こちらは、HRBrain Advent Calendar 2023 21日目の記事です。
はじめに
どうもこんにちは、HRBrainでバックエンドエンジニアとして働いてる藤原です。
アプリケーションをつくる上で、一定のメモリ消費で処理が成り立つかどうかを検討することは重要だと思います。
特にWebアプリケーションでは1つのアプリケーションインスタンスで複数のリクエストを同時に処理する必要があります。できるだけ少ないメモリで処理が成り立つとメモリ不足に陥りにくくなり動作が安定しますし、確保するリソースも少なくなり費用も抑えることができます。
今回は巨大な複数のファイルを一定のメモリ消費で1つのzipファイルにまとめる方法について実装を交え説明します。GCSを利用する実用的な内容になってます。
やること
GCSに置かれている動画ファイルを1ファイルずつストリームで読み、同じくGCSに作成したzipファイルにストリームで書き込んでいきます。
GCSの部分はエミュレータの fake-gcs-server をDockerで立ち上げて利用します。アプリケーション側の接続先などを変更すれば本物のGCSでも動作すると思います。
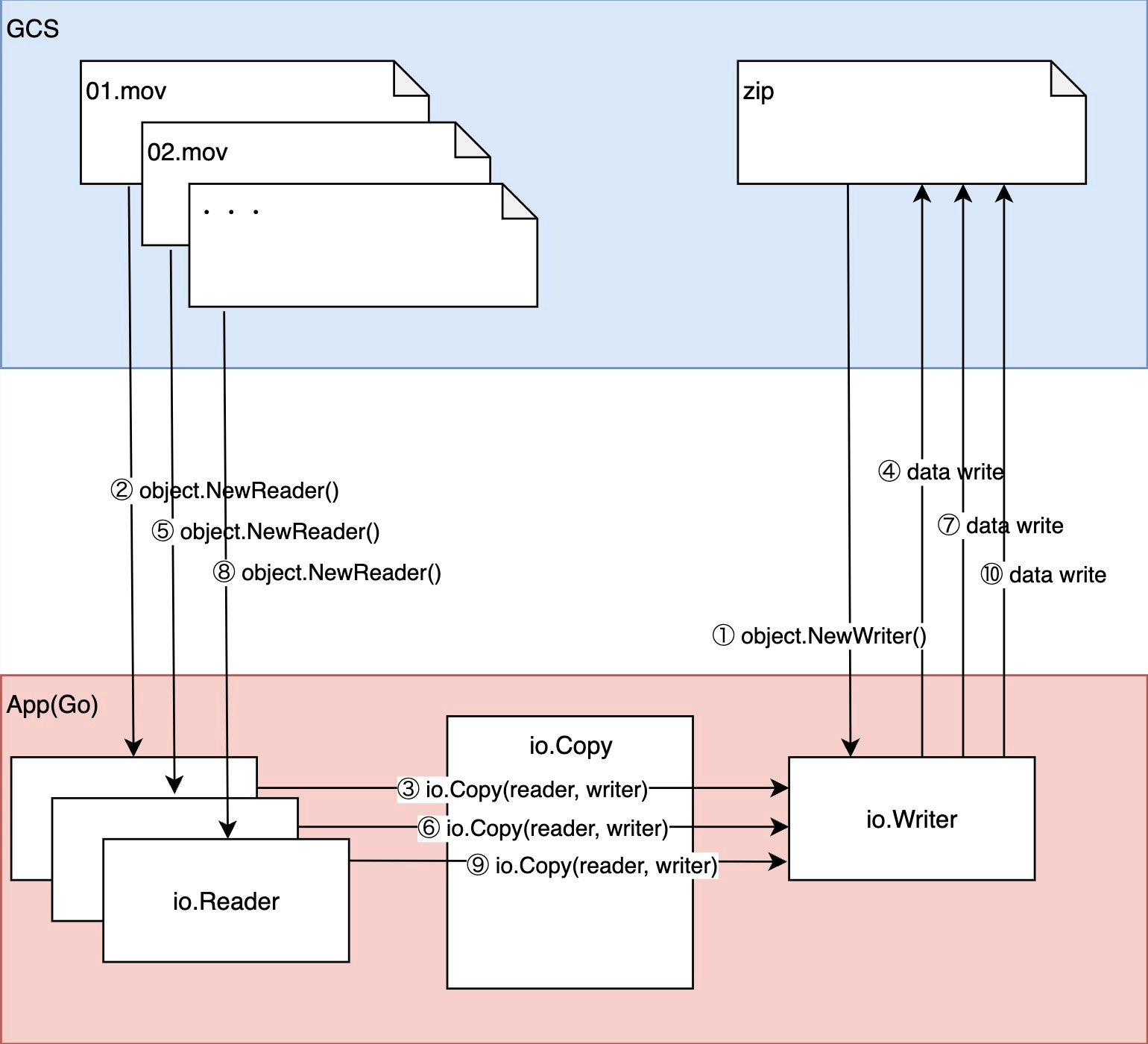
参考:GCSのストリーミング転送のサンプルコード
実装
func main() {
ctx := context.Background()
// GCSに接続
client, err := storage.NewClient(ctx,
option.WithoutAuthentication(),
option.WithEndpoint("http://localhost:4443/storage/v1/"))
if err != nil {
log.Fatalf("failed to create client: %v", err)
}
// 対象バケット名を指定してzipファイル生成関数を呼び出す
const bucket = "sample-bucket"
if err := makeBucketFilesZip(ctx, client, bucket); err != nil {
fmt.Printf("%+v", err)
}
}
func makeBucketFilesZip(
ctx context.Context,
client *storage.Client,
bucketName string,
) error {
const zipName = "all.zip"
bucket := client.Bucket(bucketName)
// バケット内のファイル一覧を取得
it := bucket.Objects(ctx, &storage.Query{})
// バケット内にzipファイルを生成し、writerを取得
writer := bucket.Object(zipName).NewWriter(ctx)
defer writer.Close()
// zip用のwriterを生成
zipWriter := zip.NewWriter(writer)
defer zipWriter.Close()
// ファイルの件数分ループ
for {
oattrs, err := it.Next()
if err == iterator.Done {
break
}
if err != nil {
return errors.Wrap(err, "it.Next")
}
// 1ファイル毎zipに書き込んでいく関数を呼び出す
if err := readWriteOneFile(ctx, zipWriter, bucket, oattrs.Name); err != nil {
return err
}
}
return nil
}
func readWriteOneFile(
ctx context.Context,
zipWriter *zip.Writer,
bucket *storage.BucketHandle,
filename string,
) error {
// バケットからファイルのオブジェクトを取得し、そのreaderを取得
object := bucket.Object(filename)
reader, err := object.NewReader(ctx)
if err != nil {
return errors.Wrap(err, "object.NewReader")
}
defer reader.Close()
// ファイルの情報を取得しzipのファイルヘッダーに書き込む
attrs, err := object.Attrs(ctx)
if err != nil {
return errors.Wrap(err, "object.Attrs")
}
header := makeZipFileHeader(attrs)
writer, err := zipWriter.CreateHeader(header)
if err != nil {
return errors.Wrap(err, "zipWriter.CreateHeader")
}
// ストリームでreaderからwriterへ書き込み
_, err = io.Copy(writer, reader)
if err != nil {
return errors.Wrap(err, "io.Copy")
}
return nil
}
// zipファイル用ヘッダーの生成
func makeZipFileHeader(attrs *storage.ObjectAttrs) *zip.FileHeader {
fh := &zip.FileHeader{
Name: attrs.Name,
UncompressedSize64: uint64(attrs.Size),
Modified: attrs.Updated,
Method: zip.Deflate,
}
fh.SetMode(0755)
return fh
}
利用したソースコード等はGitHubに上げています。
検証方法
以下、複数サイズの8ファイルをGCS側に格納しておきます。これらを1ファイルのzipにまとめます。
01(52KB).mov、02(1.5MB).mov、03(8.4MB).mov、04(13.7MB).mov、05(52KB).mov、06(1.5MB).mov、07(8.4MB).mov、08(13.7MB).mov
メモリの使用量の変化を計測する以下のコードを埋め込んで検証します。
また、比較用にストリームではなくファイルを丸っと読み込んで書き込む方式の実装でもメモリの使用量の変化を計測します。
func printMemoryStatsHeader() {
header := []string{"#", "Alloc", "HeapAlloc", "TotalAlloc", "HeapObjects", "Sys", "NumGC"}
fmt.Println(strings.Join(header, ","))
}
func printMemoryStats(prefix string) {
var ms runtime.MemStats
runtime.ReadMemStats(&ms)
data := []string{prefix, toKb(ms.Alloc), toKb(ms.HeapAlloc), toKb(ms.TotalAlloc), toKb(ms.HeapObjects), toKb(ms.Sys), strconv.Itoa(int(ms.NumGC))}
fmt.Println(strings.Join(data, ","))
}
func toKb(bytes uint64) string {
return strconv.FormatUint(bytes/1024, 10)
}
func makeBucketFilesZip(
ctx context.Context,
client *storage.Client,
bucketName string,
) error {
// ・・・(略)
printMemoryStatsHeader() // ✅ ココ
for {
oattrs, err := it.Next()
if err == iterator.Done {
break
}
if err != nil {
return errors.Wrap(err, "it.Next")
}
if err := readWriteOneFile(ctx, zipWriter, bucket, oattrs.Name); err != nil {
return err
}
printMemoryStats(oattrs.Name) // ✅ ココ
}
printMemoryStats(zipName) // ✅ ココ
return nil
}
比較用のファイルを丸っと読み込んで書き込む方式
//
// Memory waste
//
func makeBucketFilesZipWasteMemory(
ctx context.Context,
client *storage.Client,
bucketName string,
) error {
const zipName = "all-waste.zip"
bucket := client.Bucket(bucketName)
var tmpFilePath string
printMemoryStatsHeader() // ✅ ココ
err := func() error {
// create local file, waste memory and storage
file, err := os.CreateTemp("", zipName)
if err != nil {
return errors.Wrap(err, "os.Open")
}
defer file.Close()
tmpFilePath = file.Name()
zipWriter := zip.NewWriter(file)
defer zipWriter.Close()
it := bucket.Objects(ctx, &storage.Query{})
for {
oattrs, err := it.Next()
if err == iterator.Done {
break
}
if err != nil {
return errors.Wrap(err, "it.Next")
}
if err := readWriteOneFileWasteMemory(ctx, zipWriter, bucket, oattrs.Name); err != nil {
return err
}
printMemoryStats(oattrs.Name) // ✅ ココ
}
return nil
}()
if err != nil {
return err
}
reader, err := os.Open(tmpFilePath)
if err != nil {
return errors.Wrap(err, "os.Open")
}
defer func() {
reader.Close()
os.Remove(tmpFilePath)
}()
// ReadAll() waste memory
readerBytes, err := io.ReadAll(reader)
printMemoryStats(zipName) // ✅ ココ
writer := bucket.Object(zipName).NewWriter(ctx)
_, err = writer.Write(readerBytes)
writer.Close()
if err != nil {
return errors.Wrap(err, "writer.Write")
}
return nil
}
func readWriteOneFileWasteMemory(
ctx context.Context,
zipWriter *zip.Writer,
bucket *storage.BucketHandle,
filename string,
) error {
object := bucket.Object(filename)
reader, err := object.NewReader(ctx)
if err != nil {
return errors.Wrap(err, "object.NewReader")
}
defer reader.Close()
attrs, err := object.Attrs(ctx)
if err != nil {
return errors.Wrap(err, "object.Attrs")
}
header := makeZipFileHeader(attrs)
w, err := zipWriter.CreateHeader(header)
if err != nil {
return errors.Wrap(err, "zipWriter.CreateHeader")
}
// ReadAll() waste memory
readerBytes, err := io.ReadAll(reader)
if err != nil {
return errors.Wrap(err, "io.ReadAll")
}
if _, err := w.Write(readerBytes); err != nil {
return errors.Wrap(err, "w.Write")
}
return nil
}
実行
$ make run
go run .
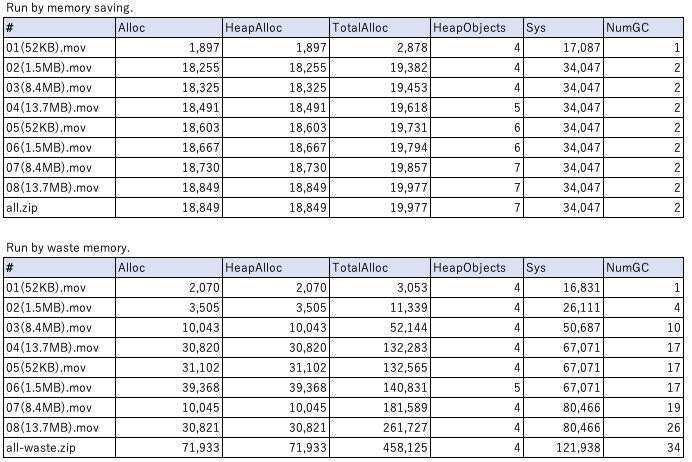
Run by memory saving.
#,Alloc,HeapAlloc,TotalAlloc,HeapObjects,Sys,NumGC
01(52KB).mov,1897,1897,2878,4,17087,1
02(1.5MB).mov,18255,18255,19382,4,34047,2
03(8.4MB).mov,18325,18325,19453,4,34047,2
04(13.7MB).mov,18491,18491,19618,5,34047,2
05(52KB).mov,18603,18603,19731,6,34047,2
06(1.5MB).mov,18667,18667,19794,6,34047,2
07(8.4MB).mov,18730,18730,19857,7,34047,2
08(13.7MB).mov,18849,18849,19977,7,34047,2
all.zip,18849,18849,19977,7,34047,2
$ make runw
go run . --waste
Run by waste memory.
#,Alloc,HeapAlloc,TotalAlloc,HeapObjects,Sys,NumGC
01(52KB).mov,2070,2070,3053,4,16831,1
02(1.5MB).mov,3505,3505,11339,4,26111,4
03(8.4MB).mov,10043,10043,52144,4,50687,10
04(13.7MB).mov,30820,30820,132283,4,67071,17
05(52KB).mov,31102,31102,132565,4,67071,17
06(1.5MB).mov,39368,39368,140831,5,67071,17
07(8.4MB).mov,10045,10045,181589,4,80466,19
08(13.7MB).mov,30821,30821,261727,4,80466,26
all-waste.zip,71933,71933,458125,4,121938,34
結果確認
実行結果をエクセルに転記しました。
一部の指標をピックアップしてグラフも作成しました。
TotalAllocは累計のメモリ使用量です。
青い方が「省メモリ方式」で、灰色の方が「全読み込み方式」の結果です。
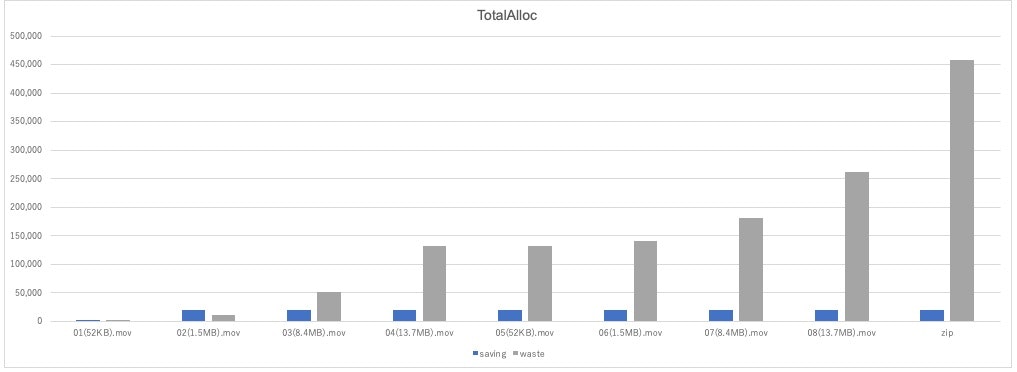
「全読み込み方式」の方がどんどん増加しているのに対し、「省メモリ方式」の方はほとんど増加していないことが分かります。
別の指標のHeapAllocとNumGCのグラフも作成しました。
HeapAllocはその時点でのメモリ使用量(棒グラフ)で、NumGCはGCの実行回数(折れ線グラフ)です。
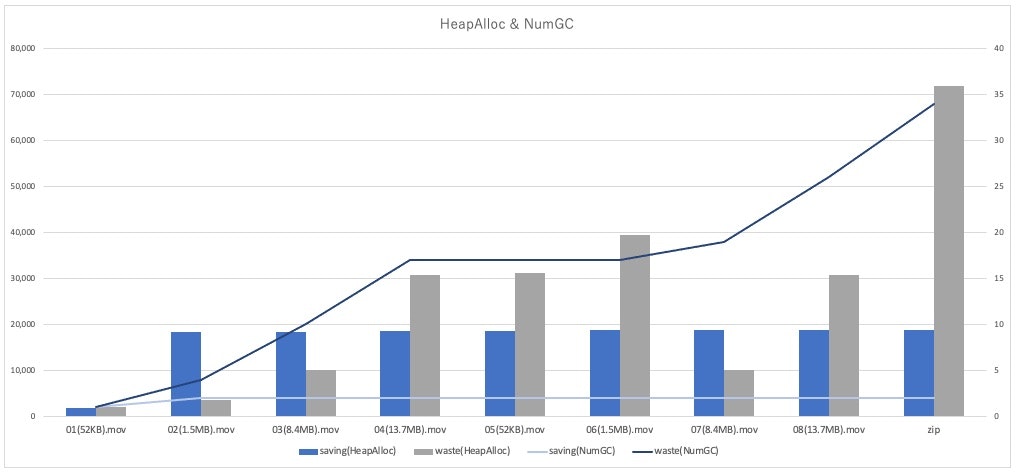
「全読み込み方式」の方がファイルサイズによってメモリ使用量が比例して増減しているのに対し、「省メモリ方式」の方は一定のメモリ使用量を保っています。
また、GCの回数も「省メモリ方式」の方が少ないです。
確認するポイントによっては「全読み込み方式」の方メモリ使用量が少ないところがありますが、これはGCが走ることでメモリが解放されたことが影響していると思います。
まとめ
ストリームの仕組みを使うと省メモリでファイル処理ができることを、実際に計測してより実感できました。
今回はzipファイルにまとめる処理についての内容でしたが、「少しずつ読んで、少しずつ書く」という仕組みは他でも応用できる考え方です。設計時点からこの観点を取り入れることでより動作の安定したアプリケーションが作れるのではないかと思います。
PR
HRBrainでは一緒に働く仲間をいつも募集しています。
省メモリのアプリケーションを一緒に作っていきましょう。