はじめに
現在、AI開発において、ノーコード、ローコード、AutoML、AIの民主化などが注目されており、また、Generative AIは世界的なブレークスルーを起こしつつあります。
ChatGPT をはじめとした大規模言語モデル(LLM)のビジネス活用はその可能性を急速に広げるなか、RAG(Retrieval Augmented Generation)やFine-tuningなどの独自カスタマイズの要望が高くなってきており、様々なAIプロダクトが、対応を始めてきています。

このような取り組みに対しては、データ品質が悪いとモデル精度が劣化していく可能性があり、高品質なデータが必要となります。このような現状からData-Centric AIが再注目される可能性があると考え、本記事にて概要をまとめておきたいと思います。
Data-Centric AIとは
Data-Centric AIは、米国時間で2021年3月24日に開かれた「A Chat with Andrew on MLOps」というオンラインイベントにおいて、Google Brainの共同設立者であり世界有数のAI研究者で、現在、DeepLearning.AIのAndrew Ng先生が「MLOps: From Model-centric to Data-centric AI」Iというスピーチを行ったことに端を発する。
現状、AI開発において、既存データに対していかに機械学習モデルを改善して精度アップを図るかに注目が集まりがちでした。このようにデータを固定してモデルを改善していくアプローチはModel-Centric AI(モデル中心のAI)と呼ばれますが、Data-Centric AI(データ中心のAI)は逆にモデルを固定してデータを改善していくアプローチです。
これらは二者択一ではなく、どちらも重要であり、実際のプロジェクトにおいては両面から取り組むことが多いですが、モデル改善の方がAI開発の花形として多く語られているのが実情です。Andrew Ng先生はあえてData-Centric AIという言葉を使うことによって、AI開発におけるデータ改善の重要性、またその体系化の必要性を訴えていると考えられます。
2021年には、AI/機械学習の業界全体から大きな注目を集め、トップカンファレンスのNeurIPSで「NeurIPS Data-Centric AI WorkshopI」というワークショップが開催されたり、DeepLearning.AIが「Data-Centric AI CompetitionI」という競技大会を開催したりと、さまざまな活動がありました。
データサイエンティスト見解
私が、興味深ったのが、「A Chat with Andrew」のイベント中のアンケートにおいて、「モデルを改善すべきか、それともデータを改善すべきか?」を参加者に聞いたところ、参加されたデータサイエンティストの20%はモデル改善、80%はデータ側を改善すべきと回答しました。(個人的にもデータ側押しです)
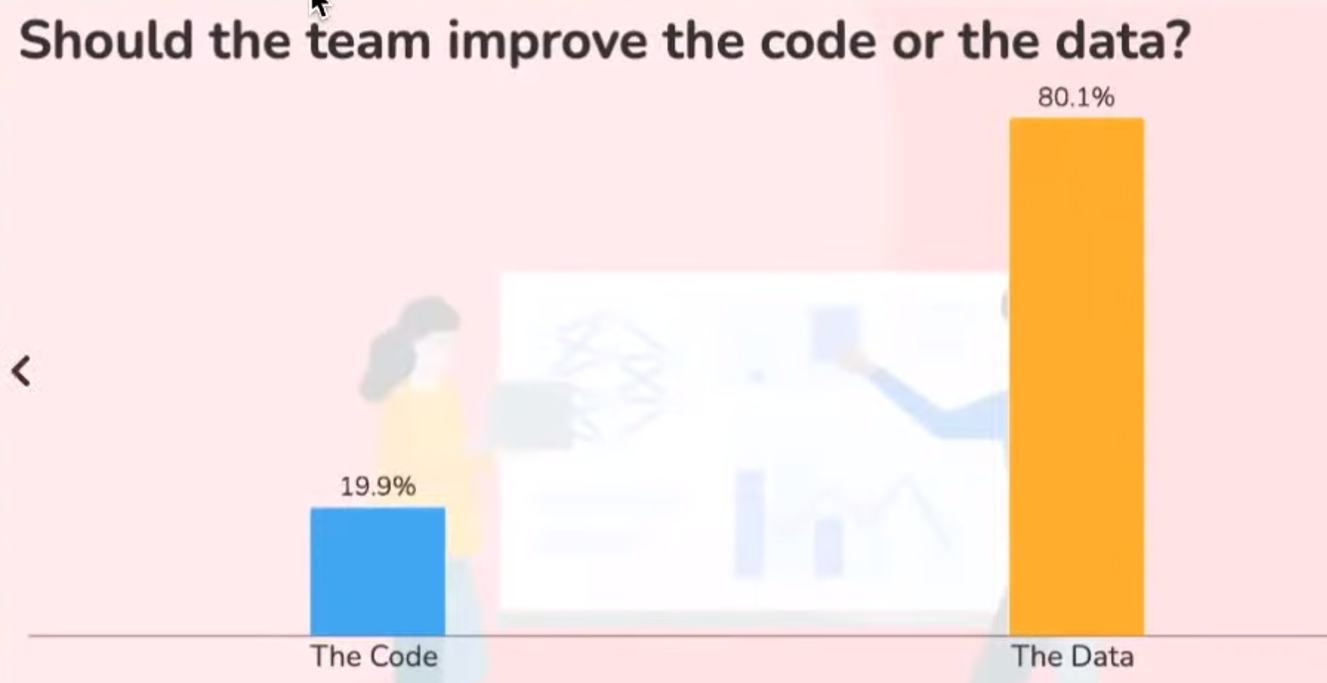
参照:A Chat with Andrew on MLOpsI
経験豊富なデータサイエンティストは、モデルをいじるよりもデータクリーニング・マイニング行う方が価値があることを知っていますが、大規模なデータセットでは、データ改造のプロセスが難しい場合があります。なので、データの品質改善は、ほとんどが個人の専門ナレッジや業務ナレッジに基づいた手作業によって、その場限りで行われてきたかと思います。
モデルの改善 vs. データの改善
AI開発に取り組むとき、データマイニングやデータマートを作成し、厳選されたデータから精度の高いモデル構築を実施していますが、実際にアプリケーションとして、業務に取り入れた際ではデータは固定されていませんし、運用では、ドリフト検知はするものの実データ品質をあまり気にしてないかと思います。実際のデータは非常に乱雑で品質問題を抱えている傾向があり、継続的に精度の高いモデルを作成するにはデータセットの改善が必要条件となります。「Garbage In, Garbage Out」の考え方もData-Centricと関連が深いと思われます。
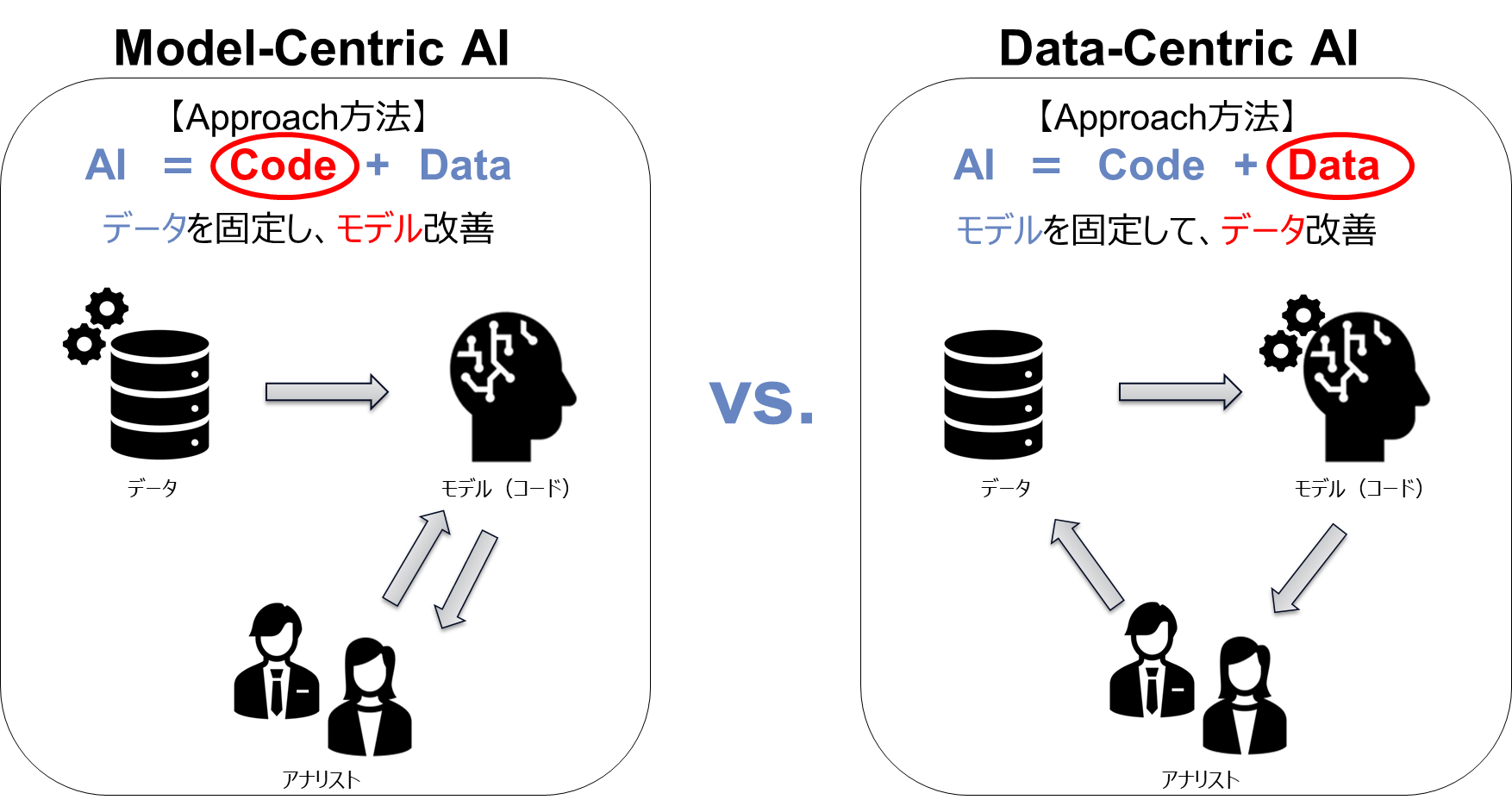
Model-Centric AIとData-Centricの比較
イベントでは、実際に3つの外観検査プロジェクトにおいて、既存のベースラインの改善をModel-CentricとData-Centricの両アプローチで実施し成果の比較結果が出ていました。Model-Centricではベースラインの性能をほとんど改善できなかったのに対し、 Data-Centricでは大きな改善が得られた結果となっています。

Big DataからGood Dataへ
Andrew Ng先生はイベントの中で、 Big DataからGood Dataを抽出すべきと言っていました。
■ Good Dataとは?
| 項目 | 概要 |
|---|---|
| 定義の一貫性 | ラベル・タグの定義に曖昧さがないこと |
| 重要なユースケースの網羅性 | 主要(重要)データの分布をカバーしていること |
| フィードバックループ | 運用のデータ・コンセプトドリフトをカバーしている事 |
| 適切なデータ量 | 過学習(Overfitting)がない、適切なデータサイズであること |
■ データ量が少ないほど、品質が重要
データの質の重要性は、データ量が少ない場合ほどより重要になって来ます。✖印がデータを表しており、与えられたデータを元に予測する機械学習モデルを作る(青い線が引けるようになるモデルを作る)ことを考えた場合、以下のようにデータ量が多い場合は線を引くのは簡単にできるが、データ量が少ない場合は、線を引くためには、品質が重要になってきます。
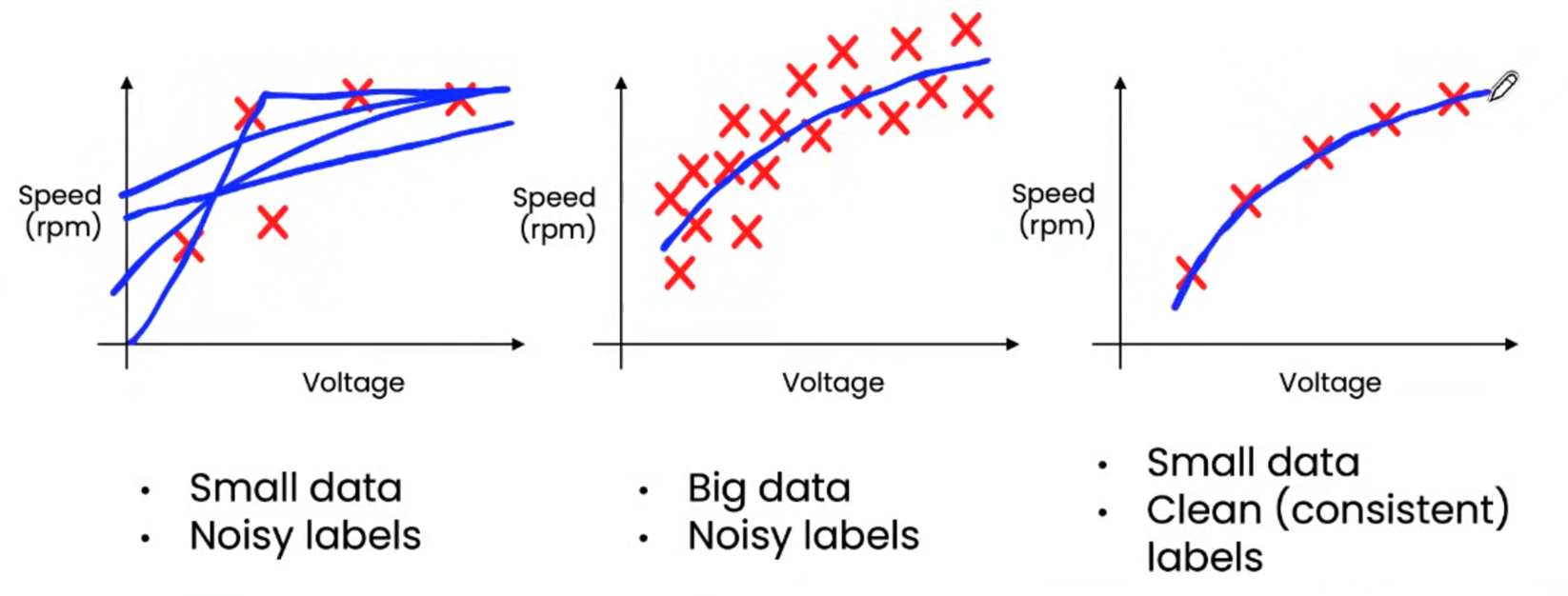
参照:A Chat with Andrew on MLOpsI
Data-Centric AIにおけるMLOpsの役割
品質の高い状態での、機械学習のプロジェクトを継続運用する為にはライフサイクル全体で、品質の高いデータを保証する必要があります。
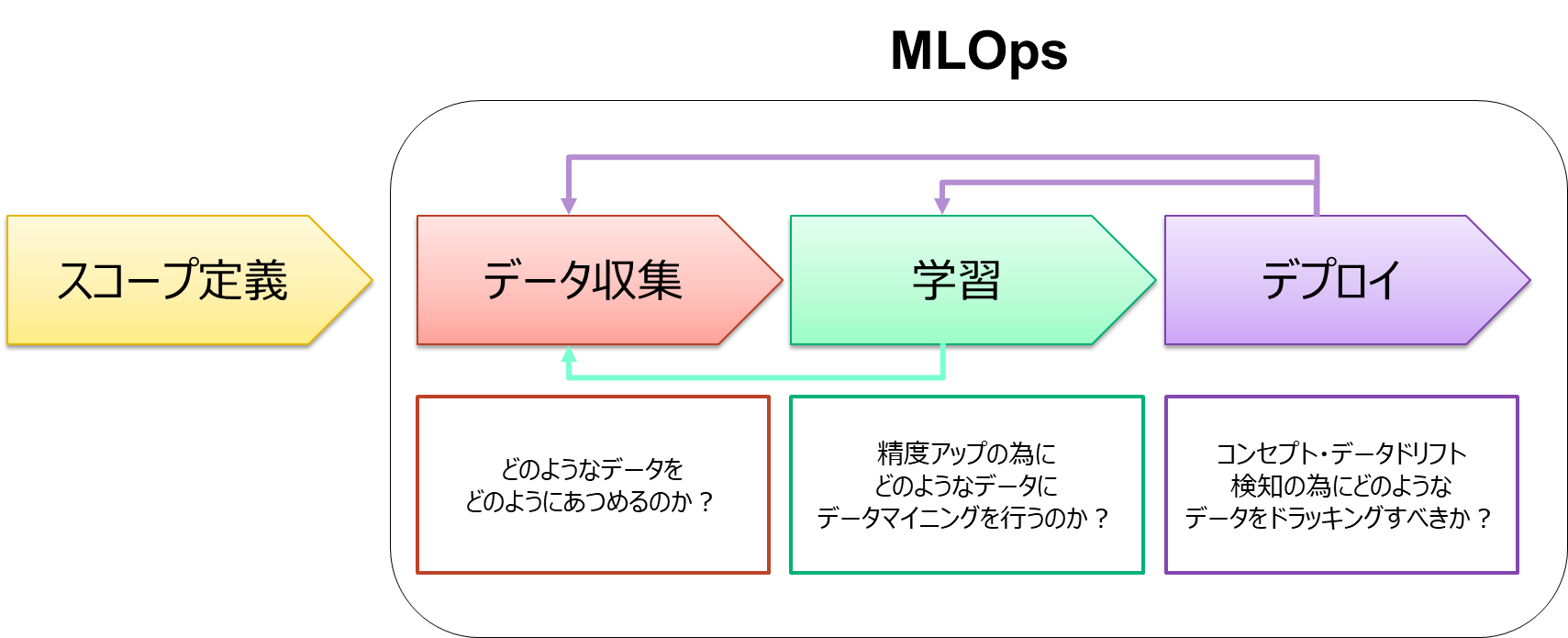
データの収集フェーズにてデータ定義や収集方法など決定し、ラベル付けを含むデータの準備や品質の高いデータを構築を行います。学習フェーズにて、モデルの構築を行い、モデルの精度アップを行い、Data-Centricでは、精度アップの為、データ収集フェーズ戻り、再度、質の高いデータ構築を行います。
最後にデプロイフェーズで、本番環境にモデルをリリースします。ご存じのように作ったモデルは、時間と共に劣化しますので、ここではモデルやデータのドリフト検知を行い、モデルの劣化では学習フェーズにもどり、データの劣化ではデータ収集のフェーズに戻るなどを行い、ライフサイクルをシステマチックに回していくことで,データの質を高い状態に保ちながら機械学習プロジェクトを運用することが必要になります。
まとめ
今回は、再注目される可能性が高いData-Centric AIの概要をまとめてみました。
データ品質問題は、業種業態関係なく起こる可能性があり、手動でそれに対処することは多大な負担となります。また、データセットが大きくなるにつれて、データセットの品質を保証することは不可能になります。
ChatGPTのような大規模なデータセットで学習されたMLシステムは、低品質のトレーニングデータで、再学習を行うとモデルが劣化すると言われており、MLモデルが高品質なデータで、継続学習するために、自動化された手法と体系的なデータエンジニアリングがこれまで以上に必要になってくることが、予想される為、Data-Centric AI(データ中心のAI)が、流行るのではないかと感じています。