概要
Azure FormRecognizerで提供されている身分証明書 (ID)事前構築済みモデルでは、運転免許証の読み取りは米国のフォーマットを対象としているため日本の免許証はうまく読み込めません。そこでFormRecognizerのカスタム抽出モデルを活用し、日本国内の運転免許証用の読み込みモデルを作成してみました。
参考:身分証明書モデル
Azure FormRecognizerとは
名刺や免許証、請求書、レシートなどのドキュメントからテキストと構造データを抽出できるOCRサービス。 事前構築済みの機械学習モデルに加え、カスタムモデルの構築も可能です。
FormRecognizerのカスタム抽出モデルの設定
プロジェクトの作成
事前にAzurePortalより、カスタム抽出モデルのプロジェクト作成時に必要となる下記のリソース作成を行います。
・Form Recognizer
・ストレージアカウント(モデル生成に必要なBLOBデータを格納するストレージ)
・コンテナ(ストレージアカウント内のBLOBデータの保管先ディクレトリ)
リソースの作成後、Form Recognizer Studioよりカスタムモデル(Custom extraction model)のプロジェクト作成を行います。
・Form Recognizer Studioの下部にあるCustom extraction modelを選択します。
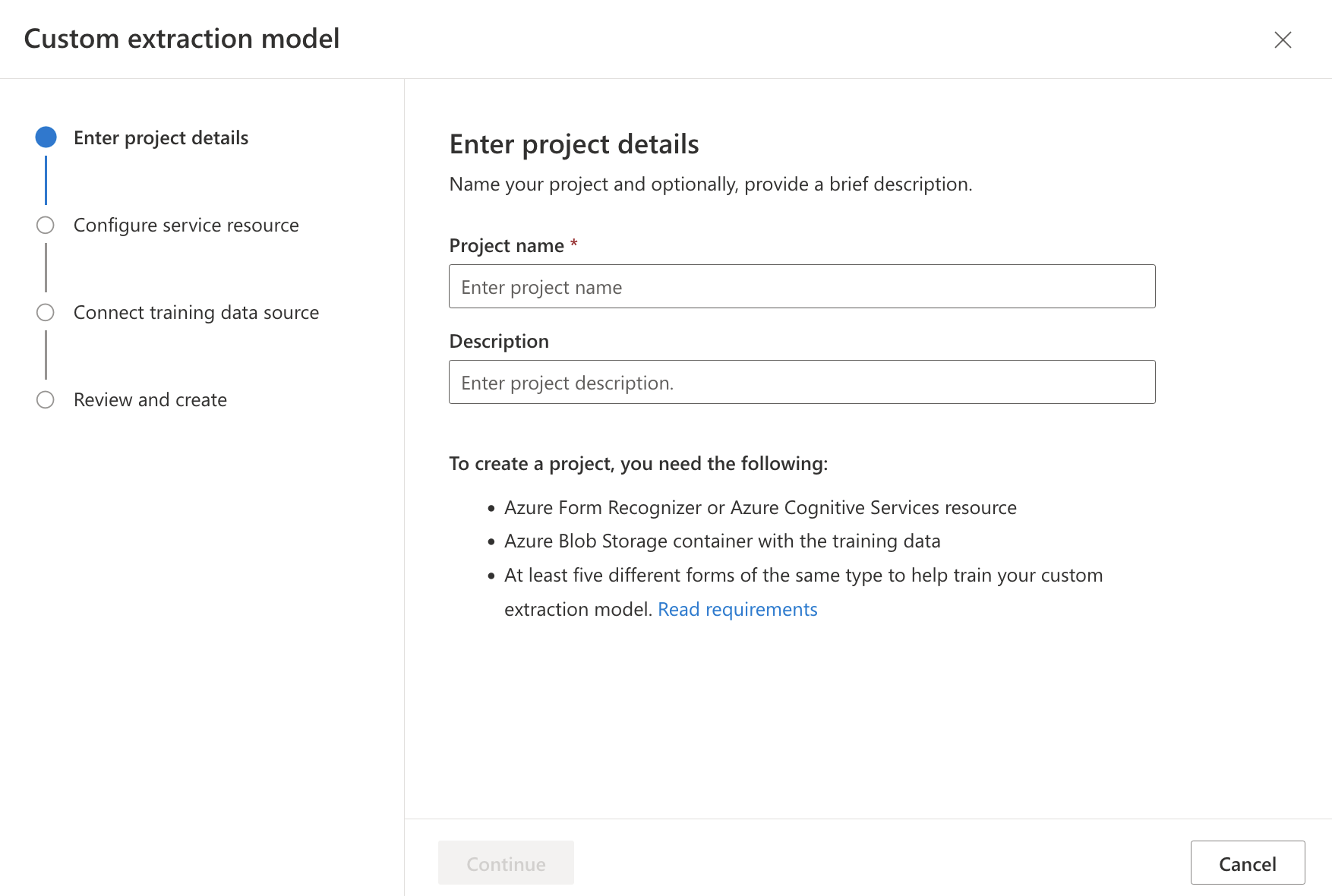
・My projectからプロジェクトを作成します。
・事前に作成したリソース(Form Recognizer、ストレージアカウント、コンテナ)を含め必要な情報を入力します。
・Form Recognizerリソースの選択
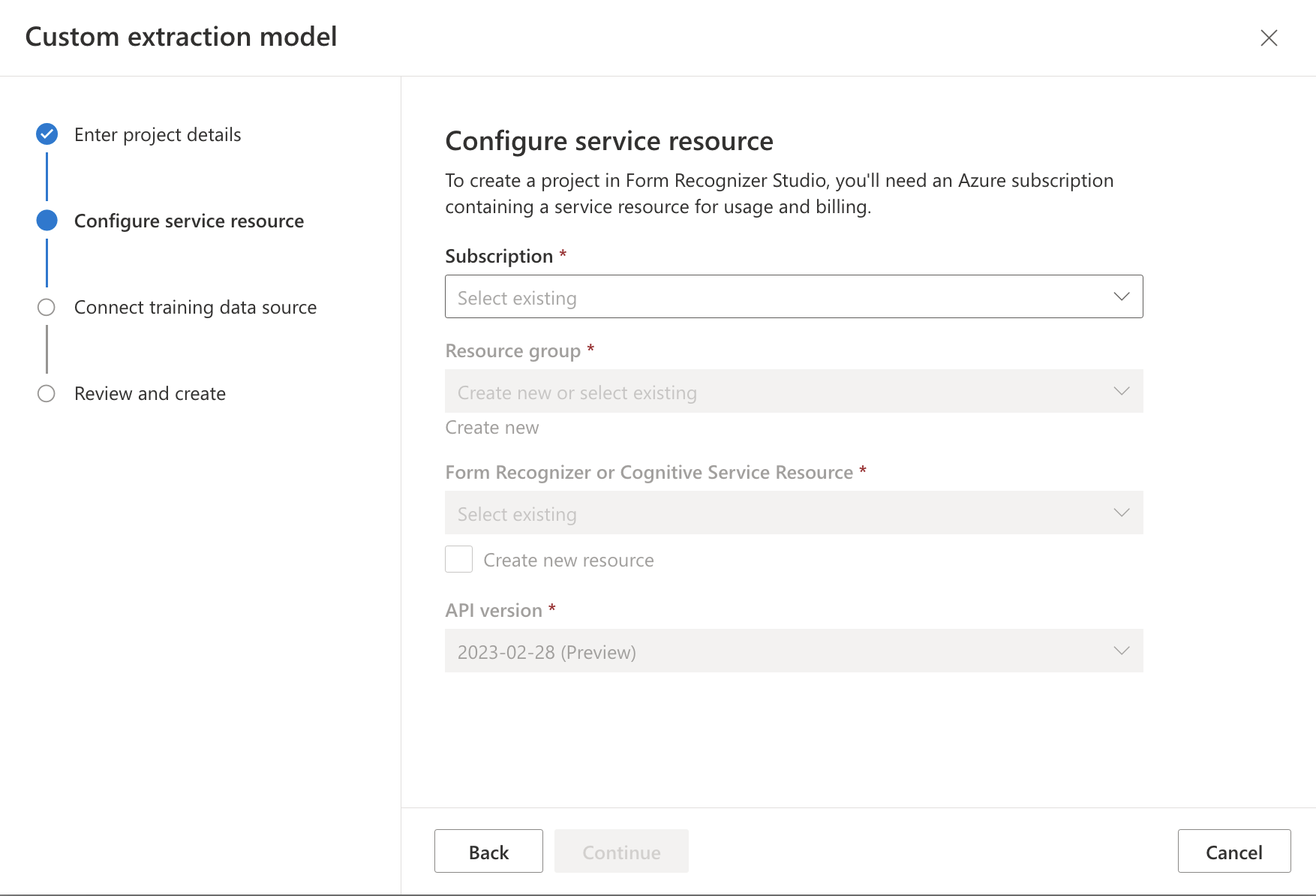
・ストレージアカウント、コンテナリソースの選択
登録が完了すると下記のカスタム抽出モデルのトレーニング画面(ラベル付け)に遷移します。
モデルのトレーニング
カスタム抽出モデルのトレーニング(ラベル付け)画面にて学習用のファイル(運転免許証画像)をアップロードします。モデルのトレーニングを行うのに少なくとも5枚以上のファイルを登録する必要があります。
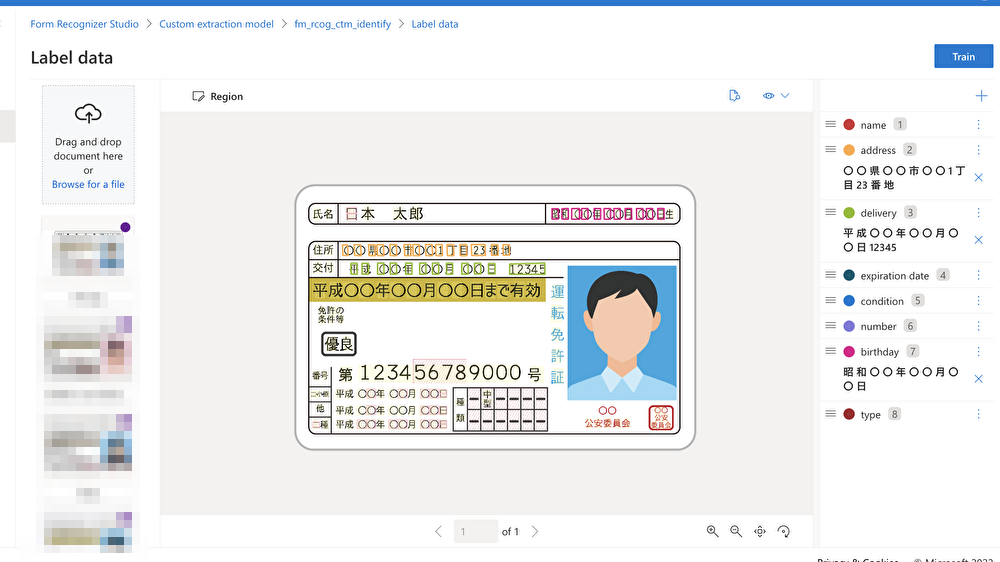
アップロードした画像ファイルに対し、抽出したいフィールド(画像内の項目)を追加の上、マウスのクリック操作でラベル付けを行います。
ラベル付けされた項目値はフィールド名の下部に表示されます。
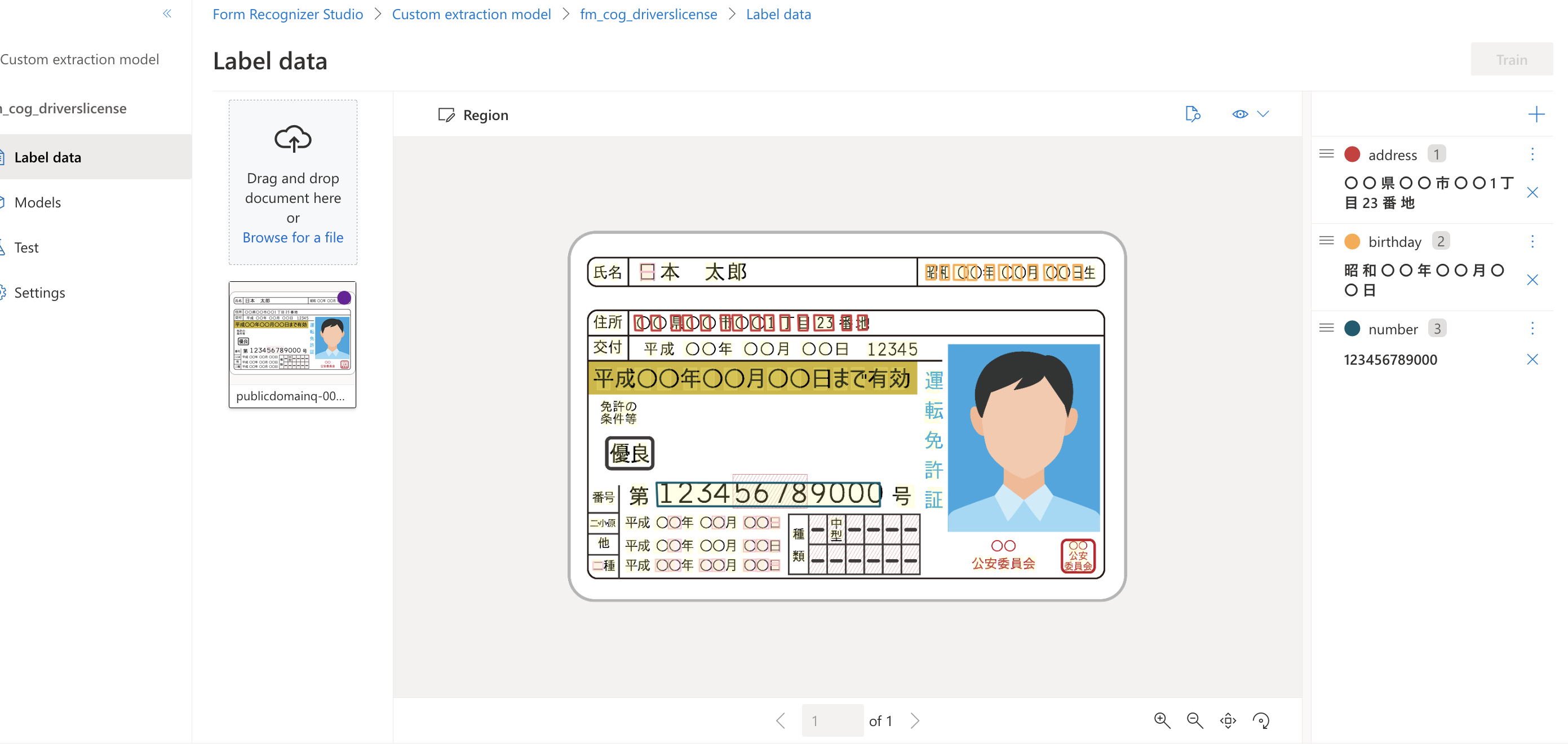
※画面右側のフィールド一覧上部の+ボタンからFieldを選択し、名称を入力し設定します。
*画像はフリー素材を利用しています
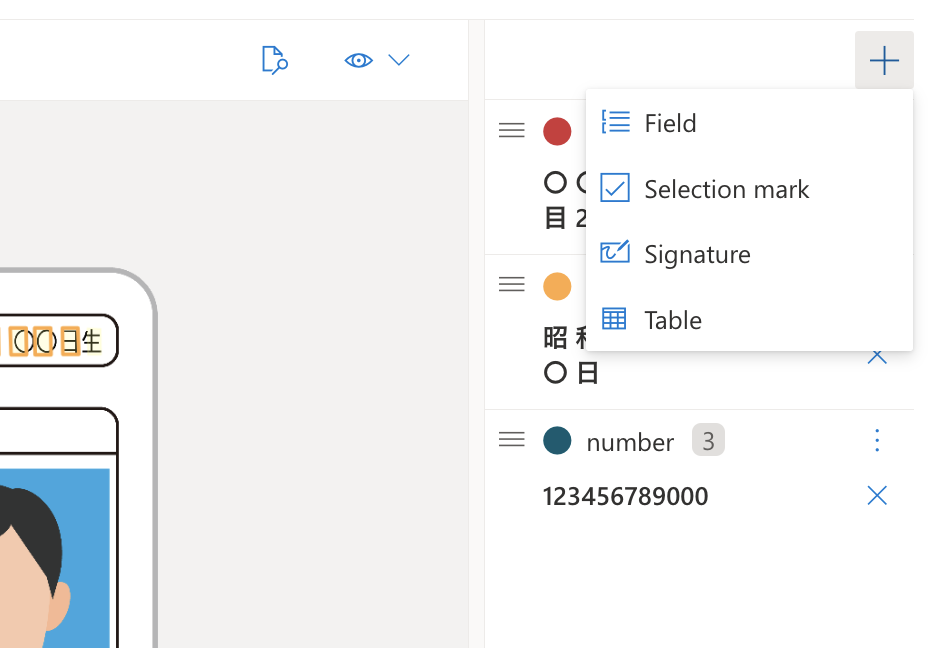
5枚以上のファイルのラベル付けを完了したら、右上のTrainボタンよりトレーニングを開始します。
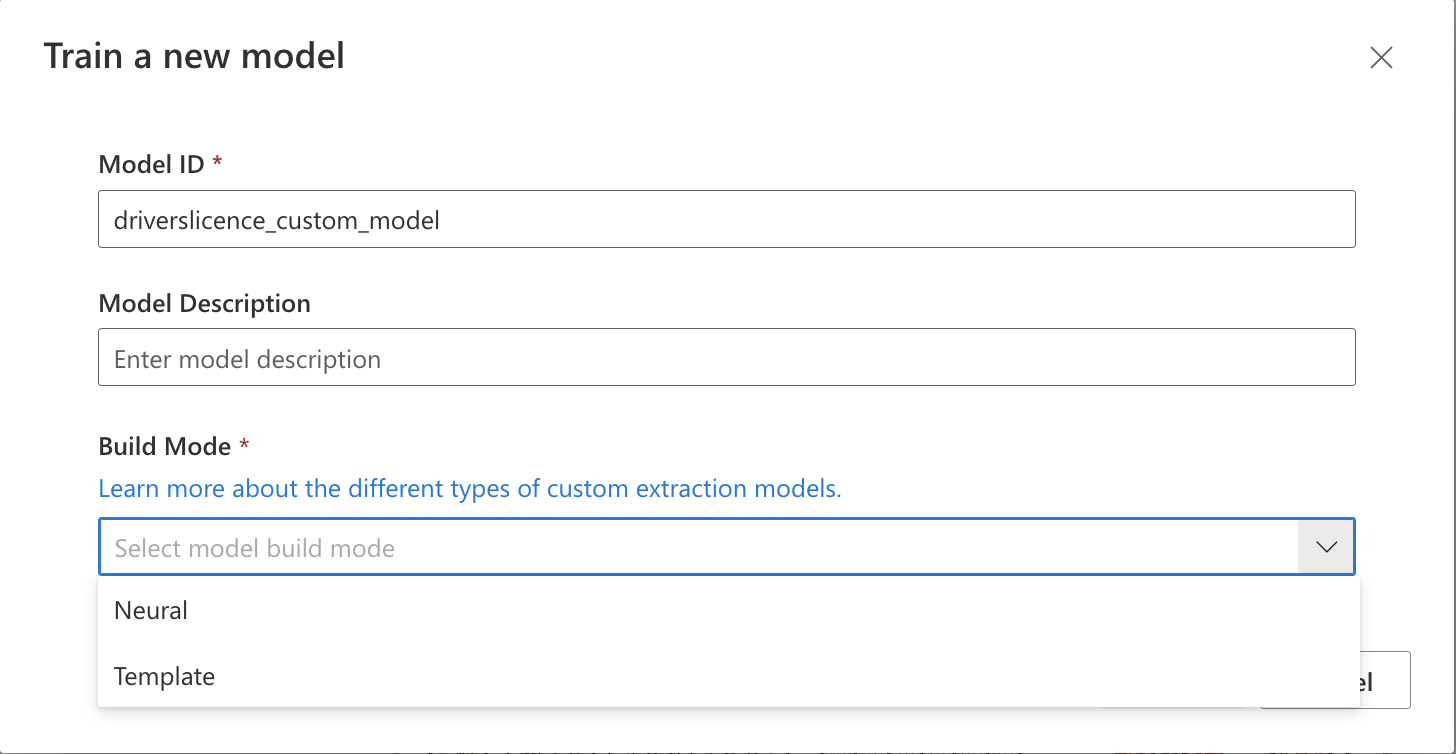
Model IDに任意の名称を入力、ModeにTemplateを選択しTrainボタンを押し、しばらく待つとモデルのトレーニングが完了します。
今回追加設定したフィールド
| フィールド名 | 免許証項目 |
|---|---|
| name | 氏名 |
| address | 住所 |
| delivery | 交付日 |
| expiration date | 有効期限 |
| number | 免許証番号 |
| birthday | 生年月日 |
| condition | 免許の条件等 |
モデルのテスト
トレーニング完了したモデルをテストします。
免許証画像*をアップロードし、Analyzeボタンを選択し、モデルのテストを開始できます。
テスト結果はメイン画面に表示され、画像から抽出された各フィールドの値が右側のナビゲーションバーに表示されます。
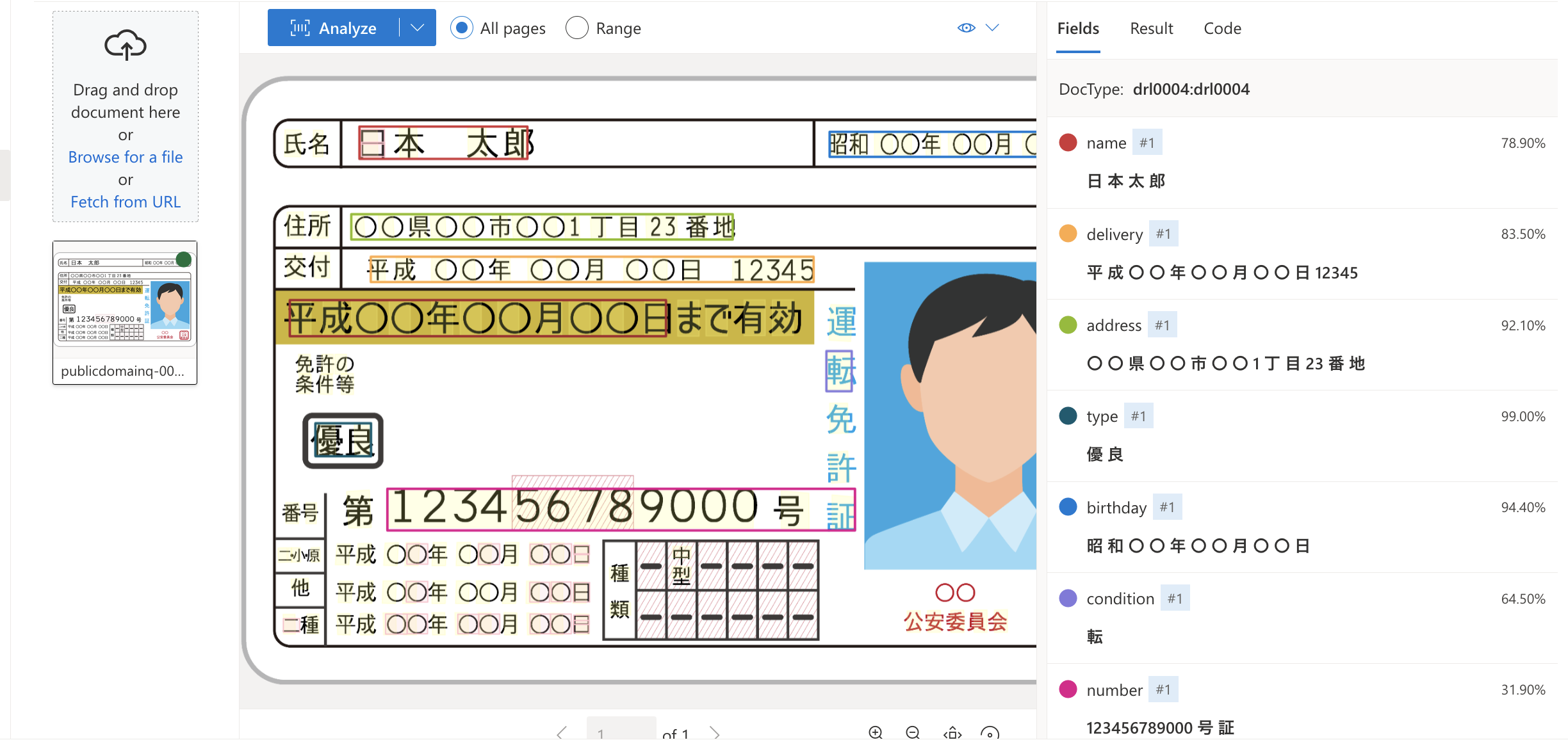
各フィールドの抽出結果を評価し必要に応じてモデルのトレーニングを継続します。
参考:モデルの正確性を高める方法
右側のナビゲーションバーでは、モデル利用のコードサンプル(python,javascript,C#)、テスト結果のJSONデータの確認もできます。
また作成したモデルは、RESTAPIから呼び出すことも可能です。詳細は下記のドキュメントからご確認ください。
おわりに
Form Recognizer v3.0をサポートするForm Recognizer Studioを使ってのカスタムモデルの作成がGUIベースで直感的に行えました。studio上でコードサンプルも提示してくれるのでモデルを利用したアプリの作成などもスムーズに行えそうな感触を持ちました。
機能追加のペースもそれなりの頻度で行われていきそうなので今後も試していきたいと思います。