概要
個人開発でAIを駆使してビデオゲームプレイ履歴記録サービス「YouPlayed」を構築しました。公的なゲームデータベースとSPARQLを活用し、文化資源としてユーザのプレイ履歴を保存できます。Vue3+Flask構成で、実践的知見や技術トピック、AIとの協働体験を共有します。
🎯 こんな方におすすめ
- ゲームプレイを記録したい一般ゲーマー
- SPARQLを使った実践例を知りたい技術者
- AIコーディングの効果を検証したい開発者
- ゲーム文化のアーカイブに興味ある研究者
💡 読了後に得られるもの
- メディア芸術DBを活用する具体的な方法
- AIコーディングの実践的な活用法と課題
- ゲーム文化を保存するサービスの設計思想
- モダンなWebアプリの技術スタック選定理由
はじめに
Qiita初投稿になります、fukudakzです。
ゲームやアーカイブ、デジタル人文学を専門に研究しているものです。
ゲーマーの皆さんは、自分がプレイしたビデオゲームを記録・管理し、共有できるプラットフォームがあったら便利だと思いませんか?
「あのひとはあのゲームやってるのかな?」「あれ、部長、キングスフィールドシリーズのマニアじゃないっすか。」
かつて遊んだゲームを、記憶のなかでしか辿れなかった時代は終わりです。
本サービス、同僚との話題が発端になって基本となる構想を8年ほど温めてました。しかし、これまでは個人で実現するにはあまりに壮大でした。転機が訪れたのはごく最近です。生成AIの目覚ましい進化は、Webアプリケーション開発のあり方を根底から変えつつあります。実際にいくつかのAI開発を行うなかで、その有効性を目の当たりにし「いよいよ実装できる」と確信、開発に着手したという経緯です。この記事は、AIコーディング(Cursor, Claude-4-Sonnet) を活用して、わずか3週間ほどでゲーム記録・共有プラットフォーム「YouPlayed」を開発した記録です。その技術アーキテクチャと開発体験やサービスの文化的・学術的位置づけについて概観します。
あなたが子供の頃、最も熱中したゲーム機で遊んだゲームを全部記録しよう -> YouPlayed
🎮 YouPlayedとは
遊んだ証をかたちに、ゲームプレイ史をつむぐ。
YouPlayedは、あらゆるゲーマーのためのプレイ履歴管理プラットフォームです。
ゲーム検索してプレイしたことがあるものや特別に思い入れのあるゲームをクリックしていくだけの単純な構成ですが、いざやってみるとだんだんと記録が溜まっていき、クセになります。
簡単な登録で、あなただけのゲームライフログの構築を始められます。
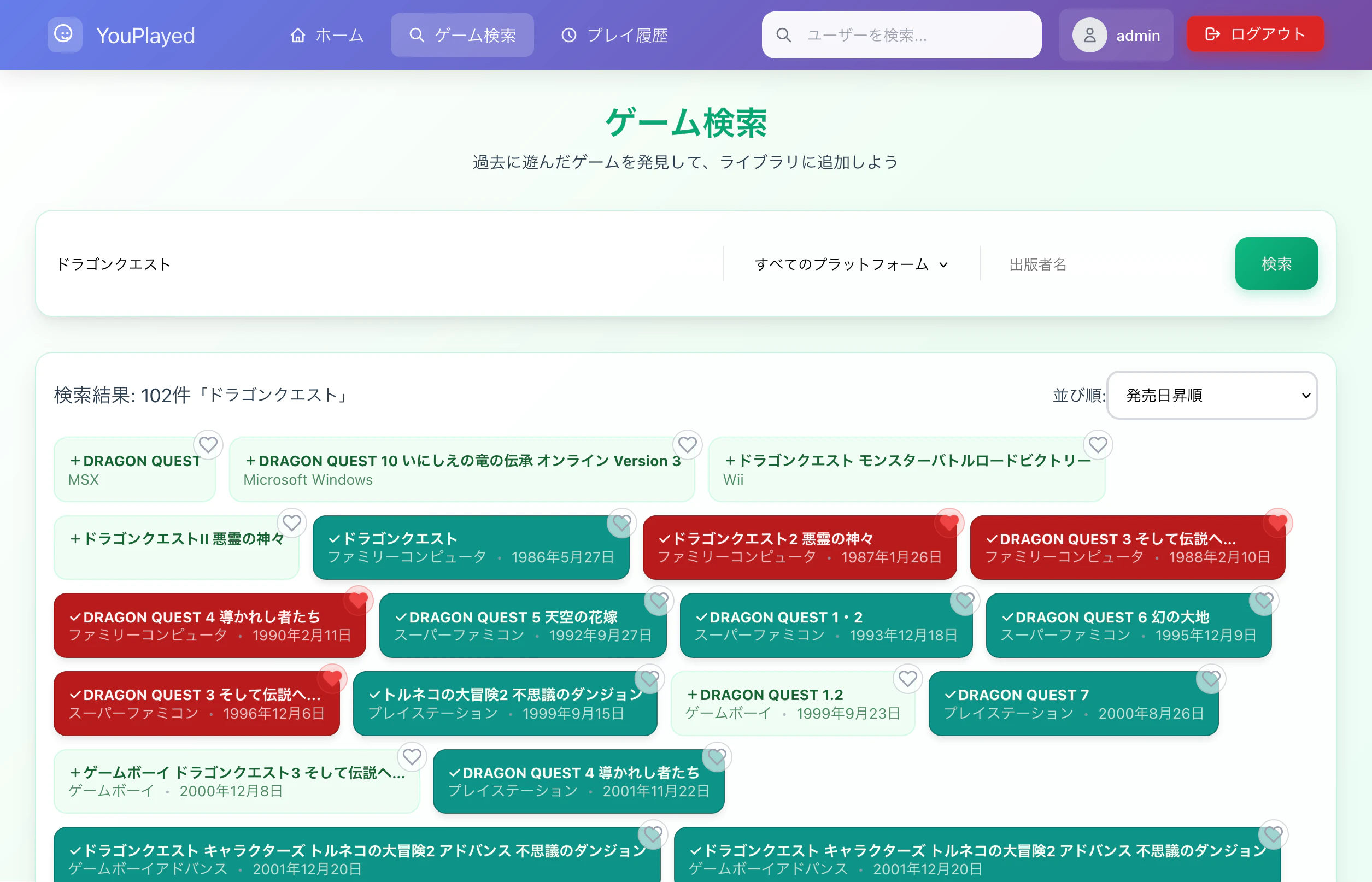
Fig. ゲーム検索画面
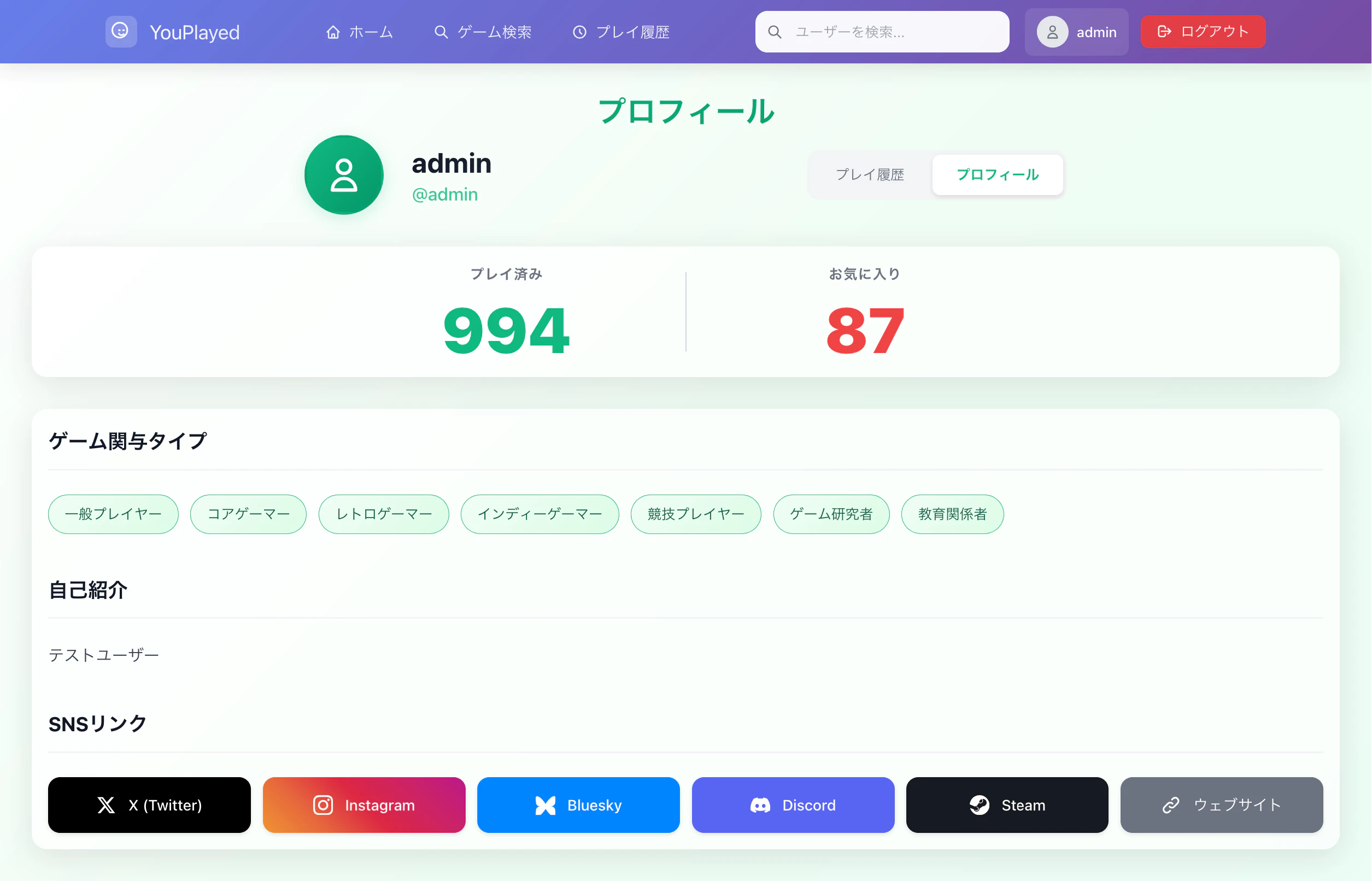
Fig. プロフィール画面
主な機能
- 🎯 ゲーム検索・登録: 豊富なゲームデータベースから検索
- 📊 プレイ状況管理: 「プレイ済み」「お気に入り」などのステータス管理
- 👤 プロフィール機能: SNSリンク、ユーザロール設定
- 🏆 ランキング機能: プレイ数によるユーザランキング
- 📱 レスポンシブデザイン: モバイル・デスクトップ完全対応
🏗️ 技術アーキテクチャ
フロントエンド
Vue.js 3 + TypeScript + Vite
├── Composition API (setup script)
├── Vue Router 4
├── Pinia (状態管理)
├── Tailwind CSS (スタイリング)
└── Axios (HTTP通信)
バックエンド
Python Flask + SQLAlchemy
├── Flask-Login (認証)
├── Flask-CORS (CORS対応)
├── PostgreSQL (データベース)
├── JWT (トークン認証)
└── RESTful API設計
データソース・検索エンジン
SPARQL + メディア芸術データベース
├── Amazon Neptune (グラフデータベース)
├── 全文検索拡張機能 (Neptune Extensions)
├── 高速クエリ処理
└── FlaskによるSPARQLアクセスの定型化
インフラ・デプロイ
さくらVPS + Apache
├── Apache HTTP Server (リバースプロキシ)
├── Let's Encrypt (SSL証明書)
├── systemd (プロセス管理)
└── Git (デプロイ自動化)
🚀 技術的特徴・工夫点
1. SPARQLによるゲームデータ活用
公的データベース「メディア芸術データベース」とのSPARQL連携
YouPlayedの最大の特徴は、以前は文化庁、現在は国立アートリサーチセンターが運営するメディア芸術データベースをSPARQLクエリで活用している点です。Amazon Neptune拡張機能を活用した高速全文検索が可能です。
- メディア芸術データベース・ラボ https://mediag.bunka.go.jp/madb_lab/
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX schema: <https://schema.org/>
PREFIX neptune-fts: <http://aws.amazon.com/neptune/vocab/v01/services/fts#>
PREFIX class: <https://mediaarts-db.artmuseums.go.jp/data/class#>
PREFIX ma: <https://mediaarts-db.artmuseums.go.jp/data/property#>
SELECT DISTINCT ?game ?title ?platform ?releaseDate ?publisher
WHERE {
SERVICE neptune-fts:search {
neptune-fts:config neptune-fts:endpoint "https://vpc-mediaarts-db-qaymrmtqbprlhmqq33a2ncf4ke.ap-northeast-1.es.amazonaws.com" .
neptune-fts:config neptune-fts:field rdfs:label, schema:name, schema:alternateName, ma:variantTitle, schema:gamePlatform, schema:publisher .
neptune-fts:config neptune-fts:queryType "query_string" .
neptune-fts:config neptune-fts:query 'くにお' .
neptune-fts:config neptune-fts:return ?game .
}
?game a class:GamePackage .
?game rdfs:label ?title .
OPTIONAL { ?game schema:gamePlatform ?platform . }
OPTIONAL { ?game schema:datePublished ?releaseDate . }
OPTIONAL { ?game schema:publisher ?publisher . }
}
メディア芸術データベースでは、ゲーム関連の分類として以下のクラスが定義されています:
- ゲーム作品(いわゆるゲームタイトル)
- ゲームバリエーション(ソフトウェアのバージョン違い)
- ゲームパッケージ(実際に販売された製品単位)
- 個別資料(個々の物理コピー)
- ゲーム関連資料(雑誌、攻略本、技術カンファレンスのスライドなど)
このサービスの対象は、この中で最もデータが充実している「ゲームパッケージ」(class: GamePackage)です。これは具体的な製品を指し、「どのゲーム機で遊べるか」「パッケージのイラストは何か」といった、プレイヤーにとって愛着を持ちやすく比較的区別がつきやすい実体(エンティティ)です。当サービスでは、この物理的な側面に焦点を当てることで、利用者にとって直感的に理解しやすいデータ構造を実現しています。
なお、この「ゲームパッケージ」の粒度は、IGDBやWikipedia(Wikidata)などのユーザ参加型データベースとは異なります。それらが「ゲーム作品」(タイトル単位)を基本とするのに対し、当サービスではより細かい「製品単位」を採用しています。主に「ゲームパッケージ isPartOf ゲーム作品」という関係が成り立ちます。ファクトベースでデータを作成するアーカイブ型データベースではゲームパッケージという実体が基準となり得ます。このアプローチを導入することは、当サービスのデータ構造として適切だと考えています。
メディア芸術データベースのメタデータスキーマはこちら -> メディア芸術メタデータスキーマ
データ課題への対応
課題: 最近のゲーム(2020年以降)のデータが不足
- メディア芸術データベースは歴史的なゲーム(レトロゲーム)に強い:今後の増加を期待
- PCゲームやインディーズゲーム/同人ゲームは不足している
- 新しいゲームは外部API(IGDB等)で補完が必要か?
- ユーザ投稿による情報追加機能も今後視野に
- 展望として、実践的なユーザによる検索で、ゲームリソースデータの間違いに気づき、結果として公的なゲームデータレポジトリへのフィードバックにつながることが期待される
2. モダンなフロントエンド設計
Composition APIの活用
// 例:プロフィール管理のロジック
const { userProfile, updateProfile } = useProfile();
const { playHistory, fetchHistory } = useGameHistory();
// リアクティブな状態管理
const playedGamesCount = computed(() =>
userStats.value?.played_games || 0
);
型安全なAPI通信
// 型定義でAPI仕様を明確化
export interface UserProfile {
id: number;
display_name?: string;
discord_handle?: string;
steam_handle?: string;
// ...
}
// APIクライアントの型安全性
const updateProfile = async (data: ProfileUpdateData): Promise<UserProfile> => {
const response = await apiClient.put<ApiResponse<UserProfile>>('/profile', data);
return response.data.profile;
};
3. スケーラブルなバックエンド設計
Blueprint による機能分割
# routes/profile.py
profile_bp = Blueprint('profile', __name__)
@profile_bp.route('/profile', methods=['GET', 'PUT'])
@login_required
def handle_profile():
# プロフィール関連の処理
SQLAlchemy ORM の活用
class UserProfile(db.Model):
__tablename__ = 'user_profiles'
id = db.Column(db.Integer, primary_key=True)
user_id = db.Column(db.Integer, db.ForeignKey('users.id'))
discord_handle = db.Column(db.String(100))
# インデックス最適化
__table_args__ = (
db.Index('idx_user_profile', 'user_id'),
)
4. パフォーマンス最適化
フロントエンド最適化
- コンポーネント遅延読み込み: Vue Router の動的インポート
- 画像最適化: エラーハンドリング付きアバター表示
- 無限スクロール: 大量データの効率的表示
バックエンド最適化
- N+1問題解決: JOINクエリによる最適化
- ページネーション: 大量データの分割取得
- インデックス設計: 検索性能の向上
# 最適化されたランキング取得
ranking_query = db.session.query(
User.id, User.username, UserProfile.display_name,
func.coalesce(played_games_subquery.c.played_games, 0).label('played_games')
).join(UserProfile).outerjoin(played_games_subquery)
SPARQLクエリ最適化
# キャッシュ機能付きSPARQLクエリ
@lru_cache(maxsize=1000)
async def cached_sparql_query(query_hash: str, query: str):
"""SPARQLクエリ結果をキャッシュして高速化"""
return await execute_sparql_query(query)
# バッチ処理による効率化
async def batch_game_enrichment(game_ids: List[str]):
"""複数ゲームの詳細情報を一括取得"""
sparql_query = f"""
SELECT ?game ?title ?platform ?year WHERE {{
VALUES ?game {{ {' '.join(f'<{gid}>' for gid in game_ids)} }}
?game dcterms:title ?title ;
schema:gamePlatform ?platform ;
dcterms:date ?year .
}}
"""
return await cached_sparql_query(hash(sparql_query), sparql_query)
5. UX/UI設計
レスポンシブデザイン
/* Tailwind CSS + カスタムCSS */
.stats-container {
display: flex;
gap: 80px;
}
@media (max-width: 768px) {
.stats-container {
gap: 40px;
flex-direction: column;
}
}
アニメーション・インタラクション
- CSS トランジション による滑らかな UI
- ホバーエフェクト による直感的操作
- ローディング状態の適切な表示
🤖 AIコーディングの活用方法
開発フローの革新
- 要件定義: 自然言語でAIに機能要求を伝達
- 設計相談: アーキテクチャの検討をAIと対話
- コード生成: 具体的な実装をAIが提案・生成
- デバッグ支援: エラー解析と修正案の提示
- リファクタリング: コード品質向上の提案
具体的な活用例
新機能追加(SNSリンク機能)
私: 「Discord、Steam、Twitch、YouTubeのSNSリンクを追加したい」
AI: データベース設計 → API実装 → フロントエンド実装 → 一気通貫で提案
SPARQLクエリ最適化
私: 「ゲーム検索が遅い、SPARQLクエリを最適化したい」
AI: インデックス分析 → クエリ改善案 → キャッシュ戦略 → 包括的解決策
バグ修正
私: 「プロフィール更新で新しいフィールドが保存されない」
AI: 問題特定 → サーバープロセス再起動が必要と判断 → 解決
AIコーディングのメリット
✅ 開発速度の劇的向上: 従来の3-5倍の速度
✅ コード品質の向上: ベストプラクティスの自動適用
✅ 学習効果: 新技術の習得が加速
✅ デバッグ効率化: 問題の早期発見・解決
📊 開発成果
開発期間・工数
- 総開発期間: 約3週間
- 実装機能数: 15+ 主要機能
- コード行数: フロントエンド 3,000行 / バックエンド 2,000行
- AI支援率: 約80%(設計・実装・デバッグ)
技術的成果
- レスポンス速度: API応答時間 < 200ms
- SPARQL検索速度: 平均50ms以下
- SEO対応: メタタグ・構造化データ完備
- セキュリティ: HTTPS、CORS、SQL インジェクション対策
- 可用性: 99.9% アップタイム目標
データ活用成果
- ゲームデータ件数: MADB 50,000件以上
- 検索精度: 複数言語や翻字さらにはバージョン表示など多様なタイトルプロパティを対象とする検索によりヒット率向上
🔧 開発で得られた知見
AIコーディングのコツ
- 明確な要求: 曖昧さを避け、具体的な要件を伝える
- 段階的開発: 大きな機能を小さく分割して実装
- コード理解: AIが生成したコードの動作原理を理解
- テスト重視: AI生成コードも必ずテストを実行
- ドメイン知識共有: SPARQL等の専門技術もAIと協調学習
技術選定の理由
- Vue 3: Composition API による保守性向上
- TypeScript: 型安全性によるバグ削減
- Flask: シンプルで拡張性の高いPythonフレームワーク
- PostgreSQL: リレーショナルデータの整合性確保
- SPARQL + Neptune: 知識グラフ技術による高度なデータ活用
Vue.jsとFlaskを組み合わせたSPA(シングルページアプリケーション)は、一見すると既視感のある技術選択かもしれません。個人開発では、速度が重視されます。Vue.jsとFlaskという成熟した技術スタックは、安定性に優れ、ページ遷移の高速化、豊富なインタラクション、モバイル対応など、ユーザー体験の向上に寄与しました。これはプロジェクトの成功に不可欠な要素であり、ユーザ価値の最大化を目的とした適切な技術選択だったと考えています。
さらに、この構成はグラフデータベース(メディア芸術データベース)とリレーショナルデータベース(PostgreSQL/SQLite)のハイブリッド運用を可能にしています。公的なグラフデータベースにSPARQLでアクセスし、フロントエンドに直接表示するという新規性野高いアプローチも採用しています。この組み合わせにより、ゲーム文化のアーカイブという学術的価値と、実用的なゲーム管理機能の両立を実現しました。
SPARQL活用の課題と対策
課題1: システムスケーラビリティの向上
- 本格運用、とりわけ大規模アクセスに対応できるインフラ基盤の整備
課題2: 最新ゲームデータの不足
対策: ハイブリッドデータソース戦略
- メディア芸術DB(歴史的ゲーム)+ 外部API(最新ゲーム): ただしリソースの粒度が違うので単純に比較もできない → ゲームタイトルとゲーム製品の違い
- ユーザ投稿による情報補完フィードバック
- アーカイブ機関のデータ作成へのゲーマーコミュニティの期待向上とそれによるコミットメント機会増
課題3: SPARQLクエリの複雑性
対策: AIコーディングによる学習支援
- 複雑または特有の語彙を含むクエリはAI生成がむずかしい(この点は私が得意分野だったので自分で書きました)
- ベストプラクティスの自動適用
🌟 今後の展望
短期的改善
- プレイ履歴ゲームランキング設置
- ダンプデータ出力
- ゲーム履歴・プロフィールのSNSシェアボタン追加
- システム安定性強化(高メモリサーバへ引っ越し・DB切り離しなど)
- プッシュ通知機能
- SPARQL検索のメタデータリッチ化
- OAuthによるログイン
長期的ビジョン
- タイトルリストによる一括インポート(候補取得)
- モバイルアプリ化
- 公開データのオープンデータ化
- ゲームレビュー機能の有効化
- AIによるゲーム推薦
- ゲーム統計分析(ユーザクラスタリング、RDF推論エンジン活用など)
- コミュニティ機能拡充
- 外部API連携拡大(Steam、Epic Games等)
- MADBとの連携強化(データ提供・データ構造提案)
知識グラフ技術の発展
- Linked Open Data (LOD) への貢献
- ゲーム分野のオントロジーの開発と評価
- 他の文化遺産データベースとの連携
📈 パフォーマンス詳細
SPARQLクエリ性能
基本検索クエリ: 30-50ms
複雑な推論クエリ: 100-200ms
全文検索クエリ: 20-40ms
バッチ処理: 500件/秒
システム全体性能
ページ読み込み時間: 1.2秒以下
API応答時間: 150ms以下
同時接続数: 1,000ユーザ対応
データベース接続プール: 50接続
🎯 技術的アピールポイント
1. 公的データの活用
- 日本最大級のゲーム文化遺産データベースを活用
- 学術的・文化的価値・信頼性の高いデータソース
- 公的なシステムによる頑健性とフリーにアクセス可能という経済性
2. 知識グラフ技術の実用化
- SPARQL による高度なデータクエリ
- RDFの構造化データ活用
- Linked Data による相互運用性
3. ハイブリッドアーキテクチャ
- リレーショナルDB + グラフDB の使い分け
- 用途に応じた最適なデータストア選択
4. AIコーディングとの親和性
- 複雑なSPARQLクエリもAI支援で効率開発
- 知識グラフ技術の学習コスト削減
- 従来困難だった技術領域への参入障壁低下
🧭 ゲーム文化アーカイブの未来
YouPlayed は、単なる個人のプレイ履歴を記録するだけのサービスではありません。ゲーム文化を未来に残すための「分散型アーカイブ基盤」としての可能性も秘めています。
🎮 プレイ体験の記録が文化資源になる
一人ひとりの「このゲームを遊んだ」という記録は、それ自体が文化的な痕跡です。多くのユーザが記録を残すことで、これまで見えづらかったゲームプレイ文化の実像が立体的に浮かび上がってきます。
- 「どの時代に」「どんなユーザが」「どんなゲームをプレイしていたのか」
- 「お気に入り」や「プレイ済」などの情報が持つ社会的・文化的意味
こうした記録の蓄積は、これからのゲーム史研究にとって欠かせない一次資料となる可能性があります。
✍️ ゲーマー自身が担う「アーカイブの民主化」
これまでゲームの記録は、企業・博物館・アカデミアなど一部の主体に限られていました。
YouPlayedでは、ゲーマー自身が自分のプレイ体験を記録・共有することで、「記録の主体」が多様化します。
- 専門家でなくても、誰もがゲーム文化の記録に参加できる
- 自分のゲーム史を記録することが、文化アーカイブへの参加になる
これは、アーカイブにおける民主化の実践例とも言えるでしょう。
📊 データ分析・教育・再発見への展望
記録が集まれば集まるほど、次のような新たな可能性が開けます:
- ゲーム嗜好の傾向や類型の分析
- 「やり逃していた名作」の再発見
- マーケティングや推薦システムへの応用
- ゲーム文化史や教育分野での活用(例:世代別のプレイ傾向分析)
こうしたデータ活用の分野はまだゲーム・スタディーズでも発展途上であり、YouPlayedはその基盤となる可能性を秘めています。
まとめ
AIコーディングを活用することで、個人開発でも短期間で高品質なWebアプリケーションを構築できることを実証できました。
特に以下の点で大きな価値を感じています:
- 開発速度: 従来の数倍の速度で機能実装
- 品質向上: ベストプラクティスの自動適用
- 学習効果: 新技術の習得が大幅に加速
- 創造性: 技術的制約に縛られず、アイデアに集中
AIコーディングについての印象としては、特にプロトタイピングが爆速で実装できることは素晴らしいと感じます。これをシステムとして実装する上では、使いやすいUI設計、URIの適切な設計、ユーザ管理の仕組み、SNS連携、利用規約、プライバシーポリシーなどの文書等、サービスとして統合的に成り立ちユーザビリティが高いものにするうえで一定の完成まで至るのはやはり大変でした。でも、当然CursorとClaudeによるサポートはこれをかなり低コスト化出来たことは間違いありません。
AIコーディング特有の実践的課題
また、AIは目の前のタスクや、AI自身が仮定したと思われる前提に執着することがあり、開発では驚くほど躓いてハマってしまうこともあります。この開発でも3〜4回ほどAIチャット無限ループに陥りかけました。場合によっては、途中でAIが課題を別のことに設定してしまって、AI「できました!」私「ってもともとの問題わいっ!」という状態に。コードを読み直して問題点を確認したり、メタレベルでの分析で方針を提案し議論をリセットすることで、なんとか抜け出せました。
しかし、特にアイコン(例えば虫メガネマークなど)が画面一杯の巨大表示になるというエラーが本当に幾度も頻発し、ここはむしゃくしゃしてしまいました。この問題は開発の後半にかけても繰り返し生じており、都度修正することに結構なコストがかかりました。
Fig. 巨大表示されたアイコンの例...
勝手に実装がSQLiteに変わっていた事件
もともとの設計ではユーザデータ保存にPostgreSQLをユーザデータの入力用に用いる想定で進めていましたが、いつのまにか実装中にSQLiteに変わってしまっていたこともAI特有のトピックで驚きました。結局、ベータ版リリース直前まではSQLiteによる実装をすすめました。しかも、一方でFlaskによるAPIではRDBとのインターフェース抽象化は進んでおり、公開直前のPostgreSQLへの置換はそこまで手間取らずに済みました。解決策まで先回りして準備しているというのは、面白いものです。
最後に
ともあれメディア芸術データベースとSPARQLの組み合わせにより、単なるゲーム管理ツールを超えた、文化的価値のあるプラットフォームとしてポテンシャルがあるサービス(と私は思っている)を実装できました。
YouPlayed.net は現在β版として運用中です。ゲーマーの皆さん、ぜひ一度お試しください!
触ってみた報告や、機能の要望などコメントも大歓迎です!✅
こちらの記事のコメントか、X(@fukudakz)のほうへよろしくお願いします。
あなたのプレイした1本1本が、未来のゲーム文化をかたち作ります。あなただけのリストを完成させ、1000本ゲーマーへの道を歩み始めましょう!🔥
リンク
- 🌐 サービス: https://youplayed.net
- 🧑🎓 researchmap: https://researchmap.jp/fukudakz
- 📧 X: https://x.com/fukudakz
- 🏛️ メディア芸術データベース: https://mediaarts-db.artmuseums.go.jp/
タグ: #Vue3 #TypeScript #Flask #PostgreSQL #SPARQL #Neptune #NCAR #文化庁 #メディア芸術データベース #セマンティックWeb #知識グラフ #AIコーディング #個人開発 #Webアプリ #デジタル人文学 #ゲームアーカイブ #ビデオゲーム #デジタルゲーム #ゲームスタディーズ