はじめに
みずほリサーチ&テクノロジーズ株式会社の@fujineです。
Python Advent Calendar 2022の19日目になります。
本記事では、今年2022年にQiitaに投稿された全記事を収集し、いいね数やタグのトレンド、貢献ユーザーなどを分析・可視化しました。
- 「いいね」が大抵1~2個しか貰えないんだけど、これは平均より高い?低い?
- 「いいね」を貰いやすい時間帯やタグってある?
- 今年は、どんなタグが人気だった?
- 良記事を多数投稿したユーザーは誰?
といった疑問をデータから明らかにすることが狙いです。
2022年末までまだ1週間近く残っていますが、現時点で集計しても統計値は大きく変動しないという仮定のもの、本記事を執筆しました。
2023年になりましたらデータを再度収集・分析し、本記事を更新する予定です。
データ収集
まずは、Qiita APIを使用して2022年の全記事を収集します。
アクセストークンの取得
アカウントの設定画面から、個人用アクセストークンを取得します。スコープは read_qiita のみを選択しました。
全記事を収集
2022/1/1から2022/12/18までに投稿された全記事をPythonで収集します。
プログラムはこちらを展開下さい。
-
USE_KEYSで、以降の分析に必要なKeyのみを抽出しています。 -
created:で記事の投稿年月日を指定します。created:2022のように年だけの指定も可能ですが、ページネーションの上限を超えてしまうため、created:2022-01のように月単位でクエリしました。 -
clean関数でデータを整形します。tagsはタグ名のリストに、userはuser.id(アカウント名)にそれぞれ置き換えています。 - 認証ユーザーの利用制限は1時間あたり1,000回のため、
sleep(4)で固定インターバルを設定しました。
from pathlib import Path
import sys
from time import sleep
import json
import requests
YEAR = 2022
PER_PAGE = 100
API_TOKEN = sys.argv[1]
HEADERS = dict(Authorization=f'Bearer {API_TOKEN}')
URL = 'https://qiita.com/api/v2/items'
EXPORT_DIR = Path('data')
USE_KEYS = ('id', 'created_at', 'comments_count', 'likes_count', 'stocks_count', 'tags', 'title', 'user')
def get(month, page):
params = dict(page=page, per_page=PER_PAGE, query=f'created:{YEAR}-{month:02}')
res = requests.get(URL, params=params, headers=HEADERS)
res.raise_for_status()
return res.json()
def clean(item):
item = {k: v for k, v in item.items() if k in USE_KEYS}
item['tags'] = [tag['name'] for tag in item['tags']]
item['user'] = item['user']['id']
return item
for month in range(1, 13):
for page in range(1, 100):
items = get(month, page)
if not items:
continue
items = [clean(item) for item in items]
filepath = EXPORT_DIR / f'{YEAR}_{month:02}_{page:02}.json'
with open(filepath, mode='w', encoding='utf-8') as f:
json.dump(items, f, indent=4)
sleep(4)
収集データは、year_month_page.jsonというフォーマットでdataディレクトリに保存されます。
約2時間で、計958ファイル(約45MB)が収集されました。
$ ls data/*.json | wc -l
958
環境準備
PythonのPandasでデータを分析、seabornで可視化していきます。
Pythonと各パッケージのバージョンは以下の通りです。
$ python -V
Python 3.7.12
$ pip list | grep -E "numpy|pandas|seaborn|japanize-matplotlib"
japanize-matplotlib 1.1.3
numpy 1.21.6
pandas 1.3.5
seaborn 0.12.1
各パッケージをimportします。
from pathlib import Path
import japanize_matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
sns.set(font='IPAexGothic', rc={'figure.figsize':(12, 4)})
全データを読み込みます。
記事のidをindexとし、投稿日時(created_at)からタイムゾーンを除外しています。
items = [pd.read_json(path) for path in Path('data').glob('*.json')]
items = pd.concat(items, ignore_index=True).set_index('id')
items['created_at'] = items['created_at'].dt.tz_localize(None)
データの先頭5件を出力してみましょう。
items.head()
| comments_count | created_at | likes_count | stocks_count | tags | title | user | |
|---|---|---|---|---|---|---|---|
| id | |||||||
| 9c4e2d365cd6f5a45514 | 0 | 2022-01-29 11:35:44 | 7 | 1 | [JavaScript, Node.js, Line, LINEmessagingAPI, ... | Flex Messageがしんどいメモ | n0bisuke |
| 8876f9bad7cc06ab73c5 | 0 | 2022-01-29 11:34:55 | 3 | 0 | [PowerBI, DAX, PBIJP, PowerPlatform] | [Power BI] データリネージュと TREATAS | akihiro_suto |
| 87f278c3df5129ae990b | 0 | 2022-01-29 11:30:37 | 0 | 0 | [Network, GRE, GNS3, ルーター, IPsec-VPN] | 久しぶりにGNS3(その5:トンネリング:GRE over IPsec) | infinite1oop |
| 4c8417934ad58bb7709d | 0 | 2022-01-29 11:21:33 | 4 | 1 | [GoogleCloudPlatform, Firebase, Nuxt] | Firebase Storageの使用量が勝手に増えていく件 → Firebase Func... | Wallaby19 |
| 4d4dbf781b9a896683f7 | 0 | 2022-01-29 11:12:09 | 1 | 0 | [cookie, React, next.js, getServerSideProps, g... | Next.jsのgetStaticPropsではnookiesによってcookieのデータを... | kosuke-17 |
以上で準備が整いました。これから、全記事を様々な角度から分析してみます。
記事の総数は約9.5万件
総記事数は約9.5万件です。平均で1日あたり260件近い記事が投稿されていることになります。
len(items)
95346
いいね数、ストック数の分析
ここでは、多くの読者や投稿者の方々が気になるであろう、いいね数とストック数について分析します。
最多いいね数は2,885!
最も多くのいいねを獲得した記事の上位10件を抽出しました。最多いいね数は2885です!。私もこんな沢山のいいねを貰いたい...
tagsを見ると、 「フロントエンド技術」、「新人プログラマ応援」、「英語」 等が共通していることが分かります。タグのトレンド分析は、以降でも詳しく分析します。
items.nlargest(10, columns='likes_count')[['likes_count', 'title', 'user', 'tags']]
| likes_count | title | user | tags | |
|---|---|---|---|---|
| id | ||||
| f3268b311e11d5b821c0 | 2885 | 有名企業のエンジニア向け研修資料まとめ | KNR109 | [研修, エンジニア, 新人プログラマ応援, プログラミング初心者] |
| 1da55b3c8760cec6d25c | 2226 | エンジニアの"有害な振る舞い"への対処法 | muumu | [チーム開発, チームビルディング, エンジニアリングマネージャー] |
| 62dda256bb7ba6c08399 | 1718 | 初心者プログラマーのための英語命名法 | YutaManaka | [PHP, JavaScript, 初心者, 英語, 初心者向け] |
| a6b3216552bee53b1724 | 1655 | エンジニア向けチートシート集 | KNR109 | [CSS, JavaScript, Rails, TypeScript, チートシート] |
| 06e50b3f7f6238d9b51b | 1616 | console.log(); しか使えなかった自分へ。。。 | ashketcham | [JavaScript] |
| af433f1013221c5ed529 | 1429 | 【2022年最新】オススメのプログラミング学習サービス集 | KNR109 | [初心者, まとめ, 勉強, 新人プログラマ応援, プログラミング初心者] |
| 48f6e78237a04684ab38 | 1393 | コードレビューで嫌われる人の特徴7選 | emjo1804 | [GitHub, チーム開発, コードレビュー, 新人プログラマ応援, fwywd] |
| f4a6539e4fbc641c6fa0 | 1359 | 30代後半になって初めて発信活動を始めたら人生が変わった話 | kojimadev | [初心者, 初心者向け, 教育, コミュニティ, 新人プログラマ応援] |
| 5a92505eab4e9da7f4e9 | 1358 | 強いエンジニアになるために英語が必要と聞いたので4ヶ月でTOEICスコア400→900まで上げた話 | NasuPanda | [ポエム, English, toeic, 英語学習, 駆け出しエンジニア] |
| 50ba4e35289e98d95753 | 1324 | Webフロントエンドパフォーマンスチューニング75選 | nuko-suke | [JavaScript, Web, Vue.js, フロントエンド, React] |
いいね数の平均は4.2
全記事で平均したいいね数は4.2です。
私は1~2あたりだと事前予想していたため、意外な結果でした。この違和感は次の分析で明らかになります。
likes_mean = items['likes_count'].sum() / len(items)
likes_mean
4.218331130828771
いいねを2個獲得できれば、上位25%圏内
パーセンタイルを確認すると、いいね数とストック数はどちらも大きく歪んでいることが分かります。
items[['likes_count', 'stocks_count']].quantile([0.5, 0.75, 0.9, 0.95, 0.99]).astype(int)
| likes_count | stocks_count | |
|---|---|---|
| 0.50 | 0 | 0 |
| 0.75 | 2 | 1 |
| 0.90 | 6 | 3 |
| 0.95 | 12 | 6 |
| 0.99 | 59 | 43 |
- 中央値(50%)はどちらも0です。これは、全記事の半数がいいねもストックもされていないことを意味します。
- いいね数では、第3四分位(75%)が2です。これはいいね数が2個以上獲得できれば、その記事は上位25%圏内であることを意味しています。6個以上獲得できれば、上位10%圏内です。
- ストック数も、いいね数と近い分布を示しています。
いいね数の平均は4.2でしたが、このようにデータの分布を調べることで、平均値が代表値として相応しくない場合があることが確認できます。
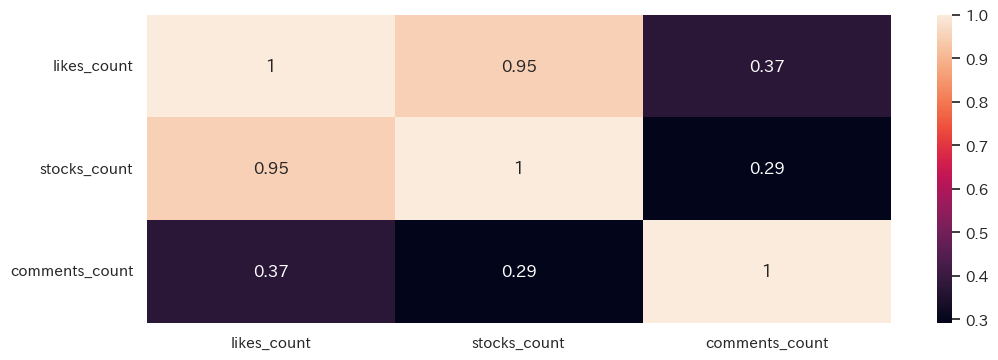
いいね数とストック数にはかなり強い相関がある
いいね数、ストック数、コメント数の相関係数を算出します。
- いいね数とストック数の相関係数は0.95で、かなり強い相関があります。良記事はいいねもストックもされやすいようです。
- 一方、コメント数といいね数・ストック数との相関係数は0.29~0.37であり、弱い相関関係であると言えます。
sns.heatmap(items[['likes_count', 'stocks_count', 'comments_count']].corr(),
annot=True)
投稿日時を分析
続いて、記事が何月、何曜日、何時に多く投稿されるのかを分析してみましょう。
はじめに、投稿日時の月、曜日、時間帯毎に記事の件数を集計します。
dt = items['created_at'].dt
counts = items.groupby([dt.month, dt.weekday, dt.hour]).size()
counts.index = counts.index.rename(['month', 'weekday', 'hour'])
counts
month weekday hour
1 0 0 69
1 56
2 23
3 14
4 10
...
12 6 19 83
20 91
21 107
22 125
23 127
Length: 2016, dtype: int64
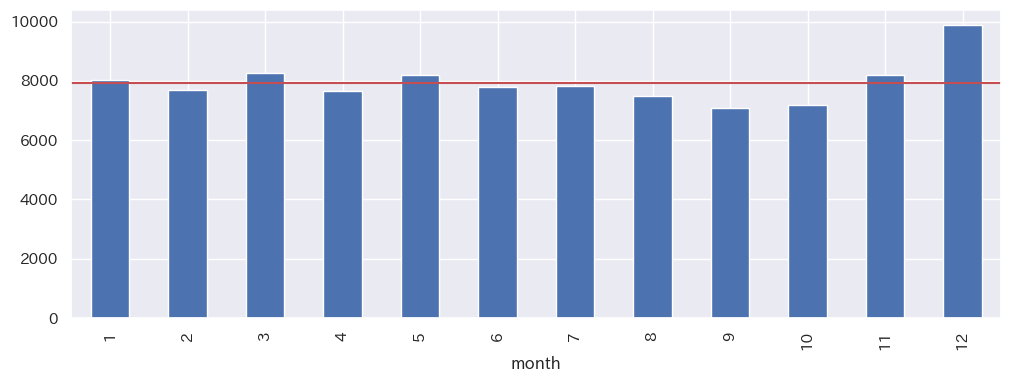
月別では、12月の投稿件数が多い
月毎の投稿件数は、平均で約8,000件(グラフの赤い横線)です。
各月を見ると、12月の投稿件数が突出しています。これは、毎年恒例のアドベントカレンダーによる影響でしょう。
12月以外の月については、多少の波はあるものの、大きな変化は無いようです。9~10月が比較的少ないのは、アドベントカレンダーに向けた記事の温存・準備のためでしょうか?
counts_month = counts.groupby('month').sum()
counts_month.plot(kind='bar')
plt.axhline(counts_month.mean(), color='r')
特定の曜日・時間帯に投稿が集中
曜日と時間帯で集計してみます。曜日の数値は、0が月曜日、6が日曜日となります。
counts_weekday_hour = counts.groupby(['weekday', 'hour']).sum().unstack('hour')
sns.heatmap(counts_weekday_hour, cmap="bwr")
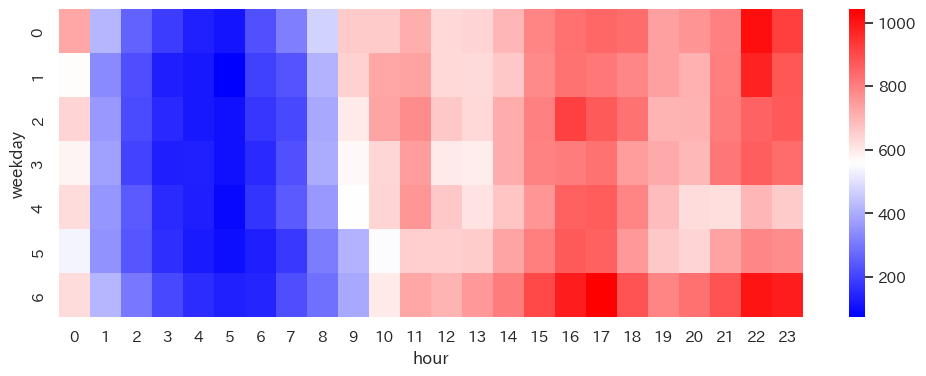
濃い赤に着目すると、全体的には16時~23時台に多く投稿されます。中でも、月~火曜日の22時前後、水曜日の16時台、日曜日の16時~23時台が特に集中しています。
あくま推測ですが、
- 月~火曜日の22時前後 ⇒ 業務終了後、自宅で記事を投稿
- 水曜日の夕方 ⇒ 会社や学校の早帰り効果?
- 日曜日の16時~23時台 ⇒ 月曜日に多数ユーザーが閲覧することを狙った投稿
という背景があるのでは、と想像しました。
なお、ヒートマップを上から下に向かって見ていくと、 Qiitaユーザーの残存体力が如実に見えてきます! 月曜(0)から金曜(4)にかけて、午前中の投稿タイミングは徐々に遅くなり、夜の投稿件数も次第に減少。土曜日(5)まで停滞が続き、日曜日(6)の夕方から投稿件数が一気に回復しています。
エンジニアの皆さん、毎日お疲れ様です。
午前中に投稿すると、いいねを獲得しやすい
投稿する時間帯毎にいいね数を集計すると、面白いことが分かりました。
likes_count = items['likes_count'].groupby(items['created_at'].dt.hour).agg(['sum', 'count'])
(likes_count['sum'] / likes_count['count']).plot(kind='bar')
plt.axhline(likes_mean, color='r')
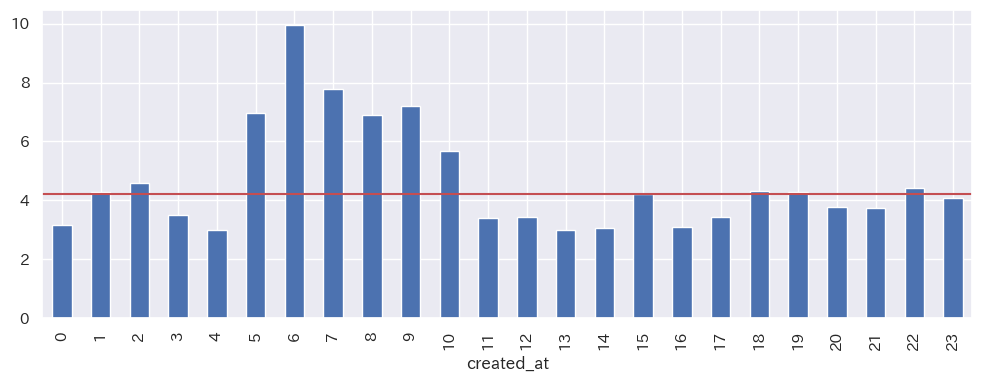
赤い横線は、いいね数の平均値(4.2)です。午前5時~10時の間に投稿された記事は、他の時間帯と比較して平均以上(最大で2倍)のいいね数を獲得しています。
この理由は3つ考えられます(ユーザーの履歴データは公開されていないため、あくまで推測です)。
- 午前中にQiitaを閲覧するユーザーが多い(通勤・通学中、始業時の習慣として閲覧)
- 投稿が集中する夜と比べて午前中の投稿はタイムラインに流されにくく、目に付きやすい
- 午前中は体力・思考力が十分にあり、ユーザーは記事をじっくり読むことができる
よって、いいねを沢山欲しい方は、午前中を狙って投稿してみましょう!
タグを分析
続いて、タグの件数や人気度、トレンドを分析します。
tags列はタグ名のリストのため、事前にexplode()関数で展開します。
tags = items.set_index('created_at')['tags'].explode()
タグの総数は26,198件
ユニークなタグは全部で26,198件あります。結構あるんですね。
tags.nunique()
26198
今年の最多タグランキングは、Python、初心者、AWS、JavaScript
使用されたタグの件数を集計します。
tags_count = tags.value_counts()
tags_count.nlargest(30).plot(kind='bar')
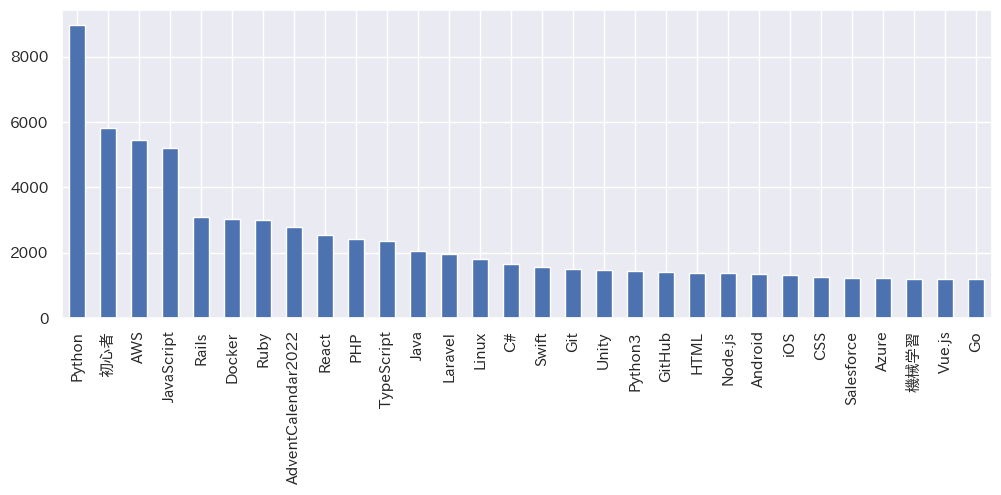
今年人気のタグは、Python、初心者、AWS、JavaScriptでした。
2021年のタグランキング(以下グラフ)ではPython、AWS、初心者、JavaScriptの順でしたので、初心者タグがランクアップしています。
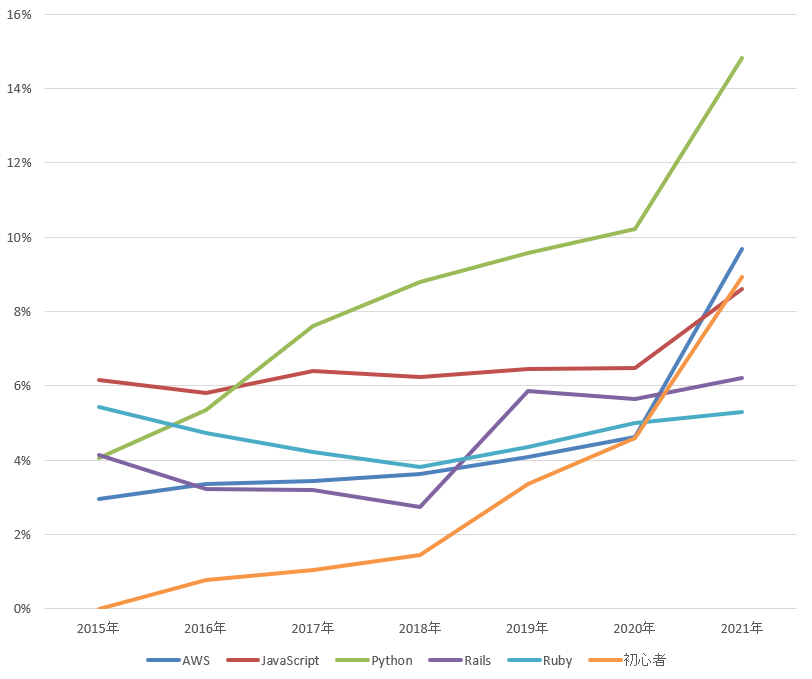
(「2021年版 Qiitaのタグ投稿割合から見るエンジニア業界の動き」より抜粋)
タグの半数以上は1回しか使われていない
人気のタグがある一方で、全タグの使用数のパーセンタイルを確認すると、タグの半数以上は1回しか使われていないことも分かります。
tags_count.quantile([0.5, 0.75, 0.9, 0.99]).astype(int)
0.50 1
0.75 4
0.90 12
0.99 144
Name: tags, dtype: int64
相当ニッチな技術なのかと思いきや、単純に名寄せされていないもの、スペルミス、面白半分で作られたタグも相当数ありました。Qiitaではタグの名寄せ方針を公開し、名寄せのリクエストと対応を行っておりますが、現状はタグがまだまだ分散している状態のようです。
print(tags_counts[tags_counts == 1].index.to_list()[:50])
['C-13X', 'CIFAR-100', 'ZXing.NET', 'Node.js16', '業務システム', 'pixel', 'bitcoind',
'Halide', 'ExplandOrCollapse', 'router-view', 'sites', 'PowerBITips', '対立仮説',
'dry-struct', 'eclipse-che', 'アンケート集計', '素数の列挙', 'コンタクトレンズ',
'パーティションのサイズ変更', '#エンジン', 'pandasgui', 'TreeMap', 'QRリーダ', 'SORBS',
'タイトル', 'discordgo', 'ブラックリスト', '#長期インターン', '魚拓', 'PGM',
'項目にアイコンを表示する', 'bigworld', 'react-native-google-mobile-ads', 'WebAudio',
'webterminal', '公開ボタンを押すの大事', '帰無仮説', 'nanoKONTROL2', 'VARモデル',
'メインループ', 'Loadshow', 'ロボやろ', 'インタラクティブ問題', 'シューティングゲーム',
'銀行', 'HG01', 'Dynamics365FieldService', '勤怠管理', '承認プロセス', '非線形計画法']
タグには季節性がある
タグの月別トレンドを見てみましょう。今回は、人気タグの上位50件を対象に月毎の変化率を算出し、変化率が100%以上増えたタグのみを抽出して可視化します。
tags_trend = items.query('likes_count > 0').set_index('created_at')['tags'].explode()
tags_trend = tags_trend[tags_trend.isin(tags_trend.value_counts().nlargest(50).index)]
tags_trend = pd.get_dummies(tags_trend).resample('M').sum().pct_change()
tags_trend = tags_trend[tags_trend.columns[tags_trend.max() > 1]]
tags_trend.index = tags_trend.index.month
tags_trend.index.name = 'month'
sns.heatmap(tags_trend, cmap="bwr", vmin=0.3, vmax=1.0, annot=True, fmt=".1f",
annot_kws={"fontsize":8})
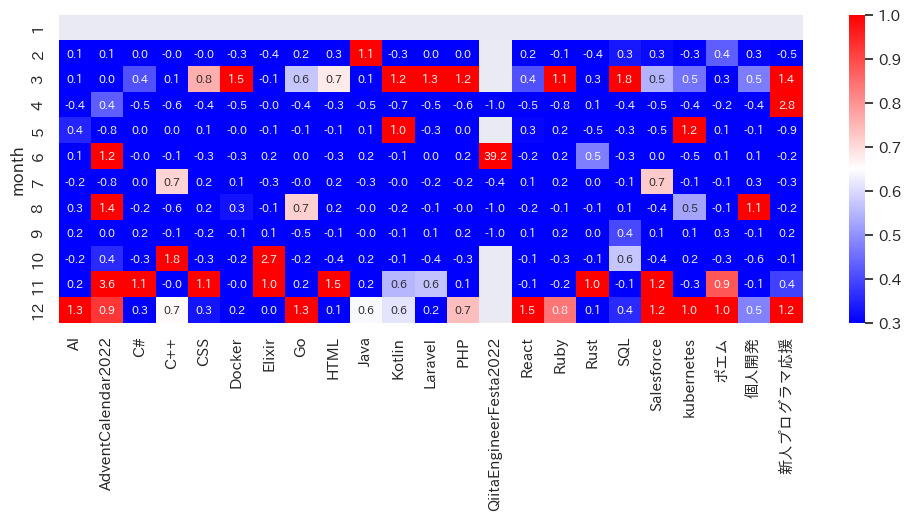
濃い赤に着目すると、季節性のトレンドがあることが分かります。
- 3月:Web系の技術を中心に半数近いタグが急増しています。4月は新卒/中途採用が始まる時期であり、同時期の記事には「個人開発」といったキーワードも多いため、 就職/転職を有利にすべく、自身のポートフォリオ作成に向けたサービス開発や情報発信に勤しむ方が増えたのでは、と予想されます。
- 3~4月:新入社員を対象とした「基本情報技術者試験」や「新人プログラマ応援」のタグが急増しています。
- 6月:QiitaEngineerFesta2022が開始し、タグ使用数が3900%近くまで高騰しています。
- 8月:夏休みや長期休暇を活用した「個人開発」が増加しています。
- 11月:QiitaAdventCalendar2022が急増します。今年は完走賞が抽選ではなく対象者全員となったため、完走賞を目指す人が11月中に記事を作成したものと思われます(自動投稿した場合、APIで取得した
created_atは投稿日ではなく記事作成日となります)。
季節性以外にも、対象技術に重要なアップデートや規約変更が起きた月は、タグの使用数が増加していました。
タグ数といいね数には、弱い相関がある
記事には最大5つまでタグを付与できます。対数変換したいいね数とタグ数には、弱いながらも正の相関関係があることが分かりました。
np.log(items['likes_count'] + 1).corr(items['tags'].apply(len))
0.1969516943301067
タグを多く設定することで、該当タグをフォローしているユーザーの閲覧数が増えることが要因と考えられます。ただし強い相関ではないため、いいね数を増やすにはタイトルと中身が大事という点は変わりません。
ユーザーの分析
最後に、記事を投稿したユーザーについて分析します。
投稿ユーザー数は22,959人
2022年に投稿したユニークユーザー数は、合計22,959人でした。
items['user'].nunique()
22959
年2回の投稿で上位50%圏内、8回の投稿で上位10%圏内
ユーザー毎の投稿数をパーセンタイルで確認します。
users.quantile([0.5, 0.75, 0.90, 0.95, 0.99]).astype(int)
結果はご覧の通りです。中央値(50%)が2のため、1年で2回投稿すれば上位50%圏内、8回投稿すれば上位10%圏内ということになります。
0.50 2
0.75 4
0.90 8
0.95 13
0.99 36
Name: user, dtype: int64
最も記事を投稿したユーザーは誰か?
投稿件数の多い上位10名の投稿件数をグラフ化します。赤線は1年間の日数(365日)です。
users.nlargest(10).plot(kind='bar')
plt.axhline(365, color='r')
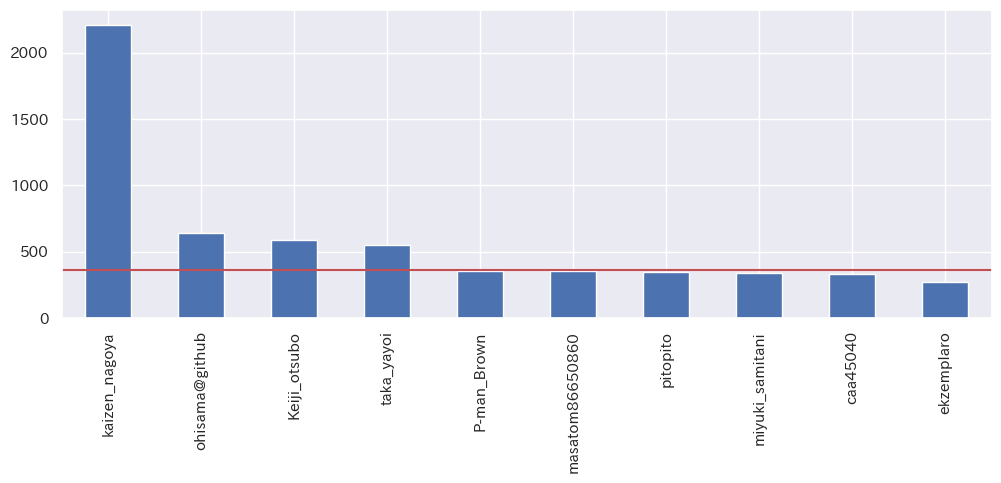
上位10名は1年で300件近い記事を投稿しています。驚異的な生産力です!
いいね数の平均値・合計値が最も高いユーザーは誰か?
続いて、いいね数を最も多く獲得した(有益な記事を提供された)貢献ユーザーを抽出します。
合計いいね数が高い上位10名を抽出し、いいね数の合計値と平均値を散布図で可視化してみましょう。
users_top10 = items.groupby('user')['likes_count'].agg(['sum', 'mean']).nlargest(10, columns='sum')
ax = sns.scatterplot(users_top10, x='sum', y='mean')
for user, v in users_top10.to_dict(orient='index').items():
ax.annotate(user, (v['sum'], v['mean']))
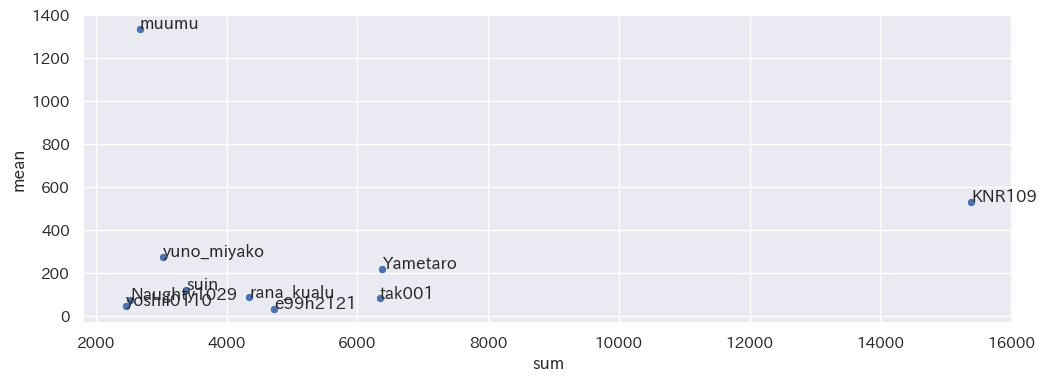
散布図の見方は、
- 右上に近いほど理想的な状態
- 右側に近いほど、記事の投稿数といいね数がどちらも多い
- 左上に近いほど、少数の記事で多数のいいね数を獲得した
ことを示しています。
@KNR109 さんは合計いいね数、@muumu さんは平均いいね数でダントツのトップでした!
まとめ
本記事では、2022年のQiita全記事を収集し、いいね数、タグのトレンド、貢献ユーザーについて分析しました。本記事を読んでいただき、今後の記事投稿のモチベーションやアイディアの参考になれば幸いです。
また、実際の分析を通じて、Qiitaの記事データにはもっと多くの可能性があると感じました。この記事を書きながら、
- 2022年以前のデータも収集し、年単位でのタグのトレンドや貢献ユーザーの推移を可視化
- タグの名前や組合せのデータをAIで学習し、名寄せの自動化にチャレンジ
- 記事のタイトル・記事・いいね数をAIで学習し、記事からタイトルの自動生成、いいねを獲得しやすいタイトルの推薦
等を次にやってみようと考え始めております。有益な結果が得られましたら、改めて記事化するつもりです。
私は1か月前にQiitaで投稿し始めたばかりの新参者ですが、来年以降も様々なテーマで技術発信を行っていきたいと考えております。
長文にお付き合いいただき、ありがとうございました。