今回は scikit-learn を使って K-近傍法 を試してみます。
K-近傍法とは
- 通称 K-NN(K-Nearest Neighbor Algorithm の略称)
- 特徴空間上において、近くにある K個 オブジェクトのうち、最も一般的なクラスに分類する。
- 距離の算出には、一般的にユークリッド距離が使われる。(他にマンハッタン距離などがある)
- 次元の呪いのため、高次元データには向かない。
- トレーニングデータ数・特徴量が増えると予測が遅くなる。
- クラス分類や回帰分析に利用可能
例)K = 3 なら クラスA に分類、K = 5 なら クラスB に分類される
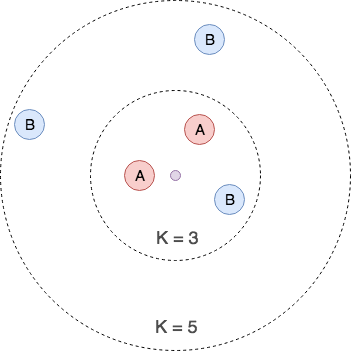
K 値の特徴
K の値によって精度が変わるため、最適な K の値を設定する必要があります。
| K | 特徴 |
|---|---|
| 小さい値 | ノイズに弱い |
| 大きい値 | 精度が下がる |
クラス分類
クラス分類には、KNeighborsClassifier クラスを使用します。
引数
| パラメータ名 | 概要 | 備考 |
|---|---|---|
| n_neighbors | K | 近傍オブジェクト数(初期値:5) |
| weights | 重み | ‘uniform’ : 均一の重み(初期値) ‘distance’ : 距離に応じた重み |
| algorithm | アルゴリズム選択 | ‘ball_tree’ : BallTreeデータ構造 ‘kd_tree’ : KD木データ構造 ‘brute’ : brute-force search(総当たり検索) ‘auto’ : 自動選択(初期値) |
| leaf_size | リーフサイズ | BallTree/KDTree のリーフサイズ(初期値:30) |
| n_jobs | 近傍検索ジョブ数 | -1指定時は CPUコア数が設定される (初期値:1) |
実際に分類を行ってみます。
アヤメの分類
アヤメという花の分類を行います。
特徴量として、萼(がく)片の長さ・幅、花びらの長さ・幅の4種類があり、
分類クラスとして、Setosa、Versicolor、Virgínia の3種類があります。
データ準備
・データ読み込み
sklearn のデータセットより、データを読み込みます。
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
# アヤメデータセット読み込み
from sklearn.datasets import load_iris
iris = load_iris()
# 特徴量
X = iris.data
# 目的変数
Y = iris.target
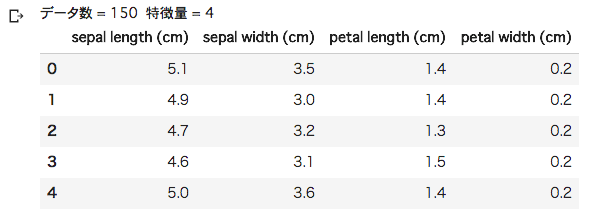
・特徴量表示
# データ表示(特徴量)
print("データ数 = %d 特徴量 = %d" % (X.shape[0], X.shape[1]))
pd.DataFrame(X, columns=iris.feature_names).head()
・目的変数表示
# データ表示(目的変数)
print("データ数 = %d" % (Y.shape[0]))
print(Y)
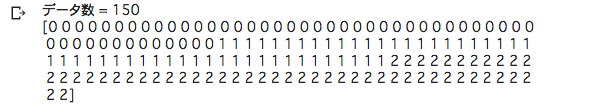
分類予測・精度
# トレーニング・テストデータ分割
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)
#
# K-近傍法
#
from sklearn.neighbors import KNeighborsClassifier
list_nn = []
list_score = []
for k in range(1, 31): # K = 1~30
# KNeighborsClassifier
knc = KNeighborsClassifier(n_neighbors=k)
knc.fit(X_train, Y_train)
# 予測
Y_pred = knc.predict(X_test)
# 評価 R^2
score = knc.score(X_test, Y_test)
print("[%d] score: {:.2f}".format(score) % k)
list_nn.append(k)
list_score.append(score)
# プロット
plt.ylim(0.9, 1.0)
plt.xlabel("n_neighbors")
plt.ylabel("score")
plt.plot(list_nn, list_score)
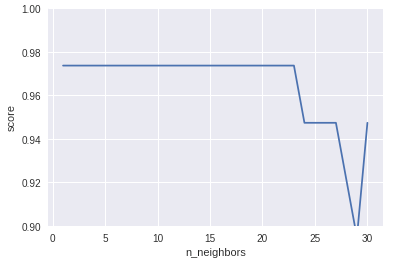
K = 1~30 まで実行しました。
K = 1~23 までの精度は 97% ですが、K = 24 以降は精度が下がっています。
K の値は、少ない数値で問題なさそうです。
乳がんデータの分類
乳がんデータの分類を行います。
特徴量として 30種類があり、分類クラスとして 悪性(malignant)、良性(benign) の2種類があります。
データ準備
・データ読み込み
# 乳癌データセット
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
# 特徴量
X = cancer.data
# 目的変数
Y = cancer.target
・特徴量表示
# データ表示(特徴量)
print("データ数 = %d 特徴量 = %d" % (X.shape[0], X.shape[1]))
pd.DataFrame(X, columns=cancer.feature_names).head()
以下のようなデータがあり、データ件数は 569件です。
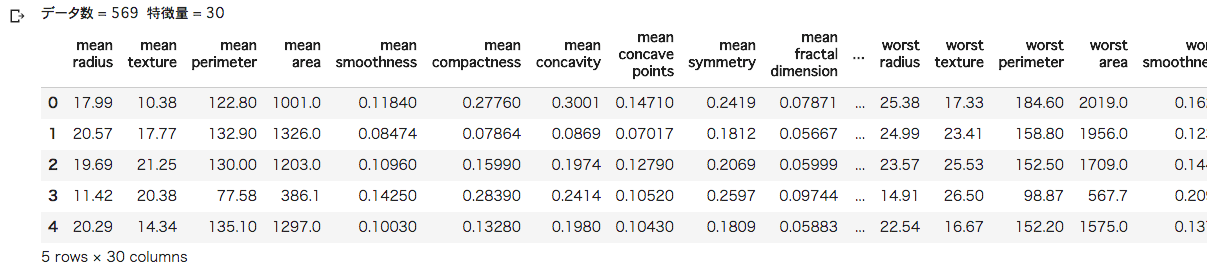
# データ表示(目的変数)
print("データ数 = %d" % (Y.shape[0]))
print(Y)

分類予測・精度
# トレーニング・テストデータ分割
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)
#
# K-最近傍法
#
from sklearn.neighbors import KNeighborsClassifier
list_k = []
list_score = []
for k in range(1, 11):
# KNeighborsClassifier
knc = KNeighborsClassifier(n_neighbors=k)
knc.fit(X_train, Y_train)
# 予測
Y_pred = knc.predict(X_test)
# 評価 R^2
score = knc.score(X_test, Y_test)
print("[%d] score: {:.2f}".format(score) % k)
list_k.append(k)
list_score.append(score)
# プロット
plt.ylim(0.9, 1.0)
plt.xlabel("k")
plt.ylabel("score")
plt.plot(list_k, list_score)
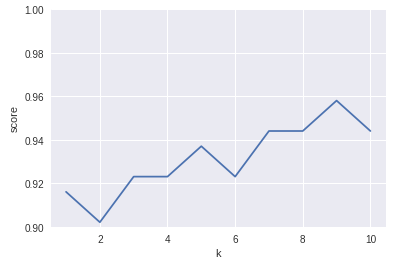
K = 9 で 精度が 96% になりました。
回帰分析
回帰分析には、KNeighborsRegressor クラスを使用します。
引数
| パラメータ名 | 概要 | 備考 |
|---|---|---|
| n_neighbors | K | 近傍オブジェクト数(初期値:5) |
| weights | 重み | ‘uniform’ : 均一の重み(初期値) ‘distance’ : 距離に応じた重み |
| algorithm | アルゴリズム選択 | ‘ball_tree’ : BallTreeデータ構造 ‘kd_tree’ : KD木データ構造 ‘brute’ : brute-force search(総当たり検索) ‘auto’ : 自動選択(初期値) |
| leaf_size | リーフサイズ | BallTree/KDTree のリーフサイズ(初期値:30) |
| n_jobs | 近傍検索ジョブ数 | -1指定時は CPUコア数が設定される (初期値:1) |
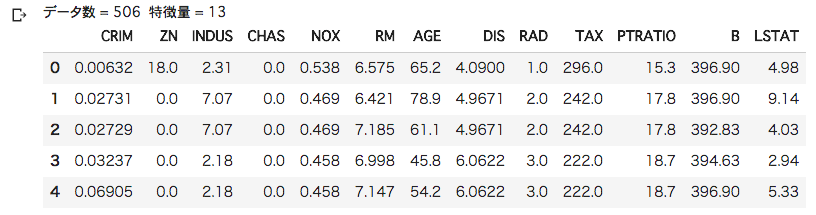
ボストン住宅価格データの回帰分析
ボストン住宅価格データの回帰分類を行います。
特徴量として 犯罪発生率や住宅区画の密集度など 13種類があり、
目的変数として、住宅価格があります。
今回は、特徴量として部屋数を使い住宅価格を予測します。
データ準備
# ボストン住宅価格データセット
from sklearn import datasets
boston = datasets.load_boston()
# 説明変数
X = boston.data
# 目的変数
Y = boston.target
・特徴量表示
# データ表示(特徴量)
print("データ数 = %d 特徴量 = %d" % (X.shape[0], X.shape[1]))
pd.DataFrame(X, columns=boston.feature_names).head()
・目的変数表示
# データ表示(目的変数)
print("データ数 = %d" % (Y.shape[0]))
print(Y[:10]) # 先頭 10件表示

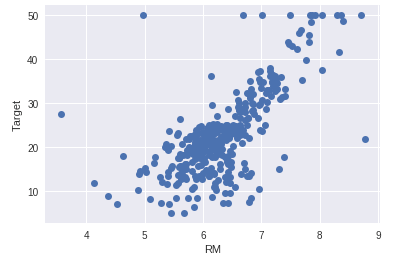
・トレーニングデータプロット
横軸に部屋数、縦軸に住宅価格を指定してプロットします。
# 説明変数に部屋数のみ使用
X = boston.data[:, [5]] # 部屋数
# トレーニング・テストデータ分割
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)
# プロット
plt.xlabel("RM")
plt.ylabel("Target")
plt.plot(X_train, Y_train, "o")
部屋数の増加に比例して、住宅価格が上がっています。
右肩上がりの正の相関関係になっています。
予測・精度
住宅価格の予測、及び、精度を確認します。
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
list_k = []
list_score = []
for k in range(1, 21):
# KNeighborsClassifier
knr = KNeighborsRegressor(n_neighbors=k)
knr.fit(X_train, Y_train)
# 予測
Y_pred = knr.predict(X_test)
#
# 評価
#
# 平均絶対誤差(MAE)
mae = mean_absolute_error(Y_test, Y_pred)
# 平方根平均二乗誤差(RMSE)
rmse = np.sqrt(mean_squared_error(Y_test, Y_pred))
# スコア R^2
score = knr.score(X_test, Y_test)
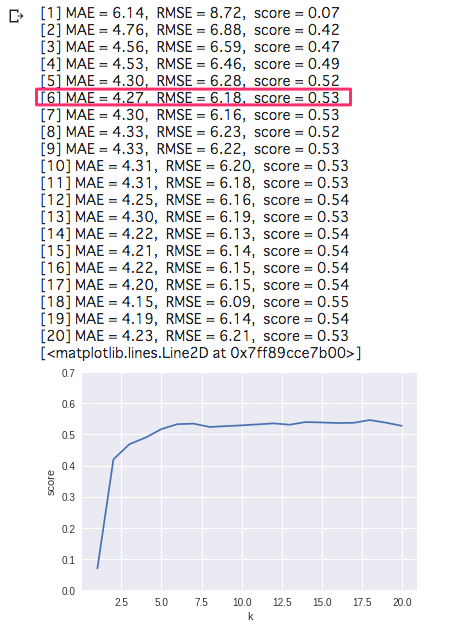
print("[%d] MAE = %.2f, RMSE = %.2f, score = %.2f" % (k, mae, rmse, score))
list_k.append(k)
list_score.append(score)
# プロット
plt.ylim(0, 0.7)
plt.xlabel("k")
plt.ylabel("score")
plt.plot(list_k, list_score)
・平均絶対誤差(MAE)
正解値と予測値の差分の絶対値を平均したもの
・平方根平均二乗誤差(RMSE)
正解値と予測値の差分の二乗を平均し、平方したもの
K = 6 以降、ほとんど変化がありません。
K 値は 6 で良いようです。
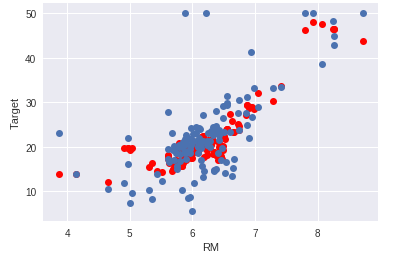
テストデータの部屋数を使った住宅価格の予測値をプロットしてみます。
青が実際の価格、赤が予測価格になります。
# テストデータ上での正解値(青)と予測値(赤)をプロット
K6_Pred = np.array(list_pred)[5]
plt.xlabel("RM")
plt.ylabel("Target")
plt.plot(X_test, K6_Pred, "ro")
plt.plot(X_test, Y_test, "o")
正解値と同様に右肩上がりのグラフになりました。
大まかな予測は出来ているようです。
以上、今回は scikit-learn を用いた K-近傍法 を試しました。