みなさんこんにちは。 @fufufukakaka です。
この記事は 情報検索・検索技術 Advent Calendar 2021 の 12/17 の記事です。数日遅れていますが...
本記事では推薦技術に焦点を当てます。具体的には、今年僕が声を大にして紹介したい RecBole を使った話を書きます。
RecBole とは?
実は会社のブログでも同じような記事を書いたので、この説明部分はそこからそっくりそのまま引用します。
RecBole は中国人民大学・北京大学の研究室が共同で始めたプロジェクトのようで、去年の11月に arxiv に登場しました。今年の8月に提供しているモジュールがv1を迎えて、本格的に色々な人が利用するようになったようです。
RecBole 最大の魅力は、上述してきた再現性の難しいレコメンドモデルを統一したインタフェースで実装し、比較を容易にしているところにあります。そして実装されているモデル、適用できるデータセットの数が凄まじいです。モデルは現時点で70以上(モデルリストがすごい )、データセットは20以上のものについて即座に試せます。どれくらい即座に試せるかと言うと
pip install recbole
python run_recbole.py --model=<your favorite model> --dataset_name ml-100k
これだけで、レコメンド界隈の中で最も有名なベンチマークである MovieLens-100k データセットに対して70以上のモデルを即座に(追加の設定が必要なやつもありますが)試せます。これだけのモデル・データを試すことができる環境はそうないと思われます。また70以上の収録されているモデルたちは全て PyTorch ベースで丁寧に再実装が行われており信頼性は非常に高いです。predict関数などの基本的なインタフェースは統一されており、実験のし易い環境が整えられています。
はい、ということで異常な数(70以上)のレコメンドモデルを、異常な数(20程度)のデータセットに対して即座に試せるエコシステムを整えてくれている OSS です。RecBole の論文内ではその他似たような立ち位置のプロダクトとの比較も行われているのですが、
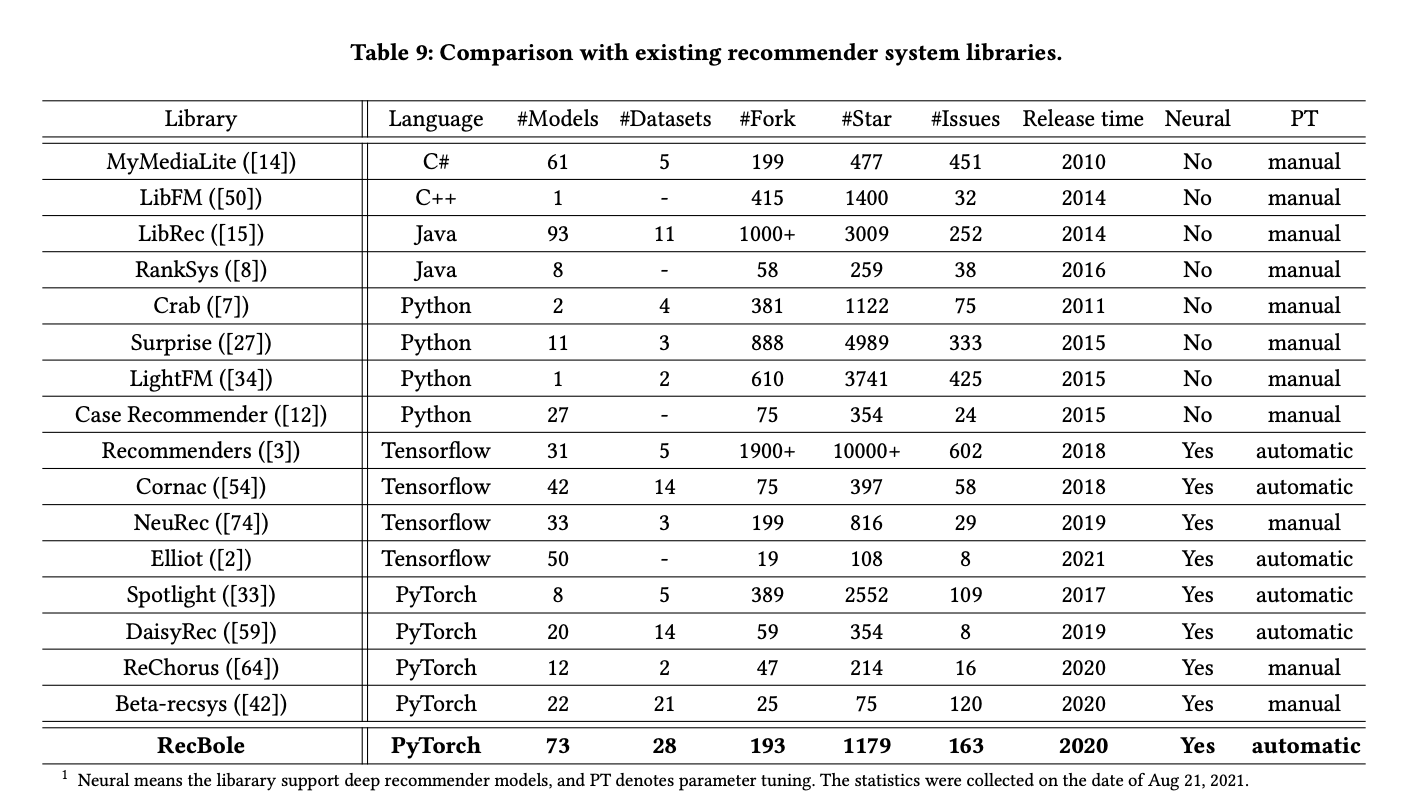
モデル数やデータセット数では圧倒的だぞ、と言っているわけですね。ForkとかStar・Issueの数で比較しているのはちょっと意図がよくわかんないですが...
「この推薦タスクでどのモデルを使えばいいのか全然わかりません」
推薦タスクに取り組まれている皆様はよく経験があるのではないか、と思うのですが
- 推薦タスクは State of the Art をよく見かける
- なおベンチマークのデータが MovieLens 100K やってなくて比較に困る
- 公開されているモデル実装を使おうとしてもMovieLens みたいに Rating があるデータ (Explicit Feedback) じゃなくて、購入したかどうか (Implicit Feedback)のデータしか無い
- Train, valid, test を分割する仕方がわからないから、オフラインテストをせずにエイヤ!でモデルを作ってオンライン評価にいきなり出す
- モデル A をなんとか実装して良い成績が得られはしたけど、実はモデル B のほうが良いのでは?などといわれ、でもモデル B まで再現実装する(自社データに合わせた実装への変更など)時間がない。オフライン評価もやってないから意思決定のしようがない
- そもそも自社のデータはでかすぎて学習が回せない!
- 自社のサービスαではモデルAが良かったので、そのままサービスβにも適用してみたらなんか成績があんまり良くない気がする(モデルCを使わないと良い成績が得られなかったパターン)
と、様々な苦難を経験されてきたのではないか、と思います。「推薦タスク、どのモデルを使えばいいのかわかんないよ」と僕も同じようにいつも思っていました。
推薦タスク自体は好きなのですが、自分の持っている手札と言えば gensim を転がしてすぐできる Item2Vec か、MatrixFactorization くらいしかなかったので知見が全然広がらなかったんですね。VAE 系が強いぞ、とかグラフ系もあるぞ、とか Transformers で推薦できるぞ、とか情報は拾っていた気がするのですがそれをいつでも振り回せるようになるには理解して実装する時間(余裕)を作れなかった... と言い訳してきたんですね。
しかし、RecBole を使えばモデルに関する理解さえあれば、実装は RecBole に任せて取り敢えずすぐ試すことができます。自分たちのデータに合わせて RecBole を動かすこともかなり簡単です。詳細は手前味噌ですがまたこちらのブログを見ていただいて...
こうして RecBole を使うことで「この推薦タスクでどのモデルを使えばいいのか全然わかりません」に関しては(ある程度の計算コストを払うことで)わかるようになりました。よかったよかった。
しかし、ここまで来ると疑問も次のステージに上がります。
「なんで推薦タスクはデータによってどのモデルが強いのか、がこんなにも変わるんですか?」
RecBole で様々なモデルを様々なデータに試すことができるようになってくると、データによって強いモデル・弱いモデルの分布が全く異なってくることに気づきます。
「機械学習はタスクによって強いモデルが異なる」というのは皆様一度はお聞きしたことがあると思います。具体例として適切かどうか微妙ですが書き連ねてみると、画像を相手にするならCNNが大体において強く(最近は Vision in Transformer のせいで "大体" の精度もかなり落ちていますが、CNN的な構造が有効だったことは認められるんじゃないかな)、言語データを相手にする場合は sequential な構造を意識したニューラルネットワークが強く、ただテーブルデータを相手にするときはニューラルネットワークよりも勾配ブースティング木の方が強い。のような感じです。
タスクごとに強いモデルは違う、というのはよくわかります。しかし、データが異なると一気に上位モデルの顔ぶれが変わる、というのはちょっとよくわからない...
本記事では実際に上位モデルの顔ぶれが変わる、がどういうことなのかを具体的なデータを通じて確認してみました。今回は2つのデータセットでの実験結果を紹介します。
Case1. MovieLens 1M
まずはこちら、MovieLens です。いわずとしれたデータセットで、ユーザの方々が映画に対して評点を付けたものです。今回は 1M = 100万レコードの評点履歴データを使います。
これは RecBole 上では何ら特別な手続きをせずに使うことができます。
from recbole.quick_start import run_recbole
run_recbole(model={model_name}, dataset="movielens-1m")
これで MovieLens のデータを勝手にダウンロードしてくれます。すごいぞ。
ただ、これだけだと色々追加したい設定が反映されないので、次のような yml を用意します。
# general
gpu_id: 0
use_gpu: True
seed: 2020
state: INFO
reproducibility: True
data_path: 'dataset/'
checkpoint_dir: 'saved/movielens-1m'
show_progress: True
save_dataset: False
save_dataloaders: False
# Atomic File Format
field_separator: "\t"
seq_separator: "@"
# Common Features
USER_ID_FIELD: user_id
ITEM_ID_FIELD: item_id
RATING_FIELD: rating
TIME_FIELD: timestamp
seq_len: ~
# Label for Point-wise DataLoader
LABEL_FIELD: label
# NegSample Prefix for Pair-wise DataLoader
NEG_PREFIX: neg_
# Sequential Model Needed
ITEM_LIST_LENGTH_FIELD: item_length
LIST_SUFFIX: _list
MAX_ITEM_LIST_LENGTH: 50
POSITION_FIELD: position_id
# Knowledge-based Model Needed
HEAD_ENTITY_ID_FIELD: head_id
TAIL_ENTITY_ID_FIELD: tail_id
RELATION_ID_FIELD: relation_id
ENTITY_ID_FIELD: entity_id
# Selectively Loading
load_col:
inter: [user_id, item_id, timestamp, rating]
user: [user_id, age, gender, occupation, zip_code]
item: [item_id, movie_title, release_year, genre]
unused_col:
inter: [timestamp, rating]
# Filtering
rm_dup_inter: ~
val_interval: ~
filter_inter_by_user_or_item: True
user_inter_num_interval: "[1,inf]"
item_inter_num_interval: "[1,inf]"
# Preprocessing
alias_of_user_id: ~
alias_of_item_id: ~
alias_of_entity_id: ~
alias_of_relation_id: ~
preload_weight: ~
normalize_field: ~
normalize_all: True
# Training and evaluation config
epochs: 50
stopping_step: 10
train_batch_size: 4096
eval_batch_size: 4096
neg_sampling:
uniform: 1
eval_args:
group_by: user
order: TO
split: {'RS': [0.8,0.1,0.1]}
mode: full
metrics: ['Recall', 'MRR', 'NDCG', 'Hit', 'Precision']
topk: 10
valid_metric: MRR@10
metric_decimal_place: 4
これを config/movielens-1m.ymlなどとして保存しまして
run_recbole(model={model_name}, dataset="movielens-1m", config_file_list=["config/movielens-1m.yml"])
と実行します。
yaml の解説↓
-
seq_separatorを設定しないと空白で分割される。モデルの学習上はこれで良いと思うんですが、あとで topk の分析をするときにアイテム名を正しく引けなくなってしまうので、絶対に分割されなさそうな文字を適当に入れています(でも、アイテム名を引くときに別のやり方で回避すればいいだけなので、ここはこのやり方が正しいわけではない気がします) -
ITEM_ID_FIELDは特に注意が必要で、データごとにアイテムidのカラム名が異なるので毎回ここは見て上げる必要があります -
MAX_ITEM_LIST_LENGTHやuser_inter_num_interval・item_inter_num_intervalはいずれもデータをカットする設定です。データ数が多すぎてモデルが回せないときはこの辺りを設定して緩めて下さい(緩めてもどうしようもないときもある) - (一番重要)
eval_argsのorderをTO、group_byをuserにします!!!これをすることで、ユーザごとにアイテムを groupby して、それを timeseries に並べる処理が入ります。そのあとにsplitの設定が効いて、今回は 80%:10%:10% に train:valid:test を作ってくれます。これが一番現実に即したデータ分割だと思います。
今回はこの実験設定で、36モデルを実験しました。RecBole のカテゴリでいうと、GeneralとContext-Aware(FactorizationMachine)系をやっています。Sequential系のモデルをやっていないのは後述する topk 出力の際にエラーが出るバグがあるから、knowledge-base系のモデルについては knowledge-base を用意する手間を現実の問題で考えると結構大変そうだな、と思って最初から外しているからです。また、各モデルはデフォルトのパラメータのままテストしています。全部チューニングする時間はなかった...
さて、RecBole ではデータの基礎統計を表示してくれるのでそれをまず確認しておきましょう。
The number of users: 6041
Average actions of users: 165.5975165562914
The number of items: 3707
Average actions of items: 269.88909875876953
The number of inters: 1000209
The sparsity of the dataset: 95.53358229599758%
ユーザとアイテム数はそこまででもないデータです。また、1ユーザのアクションした平均アイテム数が165、1つのアイテムにアクションしたユーザ数平均は269、とそれなりに dense でレコメンドで扱うデータとしては非常に扱いやすいデータであることがわかります。
ではでは36モデルの実験結果を見ていきましょう。結果は以下のようになりました。NDCG@10 で降順ソートしています。
| Name | recall@10 | precision@10 | ndcg@10 | mrr@10 | hit@10 |
|---|---|---|---|---|---|
| NGCF | 0.0581 | 0.0647 | 0.0813 | 0.1616 | 0.3745 |
| LightGCN | 0.0578 | 0.0644 | 0.081 | 0.1594 | 0.3671 |
| DGCF | 0.0587 | 0.0633 | 0.0802 | 0.1585 | 0.3608 |
| SLIMElastic | 0.0631 | 0.0612 | 0.0801 | 0.1546 | 0.3664 |
| BPR | 0.0572 | 0.0638 | 0.0798 | 0.1566 | 0.3618 |
| AutoInt | 0.0552 | 0.0635 | 0.0797 | 0.1588 | 0.3591 |
| GCMC | 0.0567 | 0.0631 | 0.0793 | 0.1571 | 0.3596 |
| AFM | 0.0535 | 0.0637 | 0.0789 | 0.1592 | 0.3652 |
| NNCF | 0.0554 | 0.0626 | 0.0788 | 0.1583 | 0.3609 |
| NAIS | 0.0592 | 0.0608 | 0.0782 | 0.1528 | 0.3589 |
| EASE | 0.0658 | 0.0583 | 0.0779 | 0.1473 | 0.3598 |
| DeepFM | 0.054 | 0.0621 | 0.0779 | 0.1579 | 0.3566 |
| DCN | 0.0548 | 0.0618 | 0.0775 | 0.1538 | 0.3505 |
| WideDeep | 0.0534 | 0.062 | 0.0774 | 0.1564 | 0.356 |
| Item2Vec | 0.0591 | 0.0609 | 0.0773 | 0.1477 | 0.3598 |
| FM | 0.0553 | 0.0611 | 0.0773 | 0.1557 | 0.3611 |
| SpectralCF | 0.0527 | 0.0608 | 0.0768 | 0.1575 | 0.3531 |
| RecVAE | 0.0563 | 0.0602 | 0.0765 | 0.1499 | 0.347 |
| NeuMF | 0.055 | 0.0606 | 0.0763 | 0.152 | 0.3543 |
| FFM | 0.0551 | 0.0612 | 0.076 | 0.1507 | 0.3614 |
| xDeepFM | 0.0532 | 0.0599 | 0.0754 | 0.1545 | 0.3551 |
| NFM | 0.0515 | 0.0605 | 0.075 | 0.153 | 0.3543 |
| DMF | 0.0575 | 0.0582 | 0.0748 | 0.1455 | 0.345 |
| PNN | 0.0524 | 0.06 | 0.0745 | 0.1509 | 0.3518 |
| ItemKNN | 0.0558 | 0.0549 | 0.0716 | 0.1376 | 0.3243 |
| FNN | 0.0476 | 0.058 | 0.0711 | 0.1434 | 0.3296 |
| MultiDAE | 0.0513 | 0.0566 | 0.0707 | 0.1403 | 0.3336 |
| MacridVAE | 0.0493 | 0.0536 | 0.0666 | 0.1341 | 0.3321 |
| CDAE | 0.0384 | 0.0532 | 0.0632 | 0.1293 | 0.2965 |
| FwFM | 0.0386 | 0.0532 | 0.063 | 0.1262 | 0.2921 |
| LR | 0.0381 | 0.0534 | 0.0628 | 0.1271 | 0.2949 |
| Pop | 0.0358 | 0.0494 | 0.0556 | 0.1095 | 0.2891 |
| LINE | 0.0253 | 0.0485 | 0.054 | 0.1185 | 0.2609 |
| DSSM | 0.0305 | 0.0411 | 0.0483 | 0.104 | 0.2627 |
| ENMF | 0.0115 | 0.0176 | 0.0193 | 0.0461 | 0.1442 |
各モデルが何を表しているのか、全て説明しているとしんどすぎるので、RecBole のページを見ながら表を見ていただければと思います。
ここで言いたいことは以下の4つです。
- NGCF・LightGCN・DGCF・GCMC のグラフ系モデルが上位を独占
- SLIMElastic・BPR など古くからあるモデルもそれなりに上にいる
- context-aware系で上位付近にいるのは AutoInt・AFM くらい
- 期待していた RecVAE など VAE系があまり振るわない
- なんで期待したかというと、所属企業のブログで書いた実験結果では RecVAE が圧倒したからです
Case2. FourSquare NYC
では、この調子でもう一つのデータでもモデル群を試していきましょう。2つ目は FourSquare NYCというデータです。https://github.com/RUCAIBox/RecSysDatasets から説明文を引用すると↓
This dataset contains check-ins in NYC and Tokyo collected for about 10 month. Each check-in is associated with its time stamp, its GPS coordinates and its semantic meaning.
ということで、ニューヨークの各スポットにチェックインしたデータだそうです。
MovieLens と同じように、まずデータの基礎統計を確認します。
The number of users: 1084
Average actions of users: 84.04801477377654
The number of items: 38334
Average actions of items: 2.374559778780685
The number of inters: 91024
The sparsity of the dataset: 99.78095038424168%
今度はユーザ数とアイテム数のバランスが全く取れていないデータです。ユーザ数に対してアイテム数の数が異常に多いですね。1ユーザのアクションした平均アイテム数は84ですが、1アイテムに対してアクションした平均ユーザ数は2、とロングテールなんだろうなあ、と目に見えてわかります。sparsity も MovieLens は 95% でしたが、こちらは 99% となっており、悩みの深いデータセットです。
今回使う yml は先程の MovieLens とほぼ同じで、Selectively Loading のところと item_id が変わります。
# Selectively Loading
load_col:
inter: [user_id, venue_id, timestamp]
unused_col:
inter: [timestamp]
item_id が venue_id に変わっているのでお気をつけ下さい。そして、アイテムの情報としてどれを使えばよいか迷ってしまって、今回は一切使っていません。なのでこの設定次第で context-aware 系のモデルの結果はかなり変わりそうな気もしますが、まあ今回は「そういうことなんだな」と思っていただいて...
免責事項も書きましたが、同じように実験結果を見てみましょう。若干数が減って33個のモデルでの実験結果が得られました。
| Name | hit@10 | mrr@10 | ndcg@10 | precision@10 | recall@10 |
|---|---|---|---|---|---|
| LightGCN | 0.2004 | 0.1089 | 0.0401 | 0.0243 | 0.0323 |
| SLIMElastic | 0.205 | 0.1071 | 0.0399 | 0.0246 | 0.0332 |
| RecVAE | 0.1958 | 0.0979 | 0.0373 | 0.0236 | 0.0316 |
| FNN | 0.1884 | 0.098 | 0.0367 | 0.0224 | 0.0303 |
| DMF | 0.1911 | 0.0953 | 0.0364 | 0.023 | 0.0307 |
| DeepFM | 0.1911 | 0.0931 | 0.0359 | 0.0229 | 0.0312 |
| GCMC | 0.1819 | 0.0955 | 0.0359 | 0.0222 | 0.0297 |
| MacridVAE | 0.1911 | 0.0934 | 0.0358 | 0.0228 | 0.0306 |
| MultiVAE | 0.1745 | 0.0936 | 0.0349 | 0.0211 | 0.0282 |
| NeuMF | 0.1791 | 0.0867 | 0.0343 | 0.0223 | 0.0299 |
| MultiDAE | 0.1671 | 0.0928 | 0.0341 | 0.0203 | 0.0281 |
| xDeepFM | 0.1662 | 0.0948 | 0.034 | 0.0198 | 0.026 |
| FwFM | 0.169 | 0.0931 | 0.0335 | 0.0202 | 0.0264 |
| WideDeep | 0.1616 | 0.0937 | 0.0335 | 0.0192 | 0.0259 |
| LR | 0.1801 | 0.086 | 0.0329 | 0.0219 | 0.0292 |
| AutoInt | 0.1644 | 0.0914 | 0.0323 | 0.0189 | 0.0253 |
| SpectralCF | 0.1653 | 0.0888 | 0.0322 | 0.0194 | 0.026 |
| PNN | 0.1717 | 0.0827 | 0.0319 | 0.0209 | 0.0283 |
| AFM | 0.1717 | 0.0802 | 0.0315 | 0.0208 | 0.0281 |
| DCN | 0.169 | 0.0839 | 0.0315 | 0.0207 | 0.0271 |
| FFM | 0.1634 | 0.0829 | 0.0308 | 0.0191 | 0.0257 |
| Pop | 0.1791 | 0.0711 | 0.0301 | 0.0214 | 0.0289 |
| FM | 0.1468 | 0.0594 | 0.0243 | 0.0172 | 0.0244 |
| BPR | 0.1505 | 0.0557 | 0.0237 | 0.0173 | 0.0238 |
| NNCF | 0.1274 | 0.063 | 0.0232 | 0.0144 | 0.0204 |
| NFM | 0.0822 | 0.022 | 0.0098 | 0.0084 | 0.0106 |
| LINE | 0.0683 | 0.0225 | 0.0094 | 0.0074 | 0.0098 |
| NGCF | 0.0572 | 0.023 | 0.0093 | 0.0059 | 0.0086 |
| ItemKNN | 0.0406 | 0.0178 | 0.0062 | 0.0043 | 0.0054 |
| Item2Vec | 0.0194 | 0.007 | 0.0026 | 0.0021 | 0.0024 |
| DSSM | 0.0037 | 0.0015 | 0.0007 | 0.0004 | 0.0007 |
| ENMF | 0.0028 | 0.0013 | 0.0005 | 0.0003 | 0.0005 |
| CDAE | 0.0009 | 0.0003 | 0.0001 | 0.0001 | 0.0001 |
- 上位に LightGCN はいるものの、NGCF・GCMCは転落している(DGCF計算忘れました
 )
) - 同様に SLIMElastic は上位にいるが、BPR はかなり下の順位に落ちている
- BPR はパラメータが適当でもいつも上位にいる感覚があったので、かなりびっくりしています
- RecVAE・MacridVAE など VAE 系が割と上がってきた
- FNN・DeepFM など context-aware 系も上位にいる
- ただし、NDCG@10 は上位でも 0.04 しかなく、そもそもタスクが異常に難しい
- MovieLens は 0.08 はあった
という結果となりました。チューニングをしていないのでこの結果は決定版ではないのですが、一応同じ条件で比較したにしては全然違う結果になったことが皆さんにも伝わったのではないかと思います。「推薦タスクはデータによってどのモデルが強いのかがかなり変わる」を実際の数字として示せました。
推薦モデル同士がどの程度似ているのかをネットワークグラフで可視化する
ここからは、2つのデータセットで得られた推薦モデル群に関する考察をしてみようとおもいます。
各推薦モデルはそれぞれのユーザに対して10個のアイテムを表出したリストを持っているわけですが、そのリストを使えば「このモデルとこのモデルはこのくらい一致してる」「一致してない」などを指標として出せそうです。
これを見ることで何が面白そうかというと
- グラフ系のモデル、FactorizationMachine系のモデルなど似た系統のモデルが一致度が高いかどうか
- 成績上位(下位)のモデルは他と全然違う推薦をしているのかそうではないのか
など、モデルの挙動を理解するのにもしかしたら役立つかもしれません。
今回はこれを 推薦リスト一致度 と呼ぶことにして、それを計算してみることにしました。
まず、RecBole のモデルから topk リストを取得します。
import json
import click
import numpy as np
import torch
from recbole.config import Config
from recbole.data import create_dataset, data_preparation
from recbole.quick_start.quick_start import load_data_and_model
from recbole.utils import get_model
from recbole.utils.case_study import full_sort_topk
import pandas as pd
from src.custom_models.Item2Vec import Item2Vec
from src.metrics import calculate_indicators
from tqdm.auto import tqdm
@click.command()
@click.option(
"--model_file",
required=True,
type=str,
help="example. saved/ckpd_recipe/Item2Vec-Nov-06-2021_02-41-35.pth",
)
@click.option(
"--output_file",
required=True,
type=str,
help="example. pop.json",
)
@click.option(
"--is_item2vec",
type=bool,
is_flag=True
)
def main(model_file, output_file, is_item2vec):
print("=====")
print(model_file)
print("=====")
# for get Item title
# foursquare ではアイテム名がないので、しょうがないからカテゴリ名を苦し紛れに取得
_df = pd.read_csv("dataset/foursquare-nyc-merged/foursquare-nyc-merged.item", sep="\t")
internal_id_to_title = _df["venue_category_name:token"].to_dict()
# custom model(Item2Vec)のとき
if is_item2vec:
checkpoint = torch.load(model_file)
config = checkpoint["config"]
config.seq_separator = "@"
dataset = create_dataset(config)
train_data, valid_data, test_data = data_preparation(config, dataset)
model = Item2Vec(config, train_data.dataset).to(config["device"])
model.load_state_dict(checkpoint["state_dict"])
model.load_other_parameter(checkpoint.get("other_parameter"))
# custom modelではないとき
else:
config, model, dataset, train_data, valid_data, test_data = load_data_and_model(
model_file=model_file
)
ground_list = []
uid_list = []
for batch_idx, batched_data in enumerate(test_data):
interaction, row_idx, positive_u, positive_i = batched_data
ground_list.append([int(v) for v in positive_i.numpy().tolist()])
uid_list.append(interaction.user_id.numpy()[0])
ranked_list = []
for uid in tqdm(uid_list):
topk_score, topk_iid_list = full_sort_topk(
[uid], model, test_data, k=10, device="cuda"
)
ranked_list += topk_iid_list.cpu()
all_metrics_results = {}
for uid, g_list, r_list in zip(uid_list, ground_list, ranked_list):
external_uid = dataset.id2token(dataset.uid_field, uid)
all_metrics_results[external_uid] = {
"ground_list_id": [v for v in dataset.id2token(dataset.iid_field, g_list)],
"predict_list_id": [v for v in dataset.id2token(dataset.iid_field, r_list)],
"ground_list": [internal_id_to_title[v-1] for v in g_list],
"predict_list": [internal_id_to_title[v-1] for v in r_list.numpy()],
}
text = json.dumps(all_metrics_results, sort_keys=True, ensure_ascii=False, indent=2)
with open(output_file, "w") as fh:
fh.write(text)
if __name__ == "__main__":
main()
Item2Vec は僕が勝手に実装したカスタムモデルなので特別な対応をやっています。
from recbole.utils.case_study import full_sort_topkという関数を使うことで topk 出力が可能になるので、それをやっている!というスクリプトです。( recbole.utils.case_studyというモジュール名からして、topk 出力はあんまりメインの用途ではなさそうですね)
で、出力した topk リストを使って以下のスクリプトからモデルごとの推薦リスト一致度を見ます。
import glob
import itertools
import numpy as np
import pandas as pd
from tqdm.auto import tqdm
def main():
filelist = glob.glob("output/foursquare_nyc_case_study/*.json")
model_results = {}
for file in tqdm(filelist):
_model = file.split("/")[-1].split(".")[0]
try:
_df = pd.read_json(file).T
model_results[_model] = _df
except:
print(f"{_model} read is failed")
# modelのコンビネーションを用意する
_models = model_results.keys()
combis = list(itertools.combinations(_models, 2))
model_similarities = []
for c in tqdm(combis):
model1 = c[0]
model2 = c[1]
model1_result = model_results[model1]
model2_result = model_results[model2]
model1_predict_list = model1_result["predict_list_id"].values
model2_predict_list = model2_result["predict_list_id"].values
sims = []
for m1_preds, m2_preds in zip(model1_predict_list, model2_predict_list):
_sim = len(set(m1_preds) & set(m2_preds)) / len(m1_preds)
sims.append(_sim)
similarity = np.mean(sims)
model_similarities.append([model1, model2, similarity])
result = pd.DataFrame(
model_similarities, columns=["source_model", "dest_model", "similarity"]
)
result.to_csv("foursquare_nyc_survey_with_recbole.csv", index=False)
if __name__ == "__main__":
main()
これをすることで、以下のような表が生成されます。これは foursquare の結果です。
この表は流石に長過ぎて全部は貼れないので、spreadsheet のリンクを置いておきます→ Link
で、この一致度をネットワークグラフで可視化します。どういうことかというと、一致度が0.5以上ならそのモデル同士にエッジを張る、というルールでネットワークグラフにしていきます。
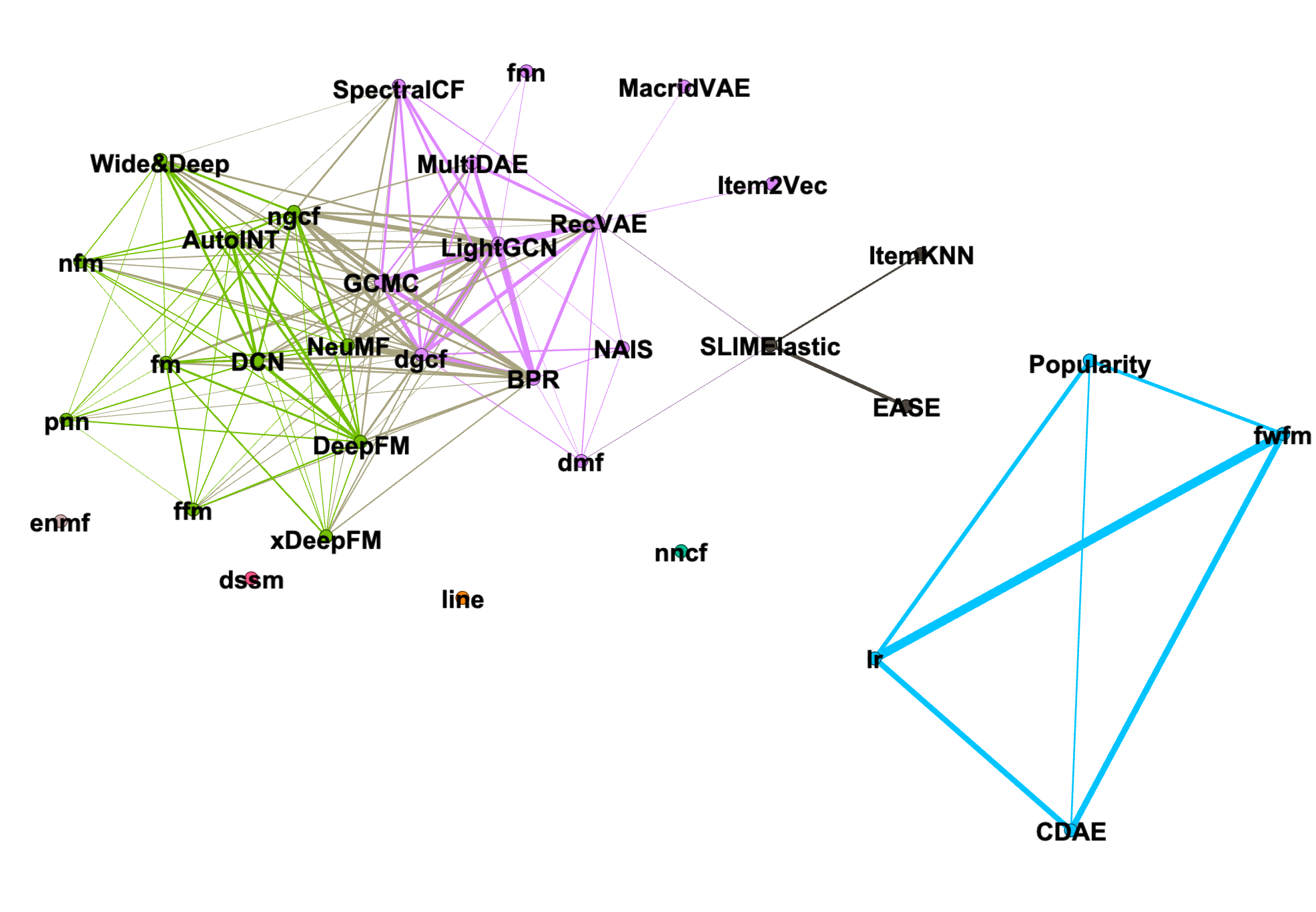
というわけでネットワークグラフは以下のようになりました。予めモジュラリティクラスタリングしており、その結果を色に反映しています。また、レイアウトアルゴリズムは Yifan Hu Multilevel です。
MovieLens
FourSquare

Discussion
いやー全然違う結果になりました。
結果をまとめてみると
- 全体的にネットワークの形が全く異なる
- MovieLens の方では FactorizationMachine 系は同じコミュニティに属している。が、FourSquare の方はそうでもない
- グラフ系のLightGCN、GCMC、DGCF は比較的同じコミュニティにいそう
- FourSquareの方でDGCF計算し忘れているのでいません
- FourSquareの方でDGCF計算し忘れているのでいません
- どちらでも上位にいた LightGCN の中心性は、MovieLens では高いが FourSquare では低い
- 固有ベクトル中心性で 0.97 -> 0.34
- ちなみに中心性一位は MovieLens では DGCFとBPR、FourSquareでは DMF と Pop(人気のアイテムをただ出すだけのやつ)!?
- MovieLens と比べて FourSquare の方はエッジを持っていないノードがかなり多い
- 単純に推薦がうまくいってない?
推薦対象のデータが変わることで、モデルの挙動も大きく変化しているらしいことがわかってきました。といっても、まだ何もわかってないのですが...
結局なにが原因でこんな結果になるのか
ここまでの分析を通して、データによってモデルの挙動が大きく変化しているので上位のモデルが入れ替わっていることがわかりました。これは結局何が原因なんでしょうか?
前述したようにまだ何もわかってないのですが、データの基礎統計から察するに、明らかにユーザ数・アイテム数・Sparsityが異なるデータで今回は比較したので恐らくその辺り、つまりそのデータを生み出したサービスの性質による影響(バイアス)を色濃く受けるからだと思います。
そりゃそうだろ、って感じですね。しかし、この感覚的に思っていたことを実際に複数のモデル・データセットで確認できたのは大きな収穫でした。
今後の展望
上述したデータのバイアスを何らかの指標で表現することができればいいな、とおもっています。これを指標で表現できるようになると、「指標がこれくらいだからモデルAとかBが強そう」のような推測が立てられるのではないでしょうか。
まとめ
こういう展望を目指せるようになったのも RecBole が登場してくれたおかげですね。みなさんも RecBole を試してみて、無限の可能性に触れてみてはいかがでしょうか。