はじめに
こんにちは、くふうカンパニーグループでデータ分析を担当しているfukiです!
最近X(旧twitter)を始めたのでぜひ皆さん交流しましょう〜!(Xはこちら)
さて、この記事ではPythonライブラリであるNetworkXとfoliumを用いて、位置情報データの関連性を視覚化する方法について紹介します。
データを可視化することは、数値の羅列だけでは読み取れない傾向の理解や分析を深めるための重要な要素です。
特に地理的な情報を含むデータではその関係性を地図上に描画することで、パターンやトレンドを直感的に把握することができます。
今回はNetworkXを用いてネットワークデータの関係性をモデル化し、Foliumを使ってこれをインタラクティブな地図上にプロットしてみたのでご紹介します。
ネットワーク分析とは何か?
そもそもネットワーク分析とは何かという方もいらっしゃるかもしれないので、簡単にご説明致します。
ざっくりした大枠としては、「対象(ノード)同士を線(エッジ)で繋いだネットワークを可視化し、関係性を捉えやすくしたもの」です。
この「対象(ノード)」と「線(エッジ)」については何を用いても構いません。
例えば
- SNSのユーザー同士の関係
- 同時に検索されるキーワード(共起キーワード)
なんかがイメージ付きやすいのでは無いでしょうか?
今回はそれを用いてこんな分析をしてみたという内容なので、ネットワーク分析の詳細は割愛させて頂きます。
↓こちらにとても分かり易くまとめている方がいらっしゃったので参考にしてみてください。
分析方法
今回行った分析については大まかに下記のことを行っています。
※実際のデータでは無くダミーのデータを利用しています
- あるエリアにおけるお店の関連度合いを抽出(これは捉えたい関係のものであれば何でもOK)
- 店舗同士の関連度合いをネットワーク分析にする
- 2のネットワークをお店同士の位置情報を用いて地図上にプロット
想定利用シーン
想定利用シーンとしては、位置情報を扱うプラットフォームサービスを提供している会社さんにおいて
- ユーザーの行動把握分析(共起店舗の把握など)
- プラットフォーム利用企業の競合との位置関係把握
のような使い方が出来るのではと思います。
データベースからのデータ集計
分析を始める前のデータ集計として結果的には下記のようなテーブルデータを準備する必要があります。
| 店舗1 | 店舗1の緯度 | 店舗1の経度 | 店舗2 | 店舗2の緯度 | 店舗2の経度 | 関係度合い |
|---|---|---|---|---|---|---|
| A | XXX | YYY | B | XXX | YYY | 100 |
| A | XXX | YYY | C | XXX | YYY | 80 |
| A | XXX | YYY | D | XXX | YYY | 120 |
| B | XXX | YYY | C | XXX | YYY | 50 |
| B | XXX | YYY | D | XXX | YYY | 90 |
| C | XXX | YYY | D | XXX | YYY | 150 |
このようなデータをSQLで集計するにはちょっと工夫が必要で、下記を考慮する必要があります。
- 今回は無向グラフのため店舗同士が逆になったパターンを削除
- 関連性が全く無い情報はデータに入れない
その結果クエリとしてはこんな内容になりました。
with
dummy_shop1_data as (
select
distinct
shop1_name,
shop1_latitude,
shop1_longitude,
shop1_subject -- 対象になる項目
from
shops_info
),
dummy_shop2_data as (
select
distinct
shop2_name,
shop2_latitude,
shop2_longitude,
shop2_subject -- 対象になる項目
from
shops_info
)
select
dummy_shop1_data.shop1_name as shop1_name,
dummy_shop1_data.shop1_latitude as shop1_latitude,
dummy_shop1_data.shop1_longitude as shop1_longitude,
dummy_shop2_data.shop2_name as shop2_name,
dummy_shop2_data.shop2_latitude as shop2_latitude,
dummy_shop2_data.shop2_longitude as shop2_longitude,
count(dummy_shop1_data.shop1_subject) as subject_count -- 関連度合いを集計
from
dummy_shop1_data
join dummy_shop2_data
on dummy_shop1_data.shop1_subject = dummy_shop2_data.shop2_subject
where
dummy_shop1_data.shop1_name < dummy_shop2_data.shop2_name -- 店舗同士が逆のパターンをなくす
group by
dummy_shop1_data.shop1_name,
dummy_shop1_data.shop1_latitude,
dummy_shop1_data.shop1_longitude,
dummy_shop2_data.shop2_name,
dummy_shop2_data.shop2_latitude,
dummy_shop2_data.shop2_longitude
order by
dummy_shop1_data.shop1_name,
dummy_shop2_data.shop2_name;
実装
バージョン情報
以下は、この記事で使用するPythonおよび各種ライブラリのバージョン情報です。
- Python バージョン
- 3.10.12
- 各ライブラリのバージョン
- pandas: 1.5.3
- networkx: 3.3
- matplotlib: 3.7.0
- sklearn: 0.24.2
- geopandas: 0.14.4
- folium: 0.16.0
事前準備
必要なライブラリをインポートします。
# インストール
!pip install geopandas
!pip install networkx
!pip install japanize-matplotlib
!pip install folium
# インポート
import random
import pandas as pd
import networkx as nx
import japanize_matplotlib
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
import geopandas as gpd
import folium
今回はダミーのデータを利用するので、GPT先生にダミーを作成してもらいました(大感謝)
場所は適当にJR中央線の三鷹駅周辺でダミー店舗&位置情報をGPTに生成して頂き、関係値を表すsubject_countはランダムに生成するようにしました。
import pandas as pd
import random
# ダミーデータの作成
data = {
'shop_name1': ['店A', '店A', '店B', '店B', '店C', '店C', '店D', '店E', '店F', '店G', '店H', '店I', '店J', '店K', '店L', '店M', '店N', '店O'],
'shop_name1_latitude': [35.7022, 35.7022, 35.7044, 35.7044, 35.7055, 35.7055, 35.7011, 35.7033, 35.7036, 35.7048, 35.7039, 35.7061, 35.7050, 35.7074, 35.7031, 35.7029, 35.7067, 35.7077],
'shop_name1_longitude': [139.5600, 139.5600, 139.5643, 139.5643, 139.5611, 139.5611, 139.5656, 139.5622, 139.5633, 139.5667, 139.5678, 139.5699, 139.5700, 139.5711, 139.5722, 139.5733, 139.5744, 139.5755],
'shop_name2': ['店B', '店C', '店C', '店D', '店D', '店E', '店E', '店F', '店G', '店A', '店I', '店J', '店A', '店L', '店M', '店N', '店O', '店A'],
'shop_name2_latitude': [35.7044, 35.7055, 35.7055, 35.7011, 35.7011, 35.7033, 35.7033, 35.7036, 35.7048, 35.7022, 35.7061, 35.7050, 35.7022, 35.7031, 35.7029, 35.7067, 35.7077, 35.7022],
'shop_name2_longitude': [139.5643, 139.5611, 139.5611, 139.5656, 139.5656, 139.5622, 139.5622, 139.5633, 139.5667, 139.5600, 139.5699, 139.5700, 139.5600, 139.5722, 139.5733, 139.5744, 139.5755, 139.5600],
'subject_count': [random.randint(1, 200) for _ in range(18)]
}
# DataFrameの作成
dummy_df = pd.DataFrame(data)
# DataFrameの内容を表示
display(dummy_df)
結果として下記のようなデータが出来上がりました。
| shop_name1 | shop_name1_latitude | shop_name1_longitude | shop_name2 | shop_name2_latitude | shop_name2_longitude | subject_count |
|---|---|---|---|---|---|---|
| 店A | 35.7022 | 139.56 | 店B | 35.7044 | 139.5643 | 62 |
| 店A | 35.7022 | 139.56 | 店C | 35.7055 | 139.5611 | 66 |
| 店B | 35.7044 | 139.5643 | 店C | 35.7055 | 139.5611 | 147 |
| 店B | 35.7044 | 139.5643 | 店D | 35.7011 | 139.5656 | 38 |
| 店C | 35.7055 | 139.5611 | 店D | 35.7011 | 139.5656 | 113 |
| 店C | 35.7055 | 139.5611 | 店E | 35.7033 | 139.5622 | 31 |
| 店D | 35.7011 | 139.5656 | 店E | 35.7033 | 139.5622 | 122 |
| 店E | 35.7033 | 139.5622 | 店F | 35.7036 | 139.5633 | 35 |
| 店F | 35.7036 | 139.5633 | 店G | 35.7048 | 139.5667 | 13 |
| 店G | 35.7048 | 139.5667 | 店A | 35.7022 | 139.56 | 186 |
| 店H | 35.7039 | 139.5678 | 店I | 35.7061 | 139.5699 | 68 |
| 店I | 35.7061 | 139.5699 | 店J | 35.705 | 139.57 | 112 |
| 店J | 35.705 | 139.57 | 店A | 35.7022 | 139.56 | 96 |
| 店K | 35.7074 | 139.5711 | 店L | 35.7031 | 139.5722 | 101 |
| 店L | 35.7031 | 139.5722 | 店M | 35.7029 | 139.5733 | 15 |
| 店M | 35.7029 | 139.5733 | 店N | 35.7067 | 139.5744 | 199 |
| 店N | 35.7067 | 139.5744 | 店O | 35.7077 | 139.5755 | 30 |
| 店O | 35.7077 | 139.5755 | 店A | 35.7022 | 139.56 | 141 |
ネットワークの可視化
続いて、上記データを実際に可視化していきます。
シンプルなネットワークの可視化
まずは単純にダミーデータをnetworkxで可視化してみます。
# グラフの作成
G = nx.from_pandas_edgelist(dummy_df, 'shop_name1', 'shop_name2', ['subject_count'])
edge_width = [d['subject_count'] for (u, v, d) in G.edges(data=True)]
# グラフの描画
pos = nx.spring_layout(G)
nx.draw(
G,
pos,
with_labels=True,
node_size=800,
font_family='IPAexGothic' # 日本語フォントを指定
)
plt.show()
出力結果
店舗同士が繋がっていることは分かりますが、その関係性はよくわからないですね。
エッジの強弱を加える
上記のままではせっかく計算した関連性がわからないので、指標の強弱に応じてエッジの太さを調整します。
# グラフの作成
G = nx.from_pandas_edgelist(dummy_df, 'shop_name1', 'shop_name2', ['subject_count'])
edge_width = [d['subject_count'] for (u, v, d) in G.edges(data=True)]
# 指標のsubject_countに応じたエッジの太さの計算(1〜10にスケールさせる)
df_edges = nx.to_pandas_edgelist(G)
scaler = MinMaxScaler(feature_range=(1, 10))
df_edges['subject_count_scaled'] = scaler.fit_transform(df_edges[['subject_count']])
edge_width = df_edges.set_index(['source', 'target'])['subject_count_scaled']
# グラフの描画
pos = nx.spring_layout(G)
nx.draw(
G,
pos,
with_labels=True,
node_size=800,
width=edge_width, # エッジの太さを設定
font_family='IPAexGothic' # 日本語フォントを指定
)
plt.show()
出力結果

多少関連度が分かりやすくなりました。
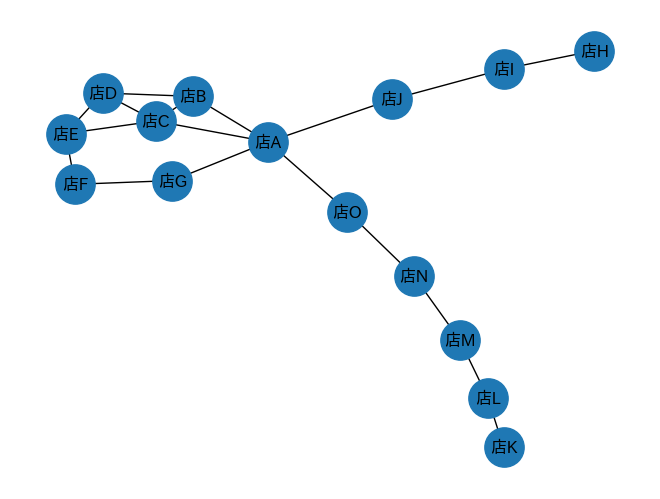
ノードに位置情報を加える
店舗間のそれぞれの関連度合いは見やすくなりましたが、それぞれの位置関係がまだわからないので、ここから更に位置情報(緯度経度)を追加します。
# グラフの作成
G = nx.from_pandas_edgelist(dummy_df, 'shop_name1', 'shop_name2', ['subject_count'])
edge_width = [d['subject_count'] for (u, v, d) in G.edges(data=True)]
# 指標のsubject_countに応じたエッジの太さの計算(1〜10にスケールさせる)
df_edges = nx.to_pandas_edgelist(G)
scaler = MinMaxScaler(feature_range=(1, 10))
df_edges['subject_count_scaled'] = scaler.fit_transform(df_edges[['subject_count']])
edge_width = df_edges.set_index(['source', 'target'])['subject_count_scaled']
# ノードの位置を設定
pos = {}
for node in G.nodes:
# それぞれの位置情報を格納
lat1 = dummy_df.loc[dummy_df['shop_name1'] == node, 'shop_name1_latitude']
lon1 = dummy_df.loc[dummy_df['shop_name1'] == node, 'shop_name1_longitude']
lat2 = dummy_df.loc[dummy_df['shop_name2'] == node, 'shop_name2_latitude']
lon2 = dummy_df.loc[dummy_df['shop_name2'] == node, 'shop_name2_longitude']
# 店舗1カラムに位置情報があればそちらを利用、なければ2から取得してくる
if not lat1.empty and not lon1.empty:
pos[node] = (lat1.values[0], lon1.values[0])
elif not lat2.empty and not lon2.empty:
pos[node] = (lat2.values[0], lon2.values[0])
# グラフの描画
plt.figure(figsize=(10, 10))
nx.draw(
G,
pos,
with_labels=True,
node_size=800,
width=edge_width, # エッジの太さを設定
font_family='IPAexGothic' # 日本語フォントの例
)
plt.show()
出力結果

おおよその位置関係が把握出来るようになりました。
カラーバーの調整
ある程度の位置関係と関連性を確認出来るようになりましたが、位置の配分とカラーバーを調整してもう少し見やすくしたいと思います
# グラフの作成
G = nx.from_pandas_edgelist(dummy_df, 'shop_name1', 'shop_name2', ['subject_count'])
edge_width = [d['subject_count'] for (u, v, d) in G.edges(data=True)]
# 指標のsubject_countに応じたエッジの太さの計算(1〜10にスケールさせる)
df_edges = nx.to_pandas_edgelist(G)
scaler = MinMaxScaler(feature_range=(1, 10))
df_edges['subject_count_scaled'] = scaler.fit_transform(df_edges[['subject_count']])
edge_width = df_edges.set_index(['source', 'target'])['subject_count_scaled']
# カスタムカラーマップ作成
colors = [(0.5, 0.8, 1, 0.7), (1, 0, 0, 0.5)] # 水色から赤へのカラーグラデーション
cmap = LinearSegmentedColormap.from_list('custom_cmap', colors)
# ノードの位置を設定
pos = {}
for node in G.nodes:
# それぞれの位置情報を格納
lat1 = dummy_df.loc[dummy_df['shop_name1'] == node, 'shop_name1_latitude']
lon1 = dummy_df.loc[dummy_df['shop_name1'] == node, 'shop_name1_longitude']
lat2 = dummy_df.loc[dummy_df['shop_name2'] == node, 'shop_name2_latitude']
lon2 = dummy_df.loc[dummy_df['shop_name2'] == node, 'shop_name2_longitude']
# 店舗1カラムに位置情報があればそちらを利用、なければ2から取得してくる
if not lat1.empty and not lon1.empty:
pos[node] = (lat1.values[0], lon1.values[0])
elif not lat2.empty and not lon2.empty:
pos[node] = (lat2.values[0], lon2.values[0])
node_colors = ['#d4d4d4'] # すべてのノードをグレーに指定
# グラフの描画
plt.figure(figsize=(15, 15))
edges = nx.draw_networkx_edges(G, pos, width=edge_width, edge_color=edge_width, edge_cmap=cmap, alpha=0.7)
nodes = nx.draw_networkx_nodes(G, pos, node_size=1000, node_color=node_colors)
nx.draw_networkx_labels(
G,
pos,
font_family='IPAexGothic',
font_size=14
) # ノードにラベルを表示
plt.colorbar(edges) # エッジのカラーバーを表示
plt.show()
出力結果

これによりかなり見やすくなったのでは無いでしょうか。
地図上に描画
ある程度の位置関係まで分かったところでこちらを地図上にプロットしていきます。
import pandas as pd
import folium
from shapely.geometry import Point, LineString
import networkx as nx
import geopandas as gpd
from matplotlib.colors import LinearSegmentedColormap, to_hex
# ネットワークを作成
G = nx.from_pandas_edgelist(dummy_df, 'shop_name1', 'shop_name2', ['subject_count'])
# ノードの位置を設定
pos = {}
for node in G.nodes:
# それぞれの位置情報を格納
lat1 = dummy_df.loc[dummy_df['shop_name1'] == node, 'shop_name1_latitude']
lon1 = dummy_df.loc[dummy_df['shop_name1'] == node, 'shop_name1_longitude']
lat2 = dummy_df.loc[dummy_df['shop_name2'] == node, 'shop_name2_latitude']
lon2 = dummy_df.loc[dummy_df['shop_name2'] == node, 'shop_name2_longitude']
# 店舗1カラムに位置情報があればそちらを利用、なければ2から取得してくる
if not lat1.empty and not lon1.empty:
pos[node] = (lat1.values[0], lon1.values[0])
elif not lat2.empty and not lon2.empty:
pos[node] = (lat2.values[0], lon2.values[0])
# ノードの位置情報をGeoDataFrameに変換
nodes = []
for node, (lat, lon) in pos.items():
nodes.append({'shop_name': node, 'geometry': Point(lon, lat)})
nodes_gdf = gpd.GeoDataFrame(nodes)
# ネットワークのエッジをGeoDataFrameに変換
edges = []
weights = []
for u, v, data in G.edges(data=True):
point_u = Point(pos[u][::-1])
point_v = Point(pos[v][::-1])
edge = LineString([point_u, point_v])
edges.append(edge)
weights.append(data['subject_count'])
edges_gdf = gpd.GeoDataFrame(geometry=edges)
edges_gdf['weight'] = weights
# 'subject_count'の最小値と最大値を取得
min_weight = edges_gdf['weight'].min()
max_weight = edges_gdf['weight'].max()
# 'subject_count' を1から15にスケールする関数を定義
def normalize_weight(value, min_value, max_value, min_scale=1, max_scale=15):
if max_value == min_value:
return min_scale
return min_scale + (value - min_value) * (max_scale - min_scale) / (max_value - min_value)
# カラーマップを定義
cmap = LinearSegmentedColormap.from_list("custom", [(0.678, 0.847, 0.902, 0.3), "red"])
# Folium Mapオブジェクトを作成
loc = [dummy_df['shop_name1_latitude'].mean(), dummy_df['shop_name1_longitude'].mean()] # マップが最初に表示されるセンターポイントを指定
m = folium.Map(location=loc, zoom_start=16)
# エッジを描画
for _, row in edges_gdf.iterrows():
weight = normalize_weight(row['weight'], min_weight, max_weight)
color = to_hex(cmap(weight / 10)) # colormapの範囲を0.1から1にスケーリング
folium.PolyLine(locations=[(row.geometry.xy[1][0], row.geometry.xy[0][0]),
(row.geometry.xy[1][1], row.geometry.xy[0][1])],
color=color, weight=weight, opacity=0.7).add_to(m)
# ノードを描画(店舗名をポップアップとして表示)
for _, row in nodes_gdf.iterrows():
folium.Marker(
location=[row.geometry.y, row.geometry.x],
popup=row['shop_name'] # shop_nameをポップアップ表示として追加
).add_to(m)
m
出力結果
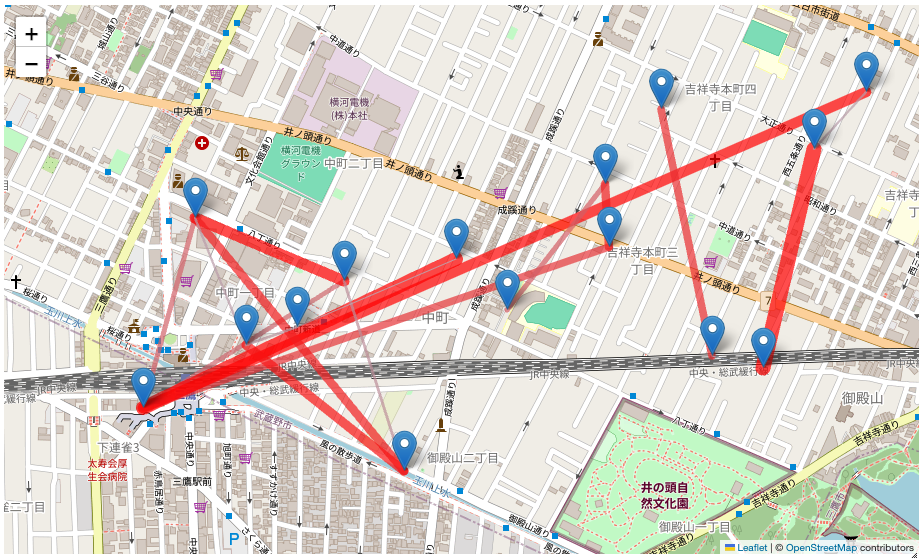
グリグリと動かすこともできます。

店舗名を表示
最後に見え方の好みによりますが店舗名を最初から表示させてみます。
# 必要なライブラリをインポート
import pandas as pd
import folium
from shapely.geometry import Point, LineString
import networkx as nx
import geopandas as gpd
from matplotlib.colors import LinearSegmentedColormap, to_hex
# ネットワークを作成
G = nx.from_pandas_edgelist(dummy_df, 'shop_name1', 'shop_name2', ['subject_count'])
# ノードの位置を設定
pos = {}
for node in G.nodes:
# それぞれの位置情報を格納
lat1 = dummy_df.loc[dummy_df['shop_name1'] == node, 'shop_name1_latitude']
lon1 = dummy_df.loc[dummy_df['shop_name1'] == node, 'shop_name1_longitude']
lat2 = dummy_df.loc[dummy_df['shop_name2'] == node, 'shop_name2_latitude']
lon2 = dummy_df.loc[dummy_df['shop_name2'] == node, 'shop_name2_longitude']
# 店舗1カラムに位置情報があればそちらを利用、なければ2から取得してくる
if not lat1.empty and not lon1.empty:
pos[node] = (lat1.values[0], lon1.values[0])
elif not lat2.empty and not lon2.empty:
pos[node] = (lat2.values[0], lon2.values[0])
# ノードの位置情報をGeoDataFrameに変換
nodes = []
for node, (lat, lon) in pos.items():
nodes.append({'shop_name': node, 'geometry': Point(lon, lat)})
nodes_gdf = gpd.GeoDataFrame(nodes)
# ネットワークのエッジをGeoDataFrameに変換
edges = []
weights = []
for u, v, data in G.edges(data=True):
point_u = Point(pos[u][::-1])
point_v = Point(pos[v][::-1])
edge = LineString([point_u, point_v])
edges.append(edge)
weights.append(data['subject_count'])
edges_gdf = gpd.GeoDataFrame(geometry=edges)
edges_gdf['weight'] = weights
# 'user_count'の最小値と最大値を取得
min_weight = edges_gdf['weight'].min()
max_weight = edges_gdf['weight'].max()
# 'subject_count' を1から15にスケールする関数を定義
def normalize_weight(value, min_value, max_value, min_scale=1, max_scale=15):
if max_value == min_value:
return min_scale
return min_scale + (value - min_value) * (max_scale - min_scale) / (max_value - min_value)
# カラーマップを定義
cmap = LinearSegmentedColormap.from_list("custom", [(0.678, 0.847, 0.902, 0.3), "red"])
# Folium Mapオブジェクトを作成
loc = [dummy_df['shop_name1_latitude'].mean(), dummy_df['shop_name1_longitude'].mean()] # どこか中央の地点を指定
m = folium.Map(location=loc, zoom_start=16)
# エッジを描画
for _, row in edges_gdf.iterrows():
weight = normalize_weight(row['weight'], min_weight, max_weight)
color = to_hex(cmap(weight / 10)) # colormapの範囲を0.1から1にスケーリング
folium.PolyLine(locations=[(row.geometry.xy[1][0], row.geometry.xy[0][0]),
(row.geometry.xy[1][1], row.geometry.xy[0][1])],
color=color, weight=weight, opacity=0.7).add_to(m)
# ノードとラベルを描画
for _, row in nodes_gdf.iterrows():
# ノードを追加
folium.CircleMarker(
location=[row.geometry.y, row.geometry.x],
radius=10, # ノードのサイズ
color='grey', # ノードの色
fill=False
).add_to(m)
# ラベルを追加
folium.map.Marker(
[row.geometry.y, row.geometry.x],
icon=folium.DivIcon(html=f"""<div style="white-space: nowrap; font-size: 10px; color: black;">{row['shop_name']}</div>""")
).add_to(m)
m
出力結果

今回は「店X」という表示方法なのであまり気になりませんが、実際のお店はもう少しテキスト量が多いのでちょっと見づらくなるかもしれないです。
おわりに
今回はNetworkXとFoliumを使用して、位置情報データの関係性を視覚化する手順をご紹介しました。
データの関連性の可視化は、ネットワーク分析だけでも可能ではありますが、地図上にプロットすることで細かい位置関係が把握出来るのでは無いでしょうか。
もしこの記事が皆さんのデータ分析に役立つ一助となれば幸いです。
最後までお読みいただき、ありがとうございました!!