はじめに
Amazon echo, Google Homeなど、今年は、AIスピーカーが大きな盛り上がりをみせました。また、「自作でAIスピーカーを作ってみた!」「GoogleHomeをHuckしてみた!」などのブログ記事も多く見られました。
みなさん、
音楽を流して、天気を教えてくれて、家電を操作する、100%人間のいいなりになる普通のAIスピーカーは飽きましたよね?ね?
ということで、人間がボケたらツッコミをいれてくれるツッコミAIスピーカー、名付けて「Ahoca」を作りました!

そうです、ケースに入れたRaspberryPiとUSBに刺さってる小さいマイクと普通のスピーカーのみです。
まだ試作機なので、あまり期待を上げすぎずに記事をごらんください
実際に動作しているデモ動画は以下のリンクにあります。
ツッコミを入れてくれるAIスピーカー「Ahoca」試作機映像 from fujit33 on Vimeo.
Ahocaの全体像
 今回、Ahocaが対応するボケとツッコミはエアコン操作のみです。
日本語で入力されたエアコンの操作音声に対し、その入力がボケなのかどうかを判断して、ツッコミを行います。
今回、Ahocaが対応するボケとツッコミはエアコン操作のみです。
日本語で入力されたエアコンの操作音声に対し、その入力がボケなのかどうかを判断して、ツッコミを行います。
今回は、ボケの検知に異常検知という統計の技術を用いて行っています。まずはそこから解説していきます。
異常検知を用いたボケ検知
異常検知とは
その名の通り、正常なデータ群の中から何かしらの理由で紛れ込んだ異常なデータを発見し検知する技術で、その手法には大きく分けて2種類あります。
- 統計分布を用いて、その分布から外れたものを異常値とする方法
- データ間の距離を測り、離れた距離のものを異常値を判定する方法
どちらも似ているようですが、分布を仮定しているかどうかが大きく異なります。今回は、エアコン操作の温度データを用いるので、データが1種類(1次元)で、ある程度統計分布に従っているだろうという予想していたので、統計分布を用いる手法を扱いました。
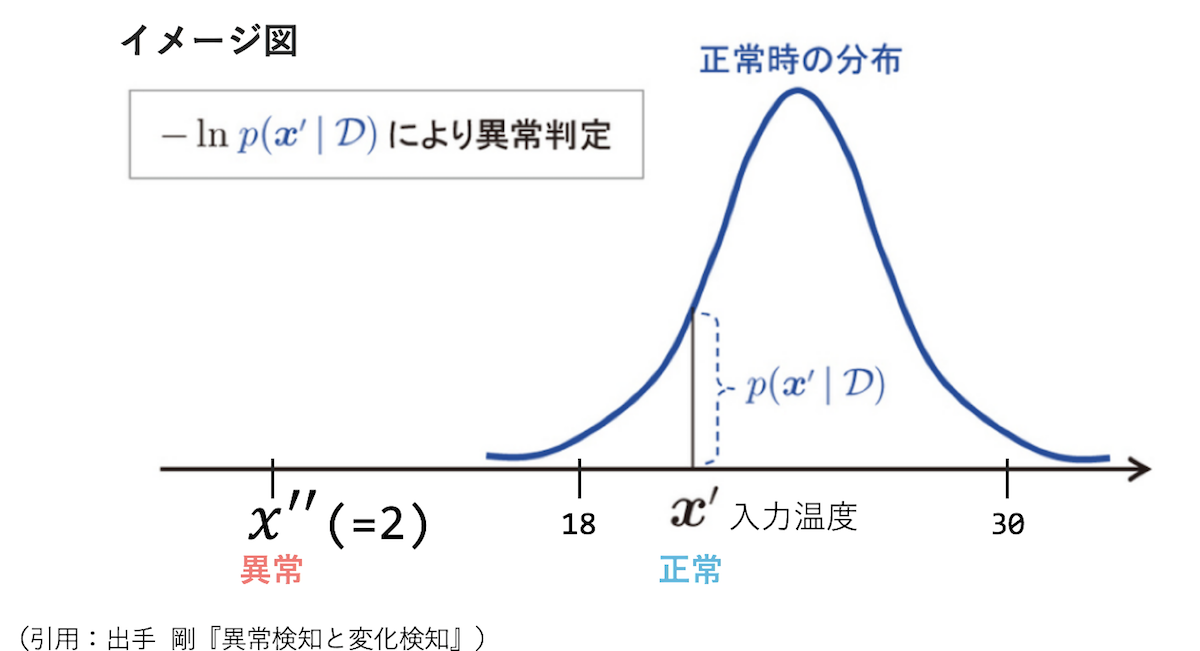
正常データ(ボケではないデータ)の分布推定
もうお気づきかもしれませんが、今回はボケ=異常と定義して分析を行います。したがって、ボケではない=正常ということになります。
なぜボケを異常と定義するのか。それは今回の内容を社内のLTで発表したときの資料がSlideshareに上がっておりリ、そこで詳しく「笑い学」として笑いのメカニズムを大真面目に解説しているのでこちらをご覧ください。
ツッコミを入れてくれるAIスピーカー「Ahoca」を作った SlideShare
正常データは、以下のアンケート調査のデータをすべて合わせたものを用いました。全て合わせて約9000人ほどの「普段設定するエアコンの温度」を今回の正常データとして扱います。
- http://www.gamenews.ne.jp/archives/2008/08/_6_7.html
- http://www.garbagenews.net/archives/881536.html
- http://www.daikin.co.jp/air/knowledge/library/vol18/index.html?ID=air_knowledge_library
- http://newsrelease.lixil.co.jp/news/2013/120_newsletter_1023_01.html
- https://www.tokyo-co2down.jp/action/emission-2/temperature/
- https://www.jstage.jst.go.jp/article/shasetaikai/2015.6/0/2015.6_173/_pdf/-char/ja
- http://tkkankyo.eng.niigata-u.ac.jp/researchs/1-16.pdf
設定温度に関するアンケートデータを整形して読み込むと以下のようになります。
import pandas as pd
import numpy as np
%matplotlib inline
# 読み込み
coolheat = pd.read_csv("../03.data/aircondition/cooling_heating_enquete.csv")
temp = pd.read_csv("../03.data/aircondition/temp_transaction.csv")
temp.head()
 各行がアンケートの1回答、tempaqrtureの列が設定温度、typeが冷房:cool,暖房:heatになっています。
まず、暖房と冷房ごとに温度の分布を確認します。
各行がアンケートの1回答、tempaqrtureの列が設定温度、typeが冷房:cool,暖房:heatになっています。
まず、暖房と冷房ごとに温度の分布を確認します。
cool = temp.query('type == "cool"')["temparture"]
heat = temp.query('type == "heat"')["temparture"]
# 冷房
plt.hist(cool, bins=25, normed=True, alpha=0.6, color='b')
# 暖房
plt.hist(heat, bins=25, alpha=0.6, color='r')
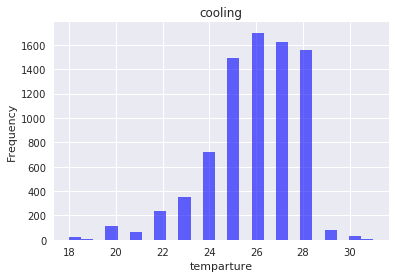
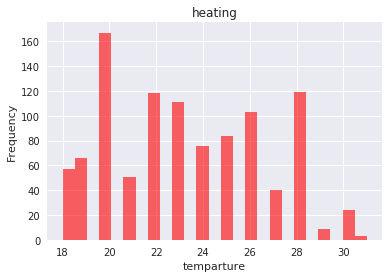
冷房の方は左に裾が長いですが、比較的きれいな分布をしています。
対して暖房は大きく見て山が2つあるように見えますが、21度が少ないなど、ばらつきも大きいです。これは、集めたサンプルサイズが少ないことも原因として考えられますが、21度という微妙な値をアンケートで答える人が少ないことも原因かもしれません。
どちらにしろ、両者の分布とも、単純な正規分布ではないため、混合正規分布で確率密度を推定することにします。
なるべくシンプルな表現にしたかったことと、ある程度推定できていれば良しとするつもりだったので、混合する分布の数は2からはじめ、プロットしておおよそ合っていればOKとする方針で行いました。
from sklearn.mixture import GaussianMixture
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import norm
# numpyの多重arrayに変換
cool2 = np.array([[x] for x in cool])
heat2 = np.array([[x] for x in heat])
# EMアルゴリズムで分布パラメータを推定
# cool
n_components = 2 # 混合する分布の数
gmm_cool = GaussianMixture(n_components, covariance_type='full', random_state=20)
gmm_cool.fit(cool2)
# heat
n_components = 3 # 混合する分布の数
gmm_heat = GaussianMixture(n_components, covariance_type='full', random_state=20)
gmm_heat.fit(heat2)
# 推定されたパラメータ
# cool
print("means",[x[0] for x in gmm_cool.means_])
print("covariances",[x[0][0] for x in gmm_heat.covariances_])
print("weights",gmm_cool.weights_)
# heat
print("means",[x[0] for x in gmm_heat.means_])
print("covariances",[x[0][0] for x in gmm_heat.covariances_])
print("weights",gmm_heat.weights_)
# cool
means [23.297820993392921, 26.418380408176766]
covariances [1.3584311769491457, 2.1498176338417809, 2.5223821217079889]
weights [ 0.17632263 0.82367737]
# heat
means [27.945357124345144, 20.299455223349213, 24.397334427680796]
covariances [1.3584311769491457, 2.1498176338417809, 2.5223821217079889]
weights [ 0.18796645 0.43631814 0.37571541]
今回は冷房の分布数は2、暖房は3とし、推定されたパラメータはこのようになりました。続いて、これらをヒストグラムに重ねてプロットしていきます。
# 冷房=========
# 元の分布ヒストグラムをプロット
plt.hist(cool, bins=25, normed=True, alpha=0.6, color='b')
# 推定されたパラメータの混合正規分布を重ねて描画
# 細い線:推定された各正規分布
# 太い線:各正規分布を混合した混合正規分布
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
p0 = norm.pdf(x, gmm_cool.means_[0], gmm_cool.covariances_[0])
p1 = norm.pdf(x, gmm_cool.means_[1], gmm_cool.covariances_[1])
p = p0[0] * gmm_cool.weights_[0] + p1[0] * gmm_cool.weights_[1]
# 描画
plt.plot(x, p, 'k', linewidth=2)
plt.plot(x, p0[0], 'k', linewidth=0.5)
plt.plot(x, p1[0], 'k', linewidth=0.5)
plt.title("cooling")
plt.xlabel("temparture")
plt.ylabel("Rate")
plt.show()
# 暖房==========
# 元の分布ヒストグラムをプロット
plt.hist(heat, bins=25, normed=True, alpha=0.6, color='r')
# 推定されたパラメータの混合正規分布を重ねて描画
# 細い線:推定された各正規分布
# 太い線:各正規分布を混合した混合正規分布
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
p0 = norm.pdf(x, gmm_heat.means_[0], gmm_heat.covariances_[0])
p1 = norm.pdf(x, gmm_heat.means_[1], gmm_heat.covariances_[1])
p2 = norm.pdf(x, gmm_heat.means_[2], gmm_heat.covariances_[2])
p = p0[0] * gmm_heat.weights_[0] + p1[0] * gmm_heat.weights_[1]+ p1[0] * gmm_heat.weights_[2] # 混合
# 描画
plt.plot(x, p, 'k', linewidth=2)
plt.plot(x, p0[0], 'k', linewidth=0.5)
plt.plot(x, p1[0], 'k', linewidth=0.5)
plt.plot(x, p2[0], 'k', linewidth=0.5)
plt.title("Rate")
plt.xlabel("temparture")
plt.ylabel("Rate")
plt.show()
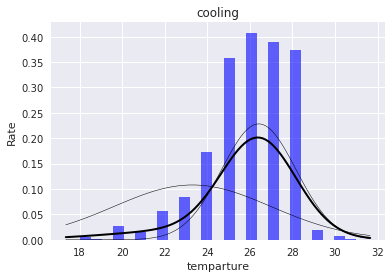
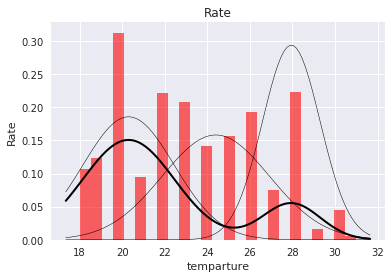
細い線は推定された各正規分布、太い線は各正規分布を混合した混合正規分布を表しています。どちらも山の高い部分までは分布分布が追えていないですが、今回は異常検知のための分布推定で、後ほど決めるしきい値より高い確率はすべて正常となるので、これで問題ありません。
これで、各正常分布の推定が終わりました。次に異常値の定義としきい値の設定に移ります。
異常値の定義としきい値の設定
正常分布の確率をそのまま異常値のしきい値とするのではなく、各確率の対数にマイナスをかけたものを異常値として定義します。数式で表すと以下のようになります。
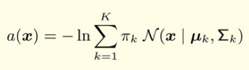
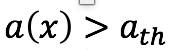
のとき、異常と判定します。しきい値を設定するために、通常のサンプルに異常値に近い値10個を加え、異常値に変換してプロットしてみました。
def get_temp_anomaly_level(x, means,covars,weights):
prob = 0
for i in range(len(means)):
prob += norm.pdf(x, loc=means[i], scale=covars[i]) * weights[i]
a = -1 * np.log(prob)
return(a)
# 冷房
input_x = []
input_x.extend(np.random.choice(cool,100))# 正常データからランダムに100個選択
input_x.extend([0,5,10,15,30,35,40,50]) # 異常データと、微妙なラインのデータを10個追加
output = pd.Series([get_temp_anomaly_level(x,means_c,covars_c,weights_c) for x in input_x])
sns.jointplot(np.array(range(len(output))),np.array(output))
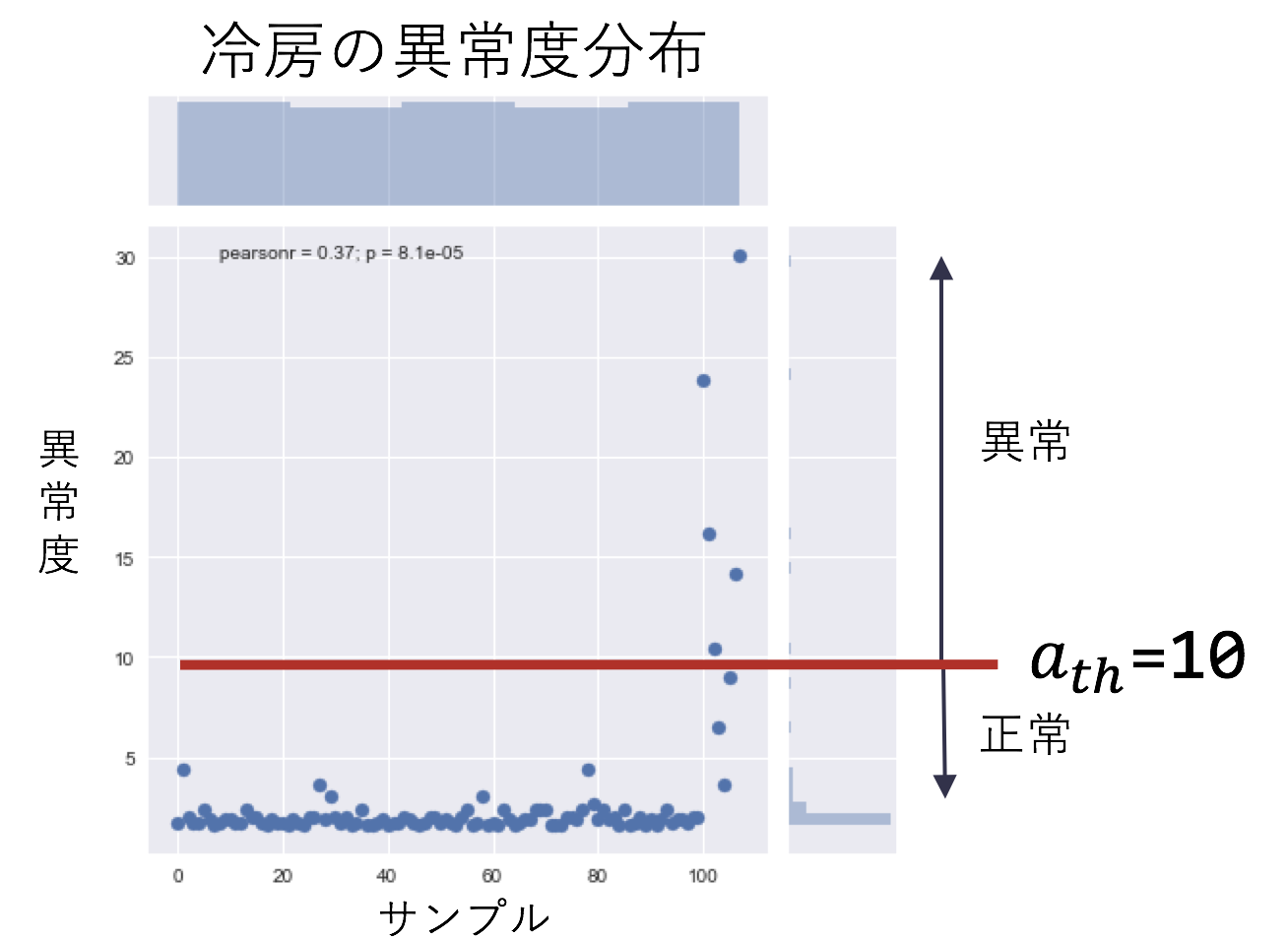
今回は緩めに異常度を10と設定します。理由は、ボケではなく真面目に温度を入力しているのに、ツッコまれると悲しいからです。
同じ処理を暖房にも行い、10と設定しました。
RaspberryPi側の処理
音声の入力から再生までは上記に記した全体像の画像の通りで、マイクとスピーカーの制御にはpyaudioライブラリを使っています。
各種初期設定
RaspberryPiの設定の仕方は多くのQiitaの記事を参考にしたので、そちらに譲ります。(逃げ)
ひとつお伝えしたいのは、インストールするOSのバージョンによって、前まであったファイルが無かったりすることがあるので、できるだけ1年以内に作られた記事を参照するのがおすすめです。(alsa-base.conf が無くて苦労した。。。)
- OSなど
- マイクやスピーカーの設定
- Cloud Speech API
音声入出力
音声入力と出力はこの記事 などを参考に作成しました。音声ファイルに慣れていないまま手探りで進めたため、まだ完全には中身を理解していない。。。
AquesTalkなどの使い方はこの記事 を参考にしています。
また、最初はツッコミの音声を合成音声で喋らせてみたのですが、「ナンデヤネン」と言われても全くおもしろくなかったので、バイキング小峠のツッコミを録音して入れることにしました。(それによる副作用は後ほど。。)
import pyaudio
import wave
import time
import io
import os
# 音声入力
def recording(self):
"""
PyAudioを使って、マイクから音声を録音し、wavファイルとして書き出す。
"""
# 基本設定
FRAMES_PER_BUFFER = self.CHANK
CHANNELS = 1
RATE = self.rate
RECORD_SECONDS = 5
DEVICE_INDEX = 0
# pyaudioオブジェクトを作成
wf = wave.open('./voicedata/input_audio.wav','w')
#Wf = wave.open('./voicedata/pyaudiotest.wav','w')
wf.setnchannels(CHANNELS) # モノラル
wf.setsampwidth(2) #16bits
wf.setframerate(RATE)
p = pyaudio.PyAudio()
# コールバック関数
def callback(in_data, frame_count, time_info, status):
# wavに保存する
wf.writeframes(in_data)
return (None, pyaudio.paContinue)
# ストリームを開始
print("Recording...")
stream = p.open(format = p.get_format_from_width(wf.getsampwidth()),
channels = wf.getnchannels(),
rate = wf.getframerate(),
input_device_index = DEVICE_INDEX,
input = True,
output = False,
frames_per_buffer = FRAMES_PER_BUFFER,
stream_callback = callback)
# 録音終了まで待つ
time.sleep(RECORD_SECONDS)
print("Stop Recording")
# ストリームを止める
stream.stop_stream()
stream.close()
# wavファイルを閉じる
wf.close()
# pyaudioオブジェクトを終了
p.terminate()
# 音声出力(wavファイルを再生する場合)
def talk(self,filename):
"""
wavファイルを再生
"""
import wave
file_path = "./voicedata/" + filename
wf = wave.open(file_path, "rb")
#wf = wave.open("./voicedata/pyaudiotest.wav", "rb")
# PyAudioのインスタンスを生成
p = pyaudio.PyAudio()
# Streamを生成
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True)
data = wf.readframes(self.CHANK)
# 実行
while len(data)!=0:
stream.write(data)
data = wf.readframes(self.CHANK)
# ストリームを停止
stream.stop_stream()
stream.close()
wf.close()
# close
p.terminate()
# 音声出力(合成音声を出力する場合)
def talk2(self, message="こんにちは", card=1, device=0):
'''
AquesTalkを使ってテキストを再生
'''
os.system('/home/pi/ahoca_pj/aquestalkpi/AquesTalkPi " ' + message + ' " | aplay -Dhw:{},{}'.format(card, device))
Cloud Speech APIによる、音声→テキスト変換
cloud speech APIはこのあたり の公式サンプルスクリプトを参考にしています。本来であれば、音声を入力しながら同時進行でリクエストを送ってテキストに変換するストリーミング機能を使いたかったのですが、今回は時間の関係でできませんでした。
from google.cloud import speech
from google.cloud.speech import enums
from google.cloud.speech import types
def audiofile_to_text(self,filename):
"""
Speech APIを使って、wavファイルをテキストに起こす
"""
client = speech.SpeechClient()
# The name of the audio file to transcribe
file_path = os.path.join(
os.path.dirname(__file__),
'voicedata',
filename)
# Loads the audio into memory
with io.open(file_path, 'rb') as audio_file:
content = audio_file.read()
audio = types.RecognitionAudio(content=content)
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=self.rate,
language_code='ja-JP')
# Detects speech in the audio file
response = client.recognize(config, audio)
if len(response.results) == 0:
return("no_input")
alternatives = response.results[0].alternatives
for alternative in alternatives:
print('Transcript: {}'.format(alternative.transcript))
return(alternative.transcript)
その他もろもろのスクリプト全体像
後日きっとたぶん公開されるであろう、GitHubをお待ち下さい。。。
記事では解説していないですが、対応できるボケの種類として
- 日付に応じて冬なのに冷房を入力したらツッコむ
- 小数点で入力したらツッコむ
という機能もついています。
いろいろゴニョゴニョして...
完成しました!
実際の挙動はこちらの動画を確認してください。
ツッコミを入れてくれるAIスピーカー「Ahoca」試作機映像 from fujit33 on Vimeo.
動画いかがだったでしょうか。期待を下回る結果だったと思います。
ただし、今回は試作機ということでご勘弁をいただき、Ahocaのこれから成長にご期待下さい!
今抱えている課題
- 重要度小
- 入力している小峠の音質が悪すぎて何言ってるかわからない
- アナログ端子で接続しているため、さらに音が悪い
- ツッコミのパターンが少なすぎる
- 対応可能なボケのパターンについては、エアコンの設定温度のみ
- エアコンの設定温度にしかツッコめない
- 重要度大
- 実行するのにPythonスクリプトを手打ちしていて、全然AIスピーカーじゃない
- そもそも本当にエアコンを操作することができない
まとめ
今回は、ボケを異常検知で表せるんじゃないか、それって今流行のなんとかスピーカーに組み合わせたら面白いんじゃないか、ラズパイ触ってみたい、という趣味と流行りと興味でつっぱしりました。
お笑いの分析はこれからも続けていくので、ご興味がある方はぜひ一緒に分析して面白いものを作りましょう。
引き続き、BrainPad Advent Calendar 2017 をお楽しみください!