TL;DR
リスト内包表記、Pythonを使っていて知らない人はあまりいないかとは思いますが、実は無限の可能性を持っていたりします。
そもそも、リスト内包表記とはこんな感じでリストの初期化ができる機能です:
# Equivalent to [0, 2, 4, 6, 8]
[i*2 for i in range(5)]
# 辞書も初期化
{chr(k): k for k in range(128)}
# これはタプルじゃなくてジェネレータになる
(i*2 for i in range(5))
それから、条件が合えばかっこは省略できます。
# 引数が一つの場合はかっこを省略できる。
enumerate(chr(i) for i in range(128))
# こう書いても同じ
enumerate((chr(i) for i in range(128)))
# こう書くとリストに展開されるので非効率的
enumerate([chr(i) for i in range(128)])
# このかっこは省略不可
zip((chr(127-i) for i in range(128)), (chr(i) for i in range(128)))
# この場合も不可能
map(lambda x: x+1, (i for i in range(20) if i%5 == 0))
リスト内包表記はfor文やwhile文よりも高速に動作します。この機会にぜひマスターしましょう! おまけで実際にベンチマークもしてみています。
1. リスト内包表記で入力を受け取る
リスト内包表記で標準入力を受け取ってみます。
f Jane Green
m Paul Meadow
m Mickel Smith
f Meary Franklin
これを
members = [
['f', 'Jane', 'Green'],
['m', 'Paul', 'Meadow'],
['m', 'Mickel', 'Smith'],
['f', 'Meary', 'Franklin']
]
のような配列にしてみます。
from sys import stdin # stdinのようなファイルオブジェクトはイテレータ(重要)
members = [line.split() for line in stdin]
ね?簡単でしょ?…って言われても何のことかわかりませんよね?わかる人は読み飛ばしてもいいですよ。
from sys import stdin
members = []
# ファイルオブジェクトはイテレータとして扱うと一行づつ読み出してくれる
for line in stdin:
# 空白文字で区切って配列にした後、membersに追加
members.append(line.split())
実はリスト内包表記の動作だけに注目すれば、それは単にfor文の簡略表記にすぎません。map関数のリスト版みたいなものです。
2. リスト内包表記でwhileを書き換えてみる
例えばこんなコードは動くでしょうか?
array = [1, 2, 3]
# for文内で要素を削除
for a in array:
array.remove(a)
array = [0]
# for文内で要素を追加
for a in array:
if array[-1] > 5:
break
array.append(a + 1)
実は動きます。最初のfor文はこのプログラム
array = [1, 2, 3]
for i in range(len(array)):
if not array[i:]:
break
array.pop(i)
と等価です。また、後のfor文は
array = [0]
while array[-1] <= 5:
array.append(array[-1] + 1)
と等価です。
実はforでwhileは実現可能なのです!ところで、リスト内包表記はfor文と等価なので、whileを実現できるということになります。やってみましょう。
loop = [0]
[i for i in loop if i <= 5 and (loop.append(loop[-1]+1) or True)]
…やっぱり何やってるかわからないですよね。わかる人は読み飛ばしても(ry
まず、
i <= 5 and (loop.append(loop[-1]+1) or True)
の部分です。これは分解すればi <= 5と(loop.append(loop[-1]+1) or True)に分けることができます。Pythonのandとorは短絡評価、つまり評価結果が確定できた時点で残りの式を評価せずに値を返します。
ようするに、この部分はi <= 5がTrueならばloop.append(loop[-1]+1)を呼び出すという意味です。or Trueはloop.append(loop[-1]+1)の戻り値Noneが暗黙にFalseなので、式全体をTrueにするためにつけているにすぎません。
同じようにすれば、どんなループ条件でも判定できることがわかるでしょうか?
ループごとの処理は
i <= 5 and (loop.append(loop[-1]+1) or print(loop[-1]) or True)
のように追記すればよいのです。複数の文を単一式で書くのはlambda式の要領ですね。
それから、標準関数を応用すれば代入もできます。
[
(lambda x: setattr(x, '__name__', name) and globals().__setitem__(name, x))(func)
for func, name in [
(lambda x: print(f'Hello, {x}'), 'greet'),
(lambda x,y: x+y, 'plus')
]
]
さらに、クラスの宣言もできます。
type('Hoge', (), {
name: (lambda x: (setattr(x, '__name__', name), func)[1])(func)
for func, name in [
(lambda x, name: setattr(x, 'name', name), '__init__')
(lambda x: print(f'Hello, {x.name}'), 'greet')
]
})
とはいえ、これは純粋にリスト内包表記だけを使っているわけではないですし、リスト内包表記を使う意味も薄いです。実際の応用を考えてみましょう。
3. リスト内法表記を実際に使ってみる
Pythonには、イテレータを作る関数が標準にもいくつかあります。map、filter、reversedなどです。
mapはリスト内包表記そのものですし、filterもリスト内包表記で簡単に書くことができます。zipはちょっと難しいかもしれませんが、書くことはできます。
# map(lambda x: x**2, range(5)) に(ほぼ)等しい
[i**2 for i in range(5)]
# filter(lambda x: not x%2, range(10)) に(ほぼ)等しい
[i for i in range(10) if not i%2]
# zip([1, 2, 3], 'abcd') に(ほぼ)等しい
x = [1, 2, 3]
y = 'abcd'
[(x[i], y[i]) for i in range(min(len(x), len(y)))]
# enumerate('abcdefg') に(ほぼ)等しい
x = 'abcdefg'
[(i, x[i]) for i in range(len(x))]
これを見てわかるように、zipやenumerateは余計にややこしくなっています。リスト内包表記はmapの変換式やfilterの条件式がややこしい場合に特に大きな力を発揮します。
例えば、次の例ではどちらのほうが読みやすいですか?
'\n'.join(
map(lambda x: f"{x} % 3 = 2, {x} % 5 = 0",
filter(lambda x: x%3 == 2 and not x%5, range(20))))
'\n'.join(f"{x} % 3 = 2, {x} % 5 = 0" for x in range(20)
if x%3 == 2 and not x%5)
このように、filterとmapをネストしたり組み合わせたりすると標準関数では非常に読みづらくなります。処理の流れも把握しにくいです。
ですが、リスト内包表記ではある程度の可読性が期待できます。リスト内包表記でも読みにくいほどネストが深いのであれば、根本的に設計を考え直すべきです。多くの場合、ネストは深くても2つか3つで事足ります。
4. まとめ
イテレータはPythonを扱うにあたり避けては通ることができません。しかしながら、標準関数での操作までで終わってしまうことや、リスト内包表記は黒魔術的なイロモノ扱いされることもしばしばあります。
でも、黒魔術と忌避するのではなく、中身や正しい意味を知ることで世界は広がります。forやwhileはかなり冗長な書き方で、しかも重く、遅い処理です。多くの場合はそれで事足りるとしても、全く別な書き方を知ることはPythonistaとして以上にプログラマとしての成長にもつながるのではないでしょうか。
Ex. おまけ
注意: 本編の内容とはほとんど関係ありません。
1. いろいろベンチマークしてみた
環境:
- Python 3.6.5
- IPython 6.2.1
ループのベンチマークをしてみます。まずは普通にfor文。
ret = []
%%timeit
for i in range(10**5):
ret.append(i)
結果:
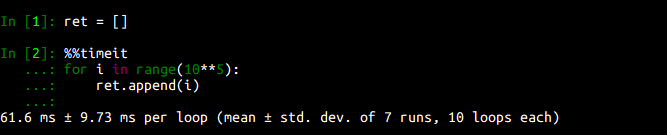
流石はPython、結構遅いですね。次は本命のリスト内包表記。appendのオーバーヘッドをそろえるため、appendを内包表記の中で呼んでみます。
ret = []
%%timeit
[ret.append(i) for i in range(10**5)]
結果は惨敗。あれ...?

じゃ、じゃあこれはどうでしょうか?
%%timeit
ret = [i for i in range(10**5)]
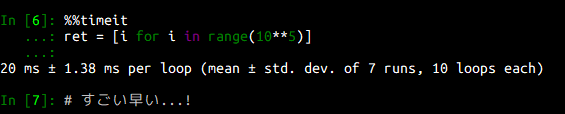
1/3以下の実行時間になりました。実はこれって関数呼び出しのオーバーヘッドがないだけかも...?と思ったので、これもやってみました。
%%timeit
list(range(10**5))

...単純にリストが作りたいならこれが最速かもしれませんね。もう何も言うまい...。
まだだ、まだ負けてない!と思ったので、条件を変えてみます。今回はrangeオブジェクトをリストにしましたが、filterを使った場合やmapを使う場合はどうでしょうか?
まずは普通にfilterイテレータをfor文で回してみます。
ret = []
%%timeit
for i in filter(lambda x: (x%5 - 1) == 0, range(10**5)):
ret.append(i)
結果:

filterによってloopの数が減ったからか、かなり速くはなっています。ですが、1/5にループが減っていることを考慮すると遅いと言わざるを得ません。続いては内包表記です。
%%timeit
ret = [i for i in range(10**5) if (i%5 - 1) == 0]
結果:

すごい速くなってますね!...ですが条件なしの内包表記と比べると、6割程度にしかなってません。1ループあたりの実行時間は遅いと言わざるを得ないでしょう。
次はlist関数を使ったものもやってみます。
%%timeit
ret = list(filter(lambda x: (x%5 - 1) == 0, range(10**5)))
結果:

唯一これだけがfilterなしより遅くなりました。filter関数がオーバーヘッドになっているようです。
whileとforってどっちのほうが速いんでしょうか? これも気になるのでベンチマークしてみます。
%%timeit
loops = 0
while loops < 10**5:
loops += 1
%%timeit
for i in range(10**5):
pass
%%timeit
for i in [None] * (10**5):
pass
%%timeit
for i in [0] * (10**5):
pass
結果:
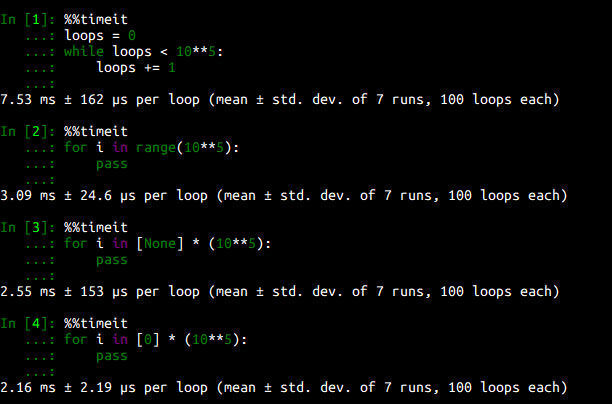
空文ではそんなに時間がかかりませんが、それでもここまで差が出ました。loops += 1するオーバーヘッドの分whileだけ不公平な気もしますが...。
単純に回数を使わない場合はrangeより[0]*loopsとか、[None]*loopsのほうが速いみたいですね。
ところで話は変わりますが、代入のオーバーヘッドってどれくらいあるんでしょう? やってみます。
%%timeit
var = 5 # int型
%%timeit
var = "hoge" # str型
%%timeit
var = [] # list型
%%timeit
var = () # tuple型
%%timeit
var = {} # dict型
結果:
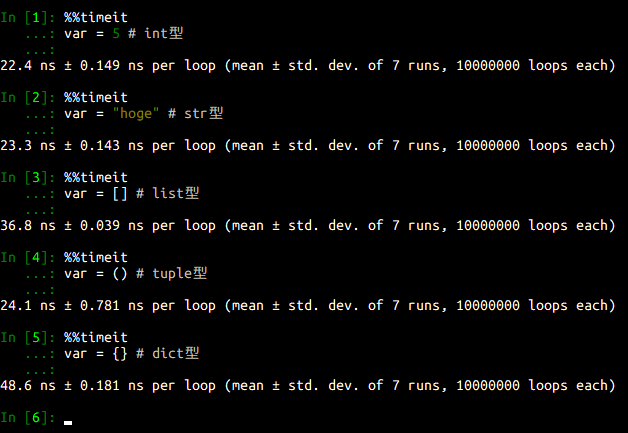
これならあまり気にする必要はなさそうですね。dictとlistが遅いのは、代入のオーバーヘッドというよりも初期化のオーバーヘッドだと考えられます。結論として、代入にはほとんど時間がかからないということになりそうです。
関数を呼び出すオーバーヘッドにも気になるものがあります。どれくらい掛かるんでしょうか?
def func(a):
a * 2
class Hoge:
def method(self, a):
a * 2
instance = Hoge()
method = instance.method
%%timeit
func(5)
%%timeit
instance.method(5)
%%timeit
method(5)
結果:
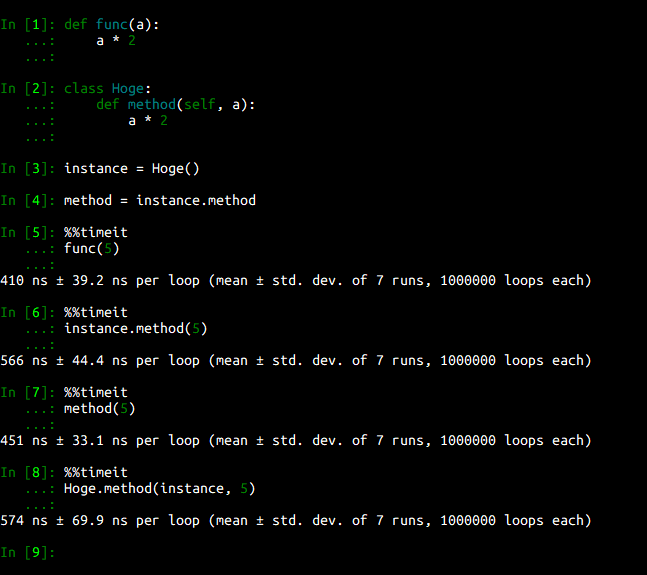
これもまぁ似たり寄ったりな結果ですね。ですが、やはりグローバル空間上に定義した関数が一番速いようです。
instance.methodの型は<class 'function'>ではありません。<class 'method'>という別の型です。この型は__func__というメンバを持っており、これを__call__の中で呼び出していると推測できます。おそらく、関数を呼ぶオーバーヘッドが1回多いので遅いのでしょう。
Hoge.methodが<class 'function'>なのになぜ遅いのかは説明できませんが...。メンバの参照って実はオーバーヘッドが大きいのでしょうか...?
2. Pythonの公式ドキュメントを読もう!
Pythonの公式ドキュメントはたぶん初心者の頃によんだきりという人も多いのではないでしょうか。でも、ある程度使えるようになってから読むドキュメントはとても面白いですよ!
知らなかった関数や動作を「発見」できるかもしれません。
3. Pythonのプロトコルを知ろう!
Pythonは標準関数などのフックになるようなプロトコルがいくつかあります。クラス定義の時に考慮すると便利になるかもしれません。
class Hoge:
def __new__(self, *args, **kwargs):
"""インスタンスを作成する関数。selfには例外的にクラスが渡される。"""
pass
def __abs__(self):
"""この関数の戻り値がabs()関数の戻り値になる。"""
return 0
def __hash__(self):
"""この関数の戻り値がhash()関数の戻り値になる。"""
return 0
def __iter__(self)
"""イテレータプロトコル。この関数をジェネレータとして定義するか、イテレータを返す必要がある。"""
yield None
ほかにもいろいろあるのでドキュメントを読んでみるといいかもしれません。