Excel の WEBSERVICE 関数を使って、任意のキーワードに対応する Wikipedia Japanese の URL を取得する方法を紹介します。ガチの Entity Linking は自然文を解析してコンテクストに応じたリソースを取得するような高度な処理ですが、ここで紹介するのは「セルの値をコピーして検索フォームに貼り付けて Wikipedia のリンクを探すのつかれた、なんとかして」という声にこたえることを目的としています。
WEBSERVICE 関数については前稿 [Excel の WEBSERVICE 関数で外部データ取得] (http://qiita.com/frogcat/items/eddf5f8df4bba0419336) を参照してください。ちなみに Mac の Excel ではいまだサポートされていないようです。
1. シナリオ
以下のように A列に雑多なキーワードが並んだ Excel があります。B列に Wikipedia のへのリンクを埋めましょう。
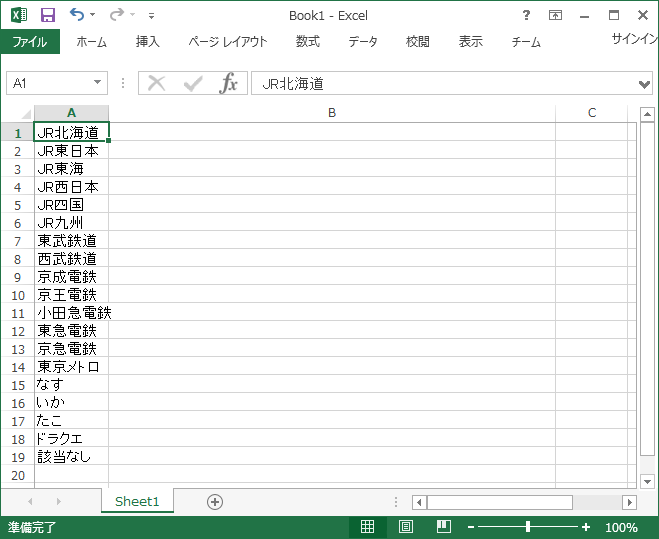
2. 手順
入力
セル B1 に以下の式を入力します
="https://ja.wikipedia.org/wiki/" & FILTERXML(WEBSERVICE("https://ja.wikipedia.org/w/api.php?format=xml&action=query&redirects&titles=" & ENCODEURL(A1)),"//*[not(@missing)]/@title")
うまくいくと次のように URL がフィルされます
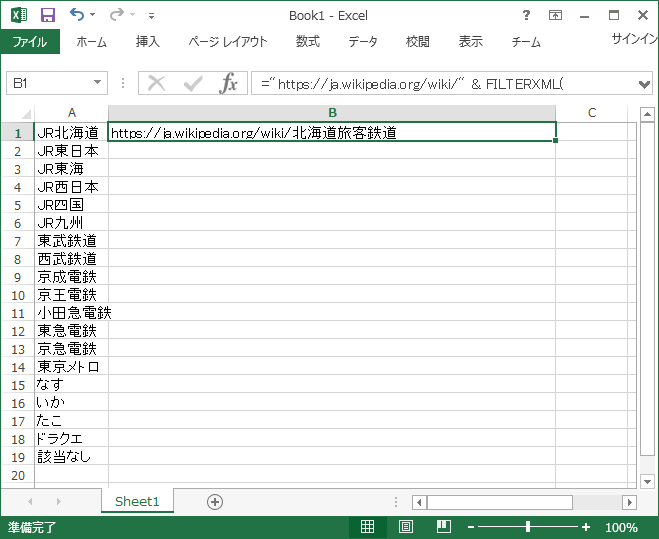
コピー
B1 を B2~B19 にコピーすると以下のようにフィルされるはずです
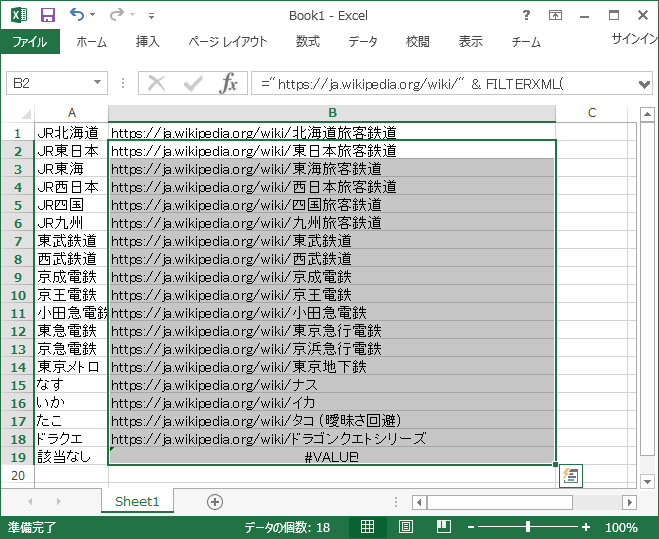
確認と手直し
フィルされた URL をそれぞれ確認しましょう。たこ や ドラクエ など、気になるものがありますね。
該当するページが存在しな場合には #VALUE! が表示されます。
またこの方法だとリンク先が 曖昧さ回避ページ であるかどうかまではわからないので、念のため個別に確認するのがいいです。
3. 解説
ここで紹介した方法は MediaWiki API:Query を使って、結果の XML から URL を作る、というものです。
具体的には以下のようなリクエストに対して
以下のような XML 出力が得られます。
<?xml version="1.0"?>
<api batchcomplete="">
<query>
<redirects>
<r from="なす" to="ナス" />
</redirects>
<pages>
<page _idx="1211" pageid="1211" ns="0" title="ナス" />
</pages>
</query>
</api>
ここに //@title という XPath を適用することで、Wiki のページタイトルを取得しています。で、https://ja.dbpedia.org/wiki/ をアタマにつけて URL 化。
なお、リンク先のページがない場合には以下のように page 要素に missing 属性が付与されているので区別することができます。このような XML に対して //*[not(missing)]/@title という XPath を適用することで、missing 属性がついた要素は選択されない= EXCEL 関数上ではエラーとなる、という挙動を実現しています。
<?xml version="1.0"?>
<api batchcomplete="">
<query>
<pages>
<page _idx="-1" ns="0" title="該当なし" missing="" />
</pages>
</query>
</api>
なお、ここ紹介した方法は単純な文字列連結で URL を作っていますが、空白をアンダースコアに変換したり、 URL エンコードをしたりなど、用途に応じて必要な処理を追加するといいでしょう。
4. まとめ
- Wikipedia の API と Excel の WEBSERVICE 関数を使って、キーワードに対応する Wikipage を取得する方法を紹介しました
-
https://ja.dbpedia.org/wiki/のかわりにhttp://ja.dbpedia.org/resource/を使うとより LOD/EntityLinking としては好ましいですがそれはまた別の機会に - もっと高度な EntityLinking をお求めの方は http://openrefine.org/ などをどうぞ