はじめに
みなさんが普段使っているブラウザですが、何気なく検索したり、Webサイトを開いたりしているとき、その裏側で何が起こっているか考えたことはありますか?
例えば、「検索バーにURLを入力してエンターを押す」といったシンプルな操作の裏には、実はたくさんの処理や仕組みが隠れています。
この記事では、ブラウザがWebサイトを表示するまでの流れを整理し、初心者の方にも分かりやすいように説明していきます。
これを理解することで、Web開発やネットワークに関する基礎知識を深めるだけでなく、日々のインターネット利用が少し違った視点で捉えられるようになるかもしれません。
この仕組みを理解する上で欠かせない知識がいくつあります。まずはそれらの基本的な知識をみていきましょう。
DNS・名前解決について
まず、はじめに覚えておきたいことは DNS(Domain Name System) です。
DNSとは、「ドメイン名」と「IPアドレス」を紐付けし、IPネットワーク上で管理するシステムです。
コンピューターやネットワーク機器は、IPアドレスのような数値しか扱うことができません。
しかし、数字のみからなるIPアドレスは人間にとっては覚えにくく、IPアドレスからでは通信先がどのようなWebサイトなのかも見当がつきません。
そこで、インターネット上にあるコンピューターに覚えやすい名前を付けるために考え出されたのが「ドメイン名」です。
| 役割 | 表示文字列の例 | |
|---|---|---|
| ドメイン名 | 任意設定した名称 | example.com |
| IPアドレス | ネットワークやコンピューターの識別子 | 93.184.216.34 |
また、ドメインは階層的に構成されており、TLD(トップレベルドメイン)、2LD(セカンドレベルドメイン)、3LD(サードレベルドメイン)で成り立っています。
以下の画像がドメイン構造の例となります。

-
TLD(トップレベルドメイン)
- ドメインの最上位部分で
.com,.jp,.orgのように、国や組織の種類を表します
- ドメインの最上位部分で
-
2LD(セカンドレベルドメイン)
- TLDの前にあり、主に企業や組織、個人の名前に対応します
-
3LD(サードレベルドメイン)
- 自由な文字列を持つことができ、さらに細分化された構造を持つことができます
DNSによる名前解決の仕組み
ドメイン名を基にIPアドレスを導くプロセスを、「名前解決」と呼びます。
インターネットでは、膨大な数のドメイン名とIPアドレスの関連を、1台のコンピューターによって一元的に管理することは現実的でないため、世界中に分散した多数のDNSが連携して管理をする、階層的な「分散型データベース」を形成しています。
【補足】
-
正引き
- ドメイン名を基に対応するIPアドレスを調べる方法
-
逆引き
- IPアドレスを基に対応するドメイン名を調べる方法
ドメインからIPアドレスを引き出すまでには、以下の図のように、複数のDNSサーバーに対して反復検索を繰り返し、名前解決が行われます。

検索に使用するデバイスとデータの間をつなぐ役割を果たしているのがDNSサーバーです。ユーザーがドメイン名を入力すると、DNSサーバーがそのドメイン名に対応するIPアドレスを探し出し、目的のデータにアクセスできるようにします。
上の図のとおり、PCなどといったデバイスは、一度DNSサーバーを経由して情報を取得しています。
DNSサーバーが、この仕組みを成立させるために必要不可欠な存在であることがわかりますね。
DNSサーバーの種類
上の図より、DNSサーバーには下記の2種類があります。
- 権威DNSサーバー
- キャッシュDNSサーバー
一つずつ役割について見ていきましょう!
権威DNSサーバー
権威DNSサーバーとは、ドメインの情報を保管するサーバーのことです。上の図で示すと青枠の位置になります。
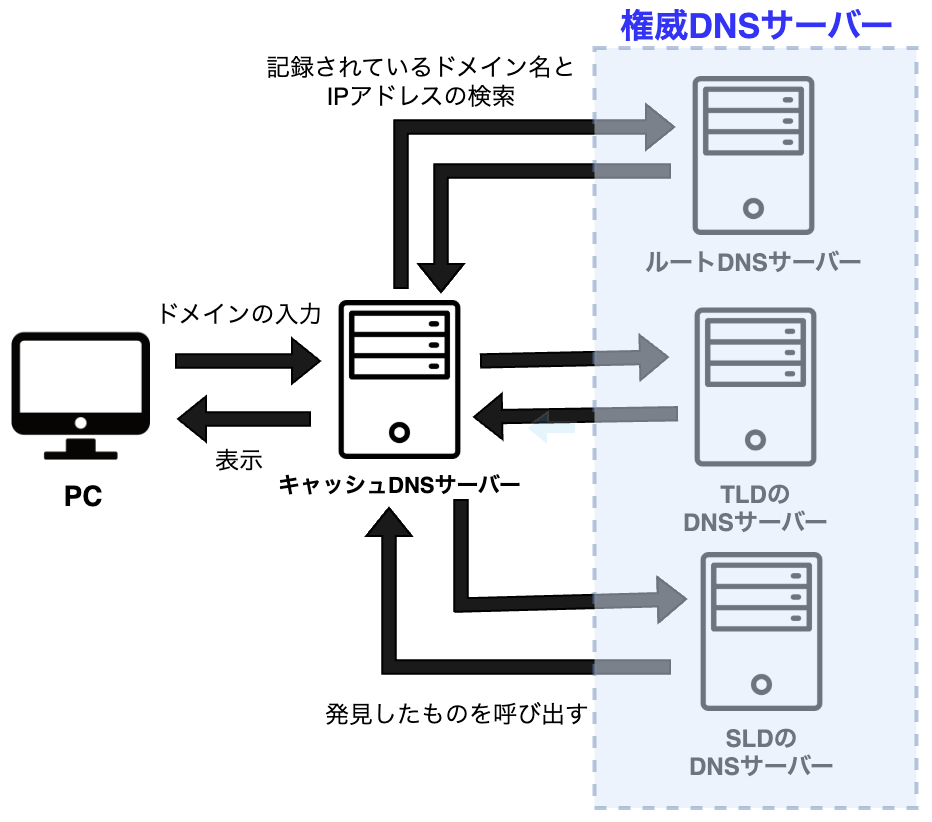
権威DNSサーバーは、後述するキャッシュDNSサーバーからの問い合わせに応じて、対応するIPアドレスを持つサーバーを特定します。
そして、そのサーバーと関連情報を見つけ出し、キャッシュDNSサーバーに返します。
キャッシュDNSサーバー
キャッシュDNSサーバーとは、入力されたドメイン名から権威DNSサーバーに合致する情報を探し出すよう指示を出すサーバーのことです。先ほどの図で言うと、下の黄色の部分に該当します。
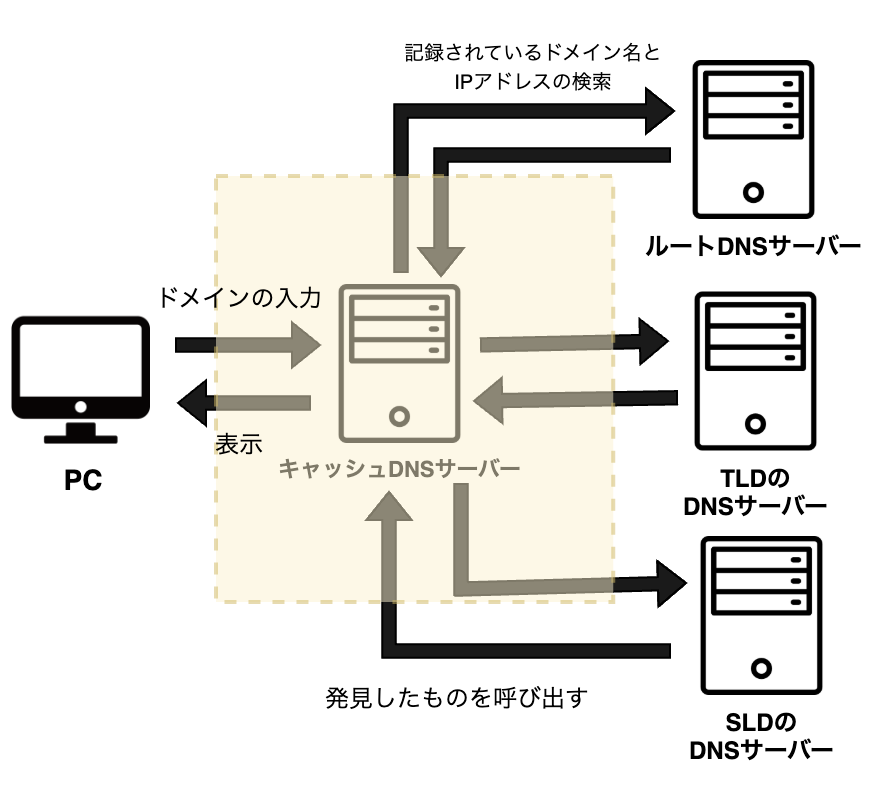
ほかにも多くのサーバーが絡んでいますが、権威DNSサーバーとキャッシュDNSサーバーが協力関係にあり、かつ重要な役割を担っています。
具体例と一緒に名前解決を考えてみる!!
では、「example.com」を例に進めていきます。
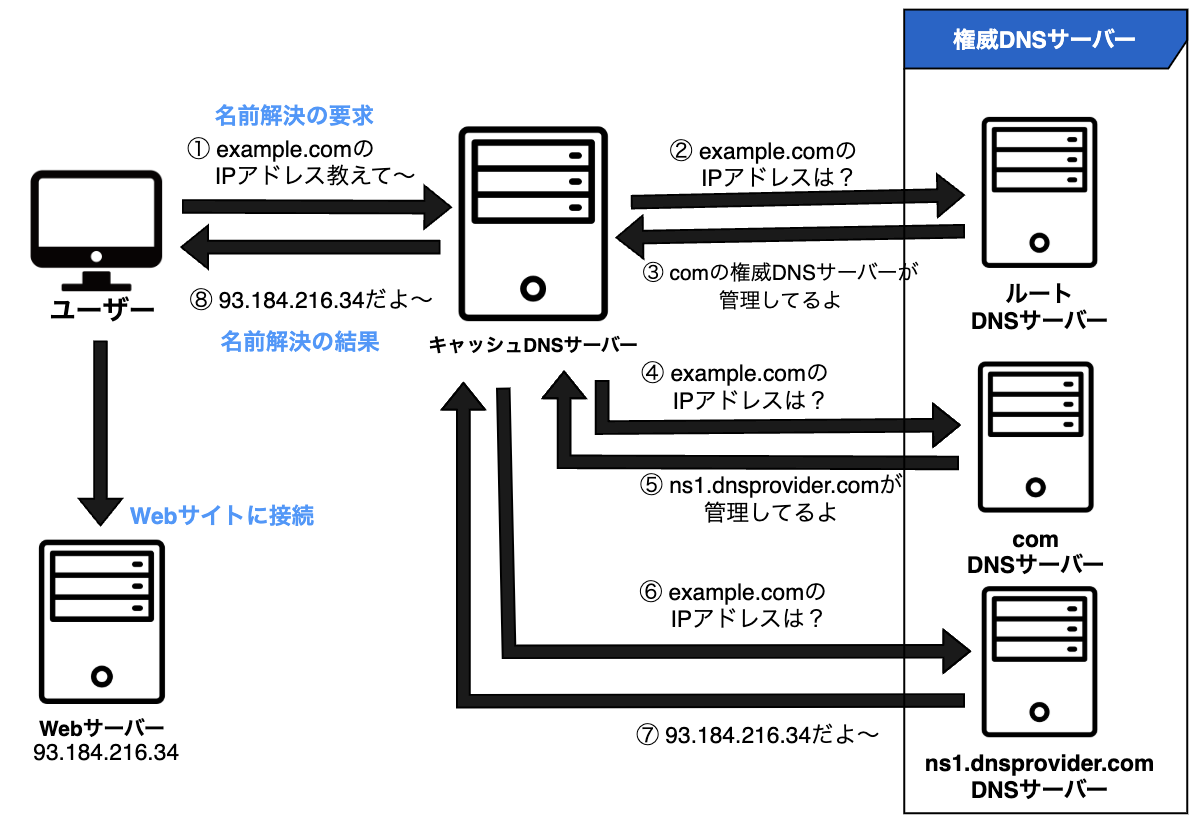
① ユーザーがドメイン名を入力
ユーザーがブラウザの検索バーにドメイン名(example.com)を入力し、Enterを押します。
すると、ブラウザは最初にローカルマシンの「リゾルバ1」が起動し、ローカルキャッシュ内に「example.com」のIPアドレスがあるかを確認します。
キャッシュにアドレスが見つからない場合、リゾルバはISP2や組織が提供する「キャッシュDNS」に問い合わせを行い、IPアドレスがキャッシュされているかを確認します。
もしISPのDNSサーバーが既にそのドメイン名のIPアドレスをキャッシュしている場合、それを直接クライアントに返すことでWebサイトにすぐにアクセスすることが可能になります。
②「キャッシュDNS」は、まず最上位層の「ルートDNS」に対し問い合わせ
ISPのDNSサーバーからルートDNSサーバーへ「example.comのIPアドレスは?」とクエリ(問い合わせ)が送られます。
ルートDNSサーバーは、インターネットのドメインネームシステム(DNS)の最上位に位置しており、主にドメインネームのTLD(トップレベルドメイン)への参照情報を提供します。
③ ルートDNSサーバーはcomのDNSサーバーが管理しているとレスポンスを返す
ルートDNSサーバーは直接リダイレクトするのではなく、適切なTLDサーバーへの参照リストを返すことで応答します。
④ TLDサーバーへ問い合わせ
ルートDNSサーバーからの情報を受け取ったISPのDNSサーバーは、「.com」などのTLDサーバーにクエリを送ります。
TLDサーバーは、そのドメイン名(example.com)に対応するネームサーバーの情報を保持しています。
TLDサーバーは、example.com に関連する権威DNSサーバー(ネームサーバー)のIPアドレスを返します。
⑤「comのDNSサーバー」は「example.com」を管理する権威サーバーである「ns1.dnsprovider.com」の情報を返す
今回の例では、TLDサーバーが、「ns1.dnsprovider.comが管理してるよ」と返します。
⑥「キャッシュDNS」は「ns1.dnsprovider.com」に対し問い合わせ
キャッシュDNSサーバーは、ns1.dnsprovider.comのDNSサーバーに対して「example.comのIPアドレスは?」とクエリを送ります。
⑦「ns1.dnsprovider.com」は「example.com」のIPアドレスを返します
ns1.dnsprovider.comは、example.comのIPアドレスは「93.184.216.34だよ〜」と返します。
⑧ 「キャッシュDNS」は得られた情報を「リゾルバ」に回答し、名前解決が終了
キャッシュDNSサーバーは得られた情報をリゾルバに返し、名前解決が完了します。
以上の①〜⑧のステップを踏むことで、名前解決がされているんですね〜
DNS名前解決後、Webサイトが表示されるまでの流れ
名前解決が終了した後は、どのような通信でどんなリソースを取得してWebサイトが表示されているのか順を追ってみていきましょう!
先ほどの名前解決を例に考えるとexample.comの名前解決が完了し、93.184.216.34というIPアドレスの取得に成功しました。
これにより、ブラウザは目的のWebサーバーの位置を特定できます。
ブラウザとWebサーバー間の通信
Webサーバーの位置を特定した後は、TCPコネクションの確立を行います。
(以降、HTTPにおけるTCPによる通信についてです)
このTCPのヘッダ内にある制御ビットの種類であるACK・SYN・FINなどの確認応答を使用した「受信準備はOKですか?」「準備OKです」といった送信元と宛先間の通信確認作業を行います。
これを「スリーウェイハンドシェイク」と言います。
下の図に示している通り、3回のメッセージのやり取りでコネクションの確立をしています。
このやり取りの交換を3回行なうのは、お互いの順序番号の初期値を確認するために必要かつ十分な回数だからです。
より詳しく接続の確立についてみていきます!
スリーウェイハンドシェイクは以下のような流れで行われます。
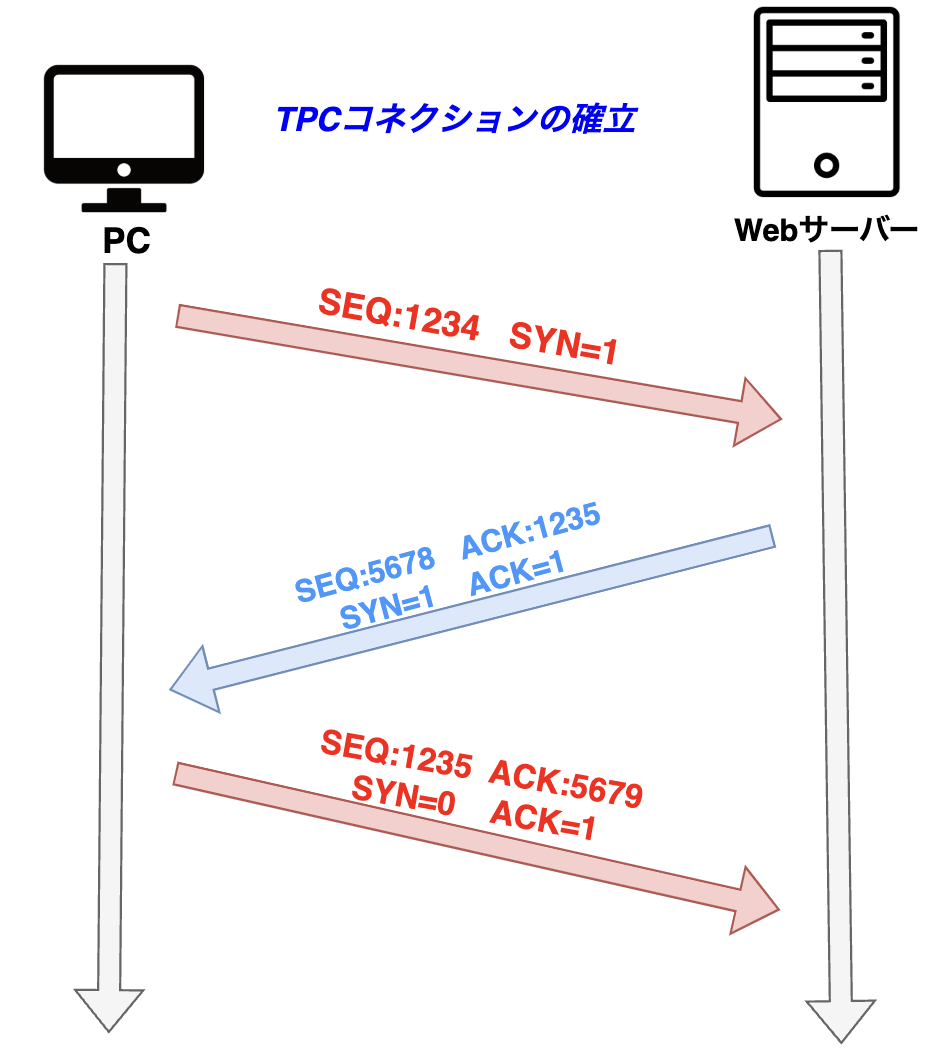
1. コネクションの確立要求
まず、PC(クライアント)はWebサーバー(宛先)に対し、SYN(SYNchronize:同期) フラグが立ったTCPパケットを送信します。
このパケットは「受信準備はOKですか?」と相手に問い合わせる意味を持ちます。
この時、TCPヘッダの 順序番号(SEQ) フィールドには、クライアント側の初期値を記入します。この値はランダムに設定され、直前のコネクションと重ならないよう工夫されています。
ここでは、仮にSEQ:1234・SYN=1とします。
2. コネクション確立要求への応答
Webサーバーは、PCからの SYNパケットを受信すると、次の内容を含むパケットをPCに返します。
-
SYNフラグ
- 「
Webサーバーも受信準備がOK〜」という意味で再びセット
- 「
-
ACK(Acknowledgment: 応答確認)フラグ
- PCからのリクエストを承認
-
順序番号(SEQ)
- Webサーバー側の初期値(例: SEQ=5678)
-
確認応答番号(ACK)
- PCのSEQに+1した値(例: ACK=1235)
このTCPヘッダのSEQフィールドには、Webサーバーの順序番号の初期値を記入します。
仮に5678とする。同時に、確認応答番号(ACK)フィールドには、相手(PC)の順序番号を正常に受信したことを伝えるため +1 の計算を行ない、1235を記入する。
そして、制御ビットのSYNフラグとACKフラグの両方をセットします。
このやり取りにより、WebサーバーはPCに対し「受信準備は完了しています」と伝えます。
3. コネクション確立
最後に、PCはWebサーバーからの応答パケットを受け取り、以下の内容を含むパケットを返します。
-
ACKフラグ
- 応答確認を示すフラグ
- 順序番号(SEQ)
- PCの次の順序番号(例: SEQ=1235)
- 確認応答番号(ACK)
- WebサーバーのSEQに+1した値(例: ACK=5679)
PCはWebサーバーへ確認応答を送信する。このときACK番号フィールドには、相手(Webサーバー)の順序番号を正常に受信したことを伝えるために +1 の計算を行ない、5679 を記入します。
また、制御ビットのACKフラグをセットされます。
この3ステップを踏んでTCPはコネクションの確立がされています。
HTTPS通信 では、TCPのスリーウェイハンドシェイクの後に、SSL/TLSハンドシェイクが続きます。
これにより、通信内容を暗号化し、盗聴や改ざんを防ぐことで、より高い信頼性とセキュリティを実現しています。
リソースの取得
スリーウェイハンドシェイクが完了すると、クライアントはWebサーバーにリソースの取得要求を送信します。例えば、WebページのHTMLや画像、CSSなどがリソースに該当します。
1. HTTPリクエストの送信
クライアント(PC)は、以下のようなHTTPリクエストを送信します(例: Webページのトップを取得する場合)。
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0
Accept: text/html
-
GET
- サーバーからリソースを取得するためのリクエストメソッド
- 上の例だと、「
/index.htmlという名前のページをください!」とリクエストを送っています
-
Host
- 接続先のホスト名を指定
-
User-Agent
- クライアント(ブラウザやアプリケーション)の種類
-
Accept
- クライアントが受け取れるコンテンツの種類を指定
2. サーバーからのレスポンス
サーバーはリクエストを受け取ると、以下のようなHTTPレスポンスを返します。
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 1234
<html>
<body>
<h1>Hello, World!</h1>
</body>
</html>
-
HTTP/1.1 200 OK
- ステータスコード3
200は「成功」を示します
- ステータスコード3
- Content-Type
- レスポンスデータの種類(例: HTML、JSON)
- Content-Length
- データのサイズ
- 上の例では、このHTMLデータの長さは1234バイトであることを示しています
3. リソースのレンダリング
クライアント(ブラウザ)はサーバーから受け取ったHTMLを解析し、Webページを表示します。
この過程では、HTMLの中に含まれる指示に従い、必要に応じて追加のリソース(CSS、JavaScript、画像など)を取得します。さらに、取得したリソースを基に以下の処理を行います。
-
CSSの適用
- ページのデザインを構築
-
JavaScriptの実行
- 動的な動きを付加
-
画像の描画
- 視覚的なコンテンツを表示
これらの作業が終わると、ブラウザ上に完成したWebページが表示されます。
さいごに
今回は、ブラウザにWebサイトが表示されるまでの流れを体系的にまとめてみました。
普段何気なく使っているブラウザですが、その裏側では、いくつものプロセスが連携して動いています。
DNSの名前解決から始まり、TCPコネクションの確立、HTTPリクエスト・レスポンス、そしてリソースのレンダリングまで、これらの仕組みがスムーズなWeb体験を支えています。
Webの仕組みを理解することで、私たちが日々当たり前に使っている技術への感謝や、インターネットの奥深さを感じられるのではないでしょうか?
やはり、ネットワークの世界は面白いですね!
最後までご覧いただき、ありがとうございます!
参考文献
-
リゾルバ(Resolver)
DNSに問い合わせを行うホストやソフトウェアをリゾルバと言います。ユーザーが利用するワークステーションやパソコンはリゾルバに当たります。リゾルバは最低でも一つ以上のネームサーバーのIPアドレスを知らなくてはなりません。通常はその組織内のネームサーバーのIPアドレスを登録します。 ↩ -
ISP(Internet Service Provider)
インターネット接続やIPアドレスの割り当て、DNSサーバーの提供を行う業者のこと ↩ -
ステータスコード
HTTP のレスポンスステータスコードは、特定の HTTP リクエストが正常に完了したどうかを示します。 レスポンスは 5 つのクラスに分類されています(MDN Web Docs)- よく使用されるステータスコードは以下のようなものが挙げられます
-
200OK: 正常に処理されました -
404Not Found: リクエストされたページが見つかりません -
500Internal Server Error: サーバー内部のエラーが発生しました
-
- よく使用されるステータスコードは以下のようなものが挙げられます