この記事で紹介していた IPA 文字情報基盤は 2020年8月より 一般社団法人文字情報技術促進協議会 に信託譲渡されました。https://mojikiban.ipa.go.jp/ 自体が失効しているため、本記事の方法は機能しません。過去の記録として閲覧してください。
入力チェックで 「JIS第n水準の字以外はNG」 といった要件が稀によくあります。そんなとき、先人の正規表現や文字リストを流用することはありがちですが信憑性は課題です。ここでは IPA の 文字情報基盤 を使って JIS 第n水準の文字集合を取得する方法を紹介します。
1. API
文字情報基盤では SPARQL Endpoint を提供しており、以下のような Web フォームに SPARQL を入力実行することで情報の取得が可能です。
SPARQL Endpoint は CORS に対応しており、以下のような javascript コードで Web ブラウザからの利用も可能です。query の部分を適当な SPARQL クエリーで置き換えましょう。
$(function() {
var query = "select * where {?s ?p ?o.} limit 10";
$.getJSON("https://mojikiban.ipa.go.jp/1bf7a30fda/sparql", {
format: "application/sparql-results+json",
m: "sparql",
query: query
}).then(function(json) {
console.log(json);
}).catch(function() {
console.log(arguments);
});
});
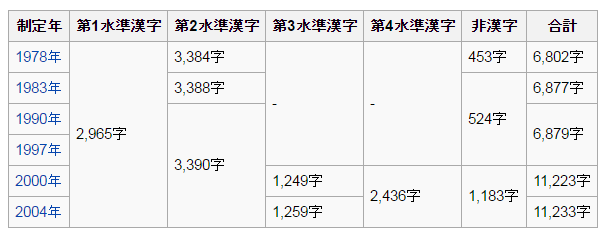
2. JIS の水準ごとの収録数
こんなクエリーが
PREFIX mjp: <http://mojikiban.ipa.go.jp/terms/prop/>
select ?o (count(?s) as ?count) where {
?s mjp:JIS水準 ?o .
} group by ?o
こんな結果を返します
{
"head": {
"vars": [
"o",
"count"
]
},
"results": {
"bindings": [
{
"o": {
"type": "uri",
"value": "http://mojikiban.ipa.go.jp/data/JIS水準/4"
},
"count": {
"datatype": "http://www.w3.org/2001/XMLSchema#integer",
"type": "typed-literal",
"value": "2436"
}
},
{
"o": {
"type": "uri",
"value": "http://mojikiban.ipa.go.jp/data/JIS水準/1"
},
"count": {
"datatype": "http://www.w3.org/2001/XMLSchema#integer",
"type": "typed-literal",
"value": "2969"
}
},
{
"o": {
"type": "uri",
"value": "http://mojikiban.ipa.go.jp/data/JIS水準/2"
},
"count": {
"datatype": "http://www.w3.org/2001/XMLSchema#integer",
"type": "typed-literal",
"value": "3390"
}
},
{
"o": {
"type": "uri",
"value": "http://mojikiban.ipa.go.jp/data/JIS水準/3"
},
"count": {
"datatype": "http://www.w3.org/2001/XMLSchema#integer",
"type": "typed-literal",
"value": "1259"
}
}
]
}
}
表形式にするとこんな結果です。
| o | count |
|---|---|
| http://mojikiban.ipa.go.jp/data/JIS水準/1 | 2,969 |
| http://mojikiban.ipa.go.jp/data/JIS水準/2 | 3,390 |
| http://mojikiban.ipa.go.jp/data/JIS水準/3 | 1,259 |
| http://mojikiban.ipa.go.jp/data/JIS水準/4 | 2,436 |
文字情報基盤の SPARQL Endpoint はデフォルトで2000件、上限5000件までのクエリーに対応しています。各水準ごとにデータを取得するのであれば LIMIT 5000 を付与すれば一度に取得が可能です。
Wikipedia Japanese : JIS漢字コード のカウントと比べると第一水準の文字数が合いませんが、それは後述。
#3. JIS の各水準に所属する文字に対応する UCS
JIS 第一水準
PREFIX mjp: <http://mojikiban.ipa.go.jp/terms/prop/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select ?label where {
?s mjp:JISX0213/mjp:JIS水準 <http://mojikiban.ipa.go.jp/data/JIS水準/1> ;
mjp:実装UCS/rdfs:label ?label .
} limit 5000
JIS 第二水準
PREFIX mjp: <http://mojikiban.ipa.go.jp/terms/prop/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select ?label where {
?s mjp:JISX0213/mjp:JIS水準 <http://mojikiban.ipa.go.jp/data/JIS水準/2> ;
mjp:実装UCS/rdfs:label ?label .
} limit 5000
JIS 第三水準
PREFIX mjp: <http://mojikiban.ipa.go.jp/terms/prop/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select ?label where {
?s mjp:JISX0213/mjp:JIS水準 <http://mojikiban.ipa.go.jp/data/JIS水準/3> ;
mjp:実装UCS/rdfs:label ?label .
} limit 5000
JIS 第四水準
PREFIX mjp: <http://mojikiban.ipa.go.jp/terms/prop/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select ?label where {
?s mjp:JISX0213/mjp:JIS水準 <http://mojikiban.ipa.go.jp/data/JIS水準/4> ;
mjp:実装UCS/rdfs:label ?label .
} limit 5000
常用漢字
PREFIX mjp: <http://mojikiban.ipa.go.jp/terms/prop/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select ?label {
?s mjp:常用漢字であるか "yes" ;
mjp:実装UCS/rdfs:label ?label .
} limit 5000
出力と利用例
実際にクエリーを実行すると以下のような JSON が出力されます。 "value": "3A02" のように 16進の UCS が取得されています。
{
"head": {
"vars": [
"label"
]
},
"results": {
"bindings": [
{
"label": {
"type": "literal",
"value": "3A02"
}
},
{
"label": {
"type": "literal",
"value": "63C0"
}
},
...
- html 上で使用するのであれば各 value の前後を
㨂のように補ってあげることで数値文字参照として文字指定が可能になります。
4. 例外
JIS 第一水準は前述の通り、一般的に言われている文字数と文字情報基盤での文字数が一致していません。
次のクエリーは DB 内で JIS第一水準とされているもののうち、面区点番号が 1-0 ではじまっているものを取得するもので、4件がヒットします。
PREFIX mjp: <http://mojikiban.ipa.go.jp/terms/prop/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select * where {
?a mjp:JIS水準 <http://mojikiban.ipa.go.jp/data/JIS水準/1> ;
rdfs:label ?jis .
FILTER REGEX(?jis, "^1-0.*$")
} limit 5000
- 1-01-24
- 1-01-25
- 1-01-26
- 1-02-22
JIS 第一水準の面区点番号は 1-16-xx から 1-47-xx のあいだとされているようなので、この部分で齟齬があるようです。問い合わせて情報を更新してみたいところです。
5. まとめ
文字情報基盤の SPARQL Endpoint を使って JIS 第n水準の文字集合を取得するクエリーを紹介しました。公的かつAPIも提供されているので、プログラマー的には安心して使えるのではないでしょうか?文字情報基盤では JIS の水準に限らず文字に関するさまざまな情報が保持されているので、興味のある方はさらに深堀してみると面白いかもしれません。