友達の「誰かにプログラミングを教えたい欲」が高まっているらしいので教えてもらうことにした
— ゆーさん (@fukannk0423) July 31, 2020
とりあえず今日は環境構築で終わった
明日は中日ドラゴンズのホームページから選手の成績を持ってきて各選手のOPSを出すプログラムを書く
疲れた、おやすみー
初めまして。同級生の友人がプログラミングを教えてくれると言うので、教えてもらうついでにどこかでアウトプットして成長日記をつけようと思いQiitaを始めました。
やりたいこと
今のところ研究や就職先でPythonを活用する予定がない(後々できるかもしれない)ので、研究やビジネスライクな目的はなく個人的な好奇心のままにコードを書いていきます。
2021.1.14追記
この投稿から半年ほど経って就活生になりましたが、エンジニアの採用を目指すことにしました。
今やっていることも下記のやりたいことリストからかなり離れているので簡単に書いておきます。
- 競技プログラミング(AtCoder)
- 機械学習を使った将棋AIの開発
- その他、おもしろそうなプログラムをいろいろ書いていく
-
Webスクレイピング
- ニュースサイトの最新記事見出しや今日の天気をスクレイピングして毎朝自分の携帯にメールで送る
- 中日ドラゴンズの選手のデータをスクレイピングしてJSON形式のデータベースを作る
-
機械学習(Machine Learning, ML)
- 中日ドラゴンズの明日の采配予想プログラムを組んで実際のオーダーと比較し学習させる
-
データサイエンス
- Kaggleなんかにも手を出せたらいいな(初心者並感)
-
その他、おもしろそうなプログラムをいろいろ書いていく
目標
「自作の中日ドラゴンズの選手の成績データベースから明日の与田采配を予想するプログラムを作成し、実際のオーダーと比較してより正確な予想ができるように学習させる」
当面はこれを目標にいろいろなコードを書いていきたいと思います。
環境
$ python --version
Python 3.8.3
$ conda --version
conda 4.8.3
Anacondaでjupyter notebookを起動してPythonのコードを書いています。
初心者なので環境に何を書いといたらいいか分からない…他に挙げておいた方がいいものがあったら教えてください。
ということで早速冒頭で引用したツイートのプログラムを書いていきましょう。
中日ドラゴンズの選手のデータを公式HPからスクレイピングコピペしてpandasで処理
今日はプログラミング初日ということでWebスクレイピングしたデータを処理していくのはさすがにハードルが高いので、あらかじめ手動で中日ドラゴンズの公式HPからコピペした、2020.8.1現在の中日の選手の打撃成績データをcsvファイルに保存しておき、pandasでいじることにしました。スクレイピングは次回からやっていきます。
# pandasでcsvファイルを読み込んでdf:DataFrameを作る
import pandas as pd
df = pd.read_csv('cd_seiseki2020.csv', encoding='Shift-jis')
# エンコードは指定しないとutf-8で読み込まれてしまい文字化けする
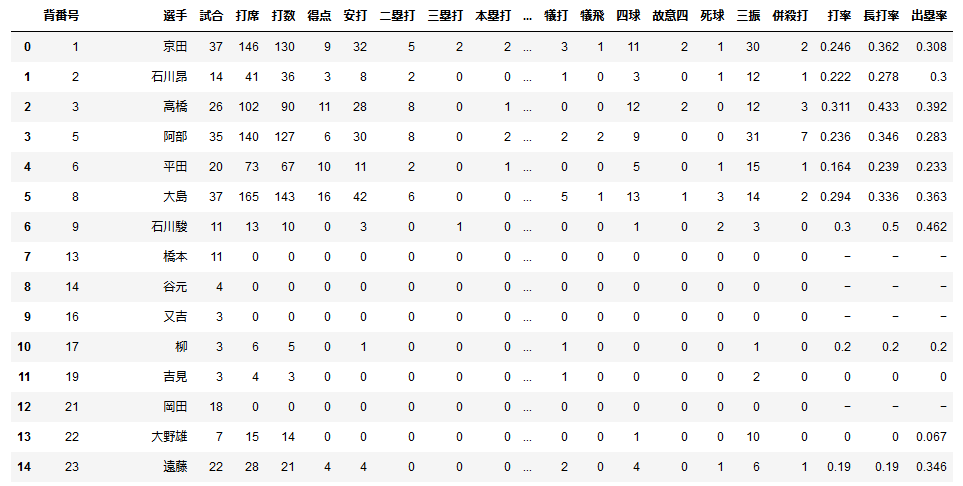
公式サイトと同じような表が作れました。
これだけではちょっと物足りないので、表の出塁率と長打率のデータを基に各選手のOPSを算出してみましょう。
# 表の各要素を数値に変換してOPSを算出
df_2 = df.replace('-', '0')
df_3 = df_2.astype({'出塁率': float, '長打率': float})
df_3['OPS'] = df_3['出塁率'] + df_3['長打率']
df_3
OPSは出塁率と長打率の和なので単純に数字を足せば得られますが、このままだと表の各要素はstring(文字列)なので演算できません(正確には文字列が連結されて0.3080.670のような結果が出てしまいます)。なので文字列を数値に変換する必要があります。
今回は出塁率のような確率を扱うのでfloat(浮動小数点)に変換しています。
その際まだ打席に立っていない選手の出塁率は"-"表記になっていたので、数値に変換できるよう今回は"0"に変換しておきました。
そして新しくOPSの列を作って数値を計算します。
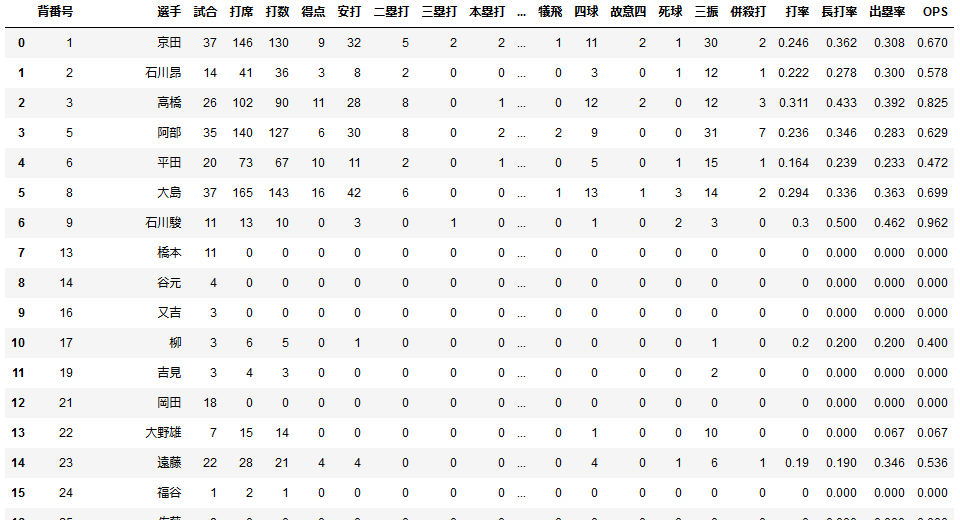
表の一番右側にOPSが表示されました。
このままだと誰のOPSが一番高いのか見にくいので数値の大きい順にソートします。
df_s = df_3.sort_values('OPS', ascending=False)
df_r = df_s.reset_index()
df_r2.index = df_r.index + 1
df_r2
なんかいちいち変数を振りなおしてるのは、jupyternotebookで逐一セルを変えて出力を確認してたからです。
ついでにインデックスも振り直した結果が下の表です。
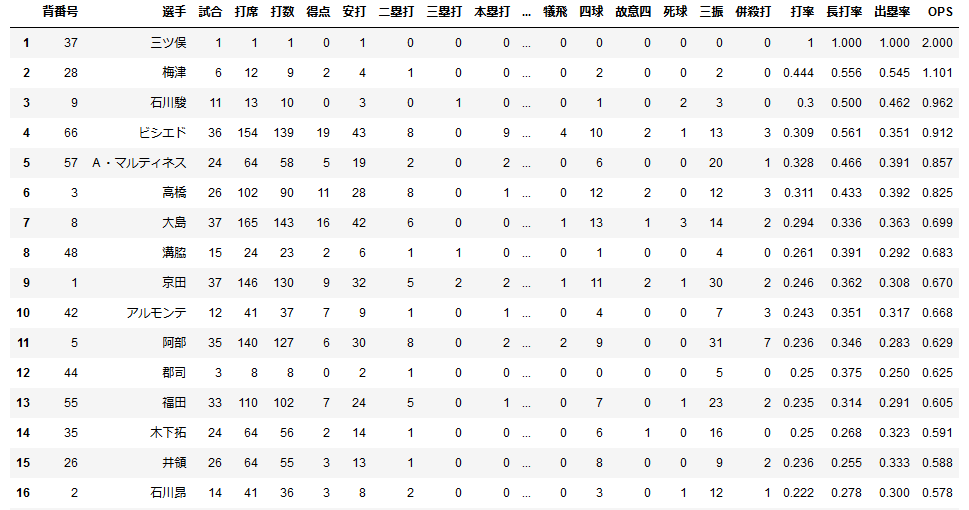
この日は三ツ俣が今季初めて代打で出てきて安打を記録したのでOPS2.000になっていますね。
ある程度打席をこなした選手を見ると、OPSの高い選手はスタメン起用されている選手が多いですね。
打席の数が30以上の選手だけピックアップする処理をしてみてもいいかもしれませんね(面倒なのでやらない)。
最後にDataframeのデータをcsvファイルに出力します。
df_r2.to_csv('cd_ops_out.csv', index=False)
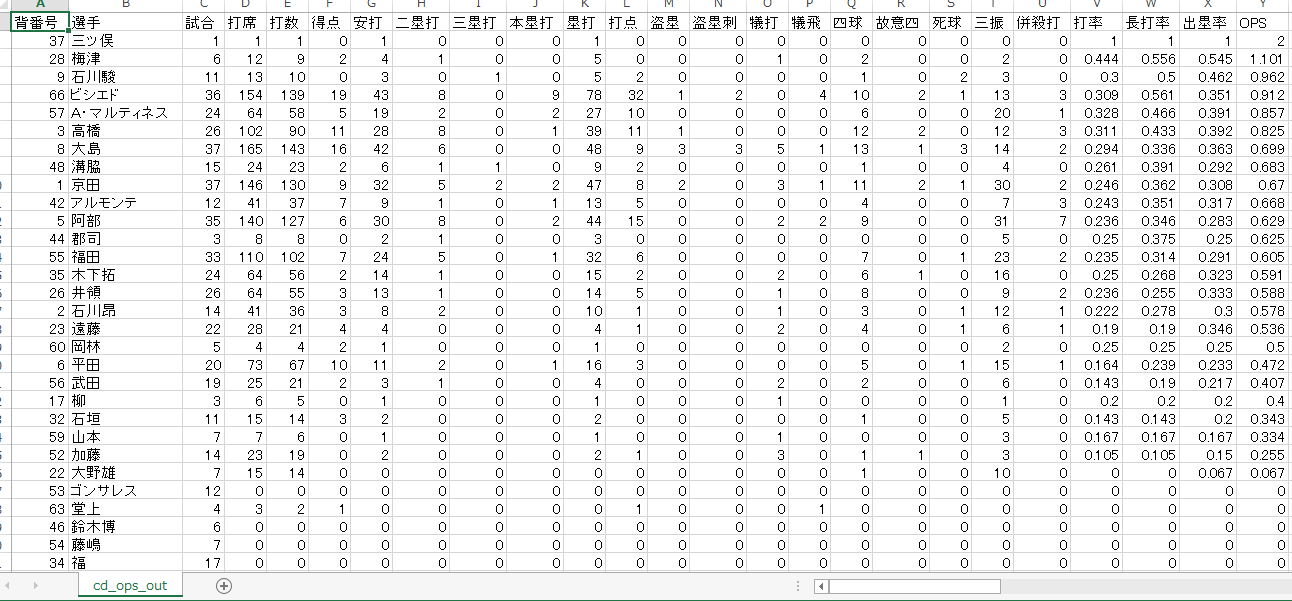
できました。
pandasはデータを扱うときデフォルトでutf-8のエンコーディングを使用しているらしいので、最終的に見る時はShift-JISに変換する必要がありそうです。.to.csv()の引数でエンコーディングの指定もできるそうです。
とりあえず今回はここまでにしました。次回はrequestsやBeautisulSoupモジュールを使って、Webからデータを取得する工程もプログラムに組み込んでいきます。
明日の課題
- requestsやBeautifulSoupを使って自動でWebページからデータを取得する
- pandasのDataFrameやcsvファイルをQiitaでうまく表示する方法を考える(今回はスクショをとったけどマークダウン記法とかとうまく親和したやり方はないのかなあ。誰か教えてください)
おわりに
ウェブサイトによってはスクレイピングは規約で明示的に禁止されていることもあり、サーバーに負荷をかけるようなプログラムを組んでしまうとよくない結果を招くこともありえます。
もし僕のような初心者でWebスクレイピングをやってみたいと思った方は、プログラムの実行には十分気を付けましょう。定期的にサイトから情報を取得するコードなどを組む際は、事前にオフラインのデータを対象に試すなどして高頻度になりすぎていないか確かめましょう。