通常のシステムなどで使用する業務システムと、データ分析するためのシステムの違いについてや、データ分析の用語について自分自身わからないことが多かったのでまとめてみました。
- 業務システムと分析システムの違い
- データ分析の用語
- データ分析手法の紹介
の、3つの観点でまとめています。
業務システムと分析システムの違い
さまざまな情報システムには、おおきく分けると一般的に2つの機能を持つシステムで構成されています。
社内システムやECサイトなどの業務システムと、データを分析するための分析システムです。
それぞれの違いについてみていきます。
アクセス手法の違い
まずは、業務システムなどでデータにアクセスする際の特徴と、分析システムでデータにアクセスする際の特徴の違いについてみていきます。
出典:平山 理 著『絵で見てわかるSQL Serverの仕組み』
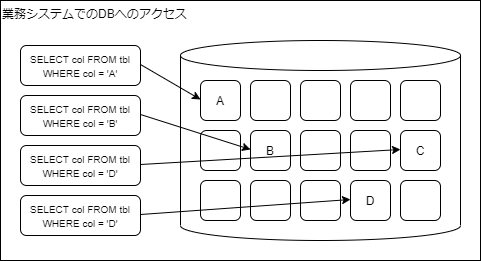
業務システム
社内システムやECサイトなどの業務システムでは、多数のクライアントがアクセスを行い、それぞれが小規模なデータを操作することが多いです。
小規模なトランザクションが多数発生した場合に、迅速にデータを取得したり、大量に発生するI/Oを同時に実行する必要があります。
これに特化した仕組みをOLTP(Online Transaction Processing)といいます。
一般的に、ECサイトやソーシャルゲーム、社内システムはOLTPであることが多いです。
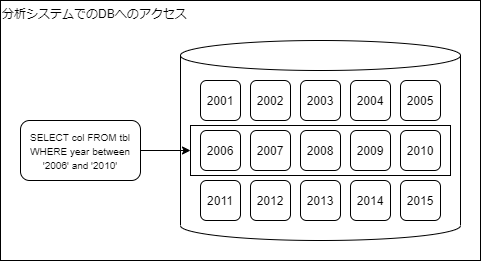
分析システム
一方、データ分析では、少数のクライアントが大規模な読込みを行うことが多いです。「売上データの過去5年分」といった一定の連続性を持ったデータを必要とする傾向が強いです。
これに特化した仕組みをOLAP(Online Analytical Processing)といいます。
データ形態の違い
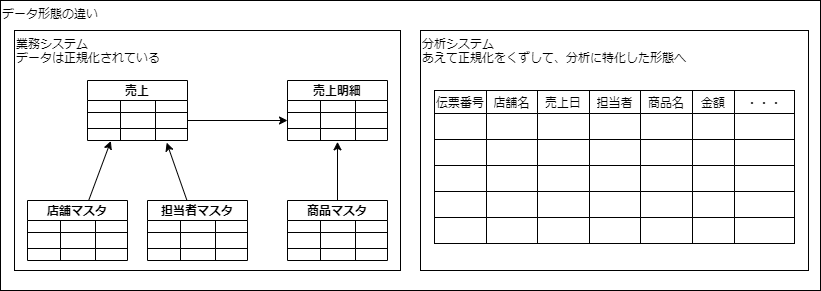
上記で触れたとおり、業務システムでは小規模なトランザクションが大量に発生します。
そのため、一般的にはOLTP用のデータは正規化が進められており、1レコードの中の繰り返し項目は別々のテーブルに分解され、列数が少ない傾向にあります。
しかし、正規化が進められたデータは、数年分といった長い範囲のデータを集計する分析処理には向きません。
なぜなら、必要なデータを得るために、多くのテーブルを複雑な形式で結合する必要があるからです。
なので、分析用にはあえて正規化をくずした形でデータを保持する場合があります。
違いについてまとめ
上記で業務システムと分析システムのデータアクセス手法について触れましたが、それぞれの特徴をまとめたのが以下の図です。
| 特徴 | 業務システム | 分析システム |
|---|---|---|
| データ量 | 小 | 大 |
| データ形式 | 単 | 複 |
| 発生から消費まで | 短 | 長 |
| 同時アクセス | 多 | 少 |
| 正規化 | 高 | 低 |
| 費用 | 小 | 大 |
出典:オンライン トランザクション処理 (OLTP) - Azure Architecture Center | Microsoft Docs
出典:オンライン分析処理(OLAP)-Azure Architecture Center | Microsoft Docs
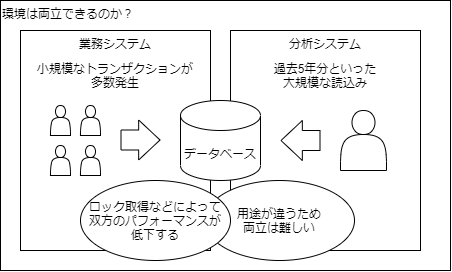
環境は両立できるのか
1つのデータベースで業務システムと分析システムの機能を両立するのは難しいとされています。
なぜならそれぞれの機能に特化するため、データベースの仕組みやハードウェアレベルでチューニングしている事が多いからです。
また、業務システムのデータベース上で分析のクエリを発行すると、データベースに負荷がかかり業務処理に影響が出てしまいます。
これらの理由により、業務システムと分析システムの環境は分けた方がいいとされます。
出典:OLTPとOLAPの違いとは? ~データベースの使用用途による違い~|データ分析用語を解説 - GiXo Ltd.
両立を目指した仕組み
それぞれに特化した環境を分けるのは、それぞれのパフォーマンスを最適化する点でメリットがあります。しかし、2つの環境を構築・維持するのは大きなコストが必要になります。
そこで、1つの環境で実現するために、HTAP(Hybrid Transaction/Analytical Processing)という考え方があります。
例えばSQL Serverで実現するHTAPでは、従来の行ストア型データと列ストアインデックスを組み合わせて使用します。
小規模なトランザクション処理には、B-Treeインデックスを使用してアクセスし、
分析処理には列ストアインデックスを使用してアクセスすることで、両方の処理に最適化した動作が可能になります。
データの規模や処理性能によって、環境をわけるのか、HTAPを取入れるのか、検討してもよいでしょう。
データ分析の用語
データ分析の用語はたくさんあって、どれがどう違うのかがよくわからないので、いくつかまとめてみました。
| 用語 | 意味 |
|---|---|
| ビッグデータ | 従来のデータベース管理システムなどでは記録や保管、解析が難しいような巨大なデータ群。明確な定義があるわけではなく、企業向け情報システムメーカーのマーケティング用語として多用されている。 |
| DWH(Data Ware House) | 企業などの業務上発生した取引記録などのデータを時系列に保管したデータベース。また、そのようなシステムを構築・運用するためのソフトウェア。“warehouse” は「倉庫」の意。 |
| データレイク | データの解析や活用を行うために、形式や規模によらず雑多なデータを一元的に保管しておくためのデータ管理システム。 |
| データマート | 企業などで情報システムに記録・蓄積されたデータから、利用部門や用途、目的などに応じて必要なものだけを抽出、集計し、利用しやすい形に格納したデータベースのこと。「マート」(mart)は「小売店」の意。 |
| データストア | 情報システムの構成で、データを決められた形式で記憶装置に永続的に保存・蓄積する機能や主体を抽象的・総称的に表す用語。 |
| OLTP(Online Transaction Processing) | コンピュータシステムの処理方式の一種で、互いに関連する複数の処理を一体化して確実に実行するトランザクション処理を、端末などからの要求に基づいて即座に実行する方式。 |
| OLAP(Online Analytical Processing) | データベースに蓄積された大量のデータに対し複雑な集計、分析を行い、素早く結果を提示することができるシステム。 |
| BI(Business Inteligence) | 企業の情報システムなどで蓄積される膨大な業務データを、利用者が自らの必要に応じて分析・加工し、業務や経営の意思決定に活用する手法。そのためのソフトウェアや情報システムをBIツールあるいはBIシステムという。 |
| データマイニング | 情報システムに蓄積した巨大なデータの集合をコンピュータによって解析し、これまで知られていなかった規則性や傾向など、何らかの有用な知見を得ること。「マイニング」(mining)とは「採掘」の意味で、膨大なデータの集積を鉱山になぞらえ、そこから有用な知見を見出すことを鉱石を掘り出すことに例えた表現となっている。 |
| ML(Machine Learning)/機械学習 | コンピュータプログラムにある分野のデータを繰り返し与えることで内在する規則性などを学習させ、未知のデータが与えられた際に学習結果に当てはめて予測や判断、分類などを行えるようにする仕組み。現代の人工知能(AI)研究における最も有力な手法の一つ。 |
| ETL(Extract/Transform/Load) | データベースなどに蓄積されたデータから必要なものを抽出(Extract)し、目的に応じて変換(Transform)し、データを必要とするシステムに格納(Load)すること。また、ソフトウェアの持つそのような機能。 |
文字だとイメージがつかみにくいので、それぞれの用語の位置付けを自分なりに図示してみました。
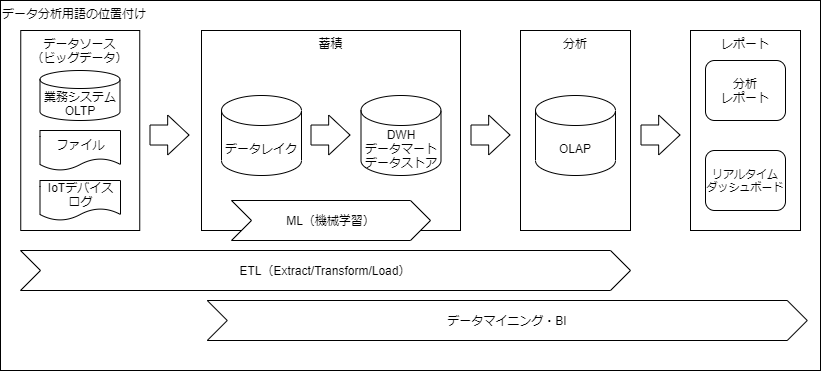
データ分析手法の紹介
データ分析のアーキテクチャ例や、分析に使われる主な手法などを紹介します。
アーキテクチャ例
まずはシンプルなデータ分析のアーキテクチャ例です。
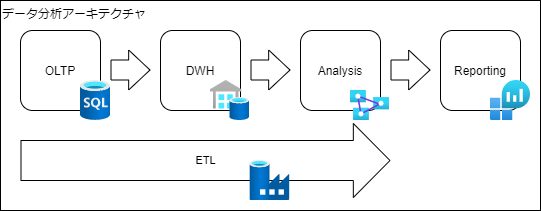
こちらの例では、業務システムであるOLTPからDWHにデータを保管し、分析、レポートを作成しています。
出典:Azure データ アーキテクチャ ガイド - Azure Architecture Center | Microsoft Docs
次にビックデータを使った複雑な例です。
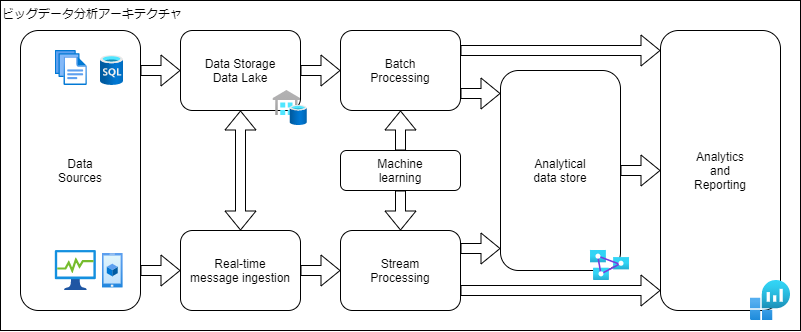
- Data Sources
データソールには様々な種類があります。データベースや、アプリケーションによって生成されたファイル、IoTデバイスなどリアルタイムのデータソースです。 - Data Storage・Data Lake
様々な形式の大きなファイルを保持できる分散ファイルストアです。 - Batch Processing
データセットは非常に大きいため、バッチによりデータファイルを処理します。 - Real-time message ingestion
リアルタイムのソースを取得する必要がある場合は、ストリーム処理のためにリアルタイムメッセージを取得して保存する方法が必要です。 - Stream Processing
リアルタイムメッセージを取得した後、フィルターや集計などの処理をします。 - Analytical data store
分析用に構造化された形式のデータです。
ビッグ データ アーキテクチャ - Azure Architecture Center | Microsoft Docs
メダリオンアーキテクチャ
データクレンジングの進行度によってデータを階層化しようという考え方です。
- ブロンズ → 何も加工していないデータ
- シルバー → IT部門の人がみてきれいな形のデータ
- ゴールド → ユーザが見やすいデータ
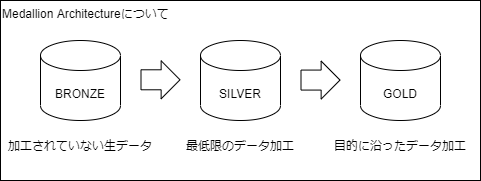
階層化することにより、階層ごとのデータの役割が明確になり管理しやすくなります。
- 利用者に必要なデータが階層別に整理されている
- 元データが必要になったときアクセスしやすい
などのメリットがあります。
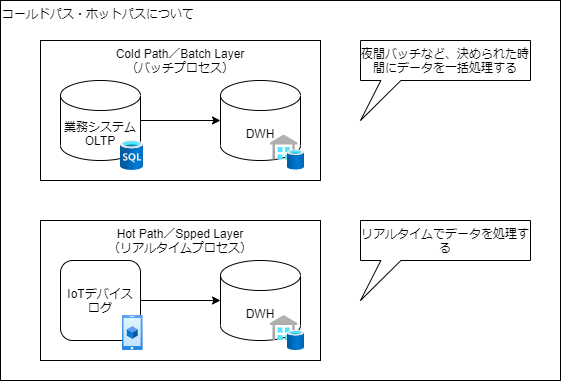
コールドパス・ホットパス
データの処理周期に応じて、データの取得方法を変える考え方です。
- コールドパス(バッチ処理)
バッチ処理の間隔内でたまったデータ(多)を一括処理 - ホットパス(リアルタイム処理)
発生したデータ(小)を絶え間なく処理
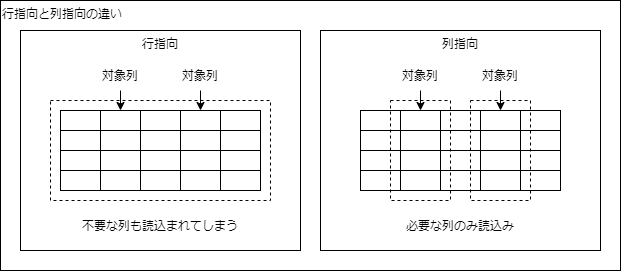
列ストアインデックス
従来のOLTPシステムでは、行ストア型という、テーブルの行ごとにデータが格納されている構造となっています。
一方、データを分析するためのデータベース(データマートやDWH)では、列指向データ形式を使用してデータを格納、取得、管理するための列ストアという構造があります。
列ストア インデックス: 概要 - SQL Server | Microsoft Docs
- 行指向
- 業務システム向けの仕組み
- 行ごとにデータが格納される
- 分析クエリでは対象のカラム以外のすべてのカラムも読込まれてしまう
- 行指向のインデックスは行を素早く特定するための仕組み
- 列指向
- 分析システム向けの仕組み
- 列ごとにデータが格納される
- 分析クエリでは少数のカラムしか利用しないため、必要なカラムのみ読込む事ができる
- レコード単位の処理をするようなOLTPには不向き
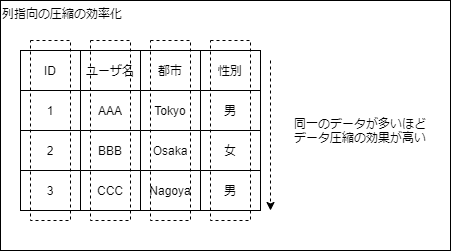
列指向による圧縮効率は、ユニークなデータが少ないほど効率的です。
列ごとに圧縮するため、同じ値が多ければ圧縮の効果は高くなります。
まとめ
データ分析の技術はどんどん新しくなっています。
様々な知識を蓄えて、目的と方法と考えていきたいです。