1.想定読者
・AWSの環境を使ったシステムに関わっている方
2.自己紹介
新卒で開発者(プログラマ)としてIT業界に入り、
Randstadの前身であるFSHD(フジスタッフホールディングス)への転職を機にヘルプデスクを経験、
後にRandstadでインフラへ転進後、会社の色々な事情でGISを経験、
またRandstadに戻ってきたインフラ系エンジニア。
現在はインフラ系ITコンサルタントのようなことを行っています。
3.はじめに
AWSでサーバ環境を持っていて、何かしらシステムに不具合が発生した際、
インフラ視点での問題の切り分け方法について書いてみます。
内容が捉えやすいようポイントがどういうものか、
私の個人的なイメージも添えて記載しますがご了承ください。
今までの私の経験から障害対応時に注意して、まず確認するポイントを
参考までにご紹介させていただきます。
4.障害発生時の切り分けポイント
①サーバ状態の確認
・サーバが正常に起動しているか
まずはサーバ自体が起動していることを確認します。
一番簡単なところだとICMPでサーバが起動していることを確認できれば良いですが、
そもそもポートが開いていない可能性もあるため、
AWS管理者にサーバの状態を確認するのが確実です。
・サーバ上のイベントログ等に異常はないか
Windowsログを確認し、サーバに異常が無いか確認します。
・AWS自体から何かしらの不具合通知は無いか
AWSコンソール画面でのアラート確認しましょう。
AWS Personal Health Dashboard で AWS から通知が来ていないか確認します。
たとえば、AmazonEC2インスタンスにアクセスできない場合、
定期メンテナンス等を実施していてアクセスできないだけの可能性が考えられます。
【参考URL】(※AWSアカウントが必要)
https://phd.aws.amazon.com/phd/home#/dashboard/open-issues
②Security Groupの確認
・サーバやRDS、ELBに紐付くSecurity Groupの確認
私の感覚ですと対象のサーバ等から見て玄関みたいなイメージです。

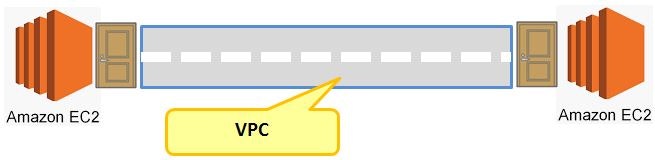
③VPCの確認
サブネットやルーティングといった、そもそもその対象同士に関しての
道ができているのか?という部分になります。
こちらも私の感覚だとサーバ間に道があるかどうかというイメージです。
④障害を確認したクライアント周りの確認
・対象サーバに対して疎通は取れているか?
確認元がWindows系だと仮定した場合、
簡単な疎通の確認としてはコマンドプロンプトからのICMP確認(pingコマンド)となります。
・名前解決はできているのか?
こちらもコマンドプロンプトからnslookupコマンドによる名前解決の確認ができます。
⑤アプリケーションシステム自体のエラー確認
上記のものがすべて問題無いとなった場合、
今までの私の経験上、ほぼ100%アプリケーション特有のエラーでした。
アプリケーション側のエラーについてはシステムによるところですので特にここでは割愛。
5.終わりに
この記事が少しでも障害対応の問題切り分けの助けになれば幸いです。