TL;DR;
・Judgitというサイトで各省庁の事業支出状況が可視化されている
・そのデータを用いて、事業施策・省庁・部局・支出先のグラフを作った
・グラフ埋め込みを行い、事業施策たちをベクトル化した。類似してる事業施策などを検索できるようにした
・使い道をいろいろ考えたい
Judgitについて
7/11にJudgitというサイトが公開されました。複数の団体で運営されているようで、政府が公開している資料をデータベース化して税金の使い道を検索できるようになってます。
【みんなで調べよう!】
— Waseda Chronicle (@WasedaChronicle) July 11, 2019
大勢の人が来れば来るほど、政治や行政が良くなるサイト、税金の無駄遣いが減るサイトができました!
日本の予算をデータベース化しました。税金の使い方を調べてみてください。#ワセクロ #構想日本 #vdslab #Visualizing #税金 #予算 #judgithttps://t.co/2AQaGPeE3S
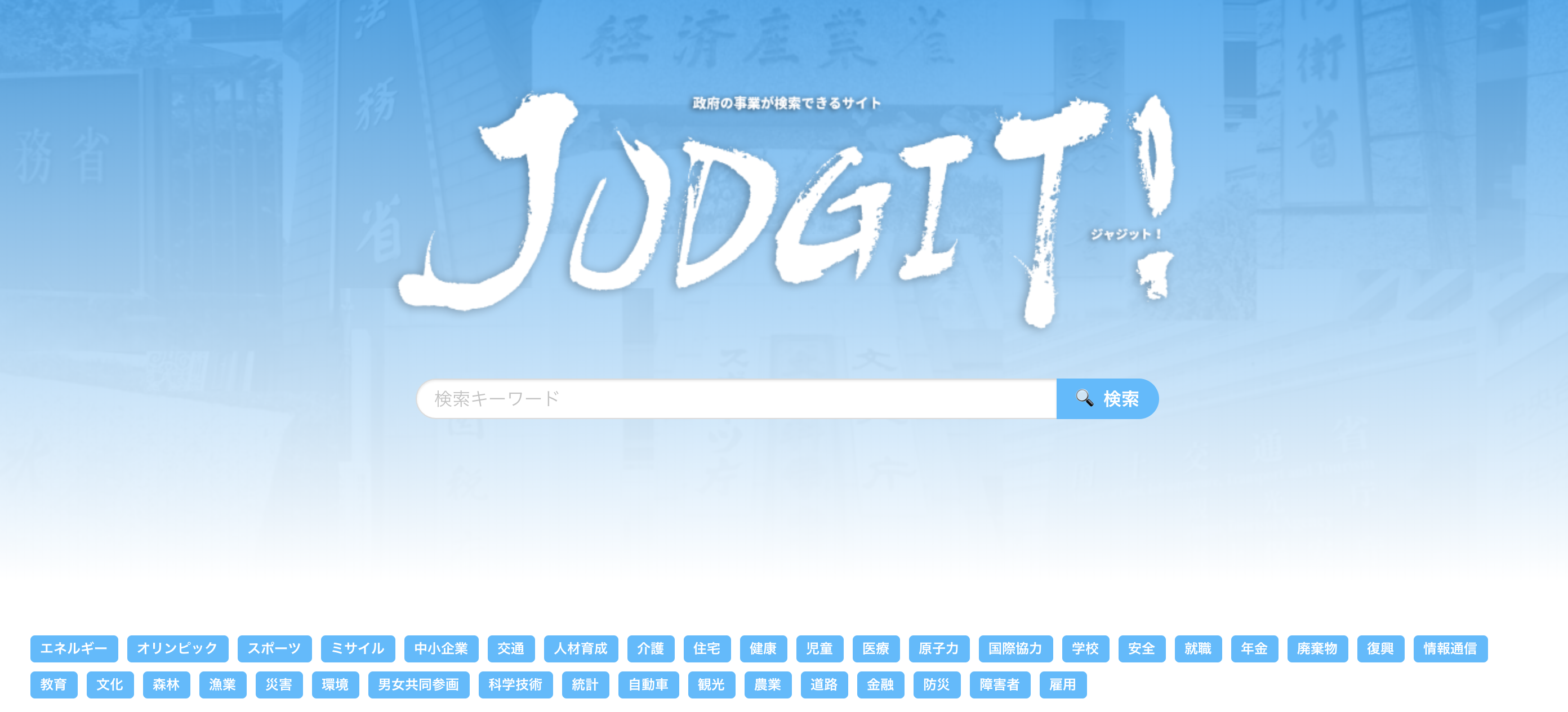
検索するとこんな感じで、事業Aでどれくらいの金をどこに支出したよ、担当省庁・部局はこんなところだよ、というのがわかります。グラフとかもきれいで実際ベンリ

僕自身、政府がこういうデータを公開していることを全然知らず、このサイトでこういうふうにデータ化出来るのすごいなーと思いました。
支出データを使って作ったデモ
で、このデータを使ってなんかやろうって出来たのが以下になります(ちょっと今、不具合により動かせてないです。載せているgif動画で雰囲気だけでもお楽しみください)

なんのデモなのかといいますと、「選択した事業施策・省庁・部局・支出先と似ているものを選び出す」デモとなっております。
例1: パソナ→リクルートキャリアコンサルティング
例2: 内閣サイバーセキュリティセンター→ 各部局のセキュリティ担当部分
例3: 公正取引委員会→ 金融庁
例4: 東京オリンピック・パラリンピック競技大会推進本部経費→緊急事態対処に必要な経費(テロなどに備えるという意味合いで支出の方向性が似ているのかも)
いろいろ見れるので遊んでみてください〜
本記事では、このデモをどのようにして作ったのか、似ていることをどのようにして定義しているのかについて書きます。
省庁の支出状況をグラフで表現する
Judgitのデータを見ていて最初に思いついたのは「グラフにしたらなんか面白いかな」という感想でした。hogeについてはfugaが担当していて、なんたらに100万、ふがふがに50万、というのがネットワークグラフで見えると面白いなーと。
Judigt運営の方もグラフとして分析をされているようです。
JUDGITの生データが活用できると、こういう府省庁の部局と企業等のつながりの関係を可視化できたりします #judgit pic.twitter.com/RZzm54rZPB
— Yosuke Onoue (@_likr) July 11, 2019
なんにせよ、このようにグラフで表現することが出来ると、見る以外にも色々と面白いことが出来るようになります。
・中心性指標を計算することでハブになっている省庁などがわかるようになる
・モジュラリティによるコミュニティ検出、クラスタリングができる
・グラフ埋め込みをすることで、各ノードのベクトルがわかる
で、今回は一番下のグラフ埋め込みをやることにしました。
グラフ埋め込みをすると何が嬉しいのか
グラフ埋め込みをやるとどんな嬉しいことがあるのかといいますと、グラフ上に表現されているノード全てのベクトルがわかります。ベクトルがわかるとなんなの?という方のために雰囲気だけでもお伝えしたいのですが、グラフ埋め込みの論文のイントロでいつも書かれる感じのことをちょっと挙げてみます。
各ノードのベクトルがわかるので、
・ノード同士のコサイン距離がわかる→類似度が図れる
・リンク予測問題が解ける→この省庁は、今後この企業にも支出しそうというのが予測できる
・全般としてグラフ表現を入力の前提としないいろんな手法が使える
という感じでとにかく嬉しいというわけですね〜
Judgitからデータを取得してグラフ埋め込みをしていく
では、実際にやっていきましょう。まず、Judgitからデータをスクレイピングで取得します。利用規約を見る限り、特別に禁止されているわけではなさそうなので問題ないと判断し、sleepを適宜入れて負荷にならないようにやっていきます。※
スクレイピング
# %%
# 必要なパッケージがなければインストール
!pip install pandas requests tqdm beautifulsoup4 selenium -U
# %%
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
import json
from tqdm import tqdm_notebook
import time
# %%
# seleniumとbeautifulSoup4でデータを取得する
def get_element_from_judgit(page_number):
result = {}
driver.get(f"https://judgit.net/projects/{page_number}")
try:
# 最初にjsのローディング画面が入るので最大15秒待つ
WebDriverWait(driver, 15).until(EC.presence_of_element_located((By.CLASS_NAME, 'table')))
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "html.parser")
# init
result['タイトル'] = soup.find_all("h3", attrs={"class", "title"})[0].string
result['タグ'] = [v.string for v in soup.find_all("a", attrs={"class",
"tag is-info"})]
result['担当省庁'] = {}
result['担当部局'] = {}
result['事業期間'] = {}
result['会計区分'] = {}
result['実施方法'] = {}
result['事業の目的'] = {}
result['事業概要'] = {}
result['成果目標及び成果実績(アウトカム)_基準'] = {}
result['活動指標及び活動実績(アウトプット)_基準'] = {}
# get table elements
table_elements = pd.read_html(html)
result['予算額・執行額'] = table_elements[0].to_dict()
result['主要な支出先'] = table_elements[-1].to_dict()
# あったりなかったりして取得が難しいので一旦外す
# result['成果目標及び成果実績(アウトカム)'] = table_elements[1].to_dict()
# result['活動指標及び活動実績(アウトプット)'] = table_elements[2].to_dict()
# get each year elements
year_list = [v.text for v in soup.find_all('ul')[2].find_all('li')]
for year in year_list:
driver.find_element_by_link_text(year).click()
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "html.parser")
p_styled_elements = soup.find_all("p", attrs={"style": "margin-bottom: 0.75rem;"})
div_elements = soup.find_all('div')
result['担当省庁'].update({year: p_styled_elements[0].find('a').string})
result['担当部局'].update({year: p_styled_elements[1].text.replace('担当部局:',"")})
result['事業期間'].update({year: p_styled_elements[2].text.replace('事業期間:',"")})
result['会計区分'].update({year: p_styled_elements[3].text.replace('会計区分:',"")})
result['実施方法'].update({year: p_styled_elements[4].text.replace('実施方法:',"")})
result['事業の目的'].update({year: p_styled_elements[5].text})
result['事業概要'].update({year: p_styled_elements[6].text})
result['成果目標及び成果実績(アウトカム)_基準'].update({year: [v.text for v in soup.find_all('div',
attrs={'id':None,'class': None,'style':None})[4].contents[:-1]]})
result['活動指標及び活動実績(アウトプット)_基準'].update({year: [v.text for v in soup.find_all('div',
attrs={'id':None,'class': None,'style':None})[5].contents[:-1]]})
except:
result = 'None'
return result
# %%
result_set = []
for page_number in tqdm_notebook(range(0,8000)):
time.sleep(5)
result_set.append(get_element_from_judgit(page_number))
# %%
with open("../output/judgit_data.json", "w") as f:
json.dump([v for v in result_set if v != "None"], f,ensure_ascii=False, indent=4)
取得したデータの整形
取得して保存したデータを、 networkx が解釈できる形に直していきます。
ちなみに、以下に示すコードでは支出先がかなり表記ゆれがあると書いておりますが、どんな感じで揺れているかというと、
・株式会社で書かれている場合と前株で書かれている場合がある
・職員A・職員B...みたいに個人や職員がひたすらABCD...で列挙されたりしている
・株式会社hoge等、のように共同で支出されている場合におそらく規模の小さい会社などが 等 でまとめられてしまっている(株式会社hogeを取ってきたいので、 等 が出てきたら削除する)
のような感じです。政府の公開している資料での書き方がそもそも正規化されていないんですよね。しょうがないです。
ちなみに、この記事を書いている途中で「株式会社と前株、名寄せするの忘れた」ってなりました。ぐぬぬ...
# %%
import json
import pandas as pd
import networkx as nx
import neologdn
# %%
with open("../output/judgit_data.json", "r") as f:
result_set = json.load(f)
# %%
# 支出先については、かなり表現にブレがあるのでできるだけ正規化する
def money_out_normalize(money_out):
# 個人・職員は支出先解析のスコープ外とする
if '個人' in money_out:
return None
elif '職員' in money_out:
return None
# 支出先は基本的に正規化する
money_out = neologdn.normalize(money_out)
# テキストの最後に"等"がある場合はそれを削除する
if money_out[-1] == '等':
money_out = money_out[:-1]
if money_out in concat_texts:
return [money_out]
else:
# "、"がある場合、それをsplitして返す
return money_out.split("、")
# %%
# add data
for result in tqdm_notebook(result_set):
money_use_df = pd.DataFrame.from_dict(result['主要な支出先'])
for year_key in list(result['担当省庁'].keys()):
money_use_dict = money_use_df.query('年度==@year_key').reset_index().to_dict(orient='index')
for money_use_dict_key in list(money_use_dict.keys()):
money_out_array = money_out_normalize(money_use_dict[money_use_dict_key]['支出先'])
if money_out_array is not None:
for money_out in money_out_array:
df_dict['title'].append(result['タイトル'])
df_dict['year'].append(year_key)
df_dict['minister'].append(result['担当省庁'][year_key])
df_dict['group'].append(result['担当部局'][year_key])
df_dict['money_purpose'].append(money_use_dict[money_use_dict_key]['業務概要'])
df_dict['money_out'].append(money_out)
money_num = money_use_dict[money_use_dict_key]['支出額(百万円)']
if money_num == 0:
# 単位が百万円のため0が存在するが、後にリンクの重みとして使う際に0では都合が悪いため
df_dict['money_num'].append(0.5)
else:
df_dict['money_num'].append(money_num)
ここまでやると、以下のようなデータフレームが手に入ります。やったね。
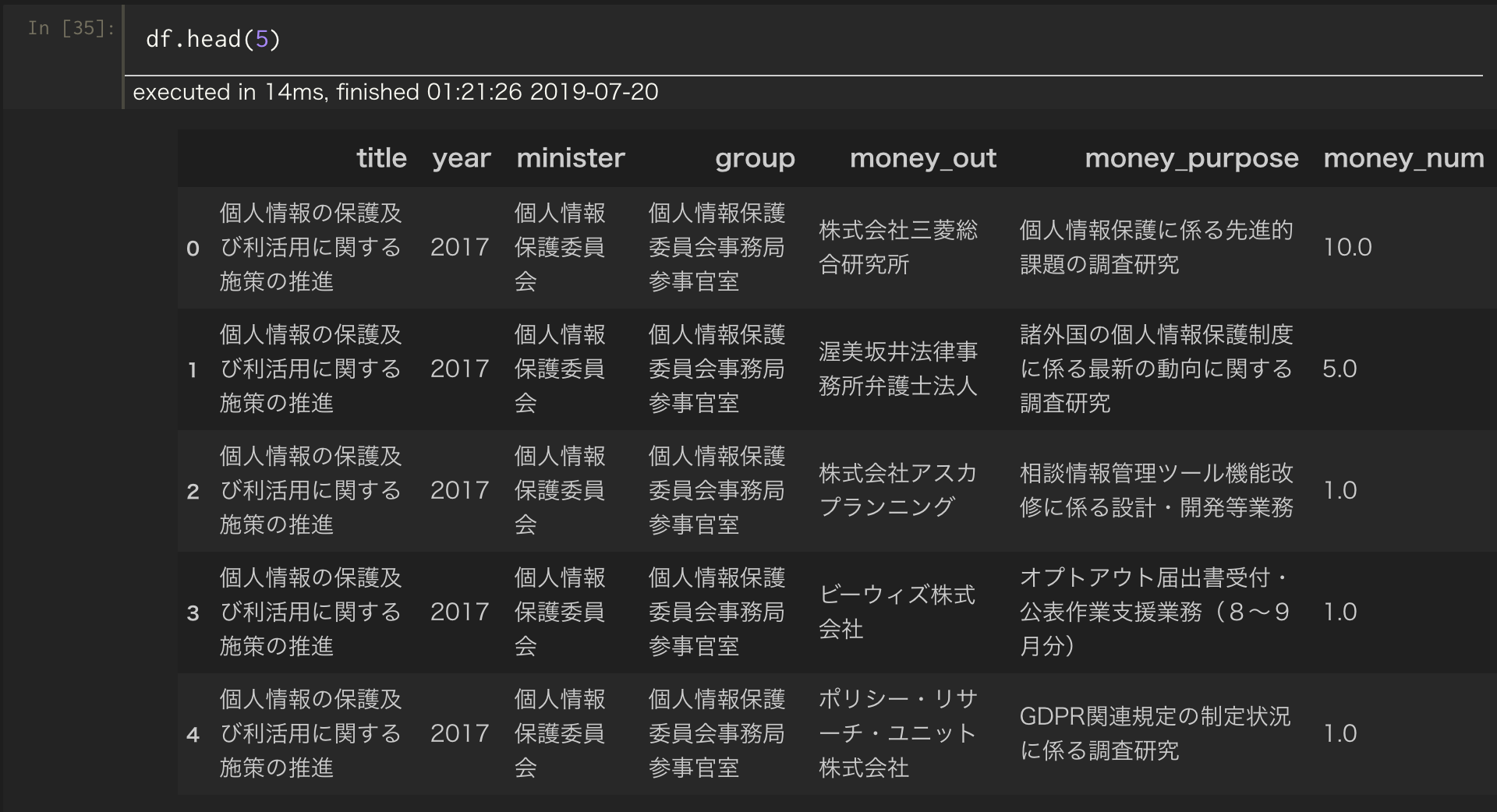
networkxはデータフレームから直接グラフを作ってくれるので、あとはこれを読み込んでいきます。
# %%
# ノードの属性を付与したいので辞書として持っておく
node_attr_dict = {}
for m in df['minister'].unique():
node_attr_dict[m] = ['minister']
for g in df['group'].unique():
# 複数属性がつくこともあるので、既にキーが有る場合はその配列に属性を追加する
if g in node_attr_dict:
node_attr_dict[g].append('group')
else:
node_attr_dict[g] = ['group']
for mo in df['money_out'].unique():
if mo in node_attr_dict:
node_attr_dict[mo].append('money_out')
else:
node_attr_dict[mo] = ['money_out']
for t in df['title'].unique():
if t in node_attr_dict:
node_attr_dict[t].append('title')
else:
node_attr_dict[t] = ['title']
# %%
df['temp_weight'] = 1
graph_set = {}
# 支出の年度ごとにグラフを作る
for y in ['2015','2016','2017']:
df_ = df.query("year<=@y")
G1 = nx.from_pandas_edgelist(df_, 'group', 'money_out', ['money_num'])
G2 = nx.from_pandas_edgelist(df_[['minister','group','temp_weight']].drop_duplicates(),
'minister', 'group', ['temp_weight'])
G3 = nx.from_pandas_edgelist(df_[['title','minister','temp_weight']].drop_duplicates(),
'title', 'minister', ['temp_weight'])
# combine
combined_graph = nx.compose(G1,G2)
combined_graph = nx.compose(combined_graph,G3)
# set node attribute
nx.set_node_attributes(combined_graph, values=node_attr_dict, name='category')
graph_set[y] = combined_graph
# %%
import cloudpickle
cloudpickle.dump(graph_set, open("../output/judgit_graph_set.pkl","wb"))
cloudpickle.dump(node_attr_dict, open("../output/node_attr_dict.pkl","wb"))
寄り道: 固有ベクトル中心性から見る、各年度での中心的な施策の推移
ここまでやるとグラフが手に入ります。 networkx形式になっているので、中心性の計算などはこの時点ですでに簡単にできちゃいます。例えば以下のような感じで、施策ノードの中で固有ベクトル中心性が高いノード上位10が計算できます。
title_list = df['title'].unique()
eigen_centers = nx.eigenvector_centrality_numpy(graph_set['2015'])
sort_eigen = sorted(eigen_centers.items(), key=lambda x: x[1], reverse=True)
[(k,v) for (k,v) in sort_eigen if k in title_list][:10]
2015年度
[('国民健康保険団体連合会等補助金', 0.0027399507838927373),
('輸入食品の監視体制強化等事業', 0.0027399507838927373),
('生活衛生関係営業対策費補助金', 0.002739950783892737),
('臨床効果データベース整備事業', 0.0022355803162143026),
('外国人受入医療機関認証制度等推進事業', 0.0022355803162143017),
('外国人看護師候補者就労研修支援事業', 0.0022355803162143017),
('精神障害者措置入院等', 0.0022355803162143017),
('ES細胞・iPS細胞臨床研究指針対策費', 0.0022355803162143017),
('名誉回復事業', 0.0022355803162143013),
('地域保健従事者現任教育推進事業', 0.0022355803162143013)]
2016年度
[('輸入食品の監視体制強化等事業', 0.003051131419890442),
('生活衛生関係営業対策費補助金', 0.0030511314198904413),
('国民健康保険団体連合会等補助金', 0.00305113141989044),
('保健医療福祉分野の公開鍵基盤(HPKI)普及・啓発事業', 0.002756220887928504),
('ホームレス等に対する就労支援事業', 0.0027562208879285035),
('医療研究開発推進事業費補助金(ジャパン・キャンサーリサーチ・プロジェクト)', 0.0027562208879285035),
('医療研究開発推進事業費補助金(新興・再興感染症制御プロジェクト)', 0.0027562208879285035),
('医薬品研究開発動向等調査費', 0.0027562208879285035),
('子育て世帯臨時特例給付金給付事業に必要な経費', 0.0027562208879285035),
('生涯現役促進地域連携事業', 0.0027562208879285035)]
2017年度
[('生活衛生関係営業対策費補助金', 0.0026349361825696196),
('国民健康保険団体連合会等補助金', 0.0026349361825696175),
('輸入食品の監視体制強化等事業', 0.0026349361825696175),
('アルコール健康障害対策理解促進経費', 0.002618744131672778),
('中国残留邦人等永住帰国者に対する就労支援事業', 0.0024275640956570375),
('女性の活躍推進及び両立支援に関する総合的情報提供事業', 0.0024275640956570375),
('戦略産業雇用創造プロジェクト', 0.0024275640956570375),
('教育訓練講座受講環境整備事務費', 0.0024275640956570375),
('看護師等学校養成所報告管理運用事業', 0.0024275640956570375),
('社会復帰特別対策援護経費', 0.0024275640956570375)]
常に国民健康保険関係の補助金が上位に来ている他、17年度には女性の社会活躍に関する事業が上位に来ていたり、これを見るだけでも各年度での傾向がわかりそうですね。
node2vecによるグラフ埋め込み
では、得られたグラフを埋め込んでいきます。今回はnetworkxを入力としてそのまま動いてくれる実装が公開されているnode2vecを使って埋め込んでいきます。node2vecについてはこちらの原論文をどうぞ→ node2vec: Scalable Feature Learning for Networks
import click
from node2vec import Node2Vec
import cloudpickle
import logging
import os.path
import sys
logger = logging.getLogger()
logging.basicConfig(format="%(asctime)s : %(levelname)s : %(message)s")
logging.root.setLevel(level=logging.INFO)
@click.command()
@click.option("--input_year")
@click.option("--output_dir")
def main(input_year, output_dir):
# prepare data
judgit_graph_set = cloudpickle.load(
open("output/judgit_graph_set.pkl", "rb"))
target_graph = judgit_graph_set[input_year]
# run node2vec
node2vec = Node2Vec(target_graph, dimensions=64,
walk_length=30, num_walks=200, workers=8)
model = node2vec.fit(window=10, min_count=1, batch_words=4, workers=8)
model.save(f"{output_dir}/{input_year}_node2vec.model")
pass
if __name__ == "__main__":
# pylint: disable=no-value-for-parameter
main()
ここまではノートブックで作業してましたが、計算量が多くて待たなきゃいけない処理は自分はいつもスクリプトに落とす癖があり、ちゃんとスクリプトにして、年度をclickで指定して動くようにし、GCPのインスタンス上で動かしました。
得られたnode2vecオブジェクトは、実体はgensim.models.Word2Vecなので、簡単に読み込めます。
このオブジェクトを使うことで、類似するノードの検索ができます!
def search_nearest_given_list(search_word, target_list, target_vector, topn):
result = []
score_list = []
word_list = []
# 与えられたリストのエンティティらに対して類似度を計算する
for target in target_list:
try:
score = target_vector.wv.similarity(search_word, target)
score_list.append(score)
word_list.append(target)
except:
continue
# sort
sorted_index = np.argsort(-np.array(score_list))
for i in sorted_index:
if word_list[i] != search_word and len(result) < topn:
result.append({word_list[i]: float(score_list[i])})
else:
continue
return result
今回は事業施策の中での類似度、省庁の中での類似度などが知りたいのでただ単にmost_similarで類似度上位Nを持って来るだけだとうまく取得ができません。そこで↑のような感じで、例えば事業施策のリストを用意してそれらに対する類似度を計算し、上位Nを持ってくるなどがやり方として考えられます。あとは
GitHub - yagays/minify_w2v: Minify word2vec model file などを利用して、対象エンティティのみでKeyedVectorを構成し直して most_similar一発で検索できるようにするか、色々やりようはあると思います。
検索できるデモサイトを作ろう: 技術構成の紹介
ここまでやれば当初の目的であるグラフ埋め込み自体は達成できますが、せっかくなのでデモサイトも作ろう!ということで勢い余って作ったのが冒頭のものになります。
技術構成については細かい内容を書くとキリがないので全体観だけ以下に示します。
- フロントは
Reactと緩めのTypeScript- コンポーネントのベースは
reactstrapを利用。Bootstrapを何時まで経っても卒業できない。 -
react-reduxでストア管理、redux-sagaでバックエンドにリクエスト。 -
react-selectで検索インターフェースを提供。 - 検索結果表出時のアニメーションは
react-reveal - 個人的につまずいたのは、
react-relectに渡している表示用のリストが多いもので40000件くらいだったので、最初の雑実装(今もかなり雑ですが)のときはいちいちカクついてしまってた。react-virtualizedで解決。
- コンポーネントのベースは
- バックエンドは
flask- 必要な要件に沿ってエンドポイントを実装していっただけ。
- 動かしている場所は
Herokuで無料プラン-
NewRelicで定期的に叩いてスリープを避けている。
-
大体、思いついてから一週間ちょっとくらいの土日と平日夜を捧げて召喚しました。
やろうとしてできなかったこと
今回やりきれなかったことについて
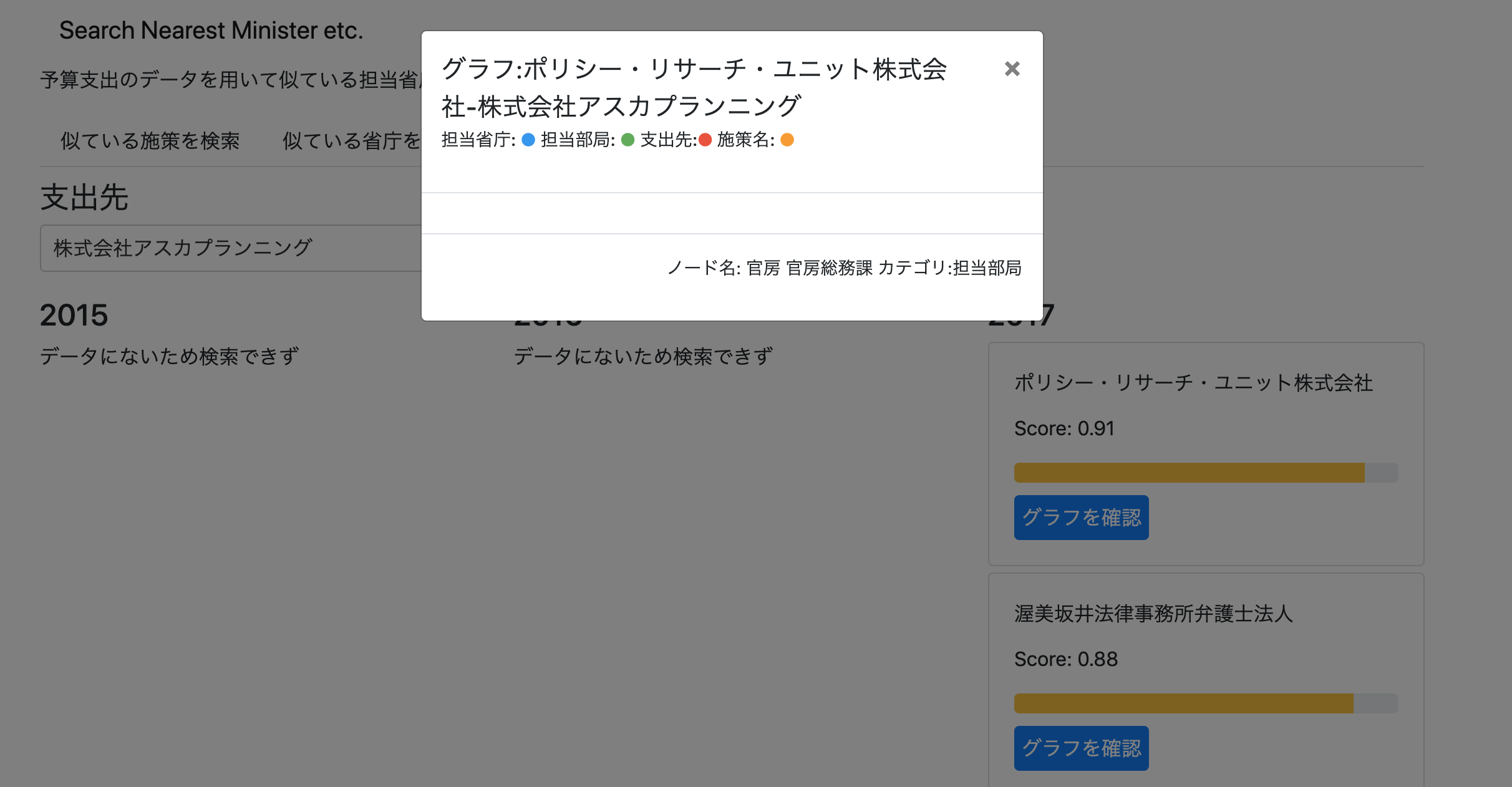
グラフを表示できるように一瞬したけど前処理が出来てなさすぎてやめた

適当に押したやつが文字文字してるグラフですみません
こんな風に、グラフを表示するインタフェースを作っていたんですがやめました ![]()
理由は、別の場所でも述べましたが、そもそもの政府が公開しているデータに生じている表記揺れに対しての前処理をやりきれておらず、グラフを表示しようとしてエラーになることが多すぎたからです、かなしい
Judgitの方々もおそらく膨大な時間を前処理に使われているのではないかと思われます。本当にしんどかっただろうなと。。。その恩恵を受けてこうしてデータを使えているので感謝感謝ですね。
支出金額を反映した埋め込み
これはただ単にやり忘れただけなんですが、グラフの重みに支出金額を使っていませんでした。
node2vecの計算が結構長く、しかもメモリもそれなりに使うので(100Gメモリくらいのインスタンスじゃないと途中でメモリエラーで死んだ)、kaggleでもないのにそんなにお金使うのもなってことで一回回したきり回せてないです。
上の前処理やら名寄せの件と合わせてFuture Workということでどうか...
Special Thanks
重ね重ね、データをこうしてデータベース化して使える段階まで整えられたJudgit運営団体の方には頭が上がりません。ありがとうございました。