前回リンク:https://qiita.com/fs-shinji-tomiyama/items/5bf63f6f5b20a9fd9b5f
概要
本エントリーは、早くシンギュラリティが実現して、生理食塩の水槽に脳ミソ一つでプカプカ浮かびながら、無限大の時間と空間を飛び回りたいと望んでいる筆者のポエムです。
ディープラーニング
「シンギュラリティ = 超AI」ということで、まずは流行りのディープラーニングを実際に動かして体験してみようというのが本エントリの目的です。
ガイド本
独学で新しい技術を学ぶ時、1冊はそのテーマの実装方法が詳細してある技術本を購入して、実際に動かして遊んでみるのが早道だというのが私の経験則です。
ディープラーニングについては、2年ぐらい前から、良い本がないかと本屋をチェックしていましたが、なかなか丁度良い感じのものがなかったのですが、昨年末にこちらの本を見つけ、今回はこの本で紹介されているサンプルをとにかく全部動かしてみることを目的にしました。
実装 ディープラーニング オーム社 ¥3,200- 税別

以上、ここまでテンプレ
推測
学習が完了したらいよいよ、テストデータを投入して推測の実行です。
ディープラーニング使ってんだから、すごい結果が出るんだろうなぁとワクワクで実行します。
しかしクラス分けの結果は。。。
30%〜90%前半代
うーん。。。トレーニングを40分程度回しただけだと、この程度なのかとちょっと肩透かし。
しかし、ご安心を。
この後、学習済みモデルを使ったサンプルが待っています。
最初に使ったものが9層ネットワークで、次に16層の学習済みモデルを使います。
16層の学習済みモデルを使うと、ほとんど100%のクラス分けに成功し、低くて90%前半という感じです。
さらに次なるサンプルプログラムでは、152層の学習済みモデルを使って99.9%の認識率を叩き出します。
152層とか、相当深い(高い?)ダンジョンで最後の層にはきっと最強の大ボスがいるのではないかと想像してしまいます。
とにかく、こんなに精度が高いモデルが、ネットで簡単に手に入り、自作PC程度で実行できるというのは驚きです。
4章後半では、さらに精度を上げるための施策とそのサンプルプログラムが紹介されています。
この辺は同じことの繰り返しでデータを詰めていくというところで、ちょっと飽き気味になりますが、実務ではきっとこういう作業が避けて通れないんだろうなぁと感じさせられます。
続く5章では、物体位置検出と物体形状検出が待っています。
先へ進みたいのをぐっと我慢して、人間バッチ作業を実行して、とにかくデータ詰めを終わらせます。
この精度を上げる作業はかける工数に対して、思いの外精度が上がらないので現実のAI研究現場を疑似体験している気分に浸れます。
#物体検出
画像のクラス分けに比べると、派手さ十分です。
顔認識や自動運転につながる技術なので、興味津々です。
物体位置検出
解説を読み進めて、実際に認識させた画像がこちら。


ラベルづけもできていて、まぁ、いいんじゃないでしょうか。
ただ、ガイド本では紹介されていなかった対象物が複数存在するケースはあんまりうまくいきませんでした。
学習でAvg IOUの値が0.9以上になると、それなりの精度が出るということでしたが、私のマシンでは0.8代までしか上がりませんでした。
エポック回数を増やして、試してみたいと頃ですが数時間単位で時間を使います。
物体形状検出
学習データとして物体の写った写真と、その対象データを2値化して対象部分を切り抜いた画像をトレーニングデータとして読み込ませ、テスト画像を与えて輪郭を切り出すという流れですね。
こちらの実行結果がこちら、






まぁ、ガイド本の掲載サンプルより、輪郭が溶け気味ですが、ほぼ同じ結果が得られているのではないでしょうか。
切りだしているのは何かわかりますよね?
はい、飛行機です。下の方は複葉機なのですが、サンプル数が少ないと制度が落ちるようです。
強化学習
ガイド本の最終章は「強化学習ー三目並べに強いコンピュータを育てる」です。
「コンピュータを育てる」。。。良いですねぇ。シンギュラリティの香りがします。
ここではDQNの原理を解説しています。
DQNという単語は認識していたのですが(2ch用語ではなく)、いまひとつ原理がわからなかったのですが、かなり丁寧に説明されており、なるほどなるほどという感じで身近に感じられる用語になりました。
このサンプルプログラムでは、実際に強化学習をしていく過程をグラフ出力してくれる機能も実装しています。
それがこちらです。
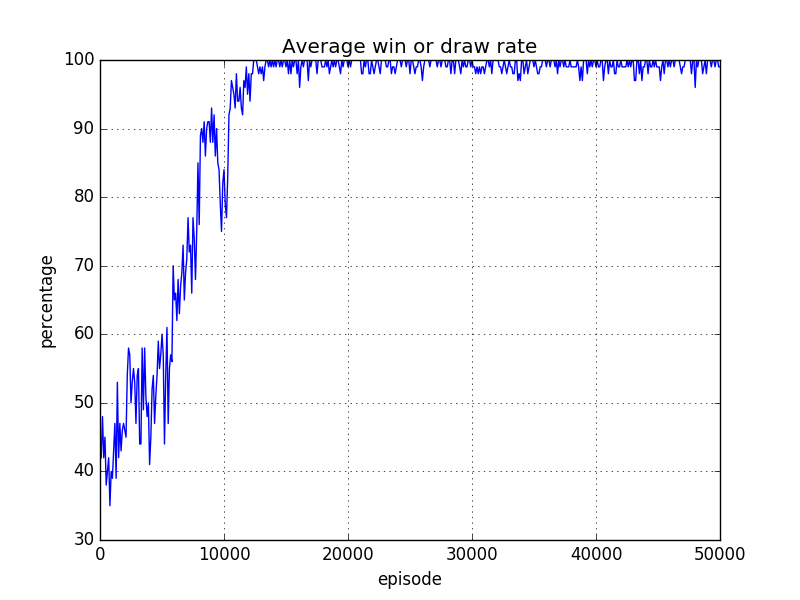
勝率(実際には勝ったか引き分け)のグラフになりますが、強化学習が進むほど勝率が上がっていくのがよく分かります。
強化学習の過程で、どのような手を打ったのかもログとして吐く機能もありますので、学習初期と後半のものを比べてみるのも面白いです。
まとめ
以上でガイド本のサンプルプログラムを全て動かしてみたでした。
「なんだサンプル動かすのであれば、誰でもできるじゃない」と思われる方もいますが、例え出来合いのプログラムで環境作って動かしてみると、頭というより体が覚えてくれるところが大です。
実際には、今回のガイド本の通りにやると動かないケースもあったりで、原因調べて自分の環境用にスクリプトを修正したりする作業もあり、そんなことで身についていくんだと思います。
また、ネットで見るAI系のニュース記事など内容の理解度がかなり上がったと感じられます。
それまではもやっとこんな感じなんだろうなという程度のことが、あぁ、そういうことねと腑に落ちるケースが増えました。
発売から間も無く1年になろうとしているガイド本ですが、CUDA8レベルはまだまだ現役だと思いますので、Linuxは普段から触っていて、PCも自作というレベルの人で、ディープラーニングをちょっと動かしてみたいという方にはおすすめです。
今回使ったガイド本には株価予測のような時系列データについては、サンプルがなかったので、次はその辺を攻めてみようかなと思っています。
ということで、早く来い来いシンギュラリティ!ということで一旦閉めたいと思います。
ありがとうございました。
おまけ
筆者は現在海外に長期出張中です。
お盆の頃に数日の帰国する機会があり、帰国前に、ディープラーニング用マシンの必要パーツを選定、帰国後尼で一気に発注、部品到着、換装を行い、ubuntuインストールと外部からsshできる環境までを自宅に構築。出張先に舞い戻ったところからsshで環境構築して利用しました。
電源を落としてしまうと、起動できないので電源入れっぱなしです。
ビットコインのマイニングでGPUを回しっぱなしすると数万円は電気代がかかるという話もあり、ヒヤヒヤしていましたが、帰国した数日間のエアコン代含めて4000円程度のアップしていました。
電気代でこれぐらいかかるとすると、自己学習目的での利用なら、クラウドGPUインスタンス利用もありかもしれませんね。
落とし忘れ時の打撃は大きいですが。。。
ではでは、ハッピーAIライフを。