はじめに
広告効果の可視化として、MMM(マーケティングミックスモデリング)というモデルの実装を行いました。
今回の分析データについて
今回の分析はkaggleという機械学習のコンペサイトにある、
各種広告予算と売り上げのデータです
実行環境はkaggle内のnotebookを利用して分析を行います。
データ表示と可視化
- Sales:売上
- TV:TV CMのコスト
- Newspaper:新聞の折り込みチラシのコスト
- Radio:ラジオ広告のコスト
データの読み込み
df = pd.read_csv(
"/kaggle/input/advertising-sales-dataset/Advertising Budget and Sales.csv",
skiprows=1,
names = (
'index','TV','Radio','Newspaper','Sales'
),
parse_dates=['index'], # 指定した列をdatetimeに変換
index_col='index',
)
df
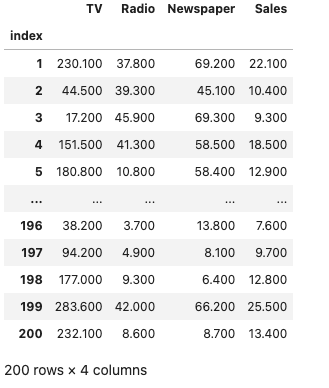
※インデックスとカラムは整理しています
データの可視化
# 変数情報
df.info()
# X, yの指定
X = df.drop(columns=['Sales'])
y = df['Sales']
y.plot(figsize=(10,4))
plt.title('sales')
X.plot(figsize=(10,4))
plt.title('Advertising')
AdStockを考慮したMMM
広告の残存効果(AdStock)を考慮したMMMの実装を行う
飽和効果+キャリーオーバー効果=アドストック
通常の線形モデルでは、広告効果が即座に商品購買に影響を与えると仮定しているが、
実際にはキャリーオーバー効果(ラグ効果、残存効果)があり、効果が遅れて現れるか長く残る可能性がある。
ex)
高価な商品は購買までに検討期間があり、広告に何度も接触した後に購買することもある。
安価な商品でも複数回の広告接触が影響し、後日購買が行われることがある。
線形回帰モデルの通常の仮定では広告コストが増えれば売上も増えるが、現実では収穫逓減により効果が鈍化し飽和する。
アドストック(Ad Stock)という変換器を使って、広告投入量を数値変換し、それを線形回帰モデルの新たな入力として使用して売上を予測する方法が考えられる。
この一連の流れはパイプラインと呼ばれる。
キャリーオーバー効果モデル
キャリーオーバー効果を表現する数理モデルは色々あるが、
最もシンプルな、広告などを打ったときが効果のピークで、徐々に効果が一定の割合で減衰していくモデル
x^*_{t} = \sum^L_{l=0} w_{t-l} \cdot x_{t-l} , \ w_{t-l} = R^t
- $x_t$:t期の広告等の投入量
- $x^*_t$:t期とそれ以前までの広告などの効果の累積(残存効果を足したもの)
- $w$:過去の時点から現在の時点までの間で加重合計するために使用するウェイト
ハイパーパラメータ
- L(length):効果の続く期間 ※当期含まない
- R(rate):減衰率
期間:どのくらいまで考慮するか
ex)
減衰率50%で期間3の場合、以下のようになる
当期:100
次期:50
次々期:25
次次々期:12.5
次次次々期:0
次次次次々期以降:0
ex)
隔期に広告を100打った場合、減少しながら加算される
当期:100
次期:50
次々期:25+100=125
次次々期:12.5+50=62.5
次次次々期:0+25+100=125
次次次次々期:0+12.5+50=62.5
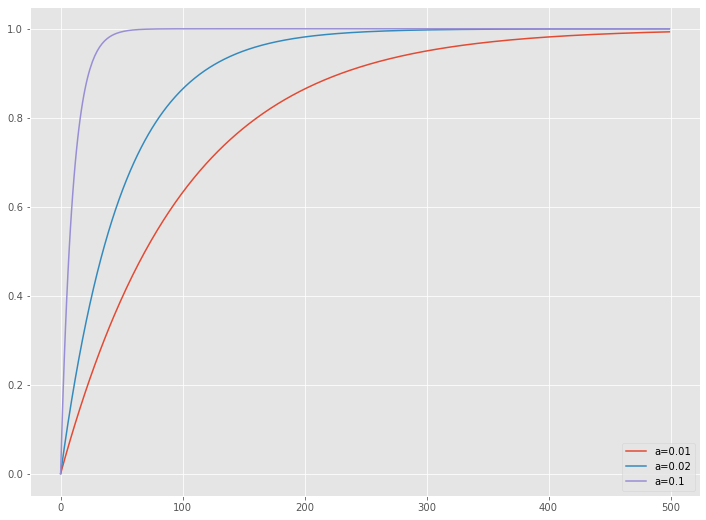
飽和モデル
飽和(収穫逓減)を表現する数理モデルは色々あり、最もシンプルな指数関数でモデル化する
$$1-exp(-ax)$$
$\alpha$:ハイパーパラメータ
↓飽和モデルのイメージ図
- 横軸:広告等の投入量
- 縦軸:効果の大きさ
MMMの実装
飽和モデル、キャリーオーバーモデルの定義
# 飽和モデルの定義
def Saturation(X, a):
return 1- np.exp(-a*X)
# キャリーオーバー効果モデルの定義
def Carryover(X:np.ndarray, rate, length):
filter = (
rate ** np.arange(length + 1)
).reshape(-1,1)
convolution = convolve2d(X, filter) # 二次元フィルタ畳み込みを適応
if length > 0 : convolution = convolution[: -length]# lengthが正なら末尾からlength個の要素を削除
return convolution
飽和モデル、キャリーオーバー効果モデルの活用
飽和モデル、キャリーオーバー効果モデルは単体で利用するわけではなく、下記のように活用する
$$
入力データ→飽和モデル→キャリーオーバー効果モデル→学習器のインプット
$$
# TVCMのハイパーパラメータの設定
TV_carryover_rate = 0.5
TV_carryover_length = 4
TV_saturation_a = 0.000002
# Newspaperのハイパーパラメータの設定
Newspaper_carryover_rate = 0.5
Newspaper_carryover_length = 2
Newspaper_saturation_a = 0.000002
# Webのハイパーパラメータの設定
radio_carryover_rate = 0.5
radio_carryover_length = 0
radio_saturation_a = 0.000002
# 学習器へのインプットの作成
# TVの変換
X_TV = Saturation(
Carryover(
X[['TV']], # 入力
TV_carryover_rate, # 減衰率
TV_carryover_length # 効果期間
),
TV_saturation_a
)
X_Newspaper = Saturation(
Carryover(
X[['Newspaper']], Newspaper_carryover_rate, Newspaper_carryover_length
),
Newspaper_saturation_a
)
X_Radio = Saturation(
Carryover(
X[['Radio']], radio_carryover_rate, radio_carryover_length
),
radio_saturation_a
)
X_trans = pd.DataFrame(
np.concatenate( # np.concatenate():配列を結合(デフォルトは0方向)
[X_TV, X_Newspaper,X_Radio], # 結合する配列
1 # axis=1
)
)
X_trans.columns = ['TVCM','Newspaper','Radio']
X_trans #確認
学習と検証
# クロスバリデーションで精度検証(R2)
lr = LinearRegression()
np.mean(cross_val_score(lr,
X_trans, y,
cv=TimeSeriesSplit()
)
)
>>>出力結果
0.7389849835924769
# 全データで精度検証(R2)
lr.fit(X_trans, y)
lr.score(X_trans, y)
パップライン構築
飽和モデルとキャリーオーパー効果モデルを、パイプラインで利用できる変換器にします。
# ExponentialSaturationという変換器クラスを定義 飽和モデルのパイプラインの一部
class ExponentialSaturation(BaseEstimator, TransformerMixin):
def __init__(self, a=1.0): # 初期化
self.a = a
def fit(self, X, y=None): # 何もせずに返しているがパイプラインの一部として規定
return self
def transform(self, X): # データを入力→出力に変換
return Saturation(X, self.a)
# ExponentialCarryoverという変換器クラスを定義 キャリーオーバー効果モデルのパイプラインの一部
class ExponentialCarryover(BaseEstimator, TransformerMixin):
def __init__(self, rate=0.5, length=1): # 初期化
self.rate = rate
self.length = length
def fit(self, X, y=None):
return self
def transform(self, X:np.ndarray): # データを入力→出力に変換
return Carryover(X, self.rate, self.length)
# Pipelineの構築
adstock = ColumnTransformer(
[
(
'TV_pipe',
Pipeline(
[('carryover', ExponentialCarryover()),('saturation', ExponentialSaturation())]
),
['TV']
),
(
'Newspaper_pipe',
Pipeline(
[('carryover', ExponentialCarryover()),('saturation', ExponentialSaturation())]
),
['Newspaper']
),
(
'Radio_pipe',
Pipeline(
[('carryover', ExponentialCarryover()),('saturation', ExponentialSaturation())]
),
['Radio']
)
],
remainder = 'passthrough'
)
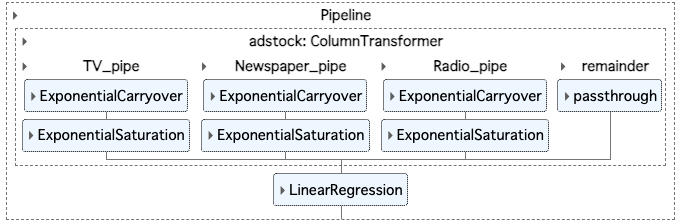
MMM_pipe = Pipeline(
[
('adstock', adstock),
('regression', LinearRegression())
]
)
set_config(display='diagram')
MMM_pipe
ハイパーパラメータの探索
optunaを利用してパラメータの最適化を行います。
# 各モデルのハイパーパラメータの探索範囲を設定
params = {
'adstock__TV_pipe__carryover__rate':FloatDistribution(0, 1),
'adstock__TV_pipe__carryover__length':IntDistribution(0, 6),
'adstock__TV_pipe__saturation__a':FloatDistribution(0, 0.01),
'adstock__Newspaper_pipe__carryover__rate':FloatDistribution(0, 1),
'adstock__Newspaper_pipe__carryover__length':IntDistribution(0, 6),
'adstock__Newspaper_pipe__saturation__a':FloatDistribution(0, 0.01),
'adstock__Radio_pipe__carryover__rate':FloatDistribution(0, 1),
'adstock__Radio_pipe__carryover__length':IntDistribution(0, 6),
'adstock__Radio_pipe__saturation__a':FloatDistribution(0, 0.01),
}
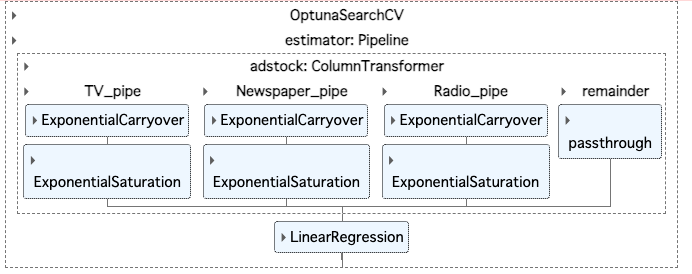
optuna_search = OptunaSearchCV(
estimator = MMM_pipe, # 機械学習モデルの指定
param_distributions=params, # パラメータの指定
n_trials = 1000,
cv = TimeSeriesSplit(),
random_state = 0
)
optuna_search.fit(X, y)
# 探索結果の表示
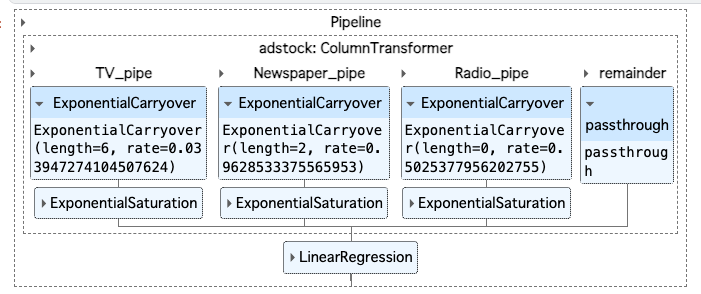
optuna_search.best_params_
>>>出力結果
{'adstock__TV_pipe__carryover__rate': 0.033947274104507624,
'adstock__TV_pipe__carryover__length': 6,
'adstock__TV_pipe__saturation__a': 0.00574531007142841,
'adstock__Newspaper_pipe__carryover__rate': 0.9628533375565953,
'adstock__Newspaper_pipe__carryover__length': 2,
'adstock__Newspaper_pipe__saturation__a': 0.0009740870589822785,
'adstock__Radio_pipe__carryover__rate': 0.5025377956202755,
'adstock__Radio_pipe__carryover__length': 0,
'adstock__Radio_pipe__saturation__a': 1.1646563170445225e-06}
add Codeadd Markdown
# 最適化された学習器
optuna_search.best_estimator_
最適化されたパイプラインでの学習
# 最適化されたパイプラインの構築
best_estimator = optuna_search.best_estimator_
# クロスバリデーションで精度検証(R2)
np.mean(
cross_val_score(
best_estimator,
X, y,
cv = TimeSeriesSplit()
)
)
>>>出力結果
0.9161788979631276
# 全データでの精度検証
best_estimator.fit(X, y)
best_estimator.score(X,y)
>>>出力結果
0.9213117128718895
売り上げ貢献度の算出
線形回帰モデルの確認
# 線形回帰モデルの切片と回帰係数
intercept = best_estimator.named_steps['regression'].intercept_ #切片
coef = best_estimator.named_steps['regression'].coef_ #回帰係数
# 回帰係数をデータフレーム化
weights = pd.Series(
coef,
index=X.columns
)
# 結果出力(切片と係数)
print('Intercept:\n', intercept, sep='')
print()
print('Coefficients:\n',weights, sep='')
>>>出力結果
Intercept:
0.5142938574792009
Coefficients:
TV 17.454
Radio -3.671
Newspaper 168220.798
dtype: float64
# 線形回帰モデルの切片(intercept) を取得しinterceptという変数に格納
# named_steps['regression']:パイプライン中の線形回帰モデルにアクセスしてintercept_属性はこのモデルの切片を取得
intercept = best_estimator.named_steps['regression'].intercept_
# 同様に線形回帰モデルの回帰係数(coef_) を取得しcoefに格納
coef = best_estimator.named_steps['regression'].coef_
# 回帰係数をデータフレームに変換(indexをX.columns (入力変数の列名)を使用)
# 各特徴量に対する線形回帰モデルの回帰係数を取得
weights = pd.Series(
coef,
index=X.columns
)
# 最後に、得られた切片と回帰係数を出力
print('Intercept:\n', intercept, sep='') # 切片の出力
print()
print('Coefficients:\n',weights, sep='') # 係数の出力
>>>出力結果
Intercept:
0.5142938574792009
Coefficients:
TV 17.454
Radio -3.671
Newspaper 168220.798
dtype: float64
売り上げ貢献度の算出
学習し構築したパイプラインの変換器(adstock)を抽出
# Piplineの変換器(adstock)を抽出
adstock = best_estimator.named_steps['adstock']
# 説明変数Xをadstock.transform(X)にて入力変数に変換
X_trans = pd.DataFrame(adstock.transform(X),
index=X.index,
columns=X.columns)
X_trans
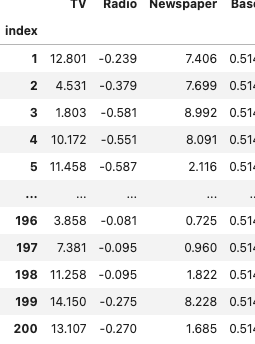
# 補正前の貢献度を算出
unadj_contribution = X_trans.mul(weights) #Xと係数を乗算
unadj_contribution = unadj_contribution.assign(Base=intercept) #切片の追加
unadj_contribution #確認
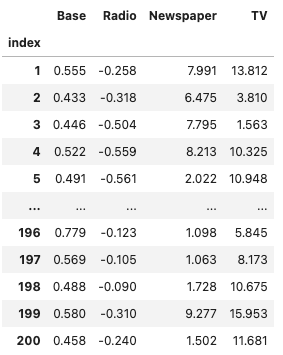
# 貢献度の合計(yの予測値)
y_pred = unadj_contribution.sum(axis=1)
y_pred #確認
>>>出力結果
index
1 20.481
2 12.366
3 10.729
4 18.226
5 13.501
...
196 5.016
197 8.760
198 13.499
199 22.618
200 15.036
Length: 200, dtype: float64
# 実測値の出力
y
>>>出力結果
index
1 22.100
2 10.400
3 9.300
4 18.500
5 12.900
...
196 7.600
197 9.700
198 12.800
199 25.500
200 13.400
Name: Sales, Length: 200, dtype: float64
# 補正係数
correction_factor = y.div(y_pred, axis=0) # .div():要素ごとの除算(割り算)
correction_factor #確認
>>>出力結果
index
1 1.079
2 0.841
3 0.867
4 1.015
5 0.956
...
196 1.515
197 1.107
198 0.948
199 1.127
200 0.891
Length: 200, dtype: float64
補正した貢献度の出力
# 貢献度(補正後)
adj_contribution = (unadj_contribution.mul(# 売上貢献度に補正係数を掛ける
correction_factor,
axis=0
)
)
# 順番の変更
adj_contribution = adj_contribution[['Base', 'Radio', 'Newspaper', 'TV']]
#確認
adj_contribution
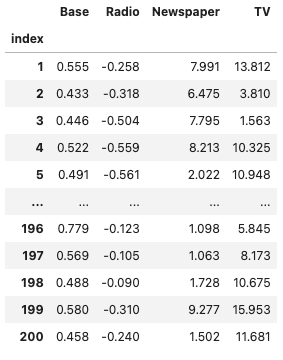
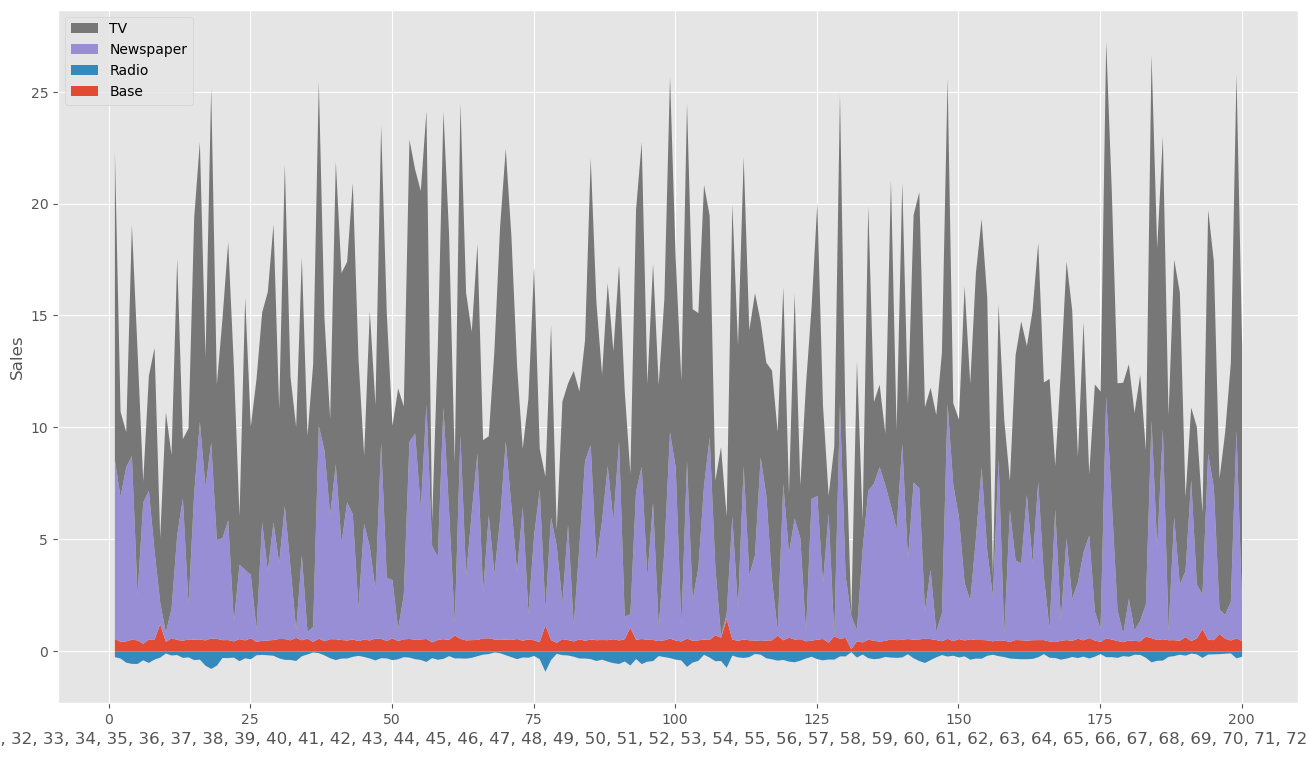
グラフで可視化
時系列ごとに積み上げ棒グラフを表示
# 週×媒体別で積み上げグラフを可視化
ax = (adj_contribution.plot.area(
figsize=(16, 9),
linewidth=0,
ylabel='Sales',
xlabel=adj_contribution.index
)
)
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles[::-1], labels[::-1])
広告ごとに貢献度の可視化
# 媒体別の貢献度の合計
contribution_sum = adj_contribution.sum(axis=0)
#集計結果
print('売上貢献度(円):\n',
contribution_sum,
sep=''
)
print()
print('売上貢献度(構成比):\n',
contribution_sum/contribution_sum.sum(),
sep=''
)
# 棒グラフにて可視化
contribution_sum.plot.bar()
>>>出力結果
売上貢献度(円):
Base 105.851
Radio -61.094
Newspaper 900.760
TV 1858.983
dtype: float64
売上貢献度(構成比):
Base 0.038
Radio -0.022
Newspaper 0.321
TV 0.663
dtype: float64
<Axes: >
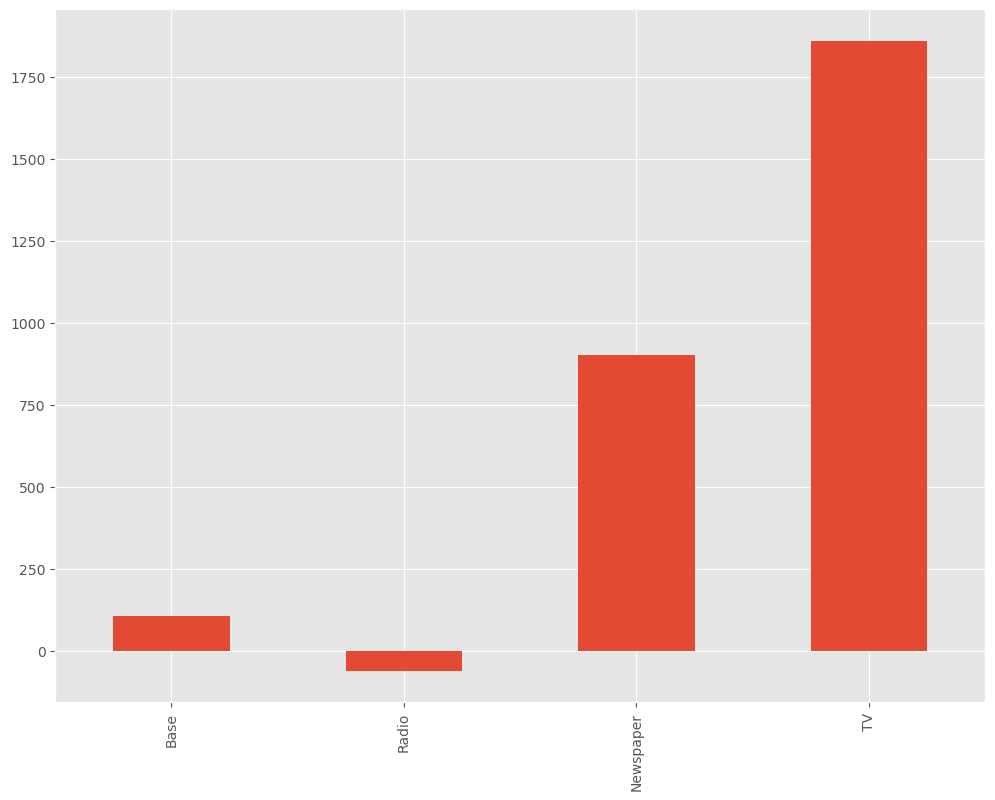
上記より、TV,Newspaperの順で売上影響が大きく、ラジオは費用対効果が悪いことが把握できる