前置き: 会社の仕事でもKaggleっぽくやりたい
みなさま、Kaggleはお好きでしょうか。好きですよね。僕もKaggleやっていきたいのですが、まだ片手で数えられるほどしかコンペに参加できておらず歯がゆい思いをしております。今年はどんどん参加していきたい。
「ではこのGWは何をしていたのか、地震コンペも壺コンペもあったぞ!」 ...すみません、それはそのとおりです。でもこのGWは他にやりたいことが出来たのでそちらを進めておりました。それがこの記事で紹介したい EvalAI の検証です。
EvalAIについて

arxivに論文がありますので、そのアブストラクトを引用してみます。
We introduce EvalAI, an open source platform for evaluating and comparing machine learning (ML) and artificial intelligence algorithms (AI) at scale. EvalAI is built to provide a scalable solution to the research community to fulfill the critical need of evaluating machine learning models and agents acting in an environment against annotations or with a human-in-the-loop. This will help researchers, students, and data scientists to create, collaborate, and participate in AI challenges organized around the globe. By simplifying and standardizing the process of benchmarking these models, EvalAI seeks to lower the barrier to entry for participating in the global scientific effort to push the frontiers of machine learning and artificial intelligence, thereby increasing the rate of measurable progress in this domain.
(みらい翻訳で直した日本語)
機械学習(ML)と人工知能アルゴリズム(AI)を大規模に評価し,比較するためのオープンソースプラットフォームであるEvalAIを紹介する。EvalAIは、アノテーションやヒューマン・イン・ザ・ループに対して環境内で動作する機械学習モデルやエージェントを評価するという重要なニーズを満たすために、研究コミュニティにスケーラブルなソリューションを提供するように構築されています。これは、研究者、学生、データサイエンティストが世界中で組織された人工知能の課題を作成し、協力し、参加するのに役立つだろう。これらのモデルのベンチマーキングのプロセスを簡素化し標準化することにより、EvalAIは、機械学習と人工知能のフロンティアを推し進めるための世界的な科学的取り組みへの参入障壁を低くし、この分野における測定可能な進歩の速度を高めることを目指している。
まあ要するに、ベンチマーキングのプロセスを補助するためのソフトウェア、乱暴に言うとみんなが自分の環境でコンペできるようにしたからぜひ使ってくれよな!!!という感じです。
本文には内部のシステムなどについて細かい説明が書いてあります。DjangoとAngularjsで作られてますね。
様々な機能があるのですが、submissionを評価する際に別のサーバ(AWSなど)・Dockerコンテナにリクエスト出来るような仕組みがあったり、なんと強化学習の環境(Open AI Gym的な)をも提供可能になっているとのことです。今回はそこまで見てないですが、柔軟に自分たちの欲しい形式のコンペティションをホストできるようになっているみたいですね。
EvalAIのメリット・デメリット
EvalAIを用いる大きなメリットは言うまでもなく、外に出せないデータを使ってコンペティションを開催できる点です。Kaggleでもプライベートなコンペティションを開くことは In-CLassコンペティションによって可能だと思いますが、データはKaggle上にアップロードしないといけない以上、難しいと思います。
EvalAIであれば、任意のサーバ上にEvalAIを展開できるので、オンプレサーバなどデータを外にだすことなくコンペティションの形式を整えることが出来ます。
もちろんその分、自分たちでホストすることによる運用は発生しますが、部署内のデータサイエンティストらだけで利用するものだと考えればそこまで大きな手間ではないと思います。
EvalAIの実際の画面など
ここからは、実際にどんな感じでコンペに参加することが出来るのかなどを見ていきます。ちなみに、EvalAIはOSSとして提供されているだけでなく実際にEvalAI開発元のCloudCVがホストしてコンペを開催しています。 https://evalai.cloudcv.org
SignUpしてLoginすると、以下のように現在開催されているコンペティションを確認できます。

一つ選択してみると以下の画面に遷移します。

Participate から画面をポチポチしていけば、Submitできるようになります。特に迷うところはないです。
リーダーボードを確認してみると、こんな感じで全体のスコアが見れます。3チームしかいないのが寂しさを漂わせていますね

コンペティションを開催してみよう
EvalAIを自分の環境にインストールする
さて、ここからは実際に自分でコンペティションを開催してみようとおもいます。ここからは、自分が持っている環境で行います。勝手にコンペを作って迷惑をかける訳にも行かないので...
まずなにか適当に環境を準備します。ローカルでも良いですし、GCP・AWSでもなんでもよいです。 docker、 docker-composeを予めインストールしておきます。
できたら、その環境内でコードをクローンします。
git clone https://github.com/Cloud-CV/EvalAI.git evalai && cd evalai
その後、docker-compose でコンテナを起動します。
docker-compose up --build
ここまでできればもう http://127.0.0.1:8888/ にアクセスできるようになっています。簡単ですね。コンテナありがてえ。
コンテナを展開した時点で、以下のユーザが作られています。以下の手順を進める上で、HOST USER以上でログインしておきます。
SUPERUSER- username: admin password: password
HOST USER- username: host password: password
PARTICIPANT USER- username: participant password: password
コンペティションの設定ファイルを作ってアップする
左のメニューから Create Challenge を押して遷移すると、以下のように設定ファイルをzipに固めたものをアップせよと言われます。

公式でチュートリアル用のリポジトリが用意されているので、それを見つつ進めていきます。 https://github.com/Cloud-CV/EvalAI-Starters
行うべき手順は以下です。
- リポジトリをclone
- コンペティション設定ファイル(yaml)を編集
- 正解データと評価用スクリプト作成
- zipに固めてアップロード
- 管理画面からコンペをapproveした後に
workerをリスタートする
1. コンペティション設定ファイル
challenge_config.yaml というファイルがそれに当たります。 templates フォルダ内のhtmlを見ればおおよそどのような内容が求められているかはわかると思いますので、開催したいコンペティションの要旨に合うような文言を設定していきます。
# If you are not sure what all these fields mean, please refer our documentation here:
# http://evalai.readthedocs.io/en/latest/challenge_creation.html#challenge-creation-using-zip-configuration
title: test_competition #半角英字でないと後にエラーになります
short_description: test_competition #コンペについての一言記述
description: templates/description.html #overview
evaluation_details: templates/evaluation_details.html #評価をどのように行うかなど
terms_and_conditions: templates/terms_and_conditions.html #利用規約など
image: logo.png #コンペのサムネイルとなる画像です。
submission_guidelines: templates/submission_guidelines.html #どういうファイル形式でsubmitしてほしいか、など
evaluation_script: evaluation_script.zip #評価スクリプト(後述)
remote_evaluation: False #AWSなどでEvaluateするかどうか。Falseでよいとおもいます。
start_date: 2019-01-01 00:00:00 #開催日時
end_date: 2099-05-31 23:59:59 #終了日時
published: True #コンペを公開状態にするかどうか。これをTrueにしておかないと他の人から見えません。
leaderboard: #評価したい指標が一度に計算できない場合や、2-stage制にしたいときなどに複数のリーダボードを設定できます
- id: 1
schema: { "labels": ["AUC"], "default_order_by": "AUC" }
- id: 2
schema: { "labels": ["F1@10", "MAP@10"], "default_order_by": "MAP@10" }
challenge_phases: #上で設定したリーダーボードidと、ここのidは合わせておきます
- id: 1
name: AUC
description: templates/challenge_test_description.html
leaderboard_public: True #Trueにする
is_public: True #Trueにする
start_date: 2019-01-19 00:00:00
end_date: 2099-04-25 23:59:59
test_annotation_file: annotations/auc_test.csv #正解データ
codename: auc #このフェーズの名前
max_submissions_per_day: 100 #一日に何回投稿できるようにするか
max_submissions_per_month: 5000 #一ヶ月に何回投稿できるようにするか
max_submissions: 50000 #最大何回投稿できるか
- id: 2
name: MAP_etc
description: templates/challenge_test_description.html
leaderboard_public: True #Trueにする
is_public: True #Trueにする
start_date: 2019-01-19 00:00:00
end_date: 2099-04-25 23:59:59
test_annotation_file: annotations/map_etc_true.json #正解データ
codename: map_etc #このフェーズの名前
max_submissions_per_day: 100 #一日に何回投稿できるようにするか
max_submissions_per_month: 5000 #一ヶ月に何回投稿できるようにするか
max_submissions: 50000 #最大何回投稿できるか
dataset_splits:
- id: 1 #上で設定したidと合わせる
name: AUC #上で設定したnameと合わせる
codename: auc #上で設定したcodenameと合わせる
- id: 2
name: MAP_etc
codename: map_etc
challenge_phase_splits: #visibility以外はidを合わせる。visibilityは3にしておく。
- challenge_phase_id: 1
leaderboard_id: 1
dataset_split_id: 1
visibility: 3
- challenge_phase_id: 2
leaderboard_id: 2
dataset_split_id: 2
visibility: 3
2. 正解データと評価用スクリプト作成
正解データは、各自で思い浮かべる形式で作成ください。後ほどpythonで実行してAUCなどを計算できるようになっていればどんな形式でも大丈夫です。バイナリ形式は使えないので、 pickle で固めたものなどが使えないことにご注意ください。
evaluation_script/main.py を編集します。 main.py ではデフォルトで引数としてユーザがsubmitしたファイルのパス、自分が正解データに設定したデータへのパスが得られますので、それを使って指標を計算します。以下は、チュートリアルリポジトリのものをそのまま貼っています。
import random
def evaluate(test_annotation_file, user_submission_file, phase_codename, **kwargs):
"""
Evaluates the submission for a particular challenge phase adn returns score
Arguments:
`test_annotations_file`: Path to test_annotation_file on the server
`user_submission_file`: Path to file submitted by the user
`phase_codename`: Phase to which submission is made
`**kwargs`: keyword arguments that contains additional submission
metadata that challenge hosts can use to send slack notification.
You can access the submission metadata
with kwargs['submission_metadata']
Example: A sample submission metadata can be accessed like this:
>>> print(kwargs['submission_metadata'])
{
'status': u'running',
'when_made_public': None,
'participant_team': 5,
'input_file': 'https://abc.xyz/path/to/submission/file.json',
execution_time': u'123',
'publication_url': u'ABC',
'challenge_phase': 1,
'created_by': u'ABC',
'stdout_file': 'https://abc.xyz/path/to/stdout/file.json',
'method_name': u'Test',
'stderr_file': 'https://abc.xyz/path/to/stderr/file.json',
'participant_team_name': u'Test Team',
'project_url': u'http://foo.bar',
'method_description': u'ABC',
'is_public': False,
'submission_result_file': 'https://abc.xyz/path/result/file.json',
'id': 123,
'submitted_at': u'2017-03-20T19:22:03.880652Z'
}
"""
print("Starting Evaluation.....")
print("Submission related metadata:")
print(kwargs['submission_metadata'])
output = {}
if phase_codename == "dev":
print("Evaluating for Dev Phase")
output['result'] = [
{
'train_split': {
'Metric1': random.randint(0, 99),
'Metric2': random.randint(0, 99),
'Metric3': random.randint(0, 99),
'Total': random.randint(0, 99),
}
},
]
print("Completed evaluation for Dev Phase")
elif phase_codename == "test":
print("Evaluating for Test Phase")
output['result'] = [
{
'train_split': {
'Metric1': random.randint(0, 99),
'Metric2': random.randint(0, 99),
'Metric3': random.randint(0, 99),
'Total': random.randint(0, 99),
}
},
{
'test_split': {
'Metric1': random.randint(0, 99),
'Metric2': random.randint(0, 99),
'Metric3': random.randint(0, 99),
'Total': random.randint(0, 99),
}
}
]
print("Completed evaluation for Test Phase")
return output
3. zipに固める
以上ができたら、 ルートに戻って sh run.sh を実行すればzipに固められたものが手に入ります。zipを所定の場所でアップして、エラーがなければ自分がホストしているコンペのところに先程設定したファイルに基づいてコンペが追加されているはずです。
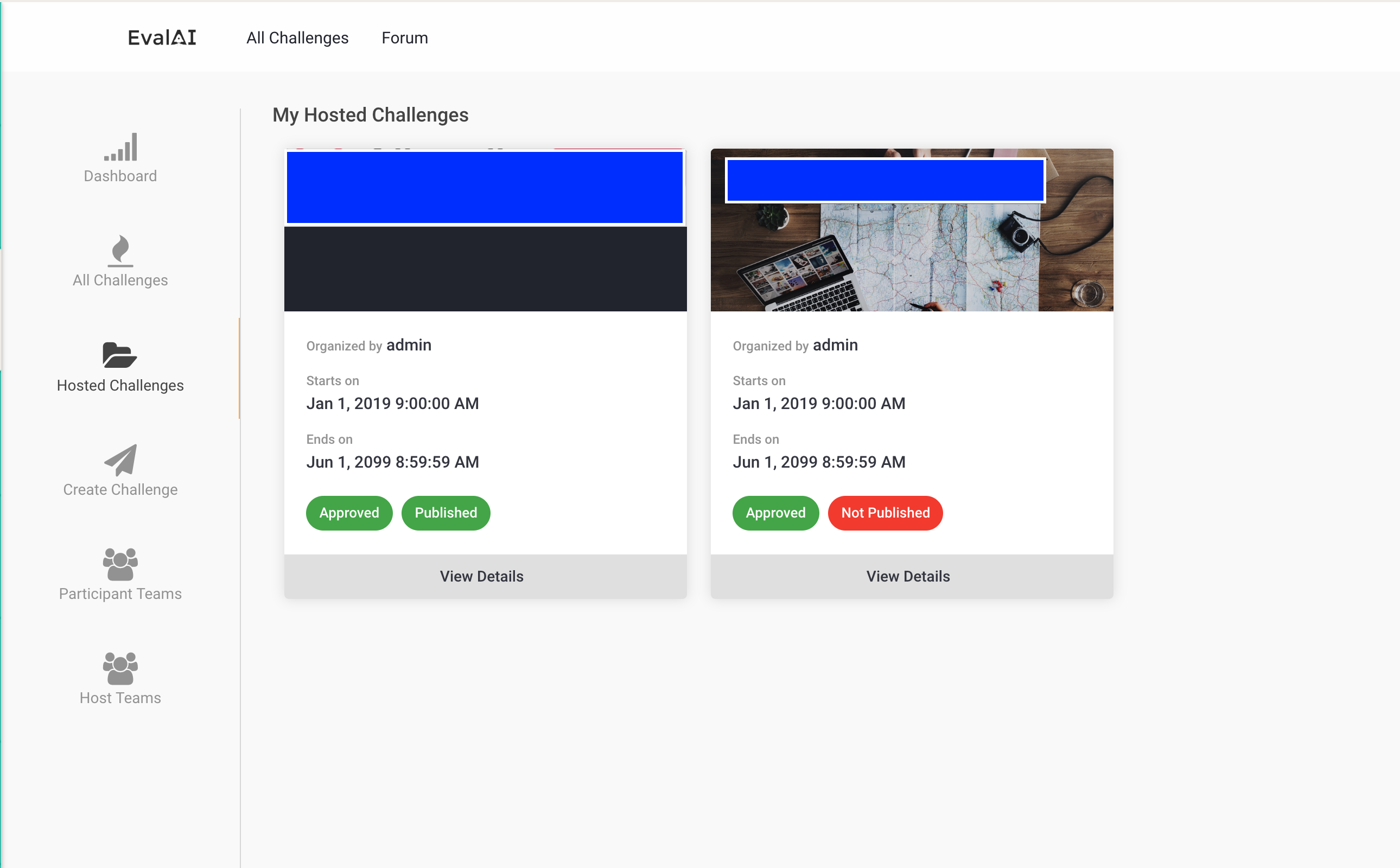
4.管理画面からコンペをapproveし、workerをリスタートする
さて、ここが個人的にハマったところです。自分たちでサーバ自体もホストしているわけなので、管理者側の手順も踏まなければいけません。この手順を踏まないと正しくworkerが動かず評価ができなかったりします。
ではまず、 http://{ホストしている環境のipアドレス}:8000/admin にアクセスして管理画面を開きます。

Django!とはっきりわかる管理画面ですね。ここから Challenge に遷移します。すると、先程アップロードしたコンペがリストにあるのを確認できるはずです。
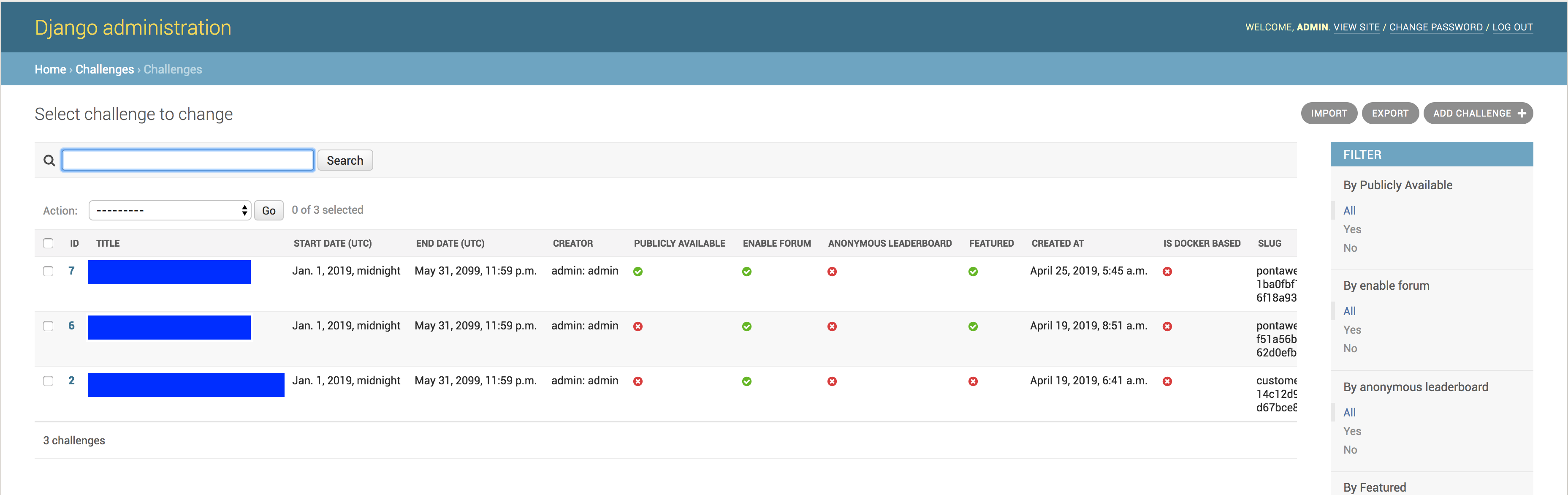
中段あたりにある Approved By Admin にチェックをします。

その後、 docker-compose で立ち上げている環境に再度入ります。workerはapproveされていないコンペティションを認識できないようで、このままだとsubmitしてもworkerがコンペティションを紐付けることが出来ず永遠にevaluateが終わらない状態になってしまうとのことです。Approveされたのを受けて再起動するようにしてくれ...
ということで、以下のコマンドでrestartをかけてやれば準備は完了です。おつかれさまでした!
docker-compose restart worker
予め定めた形式に沿ってsubmitすれば、My Submissionにそれが反映されているはずです。

右にスクロールしたところにある Show on Leaderboard にチェックを入れておけば、それらの中で一番高いスコアがリーダーボードに反映されます。
まとめ
外部にアップできない会社のデータなどでもよいコンペライフを送れるようになってとっても満足です。仕事をはかどらせていきたい。