどの場合、壊れたクライアントが結果を適切にキャッシュしないためです。
これは非常に問題で、いくつかのルートDNSオペレーターは、ローカルIPアドレスで逆引きDNSルックアップの要求に「go away」を返すために、特別なサーバーを起動する必要がありました。
TLDネームサーバーは、世界中のさまざまな企業や政府によって管理されています(Verisignは.comを管理しています)。
.comドメインを購入すると、約0.18ドルがICANNに、7.85ドルがVerisignに支払われるようになっています。
Punycode
開発者が新しいプロジェクトに付けた愚かな名前が製品版に採用されることはまれです。
会社のデータベースにDelaware(アメリカのすべての会社が登録されている州)という名前を付けることもあります(すべての会社が登録されているためです)が
本番環境に到達するまでにCompanyMetadataDatastoreになることは間違いありません。
Punycodeは、Unicodeをドメイン名にエンコードするために使用するシステムです。
このシステムが解決している問題は簡単です。
最も外部の文字がチルダであるASCIIアルファベットを使用してインターネットシステム全体が構築されたとき、どのように比薩.comを書けると思いますか?
ドメインを切り替えてUnicodeを使用するのは簡単なことではありません。
ドメインを管理する元のドキュメントは、それらがASCIIでエンコードされることを前提としています。
このページを提供するために使用されたCiscoおよびJuniperルーターを含む、過去40年間のインターネットハードウェアはすべて、その前提に立っています。
Web自体は決してASCIIのみではありませんでした。
実際には、すべてのASCII文字を含むISO 8859-1を使用することを最初は考えていましたが、¼などの特殊文字とäなどの特殊マーク付き文字を追加しています。(ただし、非ラテン文字は含まれません)
このHTMLの制限は最終的に2007年に削除され、同じ年にUnicodeがWebで最も人気のある文字セットになりました。
しかし、ドメインはまだASCIIに限定されていました。
ご想像のとおり、Punycodeはこの問題解決において最初の提案ではありませんでした。
皆さんはUTF-8を聞いたことがあると思います。
これは、Unicodeをバイトにエンコードする一般的な方法です(8は1バイトの8ビットを表します)。
2000年に、the Internet Engineering Task ForceのメンバーたちがUTF-5を思いつきました。
このアイデアは、Unicodeを5ビットのチャンクにエンコードすることでした。
そして各5ビットをドメイン名で許可されている文字(A〜Vおよび0〜9)にマッピングできます。
したがって、日本語学習用のWebサイトがあれば、私のサイト日本語.comは不可解なM5E5M72COA9E.comになります。
このエンコード方式にはいくつかの欠点があります。
たとえば、A-Vと0-9は出力エンコーディングで使用されます。
つまり、これらの文字を実際にドメインに含めたい場合は、他のすべての文字と同様にエンコードする必要があります。
これにより、非常に長いドメインがいくつか作成されることになりました。
ドメインの各セグメントが63文字に制限されている場合、これは深刻な問題です。
ミャンマー語のドメインは、15文字以下に制限されます。
このアイデアでは、モールス符号と電報でUnicodeを送信できるようにUTF-5を使用する、という興味深い提案をしています。
また、アドレスバーにM5E5M72COA9E.comを表示するのではなく、適切なUnicode文字で表示できるように、このドメインがエンコードされていることをクライアントに知らせる方法についての課題もありました。
いくつかの提案がありましたが、そのうちの1つはDNS応答で未使用のビットを使用することでした。
これは「ヘッダーの最後の未使用ビット」であり、DNSの人々は「それを断念するのを非常にためらいました」。
別の提案は、ra--でこのエンコード方式を使用してすべてのドメインを開始することでした。
当時(2000年4月中旬)、これらの特定の文字で始まるドメインはありませんでした。
インターネットについて何か知っていれば、提案が公開された直後に誰かがra--domainを登録しました。
2003年に到達した最終的な結論は、エンコードされたドメイン名を大幅に短縮できるデルタ圧縮形式を含むPunycodeという形式を採用することでした。
ドメイン内のすべての文字がUnicode内の同じ一般領域にある可能性が高いため、デルタ圧縮は特に良いアイデアです。
たとえば、ペルシア語の2人のキャラクターは、ペルシア語のキャラクターとヒンディー語の別のキャラクターよりもはるかに近くなります。これがどのように機能するかの例を示すために、ナンセンスなフレーズをとった場合:
يذؽ
非圧縮形式では、3文字[1610、1584、1597]として保存されます(Unicodeコードポイントに基づいて)。これを圧縮するために、最初に数値でソートします(元の文字の場所を追跡します):[1584、1597、1610]。次に、最低値(1584)、およびその値と次の文字(13)の間のデルタ、および次の文字(23)を格納できます。
Punycodeは、これらの整数をドメイン名で許可されている文字に(非常に)効率的にエンコードし、最初にxn--を挿入します。すべてのUnicode文字がドメインの最後で一緒になっていることに気付くでしょう。
値をエンコードするだけでなく、ドメインのASCII部分のどこに挿入するかをエンコードします。
例として、Webサイト熱狗sales.comはxn--sales-r65lm0e.comになります。ブラウザのアドレスバーにUnicodeベースのドメイン名を入力すると、このようにエンコードされます。
この変換は透過的かもしれませんが、それは重大なセキュリティ問題をもたらします。
すべての種類のUnicode文字は、既存のASCII文字とまったく同じように印刷されます。
たとえば、キリル文字の小文字a(「а」)とラテン文字の小文字a(「a」)の違いを見ることはできないでしょう。
キリル文字のamazon.com(xn--mazon-3ve.com)を登録し、あなたをだまして訪問させると、間違ったサイトにいることを知るのが難しくなります。そのため、🍕💩.wsにアクセスすると、ブラウザーのアドレスバーにxn--vi8hiv.wsがやや不自然に表示されます。
Protocol
URLの最初の部分は、アクセスに使用するプロトコルです。
最も一般的なプロトコルはhttpです。
これは、Webを強化するために特別に考案されたTim Berners-Leeの単純なドキュメント転送プロトコルです。
それが唯一の選択肢というわけではありませんでした。
一部の人々は、Gopherを使用するだけだと信じていました。
Gopherは汎用ではなく、ファイルツリーの構造に似た構造化データを送信するように特別に設計されています。
たとえば、/Carsエンドポイントをリクエストすると、次が返されます。
1Chevy Camaro /Archives/cars/cc gopher.cars.com 70
iThe Camero is a classic fake (NULL) 0
iAmerican Muscle car fake (NULL) 0
1Ferrari 451 /Factbook/ferrari/451 gopher.ferrari.net 70
2台の車を識別し、それらに関するいくつかのメタデータと、接続先の詳細を確認できます。
クライアントがこの情報を解析して、エントリをリンク先ページにリンクする使用可能な形式にすることを理解していました。
最初の一般的なプロトコルはFTPで、これは1971年に作成され、リモートコンピューター上のファイルを一覧表示およびダウンロードする方法として使用されました。
Gopherは、これを論理的に拡張したもので、同様のリストを提供しますが、エントリに関するメタデータも読み取る機能が含まれています。
これは、ニュースフィードや単純なデータベースなど、よりリベラルな目的に使用できることを意味していました。
ただし、HTTPとHTMLを特徴付ける自由度と単純さはありませんでした。
HTTPは非常に単純なプロトコルであり、特にFTPなどの代替手段や、現在人気が高まっている HTTP/3 プロトコルと比較した場合に顕著です。
まず、HTTPは完全にテキストベースであり、特注のバイナリの呪文で構成されているのではありません(これにより、大幅に効率的になります)。
Tim Berners-Leeは、テキストベースのフォーマットを使用すると、世代を超えたプログラマーがHTTPベースのアプリケーションの開発とデバッグを簡単に行えるようになることを直感しました。
また、HTTPは送信内容についてほとんど仮定を行いません。
HTML言語に付随して急に開発されたにもかかわらず、コンテンツが任意のタイプであることを指定できます(MIME Content-Typeは当時新しい発明でした)。
プロトコル自体はかなり単純です。
A request:
GET /index.html HTTP/1.1 Host: www.example.com
Might respond:
HTTP/1.1 200 OK
Date: Mon, 23 May 2005 22:38:34 GMT
Content-Type: text/html; charset=UTF-8
Content-Encoding: UTF-8
Content-Length: 138
Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
ETag: "3f80f-1b6-3e1cb03b"
Accept-Ranges: bytes
Connection: close
<html>
<head>
<title>An Example Page</title>
</head>
<body>
Hello World, this is a very simple HTML document.
</body>
</html>
これを状況に当てはめると、インターネットで使用されるネットワークシステムは、IP(インターネットプロトコル)から始まると考えることができます。
IPは、1つのコンピューターから別のコンピューターへの小さなデータパケット(約1500バイト)の取得を担当します。
その上に、TCPがあります。
これは、ドキュメント全体やファイルなどの大きなデータブロックを取得し、多くのIPパケットで確実に送信する役割を果たします。
それに加えて、HTTPやFTPなどのプロトコルを実装します。
これは、TCP(またはUDPなど)を介して送信するデータをわかりやすく意味のあるものにするために使用する形式を指定します。
言い換えれば、TCP/IPはバイトの束全体を別のコンピューターに送信し、プロトコルはそれらのバイトがどうあるべきか、そしてそれらが何を意味するかを伝えます。
必要に応じて独自のプロトコルを作成し、TCPメッセージのバイトを好きなように組み立てることができます。
唯一の要件は、話をしている人が誰でも同じ言語を話すことです。
このため、これらのプロトコルを標準化するのが一般的です。
もちろん、あまり重要ではないプロトコルがたくさんあります。
たとえば、Quote of The Dayプロトコル(ポート17)とRandom Charactersプロトコル(ポート19)があります。
今日では、ばかげているように見えるかもしれませんが、HTTPのような汎用ドキュメント送信フォーマットがいかに重要であったかを示しています。
Port
GopherとHTTPのタイムラインは、デフォルトのポート番号で証明できます。
Gopherは70、HTTPは80です。
HTTPポートは、1990年から1992年の間にTim Berners-Leeの要求で(おそらくIANAのJon Postelによって)割り当てられました。
「ポート番号」を登録するというこの概念は、インターネットよりも前のものです。
ARPANETリモートアドレスに電力を供給した元のNCPプロトコルでは、40ビットで識別されていました。
最初の32は、今日のIPアドレスの動作と同様に、リモートホストを識別しました。
最後の8つはAEN(「もう1つの8ビット番号」の略)として知られており、ポート番号を使用する方法でリモートマシンによって使用され、異なるプロセス宛のメッセージを分離しました。
つまり、アドレスはメッセージの送信先のマシンを指定し、AEN(またはポート番号)はそのリモートマシンにメッセージを取得するアプリケーションを指示します。
彼らは、衝突を制限するために、ユーザーにこれらの「ソケット番号」をすぐに登録するよう要求しました
TCP/IPによってポート番号が16ビットに拡張されたとき、その登録プロセスは継続されました。
プロトコルにはデフォルトのポートがありますが、ローカル開発および同じマシンでの複数のサービスのホスティングを可能にするために、ポートを手動で指定することもできます。
同じ論理がウェブサイトの前にwww.を付ける上の基礎となりました。
当時、「実験的な」ウェブサイトをホストするためだけに、ドメインのルートにアクセスできる人はほとんどいませんでした。
ただし、ユーザーに特定のマシンのホスト名(dx3.cern.ch)を提供すると、そのマシンを交換する必要があるときに問題が発生します。
共通のサブドメイン(www.cern.ch)を使用することにより、必要に応じてそれが指すものを変更できます。
The Bit In-between
おそらくご存知のように、URL構文では、プロトコルとURLの残りの部分の間に二重スラッシュ(//)が挿入されます。
http://cloudflare.com
このダブルスラッシュは、最初のネットワークワークステーションの1つであったApolloコンピューターシステムから継承されました。
Apolloチームには、Tim Berners-Leeと同様の問題がありました。
彼らは、パスが存在するマシンからパスを分離する方法が必要でした。
彼らの解決策は、特別なパス形式を作成することでした:
//computername/file/path/as/usual
TBLはそのスキームをコピーしました。
ちなみに、彼はその決定を後悔し、ドメイン(この場合はexample.com)がパスの最初の部分であることを望んでます。
http:com/example/foo/bar/baz
URLは、ユーザーがWeb上のサイトを識別するための不可解な方法であるようになりました。
残念ながら、URNを標準化することはできなかったため、より便利な命名システムが提供されます。
現在のURLシステムで十分であると主張することは、DOSコマンドラインを賞賛し、ほとんどの人がコマンドライン構文の使用方法を習得するだけでよいと述べるようなものです。
私たちがウィンドウシステムを持っている理由は、コンピューターをより使いやすく、より広く使用するためです。
同じ考え方は、Web上の特定のサイトを見つける優れた方法につながるはずです。
—Dale Dougherty 1996
「インターネット」を理解する方法はいくつかあります。
1つは、コンピューターネットワークを使用して接続されたコンピューターのシステムです。
インターネットのそのバージョンは、1969年にARPANETが作成されて生まれました。
HTTP、HTML、または「Webブラウザー」を作成する前に、メール、ファイル、チャットはすべてそのネットワーク上を移動しました。
1992年、Tim Berners-Leeは3つのものを作成し、インターネットと考えるものを生み出しました。
HTTPプロトコル、HTML、およびURL。彼の目標は、「ハイパーテキスト」を実現することでした。
最も簡単なハイパーテキストは、相互にリンクするドキュメントを作成する機能です。
当時は、ハイパーメディアによって補完されるサイエンスフィクションの万能薬と見なされ、「ハイパー」を前に追加できる他の単語もありました。
ハイパーテキストの重要な要件は、あるドキュメントから別のドキュメントにリンクできることです。
しかし、TBLの時代には、これらのドキュメントは多数の形式でホストされ、GopherやFTPなどのプロトコルを介してアクセスされていました。
彼は、プロトコルをエンコードしたファイル、インターネット上のホスト、およびそのホスト上のどこに存在するファイルを参照するための一貫した方法を必要としていました。
1992年3月の元のWorld-Wide Webプレゼンテーションで、TBLはそれを「Universal Document Identifier」(UDI)として説明しました。
この識別子には、多くの異なる形式が考慮されました。
protocol: aftp host: xxx.yyy.edu path: /pub/doc/README
PR=aftp; H=xx.yy.edu; PA=/pub/doc/README;
PR:aftp/xx.yy.edu/pub/doc/README
/aftp/xx.yy.edu/pub/doc/README
このドキュメントでは、URLでスペースをエンコードする必要がある理由についても説明しています(%20):
空白文字の使用はUDIで回避されています。スペース「>」は有効な文字ではありません。
これは、メールなどのシステムで行が折り返されるときに余分な空白が頻繁に「>」導入されるか、列幅が狭いために「>」が頻繁に発生するため、および「>」がさまざまな形式の空白の相互変換のために行われました。
「>」は、文字コード変換中に発生し、アプリケーション間で「>」テキストを転送します。
最も重要なことは、URLは基本的に、以前は異なる通信システムごとに文脈的に理解する必要があったスキーム、ドメイン、ポート、資格情報、およびパスの組み合わせを参照する単なる省略方法であったことです。
1994年に公開されたRFCで最初に正式に定義されました。
scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
このシステムにより、ハイパーテキスト内からさまざまなシステムを参照できるようになりましたが、事実上すべてのコンテンツがHTTPでホストされるようになったため、もはや必要ではなくなったかもしれません。
1996年には、ブラウザーは既にユーザーにhttp://とwwwを自動的に挿入していました(いまだにこれを含んでいる広告は本当にばかげています)。
Path
質問は、人々がURLの意味を学ぶことができるかどうかだとは思いません。
おばあちゃんやおじいちゃんに、最終的にUNIXファイルシステムの慣習を理解させることは道徳的に嫌いです。
— Israel del Rio 1996
URLのスラッシュで区切られたパスコンポーネントは、ほとんどのユーザーに馴染みがあるはずです。
階層ファイルシステム自体は、MULTICSシステムによって導入されました。
次に、その作成者は、1952年にアルバートアインシュタインと2時間の会話をしたことに起因します。
MULTICSは、大なり記号(>)を使用してファイルパスコンポーネントを分離しました。
例えば:
>usr>bin>local>awk
それは完全に論理的でしたが、残念なことにUnixの人々はリダイレクトを表すために>を使用することに決め、パスの分離をスラッシュ(/)に委任しました。
Snapchat the Supreme Court
違う。 私たちは今、不一致をはっきりと見ています。 あなたと私。
...
個人として、私は異なる目的に異なる基準を使用する権利を留保します。 私は、一般的な作品に、そして特定の翻訳に、そして特定のバージョンに名前を付けたいと思っています。 あなたが提案するよりも豊かな世界が欲しい。 「document」と「variants」の2レベルのシステムに制約されたくありません。
— Tim Berners-Lee 1993
米国最高裁判所の意見で参照されているURLの半分は、もはや存在しないページを指しています。
2001年に書かれた2011年の学術論文を読んでいた場合、特定のURLが無効になる可能性があります。
1993年には、「URNを支持する形でURLは消滅する」という熱烈な信念がありました。
ユニフォームリソース名は、URLとは異なり、変更または破損しないコンテンツの特定の部分への永続的な参照です。
Tim Berners-Leeは、1991年には早くも「緊急の必要性」について最初に説明しました。
URNを作成する最も簡単な方法は、たとえば、urn:791f0de3cfffc6ec7a0aacda2b147839のように、ページのコンテンツの暗号化ハッシュを使用することです。ただし、このハッシュをWebコミュニティの基準に適合させることはできません。
そのハッシュを実際のコンテンツに変えるために誰に頼むのかを実際に理解することは不可能だったからです。
また、同じコンテンツを表すファイル(たとえば圧縮ファイルと非圧縮ファイル)で頻繁に発生する形式の変更も考慮していませんでした。
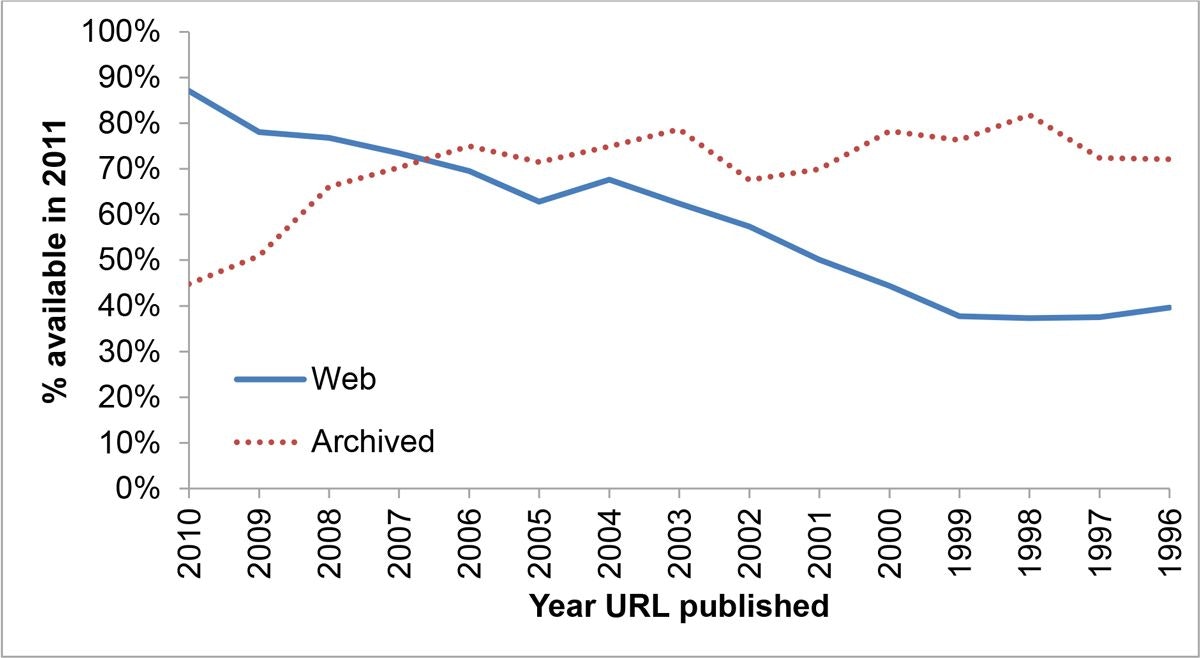
1996年にKeith Shaferと他の数人が、壊れたURLの問題の解決策を提案しました。
このソリューションへのリンクは現在壊れています。
Roy Fieldingは1995年7月に実装提案を投稿しました。
そのリンクは現在壊れています。
これらのページは、機能的にページタイトルを今日のURNにしたGoogleを介して見つけることができました。
URN形式は最終的に1997年に最終決定され、それ以降は基本的に使用されていません。実装自体は興味深いものです。
各URNは2つのコンポーネントで構成されます。
指定されたタイプのURNを解決できる機関と、機関が理解できる形式のこのドキュメントの特定のIDです。
たとえば、urn:isbn:0131103628は本を識別し、ローカルのisbnリゾルバによって(できれば)URLのセットに変換できる永続リンクを形成します。
検索エンジンの能力を考えると、今日最も良いURN形式は、ファイルが以前のURLを指す、といった簡単な方法になる可能性があります。
検索エンジンにこの情報のインデックスを作成させ、必要に応じてリンクさせることができます。
<!-- On http://zack.is/history -->
<link rel="past-url" href="http://zackbloom.com/history.html">
<link rel="past-url" href="http://zack.is/history.html">
Query Params
「application / x-www-form-urlencoded」形式は、多くの点で異常な怪物であり、長年の実装事故と妥協の結果であり、相互運用性に必要な一連の要件につながりますが、良い設計慣行を表すものではありません。
— WhatWG URL Spec
ある程度Webに関わったことがあるならば、クエリパラメータには精通していると思います。
URLのパス部分に従い、?name = zack&state = miのようなオプションをエンコードします。
クエリがアンパサンド文字(&)を使用するのは奇妙に思えるかもしれません。アンパサンド文字(&)は、HTMLで特殊文字のエンコードに使用されるのと同じ文字です。
実際、一定期間HTMLを使用している場合は、URLにアンパサンドをエンコードし、http://host/?x=1&y=2をhttp://host/?x=1&y=2 or http://host?x=1&y=2に変換する必要がありました(常に混乱が生じていました)。
また、Cookieは似ているが異なる形式であることに気づいたかもしれません: x = 1; y = 2
これは実際にはHTML文字エンコードとはまったく競合しません。
このアイデアは、実装者にサポートを促すW3Cでは失われませんでした。(1995年のクエリパラメータの&も同様)
もともと、URLのこのセクションは「インデックス」の検索に厳密に使用されていました。
Webは元々、高エネルギー物理学者のためのコラボレーションの方法を作成しました(そしてその資金はWeb作成に基づいていました)。
これは、Tim Berners-Leeが自分が実際に汎用コミュニケーションツールを作成していることを知らなかったということではありません。
彼は長年、テーブルのサポートを追加していませんでしたが、これはおそらく物理学者が必要としたことでしょう。
いずれにせよ、これらの「物理学者」は、情報をエンコードおよびリンクする方法、およびその情報を検索する方法を必要としていました。
それを提供するために、Tim Berners-Leeはタグを作成しました。
がページに表示された場合、ブラウザはこれが検索可能なページであることを通知します。
ブラウザに検索フィールドが表示され、ユーザーがサーバーにクエリを送信できるようになります。
そのクエリは、プラス文字(+)で区切られたキーワードとしてフォーマットされました。
http://cernvm/FIND/?sgml+cms
このタグは平方根を計算するための入力を提供するなど、多くのことに悪用されました。
これは具体的すぎることから、実際にはタグが必要となりました。
この提案では、実際にはプラス記号を使用して、その他の点では最新のGETクエリのように見えるコンポーネントを分離しています。
http://somehost.somewhere/some/path?x=xxxx+y=yyyy+z=zzzz
これは、広く称賛されるにはほど遠いものでした。
一部の人々は、リンクの反対側のコンテンツは検索可能であるべきだと信じていました。
<a HREF="wais://quake.think.com/INFO" INDEX=1>search</a>
Tim Berners-Leeは、強く型付けされたクエリを定義する方法が必要だと考えました。
<ISINDEX TYPE="iana:/www/classes/query/personalinfo">
いま振り返ると、より一般的なソリューションが勝ったことを嬉しく思います。
の実際の作業は、古いSGMLタイプに基づいて1993年1月に始まりました。
(おそらく残念なことに)入力には別の、より豊かな構造が必要であると判断されました:
<select name=FIELDNAME type=CHOICETYPE [value=VALUE] [help=HELPUDI]>
<choice>item 1
<choice>item 2
<choice>item 3
</select>
興味がある場合は、要素を導入するのではなく、を再利用することが必ず考慮されました。
もちろん、代替形式の提案もあり、そのうちの1つは、Angularを彷彿とさせる変数置換を含んでいます。
<ENTRYBLANK TYPE=int LENGTH=length DEFAULT=default VAR=lval>Prompt</ENTRYBLANK>
<QUESTION TYPE=float DEFAULT=default VAR=lval>Prompt</QUESTION>
<CHOICE DEFAULT=default VAR=lval>
<ALTERNATIVE VAL=value1>Prompt1 ...
<ALTERNATIVE VAL=valuen>Promptn
</CHOICE>
この例では、入力はtypeで指定されたタイプに対してチェックされ、VAR値はページでURLの文字列置換で使用できます。
http://cloudflare.com/apps/$appId
追加の提案では、クエリコンポーネントを分離するために、=ではなく@を実際に使用しました。
name@value+name@(value&value)
彼がMosaicですでに実装したものに基づいて現在の方法を提案したのは、Marc Andreessenでした。
name=value&name=value&name=value
わずか2か月後、Mosaicはmethod = POSTフォームのサポートを追加し、「モダン」なHTMLフォームが生まれました。
もちろん、(別のセパレータを使用して)Cookie形式を作成するのはMarc Andreessenの会社Netscapeでした。
彼らの提案自体は痛々しいほど近視眼的で、Set-Cookie2ヘッダーを導入しようと試み、今日までCloudflareで対処している基本的な構造上の問題を紹介しました。
Fragments
URLの「#」以降に続く部分はフラグメントと呼ばれます。
フラグメントは、URLの一部で、ロードされているページの特定の場所へのリンクに使用されます。
これはURL初期の段階から存在していました。
たとえば、サイトにアンカーがある場合:
<a name="bio"></a>
以下のURLによってアクセスできます。
この概念は、(アンカーではなく)要素に徐々に拡張され、name属性ではなくid属性に指定されるようになりました。
<h1 id="bio">Bio</h1>
Tim Berners-Leeは、アメリカの住所との関係により、このキャラクターを使用することにしました(生まれたときはイギリス人であるという事実にもかかわらず)。
Timの言葉:
少なくとも米国の'@'のメールアドレスでは、建物内のアパート番号またはスイート番号に番号記号を使用するのが一般的です。
12 Acacia Av#12は、「12 Acacia Avの建物、そしてその中で知られている12番のユニット」を意味します。
現在、http://www.example.com/foo#barは、「リソースhttp://www.example.com/foo内、その特定のビューはbarとして知られている」という意味になります。
Douglas Englebartによって作成された元のハイパーテキストシステムでも、同じ目的で「#」文字が使用されていました。
これは偶然かもしれませんが、偶然の「アイデアの借り入れ」の場合もあります。
フラグメントはHTTPリクエストに明示的に含まれません。つまり、ブラウザ内にのみ存在します。
この概念は、(pushStateが導入される前に)クライアント側のナビゲーションを実装するときが来たときに非常に価値がありました。
また、フラグメントを実際にサーバーに送信せずにURLに状態を保存する方法を考えるとき、フラグメントは非常に貴重でした。
これはどういう意味でしょうか?一緒に見ていきましょう。
Molehills and Mountains
電子データ交換[sic]には、SGMLと同様にyukkyのような、フォームとフォーム送信を意味する標準全体があります。
私はそれがスペースなしで後方にFortranのように見えることを除いてもうこれ以上知りません。
— Tim Berners-Lee 1993
インターネット標準化団体は、2002年のHTTP 1.1およびHTML 4.01の最終化から、HTML 5が実際に軌道に乗るまで、あまり多くのことを行わなかったという一般的な認識があります。
この期間は、XHTMLの暗黒時代としても知られています(私だけが知っています)。
しかし実際は、標準化の人々は非常に忙しかったです。
彼らはただやっていることで、最終的にはそれほど価値のあることを証明しませんでした。
そのような取り組みの1つがセマンティックWebです。
夢は、リソース記述フレームワーク(社説注:フレームワークを作成しようとするチームから逃げる)を作成し、コンテンツに関するメタデータを普遍的に表現できるようにすることでした。
たとえば、Corvette Stingrayに関する素晴らしいWebページを作成するのではなく、サイズ、色、運転中に取得したスピード違反切符の数を記述したRDFドキュメントを作成できます。
もちろん、これは決して悪い考えではありません。
しかし、フォーマットはXMLベースであり、世界全体を文書化することと、ブラウザーがその文書を使用して有用なことを行うこととの間に大きな「鶏と卵の問題」がありました。
しかし、それは哲学的議論のための強力な環境を提供しました。
そのような議論は少なくとも10年続き、見事なコードネーム「httpRange-14」で知られていました。
httpRange-14は、URLとは何かという根本的な質問に答えようとしました。
URLは常にドキュメントを参照していますか、それとも何かを参照できますか?自分の車を指すURLを取得できますか?
彼らは満足のいく方法でその質問に答えようとしませんでした。
代わりに、303リダイレクトを使用して、ドキュメントではないリンクからリンクをユーザーにポイントする方法と、URLフラグメント(「#」の後のビット)を使用してユーザーをリンクされたデータにポイントできる方法に焦点を当てました。
今日の現実的な考えでは、これはばかげた質問のように思えるかもしれません。
私たちの多くにとって、URLを使用して管理するものであれば何でもURLを使用できます。人々はあなたのものを使用するかしないでしょう。
しかし、セマンティックWebはセマンティクスにしか関心がないので、それは有効でした。
この特定のトピックは、2002年7月1日、2002年7月15日、2002年7月22日、2002年7月29日、2002年9月16日、および2005年までに少なくとも20回議論されました。
その後、2007年と2011年の苦情と2012年の新しい解決策の要請により再開されました。
この質問は、非常に適切な名前が付けられたペダンティックWebグループによって頻繁に議論されました。
発生しなかった1つのことは、あらゆる種類のURLの背後でWebに大量のセマンティックデータが配置されることです。
Auth
ご存知かもしれませんが、URLにユーザー名とパスワードを含めることができます。
http://zack:shhhhhh@zack.is
ブラウザはこの認証データをBase64にエンコードし、ヘッダーとして送信します。
Authentication: Basic emFjazpzaGhoaGho
Base64エンコードの唯一の理由は、ヘッダーで有効でない可能性のある文字を許可することです。
これにより、ユーザー名とパスワードの値が不明瞭になりません。
特にSSL以前のインターネットでは、これは非常に問題がありました。
接続を盗聴できる人は誰でも簡単にパスワードを見ることができます。
Kerberosは、当時も現在も広く使用されているセキュリティプロトコルです。
ただし、これらの例の多くと同様に、ブラウザメーカー(モザイク)が実装するのは簡単な基本認証の提案が最も簡単でした。
これにより、開発者が独自の認証システムを構築するツールを提供されるまで、これが最初で最終的に唯一のソリューションとなりました。
The Web Application
Webアプリケーションの世界では、Webがハイパーリンクであるための基礎を考えるのは少し変だと思います。
これは、あるドキュメントを別のドキュメントにリンクするための方法であり、スタイリング、コード実行、セッション、認証で徐々に強化され、最終的には70年代の多くの研究者が作成しようとした(そして失敗した)ソーシャル共有コンピューティングエクスペリエンスとなりました。
最終的に、結論は当時のプロジェクトやスタートアップと同じように真実であり、重要なのは採用することです。
たとえそれがどんなに滑っても、使ってもらえるなら、あなたはユーザーが必要としているものを作るでしょう。
もちろん、当然のことながら、誰もそれを使用してはいません。
技術的にどれほど健全であるかは関係ありません。
数百万時間の作業に費やされたツールは無数にあり、今日では誰も使用していないのです。