「JavaのCollectionで学ぶインターフェースの意義」という記事を書きました。
この記事では、Collectionのインターフェースに焦点をあてていたので、今回はよくつかう実装クラスに注目し、それぞれの実装クラスの内部実装や特徴、使い分けの話をしていきます。
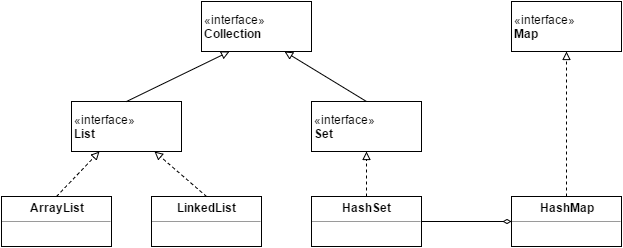
今回説明する実装クラス
おそらくよく使うであろうCollection系クラスです。
HashMapはCollectionではなくMapの実装クラスなんですが、よく使うのとHashSetとの関連が高いので、HashSetと一緒に説明していきます。
クラス図
インターフェースの役割(詳細はこちら)
| インターフェース | 役割 |
|---|---|
| List | 要素の順序付けられたグループ。基本的に重複を許す。 |
| Set | 要素の重複を許さないグループ(集合)。順序は実装クラスによる。 |
ArrayList~配列によるList~
ArrayListはその名の通り、配列(Array)によるListの実装です。
内部で配列を持っており、配列に対してデータの格納や参照、挿入などを行います。
そのため、ArrayListの特性を知るためには配列の特性を知る必要があります。
そもそも配列とは
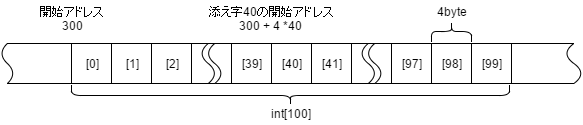
配列はメモリ上に連続した領域を確保するものです。
その一番の特性は添え字による参照が高速にできることです。
領域が連続しているので、先頭アドレス、添え字、1つあたりのデータサイズさえわかれば、参照したいアドレスを以下の式で求めることができます。
参照するアドレス = 先頭アドレス + 添え字 × 1つあたりのデータサイズ
ArrayListの内部処理
配列はこのように連続した領域を確保する必要があるため、本来であれば最初に決めた要素数から変更することはできません。
しかし、ArrayListでは動的に要素を追加していくことができるようになっています。
ArrayListでは、要素を追加していって配列が足りなくなった場合に自動的に配列を再確保します。
再確保と言うは易しですが、実際には元のサイズよりの1.5倍の要素数を持つ配列をnewして、元の配列からデータをコピーするという処理を行うため、非常に重い処理になります。
ArrayListで初期容量(コンストラクタの引数)を決めたほうがよいといわれるのは、最初に確保する配列の大きさを決めておくことでこの再確保の処理が実行される頻度を下げるためです。
また、配列は挿入に非常に弱いです。
データが格納される領域が固定されているため、場所をずらすという処理を行うことができないからです。
ArrayListでは、addメソッドで任意の場所へのデータの挿入処理を実装していますが、この内部も配列の再確保を行い、挿入位置より後ろのデータはインデックスをずらしてコピーすることで挿入場所を空けるという処理を行っています。
LinkedList~線形リストによるList~
線形リストというデータ構造を聞いたことがあるでしょうか?
LinkedListは線形リストの構造を基にしたListの実装です。
線形リストとは
線形リストはデータとリンク(次要素への参照)を1つのオブジェクト(ノード)として扱い、ノードを連結していくことでデータ列を扱えるようにしたデータ構造です。
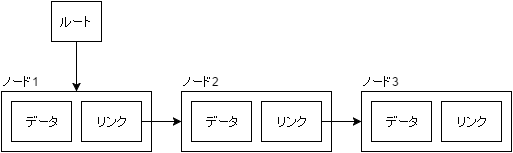
このデータ構造の利点は、ルート(最初のノードへの参照)さえ知っていれば、各ノード内のリンクを辿っていくことで要素へアクセスすることができることです。
そのため、配列のように各ノードが連続した領域に存在している必要はありません。
また、データの挿入を行う場合は前後のノードの参照さえ変更すればよいのでArrayListのような大掛かりなコピー処理も必要としません。
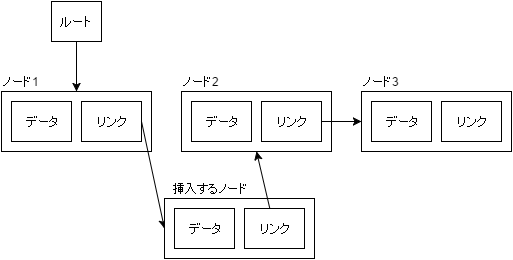
LinkedListの内部処理
線形リストで欠点となるのは、ランダムアクセスが遅いことです。
例えば、2番の要素にアクセスするためには[ルート]->[0番の要素]->[1番の要素]->[2番の要素]といったようにルートからリンクを準繰りにたどっていく必要があります。
LinkedListでは、少しでもランダムアクセスを高速化するためにリンクを双方向にしたり、一番最後の要素への参照を保持するといった工夫をしています。
しかし、要素が多ければ多いほどランダムアクセスが遅くなるのは免れません。
また、各ノードがデータ以外に参照をフィールドとして持つことによって、同じ要素数のArrayListよりもメモリ使用量は多くなります。
HashSet~ハッシュ値を利用したSet~
HashSetは先の2つのListと異なり、Setの実装クラスです。
すなわち、要素の重複を許さず、ランダムアクセスができません。
また、HashSetでは順序を保持しません。
重複を許さないということは、要素を追加する時にすでにその要素がSet内に存在するか否かを判断する必要があるということです。
HashSetでは、配列、線形リスト、ハッシュ値をうまく使うことで高速な存在確認を実現しています。
ハッシュ値とは
ハッシュ値は元となるデータから特定の式に基づく計算で算出される値です。
同じデータからは同じハッシュ値が計算できますが、少しでもデータが異なる場合は値が大きく異なるように設計されています。
また、不可逆でありデータからハッシュ値を算出できても、ハッシュ値からデータを復元することはできません。
ハッシュ値自体は認証や正当性チェック、暗号化など情報処理の世界で幅広く利用されています。
Javaにおけるハッシュ値
Javaにおけるハッシュ値はインスタンスを識別するための値であり、hashCodeメソッドで算出されるint型整数です。
hashCodeメソッドはObject型で定義されています。
「ハッシュ値の同じデータから同じハッシュ値が計算できる」という特性に基づき、equalsメソッドがtrueを返すインスタンス同士では同じハッシュ値を返さなければならず、逆にデータが異なる場合はできる限り同じ値にならないようにする必要があります。
HashSetの内部処理
HashSetはこのハッシュ値をうまく使うことで高速な存在確認を実現しています。
HashSetはインスタンス化された段階でサイズsの配列を確保します。
あるインスタンスeを格納するとき、HashSetはまずe.hashCode()でハッシュ値を求め、そこから格納されるべき場所を算出します。
e.hashCode()とsの剰余(割り算の余り)を求め、その場所にeを格納します。
array[ e.hashCode() % s ] = e;
格納場所はe.hashCode() % sから算出されるため、存在確認を行う場合に配列内をひとつひとつ調べて検索する必要はなく、与えられたインスタンスのハッシュ値を計算してそこにインスタンスがあるかどうかを調べることで存在確認ができるということになります。
衝突した場合
というのは、あくまで理想論です。
実際には配列のサイズsはハッシュ値と比べると小さい数なので、格納しようとした場所にすでにデータがあるという現象が発生します。
これを衝突と呼びます。
衝突が起きた場合に備え、HashSetではデータ格納の際に線形リストのように次の要素へのリンクを持ったデータ構造でデータを格納します。
そして、衝突が起きた場合にはすでに存在する要素の次の要素としてデータをつなげていきます。
これによって、一度の参照とはいかずともe.hashCode() % sの値が同じになるグループのみを検索していくことで存在確認を行うことができます。
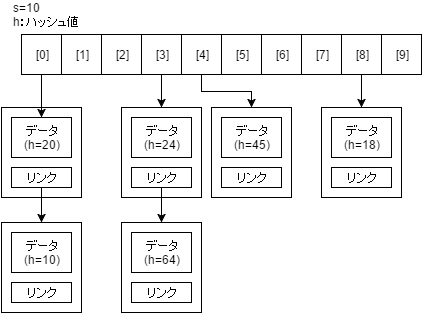
リサイズ
データ数が増えるほど、衝突の可能性は高くなります。
例えば、s = 10の場合に、11個のデータを格納する場合、確実に衝突が発生することになります(鳩の巣原理)。
そこで、データ数が増えてきた場合に配列を大きな容量で再確保し、データを入れ直すという処理を行います。
ここでのデータの入れ直しは単純なコピーではなく、配列の添え字とe.hashCode() % sの対応が崩れないように入れ直しを行うためデータの構造が崩れることはありません。
hashCodeのオーバーライド
HashSetはhashCodeの値によって格納場所を判断します。
そのため、hashCodeの式の性能がHashSetの衝突確率に直結します。
極端な話、hashCodeの中身をreturn 0;のように常に定数を返す処理にしてしまうとデータ格納のたびに衝突が起こるため、検索性能がLinkedListよりも下がります。
そのため、格納する要素のクラスに適切なhashCodeメソッドをオーバーライドすることが重要となります。
とはいえ、オレオレhashCodeでは衝突の可能性が高いです。
一番よいのはObjects.hashCodeメソッドを使うことです。
Objects.hashCode(フィールド1,フィールド2,フィールド3);
引数が可変引数になっているので、複数のObject型のデータを渡すことができます。
ただし、各フィールドのhashCodeで得られるハッシュ値を使用して最終的なハッシュ値を算出するので、それぞれのフィールドのクラスでもhashCodeメソッドをオーバーライドしてやる必要があります。
HashSetとHashMap
さて、ここまでHashSetの内部実装の話をしてきましたが、実は嘘です。
別の記事でも書きましたが、実はHashSetの内部実装というのはHashMapによって実現されています。
そのため、今まで話してきた内部実装の話は実際にはHashMapの内部実装の話だったということです。
しかし、内部処理の実装をHashMapに依存しているだけなので挙動としてはどっちも同じだということです。
HashMapの話
HashMapについて触れておくと、HashMapはMapの実装クラスであり、KeyとValueという2つのデータのペアで値を保持します。
Keyは先ほどまで説明してきたHashSetのデータの部分にあたるものです。
Keyインスタンスのハッシュ値でデータ格納を行うのでKeyからデータを高速に検索することが可能です。
Valueは単にKeyに紐づく値であり、Keyと一緒に格納されます。
HashSetでは、Valueとしてstaticな値を設定することで余計なメモリの消費をすることなく、HashMapを使った実装を行っています。
各実装クラスの比較
まとめとして、各実装クラスの性能をオーダー表記で比較してみます。
オーダー表記がわからない人はO(1)よりもO(n)のほうが遅い、くらいで見てみてください
性能比較
| 実装クラス | 追加 | 挿入/削除 | 検索 | ランダムアクセス | メモリ使用量 |
|---|---|---|---|---|---|
| ArrayList | O(1)※ | O(n) | O(n) | O(1) | 少ない |
| LinkedList | O(1) | O(1) | O(n) | O(n) | 中 |
| HashSet | O(1)※ | O(1) | O(1) | 不可能 | 多い |
| ※:リサイズが発生する可能性あり |
比較してみると、各実装クラスの特徴が見えてきます。
例えば、挿入が多ければLinkedList、ランダムアクセスが多ければArrayListのように処理の内容によってどのクラスが向いているかということは変わるので、適切な実装クラスを選択していきましょう。