SQL Serverのインデックスの理解を深める
はじめに
「インデックスを作成すれば早くなる」という認識はあったものの、実際インデックスがどのような仕組みになっているのか詳しいことが理解できていなかったので、まとめてみました。
前半は、インデックスや、データベースの構造についてまとめています。
後半は、実際にデータベースにインデックスを作成する手順や、インデックスを使ったことによって本当に処理が高速化されているのか確認する方法などについてまとめています。
参考にした書籍はこちらです。
平山 理 著『絵で見てわかるSQL Serverの仕組み』
インデックスの仕組みについて
そもそもインデックスとは
テーブルへの処理を高速化するためのデータ構造です。索引(さくいん)ともいいます。
本で例えると、特定の項目のページを探す場合、索引を使わなければ全ページを順番に調べる必要があり検索に時間がかかります。
しかし索引を使えば、調べたい項目のページ番号がわかり、検索を高速化できます。
インデックスを構築するメリットとは
索引を使うことによって目的のデータに早くたどり着くことができるので、より少ないI/O(Input/Output)回数でデータを取得できます。
インデックスの構造
SQL ServerのインデックスはB-Tree型と呼ばれる木階層構造になっています。
木階層構造の上位から下位へたどることによって、目的のデータへ効率的にアクセスできます。
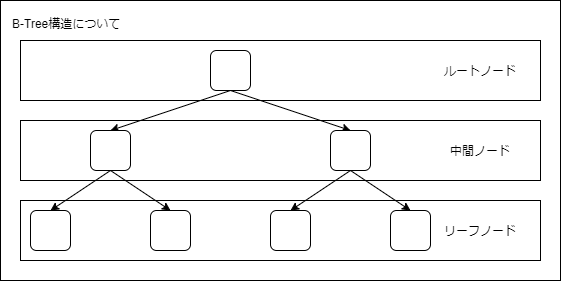
木階層構造の最上位はルートノードと呼び、最下層はリーフノードと呼びます。
双方の間に位置しているのは中間ノードと呼び、ルートノードとリーフノードを結び付ける情報を保持しています。
テーブルのデータ量に応じて中間ノードの階層は変化し、データ量が多いほど階層は深くなります。
ページについて
インデックスについて理解する前に、SQL Serverのデータの構造についても理解しておきましょう。
SQL Serverのデータは、ページという8KBの論理単位で構成されています。
さらに、ページ8個で構成された単位をエクステントといいます。
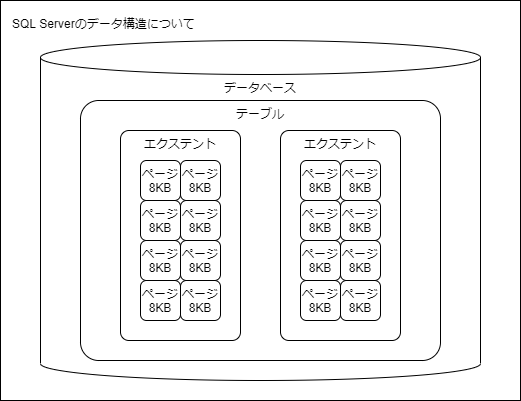
ページの種類
ページには使用用途により様々な種類があります。
主に使用されるのは、データの内容が格納されているデータページと、インデックス情報が格納されているインデックスページです。
それ以外にも、管理情報のみを格納したページが存在します。
主なページの種類(一部抜粋)
参考:Microsoft Docs - ページとエクステントのアーキテクチャ ガイド
| ページタイプ | 説明 |
|---|---|
| Data | 実際のデータが格納されているページ。 |
| index | インデックスの情報が格納されているぺージ。 |
| GAM(Global Allocaition Map) | どのエクステントが割り当て済みかの管理情報が格納されているページ。 |
| PFS(Page Free Space) | ページの割り当て情報とページ使用率の管理情報が格納されているページ。 |
| IAM(Index Allocation Map) | テーブルまたはインデックスによって使用されるエクステントに関する管理情報が格納されているページ。 |
データへのアクセス方法
では、実際にSQL Serverがどのようにしてデータにアクセスしているのかをみていきます。
インデックスを使用しない場合の検索
インデックスが使用されない場合、データページはページ同士の関連性がまったくありません。
データページには、前ページ、次ページの情報を保持していないため、ページ間の関連をたどることができないのです。
よって、前述した管理情報を格納しているページを使用します。
まず、IAMという管理情報のページ確認することによって、使用しているエクステントを判明させます。
つぎにエクステント内の割当て済みページをスキャンします。
スキャンが終了すると、IAMの情報に基づいて次のエクステントへ移動します。
これを繰り返すことにより、データを取得してきます。
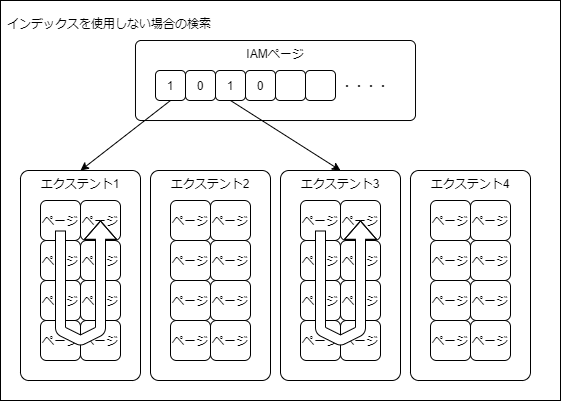
検索対象のデータが1件だけの場合でも、全データを読み込んで検索条件に合っているか比較する必要があります。
インデックスを使用した場合の検索
インデックスページは、インデックスの各階層がリンクリストで結び付けられています。また、同一階層の前ページと次ページのポインタを保持しています。
インデックスが使用される場合、インデックスページ階層の上位から下位へリンクリストをたどりページを特定します。そして前ページもしくは次ページのポインタを使用して、スキャンの開始ページから終了点まで移動して、データを取得していきます。
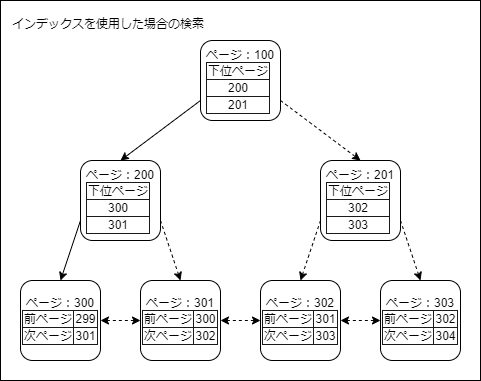
検索対象のデータが1件だけの場合、インデックスが3階層であれば3ページ分のデータの読み込みですみます。
インデックスの種類
インデックスには、クラスター化インデックスと、非クラスター化インデックスの2種類があります。
主な違いはリーフノードが保持しているデータの内容です。
参考:Microsoft Docs - クラスター化インデックスと非クラスター化インデックスの概念

クラスター化インデックス
クラスター化インデックスの場合、リーフノードのページはキー値に加えて実際のデータも保持しています。キー値はインデックスを定義した際の順序で並んでいるので、クラスター化インデックスの実データは、キー順に並んで格納されているということになります。
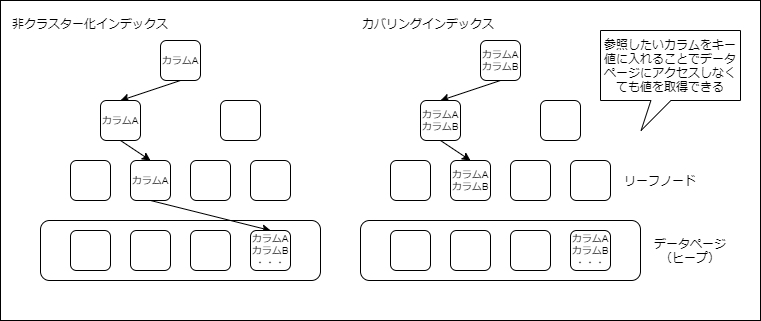
非クラスター化インデックス
非クラスター化インデックスの場合、リーフノードのページには実際のデータは含まれておらず、データページへの参照情報(ポインタ)を保持しています。
クラスター化インデックスが定義されていないテーブルのことをヒープといいます。
クラスター化インデックスが定義されている場合、データが物理的に並び変えられるためリーフノードのページは相互にリンクリストを保持しています。一方ヒープはデータが脈略なく格納されています。
参考:Microsoft Docs - ヒープ (クラスター化インデックスなしのテーブル)
カバリングインデックス
非クラスター化インデックスは実際のデータを取得するためにはデータページ(ヒープ)にアクセスする必要があります。
なので、参照したいカラムをインデックスのキーに加えることによって、データページを参照しなくてもインデックスページ内で完結できるようにするのがカバリングインデックスという考えです。
しかし、カバリングインデックスには参照したいカラムがルートノード・中間ノード・リーフノードに含まれるため、インデックスサイズが大きくなるといった問題があります。
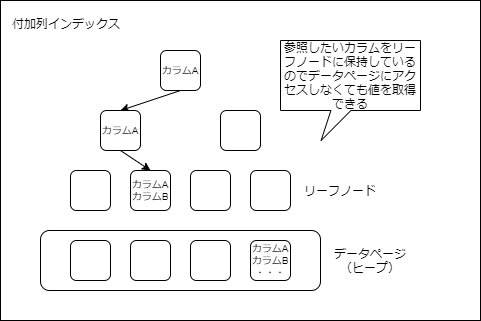
付加列インデックス
非クラスター化インデックスとクラスター化インデックスの両方のいいところを取り入れた機能が付加列インデックスです。
付加列インデックスでは、リーフノードのページに、インデックスキーに加えて任意の列を保持できます。
これにより、データページにアクセスしなくてもデータを取得できます。また、カバリングインデックスのようにルートノードと中間ノードに参照したいカラムを含めなくてもよいため、インデックスサイズの肥大化が軽減されます。
インデックスの仕組みについてまとめ
- インデックスとは
- インデックスとは、テーブルへの処理を高速化するためのデータ構造のこと
- インデックスはB-Tree型と呼ばれる木階層構造になっている
- ページの種類
- SQL Serverのデータは、ページという8KBの論理単位で構成されており、ページ8個で構成された単位をエクステントという
- ページの種類には、インデックスページ、データページ、そしてIAMのような管理情報を格納しているページがある
- データへのアクセス手法
- インデックスを使用せず検索する場合、管理情報を格納しているページを使用して、エクステント内のページを順番にスキャンする
- インデックスを使用して検索する場合、インデックスページ階層の上位から下位へリンクリストをたどりページを特定する
- インデックスの種類
- インデックスにはクラスター化インデックスと非クラスター化インデックスの2種類がある
- クラスター化インデックスはリーフノードに実際のデータも含んでいる
- 非クラスター化インデックスはリーフノードには実際のデータは含んでおらず、データページへのポインタを保持している
- クラスター化インデックスが定義されていない、データページが相互のリンクリストを持っていないテーブルのことをヒープという
- 非クラスター化インデックスのヒープへのアクセスを極力減らす為に、カバリングインデックスという考え方と付加列インデックスという機能がある
- インデックスにはクラスター化インデックスと非クラスター化インデックスの2種類がある
実際にインデックスを作成してみよう
作成方法
では、実際にインデックスを作成してみましょう。
基本構文
インデックスを作成するクエリの基本構文です。
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON database_name.schema_name.table_or_view_name (column_name [ ,...n ] )
[ INCLUDE ( column_name [ ,...n ] ) ]
GO
参考:Microsoft Docs - CREATE INDEX (Transact-SQL)
SQL Server Management Studio上のオブジェクトエクスプローラーで、作成されているインデックスを確認できます。

以下のようなテスト用テーブル、[SalesOrderDetail]を用意しました。
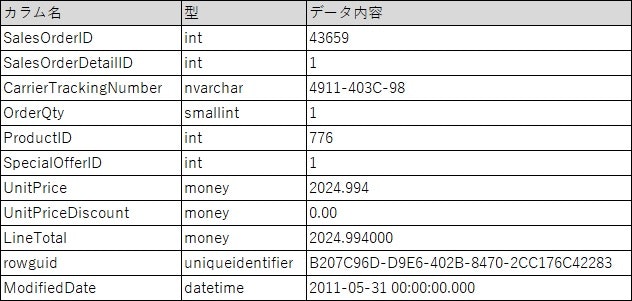
このテーブルに対して実際にインデックスを作成していきます。
クラスター化インデックスの作成例
--[SalesOrderDetailID]カラムにクラスター化インデックスを作成する例
CREATE CLUSTERED INDEX [IX_SalesOrderDetail_SalesOrderDetailID]
ON [SalesOrderDetail] ([SalesOrderDetailID] ASC)
GO
--ASCは省略できます
--複数のカラムを指定することもできます
--ただし、クラスター化インデックスは1つのテーブルに1つまでしか作成できません
CREATE CLUSTERED INDEX [IX_SalesOrderDetail_SalesOrderID_SalesOrderDetailID]
ON [SalesOrderDetail] ([SalesOrderID],[SalesOrderDetailID])
GO
非クラスター化インデックスの作成例
--[ModifiedDate]カラムに非クラスター化インデックスを作成する例
CREATE NONCLUSTERED INDEX [IX_SalesOrderDetail_ModifiedDate]
ON [SalesOrderDetail] ([ModifiedDate]);
GO
--NONCLUSTEREDを指定しなければデフォルトで非クラスター化インデックスになります
--複数のカラムを指定することもできます
CREATE INDEX [IX_SalesOrderDetail_ProductID_SpecialOfferID]
ON [SalesOrderDetail] ([ProductID],[SpecialOfferID])
GO
付加列インデックスの作成例
--[CarrierTrackingNumber]カラムに非クラスター化インデックスを指定し、
--付加列に[OrderQty]を[ProductID]を指定して作成する例
CREATE NONCLUSTERED INDEX [IX_SalesOrderDetail_CarrierTrackingNumber]
ON [SalesOrderDetail] ([CarrierTrackingNumber])
INCLUDE ([OrderQty],[ProductID])
GO
一意なインデックスの作成例
参考:Microsoft Docs - 一意のインデックスの作成
--[rowguid]カラムに非クラスター化インデックスを作成する例
CREATE UNIQUE NONCLUSTERED INDEX [IX_SalesOrderDetail_rowguid]
ON [SalesOrderDetail] ([rowguid])
GO
インデックス付き主キーの作成例
--既存のテーブルに非クラスター化インデックス付き主キーを作成する
ALTER TABLE [SalesOrderDetail]
ADD CONSTRAINT [PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID] PRIMARY KEY NONCLUSTERED (
[SalesOrderID]
,[SalesOrderDetailID]
)
GO
--新しいテーブルに主キーを作成する
CREATE TABLE [SalesOrderHeader] (
[SalesOrderID] [int] NOT NULL
,[OrderDate] [datetime] NOT NULL
,[ModifiedDate] [datetime] NOT NULL
,CONSTRAINT [PK_SalesOrderHeader_SalesOrderID] PRIMARY KEY CLUSTERED (
[SalesOrderID]
)
)
GO
インデックスの削除
DROP INDEXでインデックスを削除できます。
--[IX_SalesOrderDetail_SalesOrderID_SalesOrderDetailID]インデックスを削除する
DROP INDEX [IX_SalesOrderDetail_SalesOrderID_SalesOrderDetailID]
ON [SalesOrderDetail]
GO
検索にインデックスが使用されているかを確認する方法
インデックスを作成しても、ちゃんとインデックスが活用されていなければ意味がありません。
検索の際にインデックスが使用されているか確認してみましょう。
SQL Server Management Studio上で実行プランが表示される設定にします。
参考:Microsoft Docs - 実行プラン
- 「クエリ」タブを選択する
- 「実際の実行プランを含める」をクリックする
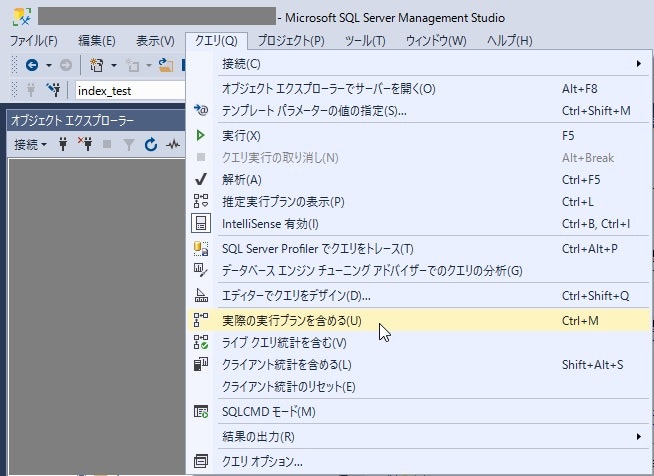
実行プランの主な操作の種類は以下のようなものがあります。
参考:Microsoft Docs - プラン表示の論理操作と物理操作のリファレンス
| 操作の種類 | 説明 |
|---|---|
| Table Scan | テーブルからすべての行を取得します。 |
| Index Seek, Clustered Index Seek |
インデックスから特定範囲の行を取得します。 |
| Index Scan, Clustered Index Scan |
インデックスの全行を取得します。 |
| RID Lookup | 指定された行識別子 (RID) を使用してヒープ上のデータを取得します。 |
| Nested Loops | 外部に入力した行ごとに内部に入力した行を検索し、一致している行を出力します。 |
インデックスを使用しない検索
まずはインデックスを作成していないテーブルで検索してみます。
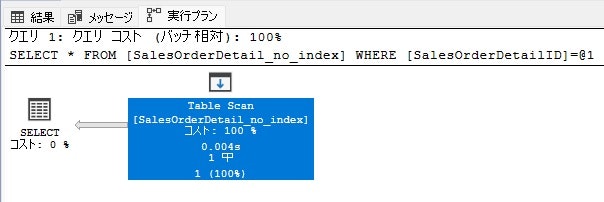
SELECT * FROM [SalesOrderDetail_no_index]
WHERE [SalesOrderDetailID] = 1
「実行プラン」タブを見ると、「Table Scan」となっています。これはテーブル全体をスキャンしています。
クラスター化インデックスを使用した検索
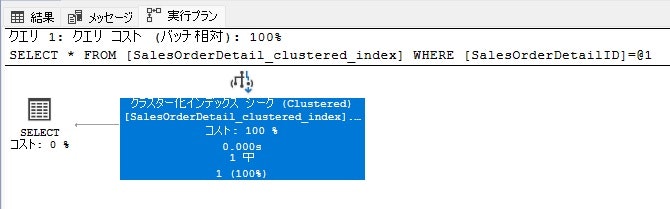
次にクラスター化インデックスが作成されているテーブルで検索してみます。
このテーブルには「SalesOrderDetailID」カラムをキー値としたクラスター化インデックスを作成しています。
SELECT * FROM [SalesOrderDetail_clustered_index]
WHERE [SalesOrderDetailID] = 1
「実行プラン」タブをみると、「クラスター化インデックス シーク」となっており、インデックスを使用して検索されていることがわかります。
「実行プラン」タブ内の「Table Scan」または「クラスター化インデックス シーク」のオブジェクトをクリックすると「プロパティウィンドウ」に詳細が表示されます。
2つのプロパティウィンドウを比較してみましょう。
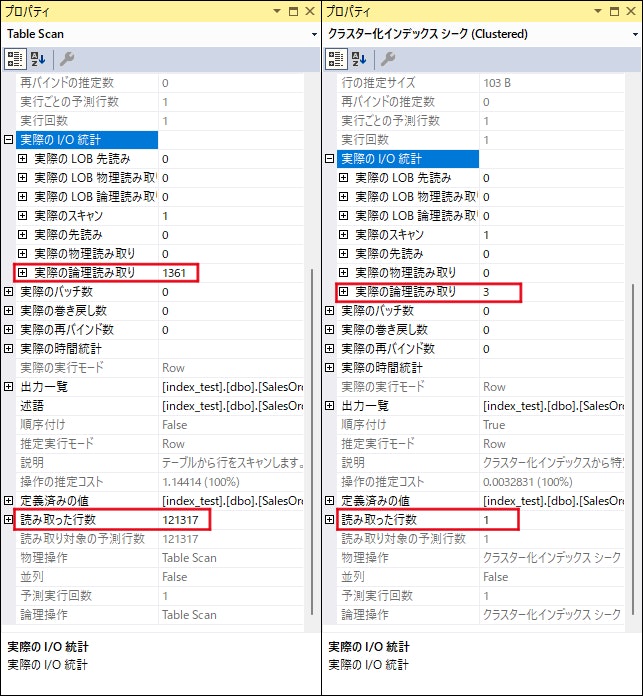
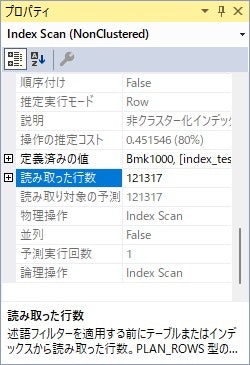
「実際のI/O統計」の「実際の論理読み取り」をみると、インデックスを作成していないテーブルは「1361」なのに対し、インデックスを作成したテーブルは「3」とかなり少なくなっています。
そして、「読み取った行数」をみると、インデックスを作成していないテーブルは「121317」とレコード全行なのに対し、インデックスを作成したテーブルはたったの「1」となっています。
インデックスがちゃんと使用され、検索が効率化されていることがわかりました。
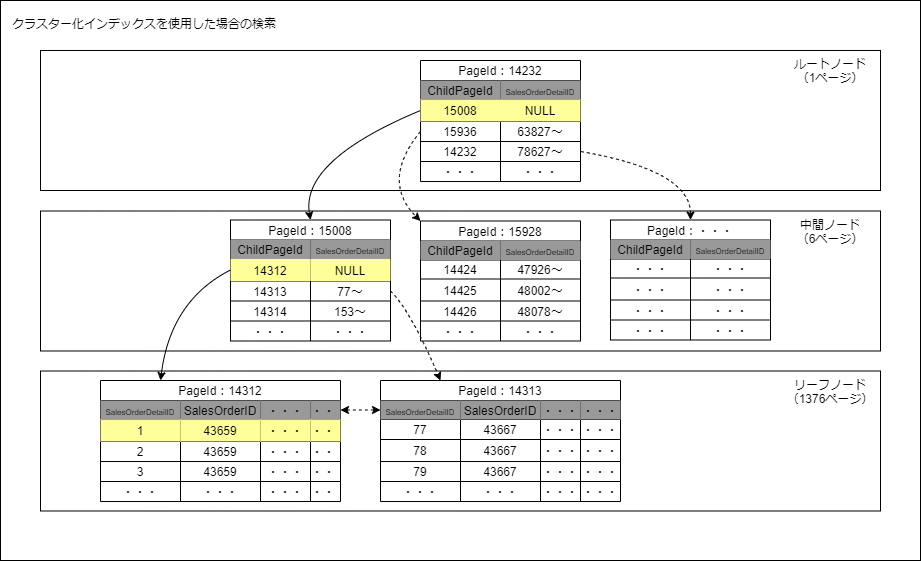
実際に、クラスター化インデックスのデータ構造はこのようになっていました。
非クラスター化インデックスを使用した検索
では、次は非クラスター化インデックスを使用した検索をしてみましょう。
このテーブルには、[SalesOrderDetailID]カラムをキー値とした非クラスター化インデックスを作成しています。
SELECT * FROM [SalesOrderDetail_nonclustered_index]
WHERE [SalesOrderDetailID] = 1
「実行プラン」タブをみると、「Index Seek (NonClustered)」となっています。

非クラスター化インデックスの場合は、リーフノードにキー値と検索対象のデータ行へのポインタを保持しています。
このポインタは行識別子(RID)といい、このポインタを使用してヒープから対象のデータ行を検索しています。
実際に、非クラスター化インデックスのデータ構造はこのようになっていました。
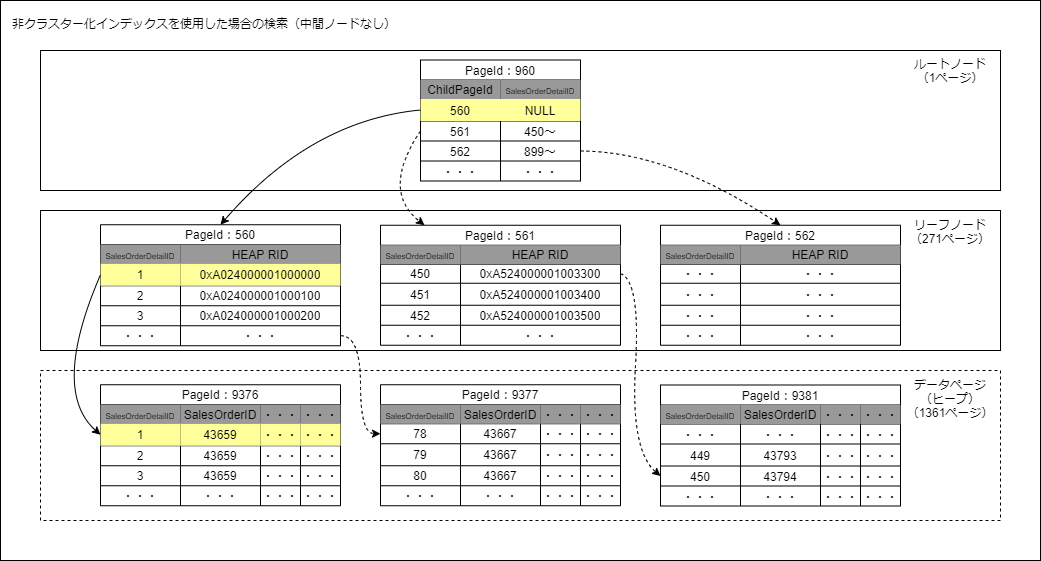
非クラスター化インデックスとクラスター化インデックスの両方を使用した検索
非クラスター化インデックスとクラスター化インデックスの両方が作成されているテーブルの検索をしてみましょう。
このテーブルには、[SalesOrderDetailID]カラムをキー値としたクラスター化インデックスと、[rowguid]カラムをキー値とした非クラスター化インデックスを作成しています。
SELECT * FROM [SalesOrderDetail_nonclustered+clustered_index]
WHERE [rowguid] = 'B207C96D-D9E6-402B-8470-2CC176C42283'
「実行プラン」タブをみると、「Index Seek (NonClustered)」となっており、一見非クラスター化インデックスのみを使用した場合と似ていますが、データページの検索が異なっています。
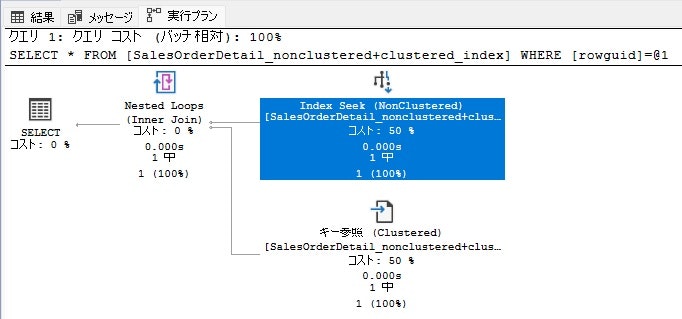
非クラスターインデックスのみを使用した検索の場合、行識別子(RID)というポインタを使用してヒープから対象のデータを検索する「RID Lookup (Heap)」となっています。
一方データページがヒープではなくクラスター化インデックスを作成している場合は、キー参照となっています。
インデックスが使用されない検索条件
インデックスを作成していても、クエリの書き方によってはインデックスを使用できない場合があります。
いくつか例を紹介します。
後方一致・部分一致検索
文字列の検索にLike句を使用した場合、前方一致検索であればインデックスが使用されますが、後方一致または部分一致検索の場合はインデックスが使用されません。
OKパターン:前方一致
前方一致検索の実行プランは「Index Seek (NonClustered)」となっており、インデックスが使用されている事がわかります。
--前方一致
SELECT * FROM [SalesOrderDetail_nonclustered_index]
WHERE [CarrierTrackingNumber] like '4911-403C-9%'
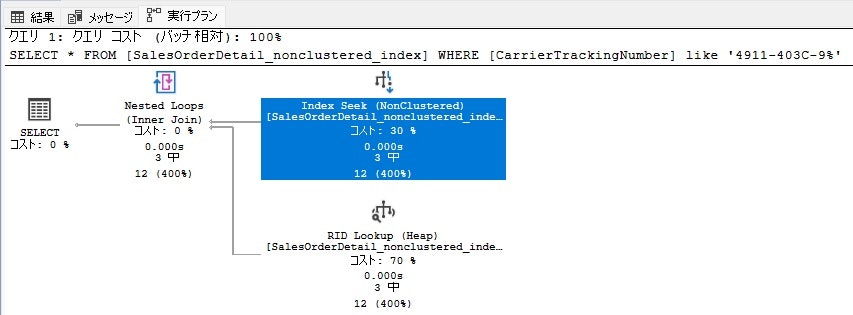
NGパターン:後方一致・部分一致
一方、後方一致もしくは部分一致検索の実行プランは「Index Scan」となっています。「Index Scan」の場合、木階層構造を使用して探索しているのではなく、インデックスのリーフノード全体を順に探索するため効率の悪い検索となっています。
--後方一致
SELECT * FROM [SalesOrderDetail_nonclustered_index]
WHERE [CarrierTrackingNumber] like '%911-403C-98'
--部分一致
SELECT * FROM [SalesOrderDetail_nonclustered_index]
WHERE [CarrierTrackingNumber] like '%911-403C-9%'

読み取った行数も全行である「121317」件となっています。
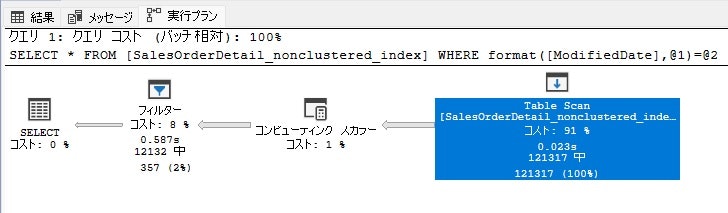
関数を使用した場合
検索対象のカラムで関数を使用した場合もインデックスを使用できない時があるので注意です。
OKパターン:関数なし
--関数なし
SELECT * FROM [SalesOrderDetail_nonclustered_index]
WHERE [ModifiedDate] = '2011-05-31 00:00:00.000'
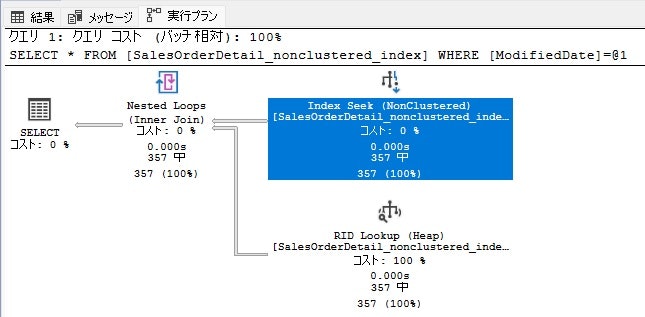
NGパターン:関数あり
--関数あり
SELECT * FROM [SalesOrderDetail_nonclustered_index]
WHERE format([ModifiedDate],'yyyyMMdd') = '20110531'
複合インデックスの場合
インデックスのキー値を複数列設定した複合インデックスの場合、検索条件の順番に注意する必要があります。
2つの列をインデックスのキー値として設定した場合、1番目の列のみ、もしくは両方の列を検索条件に指定した場合、インデックスは使用されます。
しかし、2番目の列のみを検索条件に指定してもインデックスは使用されません。
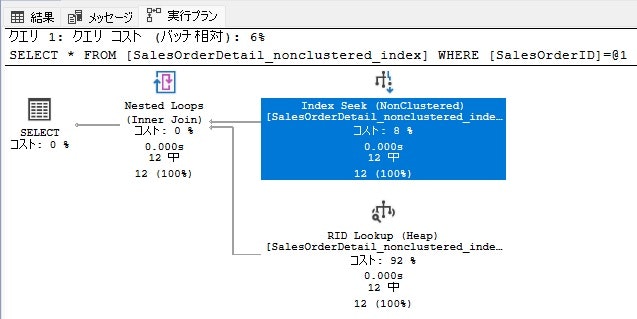
OKパターン:1番目のインデックスキー・両方のインデックスキー
--SalesOrderIDのみ
SELECT * FROM [SalesOrderDetail_nonclustered_index]
WHERE [SalesOrderID] = 43659
--SalesOrderIDとrowguidの両方
SELECT * FROM [SalesOrderDetail_nonclustered_index]
WHERE [SalesOrderID] = 43659
and [rowguid] = 'B207C96D-D9E6-402B-8470-2CC176C42283'
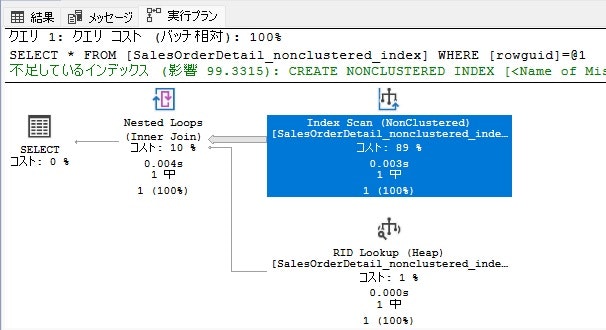
NGパターン:2番目のインデックスキーのみ
--rowguidのみ
SELECT * FROM [SalesOrderDetail_nonclustered_index]
WHERE [rowguid] = 'B207C96D-D9E6-402B-8470-2CC176C42283'
例えば、部署名と社員名の順で複合インデックスを作成した場合、部署名で検索した場合はインデックスが使用されますが、社員名単体で検索してもインデックスを使用できません。
データ型が異なる場合
検索対象のカラムと条件の型が異なる場合もインデックスを使用できません。
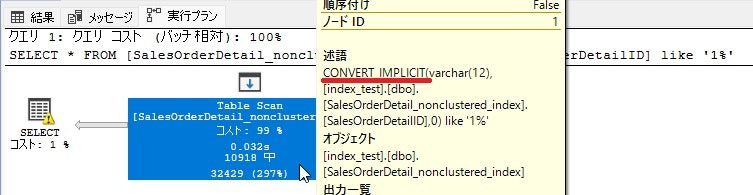
先ほど前方一致検索の場合インデックスは使用されると書きましたが、前方一致でも数値に対してlikeで前方一致検索すると、暗黙的に文字列に変換されるのでインデックスが使用されません。
SELECT * FROM [SalesOrderDetail_nonclustered_index]
WHERE [SalesOrderDetailID] like '1%'
インデックスの断片化について
インデックスの作成後、レコードを更新・挿入・削除するとインデックスの断片化が発生します。
以下のクエリで断片化率を調べることができます。
参考:ZOZO TECH BLOG - SQL Serverにおけるインデックスの再構成と再構築の性能比較
USE [DB名]
DECLARE @DB_ID int
DECLARE @OBJECT_ID int
SET @DB_ID = DB_ID('DB名')
SET @OBJECT_ID = OBJECT_ID('テーブル名')
SELECT
*
FROM
sys.dm_db_index_physical_stats(@DB_ID, @OBJECT_ID, null, null, 'DETAILED') AS A
JOIN
sys.objects AS B
ON
A.object_id = B.object_id
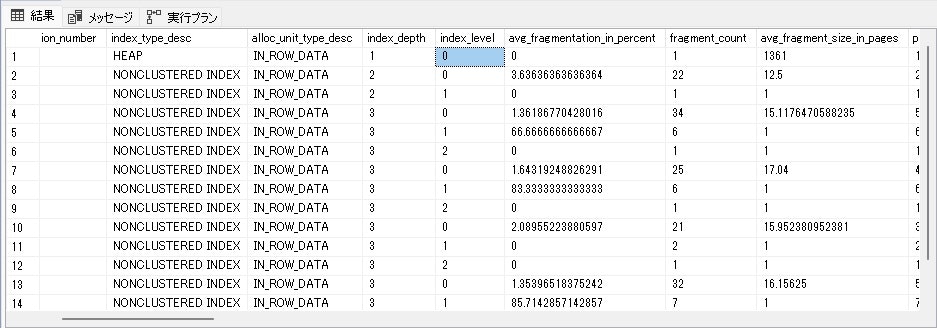
index_levelは、0がリーフノードで、数字が一番大きいものはルートノードです。
avg_fragmentation_in_percentは、各レベルにおける断片化率で、高いほど断片化が激しい事を表します。
page_countは、各レベルにおけるページ数で、断片化が激しいと、本来必要なページ数よりも多くなります。
再構成と再構築について
断片化を解消する方法には、再構成と再構築があります。
違いは以下です。
参考:Microsoft Docs - インデックス再構築と再構成の違い
| 再構築 | 再構成 | |
|---|---|---|
| 処理対象 | 全体 | インデックスのリーフレベルのみ |
| 同時実行 | 不可 | 可能 |
| 処理中断 | 処理した内容はすべて無効となり、元の状態に戻る | キャンセルした時点までの処理は有効 |
| 処理件数 | 断片化の度合いにほとんど影響されない | 断片化の度合いが大きいと多くなる |
| 使用領域 | 再構成よりも多い | 再構築よりも少ない |
| 処理時間 | 断片化の度合いにほとんど影響されない | 断片化の度合いが大きいと長くなる |
再構築もしくは再構成のクエリは以下です。
参考:Microsoft Docs - ALTER INDEX (Transact-SQL)
--再構築
ALTER INDEX index_name
ON database_name.schema_name.table_or_view_name
REBUILD
--再構成
ALTER INDEX index_name
ON database_name.schema_name.table_or_view_name
REORGANIZE
ページ情報
以下のクエリで、レコードがどのページに所属しているか調べることができます。
SELECT * FROM table_or_view_name
CROSS APPLY sys.fn_PhysLocCracker(%%Physloc%%) as fPLC
--[SalesOrderDetail]テーブルの[SalesOrderDetailID]が1のページを表示する例
SELECT * FROM [SalesOrderDetail]
CROSS APPLY sys.fn_PhysLocCracker(%%Physloc%%) as fPLC
WHERE [SalesOrderDetailID] = 1
DBCCコマンド
DBCCコマンドを使用して、ページの内容を見ることもできます。
参考:SQL and SQL only - DBCC IND, DBCC PAGE
DBCC TRACEON
--実行結果をクライアントに返すための設定
DBCC TRACEON(3604)
DBCC IND
--テーブルに使用されているページの確認
DBCC IND ('database_name', 'table_name', non clustered index_id)
引数は以下です。
| 引数 | 内容 |
|---|---|
| database_name | 1番目のパラメータは、データベース名もしくはデータベースIDを指定します。 |
| table_name | 2番目のパラメータは、テーブル名を指定します。 |
| non clustered index_id | 3番目のパラメータは、Non ClusteredインデックスID(sys.indexesのindex_id)または1、0、-1、-2のいずれか指定できます。 -1は、テーブルに関連するすべてのタイプのページ(行内データ、ローオーバーフローデータ、IAM、すべてのインデックス)についての完全な情報を提供します。 -2はIAMのみを表示します。 |
返される情報の内容は以下です。
| 列名 | 内容 |
|---|---|
| IndexID | インデックスのID 0 - ヒープ 1 - クラスター化インデックス 2以上 - 非クラスター化インデックス |
| PagePID | ページ番号 |
| IAMFID | ページを含むファイルのファイルID (sysfilesを参照) |
| ObjectID | 使用するテーブルのオブジェクトID |
| Iam_chain_type | 格納されているデータの種類(行内データ、行のオーバーフローなど) |
| PageType | 1 - データページ 2 - インデックスページ 3と4 - テキストページ |
| Indexlevel | 0 - リーフを意味する 最高値はインデックスのルートを意味する |
| NextPagePID,PrevPagePID | 次のページ番号と前のページ番号を指す |
DBCC PAGE
--ページ内の確認
DBCC PAGE('database_name', fileid, pagenumber, viewing_type)
WITH TABLERESULTS --WITH TABLERESULTSをつけるとテーブル形式で表示される
引数は以下です。
| 引数 | 内容 |
|---|---|
| database_name | 1番目のパラメータは、データベース名もしくはデータベースIDを指定します。 |
| fileid | 2番目のパラメータは、ファイルIDを指定します。 |
| pagenumber | 3番目のパラメータは、ページIDを指定します。 |
| viewing_type | 4番目のパラメータは、出力オプションを指定します。 |
出力オプションの内容は以下です。
| オプションタイプ | 内容 |
|---|---|
| -1,0 | ヘッダー情報 |
| 1 | ヘッダー情報とデータ情報(16進数) |
| 2 | データ情報(16進数) |
| 3 | 成形されたデータ情報 |
ページがインデックスのルートノード、中間ノードの場合に返される情報の内容は以下です。(※2022/02/12追記)
| 列名 | 内容 |
|---|---|
| FileId | ファイルID |
| PageId | ページID |
| Row | 行 |
| Level | インデックスレベル |
| ChildFileId | 子ページのファイルID |
| ChildPageId | 子ページのページID |
| id(Key) | インデックス上の実際のカラムの値。 インデックスに登録されたカラムの名前に '(key)' をつけたものが、結果セットの一部となります。 インデックスに 4 つのカラムがある場合は、'(key)' をサフィックスとする 4 つのカラムが結果セットに含まれることになります。 |
| KeyHashValue | キーのハッシュ値 |
| Row Size | 行サイズ |
動的管理関数(※2022/02/09追記)
DBCCコマンドは出力結果がテーブル形式ではないため、並び変えや条件指定などができません。
しかしSQL Server 2019から追加されたsys.dm_db_page_info動的管理関数を使えばテーブル形式で結果を返してくれるため、並び変えや条件指定ができます。
sys.dm_db_page_info
SQL Server 2019からは、sys.dm_db_page_info動的管理関数が使用可能になりました。
これにより、DBCC INDを使わなくてもページ情報を見ることができます。
sys.dm_db_page_info (Transact-SQL) - SQL Server | Microsoft Docs
--構文
sys.dm_db_page_info ( DatabaseId, FileId, PageId, Mode )
引数は以下です。
| 引数 | 内容 |
|---|---|
| DatabaseId | データベースの ID を指定します。 |
| FileId | ファイルの ID を指定します。 |
| PageId | ページの ID を指定します。 |
| Mode | 関数の出力の詳細レベルを指定します。 'LIMITED' は、すべての説明列に NULL 値を返します。 'DETAILED' は説明列を設定します。 DEFAULT は 'LIMITED.' です。 |
返されるテーブルの内容は以下です。
| 列名 | 内容 |
|---|---|
| database_id | データベース ID |
| file_id | ファイル ID |
| page_id | ページ ID |
| page_header_version | ページ ヘッダーのバージョン |
| page_type | ページの種類 |
| page_type_desc | ページの種類の説明 |
| page_type_flag_bits | ページ ヘッダーの型フラグ ビット |
| page_type_flag_bits_desc | ページ ヘッダーの型フラグ ビットの説明 |
| page_flag_bits | ページ ヘッダーのフラグ ビット |
| page_flag_bits_desc | ページ ヘッダーのフラグ ビットの説明 |
| page_lsn | ログ シーケンス番号/タイムスタンプ |
| page_level | インデックス内のページのレベル (リーフ = 0) |
| object_id | ページを所有しているオブジェクトの ID |
| index_id | インデックスの ID (ヒープ データ ページの場合は 0) |
| partition_id | パーティションの ID |
| alloc_unit_id | アロケーション ユニットの ID |
| is_encrypted | ページが暗号化されているかどうかを示すビット |
| has_checksum | ページにチェックサム値が含されているかどうかを示すビット |
| checksum | データ破損の検出に使用されるチェックサム値を格納します |
| is_iam_page | ページが IAM ページであるかどうかを示すビット |
| is_mixed_extent | 混合エクステントに割り当てられているかどうかを示すビット |
| has_ghost_records | ページにゴースト レコードが含まれているかどうかを示すビット |
| has_version_records | ページに使用されるバージョン レコードがページに含まれているかどうかを示すビット高速データベース復旧 |
| pfs_page_id | 対応する PFS ページのページ ID |
| pfs_is_allocated | 対応する PFS ページでページが割り当て済みとしてマークされているかどうかを示すビット |
| pfs_alloc_percent | 対応する PFS バイトによって示される割り当て比率 |
| pfs_status | PFS バイト |
| pfs_status_desc | PFS バイトの説明 |
| gam_page_id | 対応する GAM ページのページ ID |
| gam_status | GAM で割り当てられているかどうかを示すビット |
| gam_status_desc | GAM ステータスビットの説明 |
| sgam_page_id | 対応する SGAM ページのページ ID |
| sgam_status | SGAM で割り当てられているかどうかを示すビット |
| sgam_status_desc | SGAM ステータスビットの説明 |
| diff_map_page_id | 対応する差分ビットマップページのページ ID |
| diff_status | Diff の状態が変更されたかどうかを示すビット |
| diff_status_desc | Diff ステータスビットの説明 |
| ml_map_page_id | 対応する最小ログ記録ビットマップページのページ ID |
| ml_status | ページが最小ログ記録されるかどうかを示すビット |
| ml_status_desc | 最小ログ記録ステータスビットの説明 |
| prev_page_file_id | 前のページファイル ID |
| prev_page_page_id | 前のページページ ID |
| next_page_file_id | 次のページファイル ID |
| next_page_page_id | 次のページページ ID |
| fixed_length | 固定サイズの行の長さ |
| slot_count | スロットの合計数 (使用済みおよび未使用) データページの場合、この数値は行の数と同じです。 |
| ghost_rec_count | ページでゴーストとしてマークされたレコードの数 ゴーストレコードとは、削除対象としてマークされているものの、まだ削除されていないレコードのことです。 |
| free_bytes | ページの空きバイト数 |
| free_bytes_offset | データ領域の端にある空き領域のオフセット |
| reserved_bytes | すべてのトランザクションで予約されている空きバイト数 (ヒープの場合) ゴースト行の数 (インデックスのリーフの場合) |
| reserved_bytes_by_xdes_id | M_reservedCnt に m_xdesID によって提供される領域(デバッグ目的のみ) |
| xdes_id | M_reserved によって提供される最新のトランザクション(デバッグ目的のみ) |
おわりに
SQL Serverがどのようにページにアクセスしているのか、データ構造がどのようになっているのかを知ることによって、なんとなくしか理解できていなかったインデックスの理解を深めることができました。
ネットで検索するとデータベースの構造を理解していなくても小手先の技術がたくさん手に入るのですが、きちんと構造を理解したうえで最適化するための判断をしていきたいです。