はじめに
2021年もあと1ヶ月を切りました!今年もインテックのアドベントカレンダーに参加です!
どうも、エンジニアのYusuke Miyamaruです。
今年度のテーマは
「音楽」
をテーマに、一本書いてみようと思います。
実を言うとわたしは、学生の時に「音楽情報処理」と呼ばれる学問を専攻していまして、
「ドラム演奏を聞いたときに感じるノリの良さ」を情報処理、感性工学といった科学的なアプローチで研究していました。↓
社会人になってからは、大学で培った知見を活用し
SEとして地方金融機関の銀行システムの開発を行ったり、
データサイエンティストとしてお客様のデータ分析やAI活用をご支援したり、
人間中心設計の考えをベースとした使いやすいUIを目指したToB向けのマッチングアプリ「i_soda」の事業企画やUIデザインなどを行ってきました。
そこで今年は、改めて私の専門分野である「音楽」について
「データサイエンティストの観点」から少し見つめ直してみようかなと思いまして
Kaggleで公開されていた仮想の音楽アルバムのデータセットを対象としたデータ分析
にチャレンジしてみようと思います!
なお、架空のデータですので、今回の分析による考察の妥当性については保証できません。
といいますか、今回のデータセットにて仮説検証の際の原因特定をすることはあまり意味がないので実施しておりません、ご了承ください!
本記事の対象者
- 少し統計をかじった方
- データマイニングに興味があるものの、分析の流れが分からない方
- Dataikuで何ができるか知りたい方
- 音楽や楽器が好きな方
データ分析の環境
OS:MacOS Catalina 10.15.4
Dataikuのバージョン:7.0.1
pythonのバージョン:3.7
Dataikuとは
Dataikuとは、一言でいうと「データ分析のためのツール」なのですが、
データサイエンティストだけでなく、アナリストやエンジニアといった役割の違う方がコラボレーションしながら
データを分析するだけでなく統計モデリング、システム構築・実装まで完結できるマルチなツールとなっています。
前回書いた記事でも使っております!↓
先日のプレスにもあったように、これから日本市場にも力を入れていくようですので、まだ使ったことがない人は要チェックです!
自分も、これまでSPSSやMATLAB、pythonやRなどの分析ツールを使ってきましたが、
Datakuは非常にGUIが洗礼されており、今まで一番使いやすいと感じたツールです!
ぜひ興味がある方は使ってみてください!
使用するデータセット
今回使用するデータセットはこちらから入手いたしました。
下記2種類のcsvファイルを使用します。
-
albums.csv
- id(key):アルバム固有のID
- artist_id:アーティストのID
- album_title:アルバムのタイトル名
- genre:アルバムのジャンル
- year_of_pub:アルバムが公開された年
- num_of_tracks:アルバムの中にあるトラックの数
- num_of_sales:アルバムがリリース後の最初の1ヶ月間に何枚売れたか
- rolling_stone_critic:ローリングストーン誌がどのようにアルバムを評価したか
- mtv_critic:MTVがアルバムをどのように評価したか
- music_maniac_critic:レビューサイトMusic Maniacがアルバムをどのように評価したか
-
artists.csv
- id(key):アーティストのID
- real_name:アーティストの本名
- art_name:アーティストの芸名
- role:アーティストの主な役割、楽器パートなど
- year_of_birth:アーティストの誕生年
- country:アーティストの出身地
- city:アーティストが住んでいる都市
- email:アーティストのメールアドレス
- zip_code:郵便番号
上記のCSVをDataikuに入力していきます。
できました。
分析の流れ
今回の分析の流れは以下のように進めていきます!
- 仮説の策定
- データの統計量の整理・確認
- データの加工
- データの可視化&仮説検証
1.仮説の策定
何らかのデータを分析する際には仮説を立ててから分析を進めていくことが一般的です。
いわゆるアカデミックな実験室の実験においては、過去の文献等を紐解いた上での仮説策定が求められます。
しかしながら、今回のようなデータマイニング的な状況においては強い仮説を置くことが難しいので、今回はいわゆる一般論的な知識から仮説を4つ立ててみました。
①音楽ジャンルがロックのアルバムはMTVの評価が高い(MTV:1981年にアメリカで誕生した、24時間ミュージックビデオを放送する番組。ロック音楽のプロモーターであり影響力が強いと考えられる)
②レビューサイトや雑誌の評価が高いと、リリース後の最初の1ヶ月間の売り上げ枚数は多くなる。
③音楽配信の影響により、曲をストックせず早くリリースする傾向が進むと考えられるため、年が進むたびに1枚のアルバムあたりのトラック数は少なくなる。
④「アーティストの出身地の違い」や「アーティストの主な役割」、「アーティストの誕生年」等によって評価されるメディアが違う。
結構ざっくり立ててみましたが、こちらの仮説を仮置きして分析を進めていきます。
2.データの統計量の整理・確認
続いて、データの基本統計量を整理・確認していきます。ここでいう基本統計量とは、各カラムのレコード件数や、欠損値、数量データの平均値および分散、最小値、最大値のことを指します。
本格的に整理する際は、表などにしてまとめておくとよいのですが、今回はDataikuの機能で可視化されているものをざっと見ていきます。
2.1.「albums.csv」について
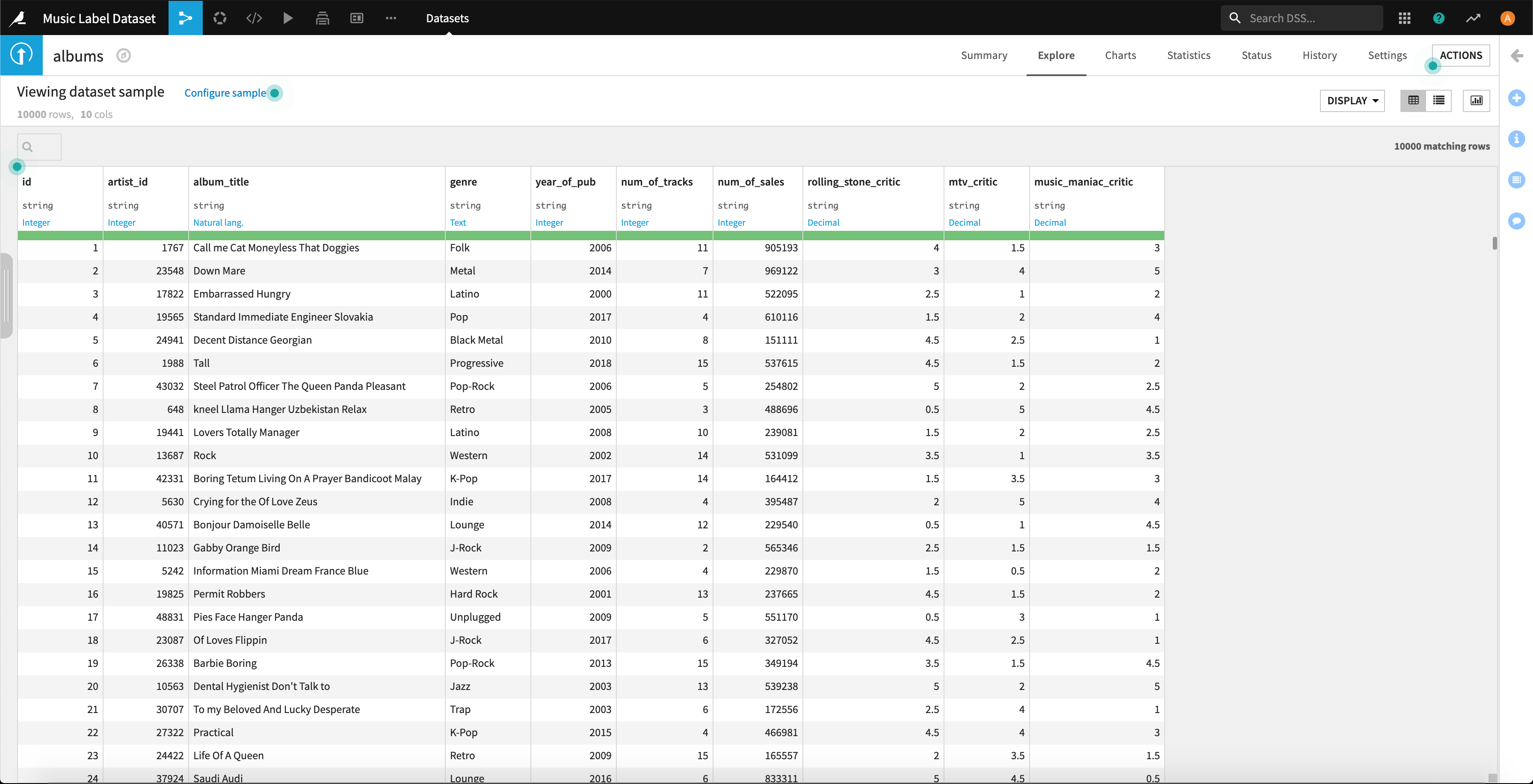
まず、「albums.csv」のデータセット画面を見てみます。
欠損値や型違いのデータがあると、各カラムの帯に赤が交じるのですが、このデータセットは綺麗ですね。。
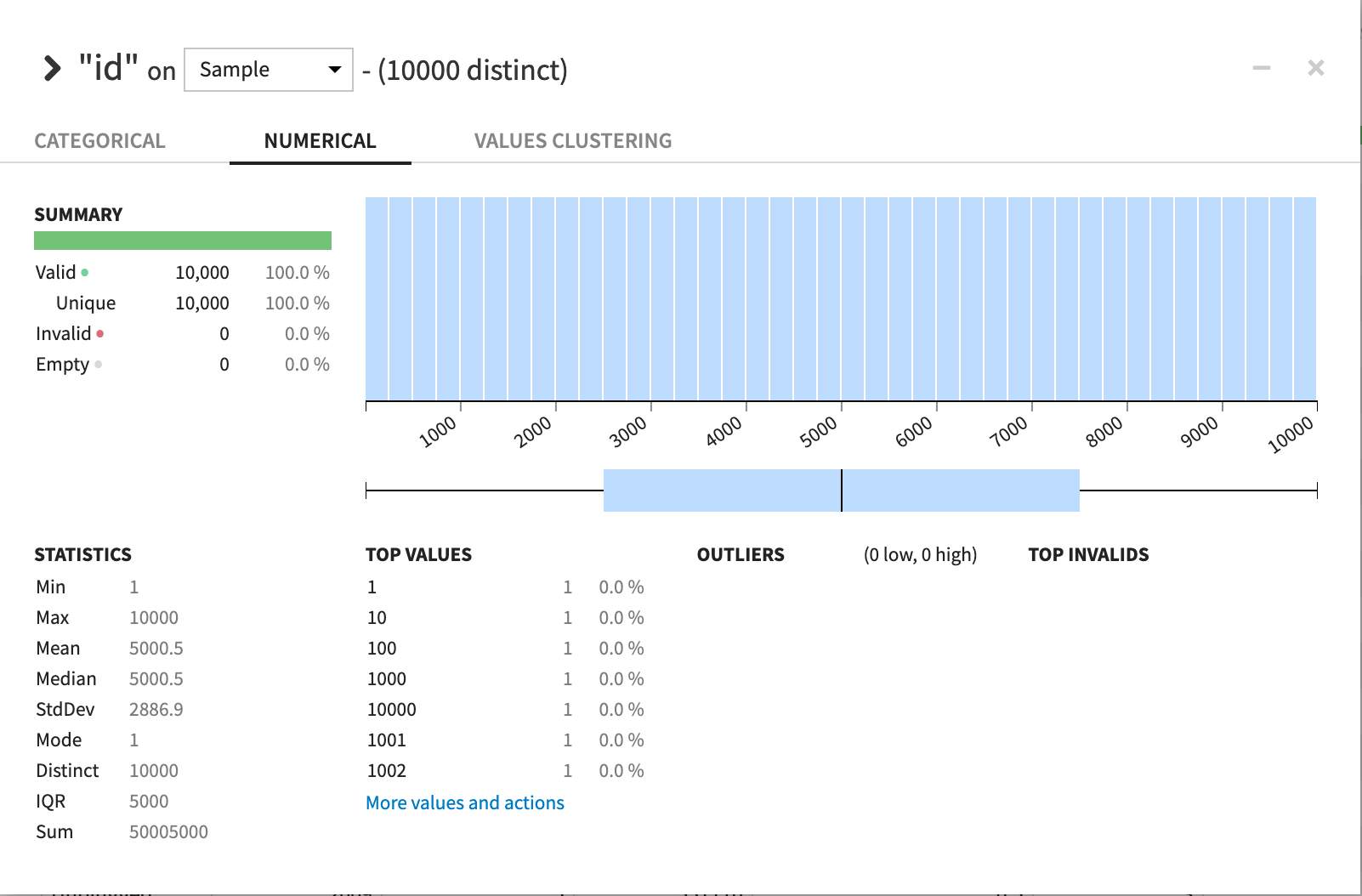
各カラムの統計量を「analyze」コマンドを使って見ていきます。
アルバムIDもすべてユニークな値になってます。レコード数は10000件ですね。
音楽ジャンルは「indie」が1位、「pop」が2位、「Rap」が3位です。それぞれの個数も出てますね。
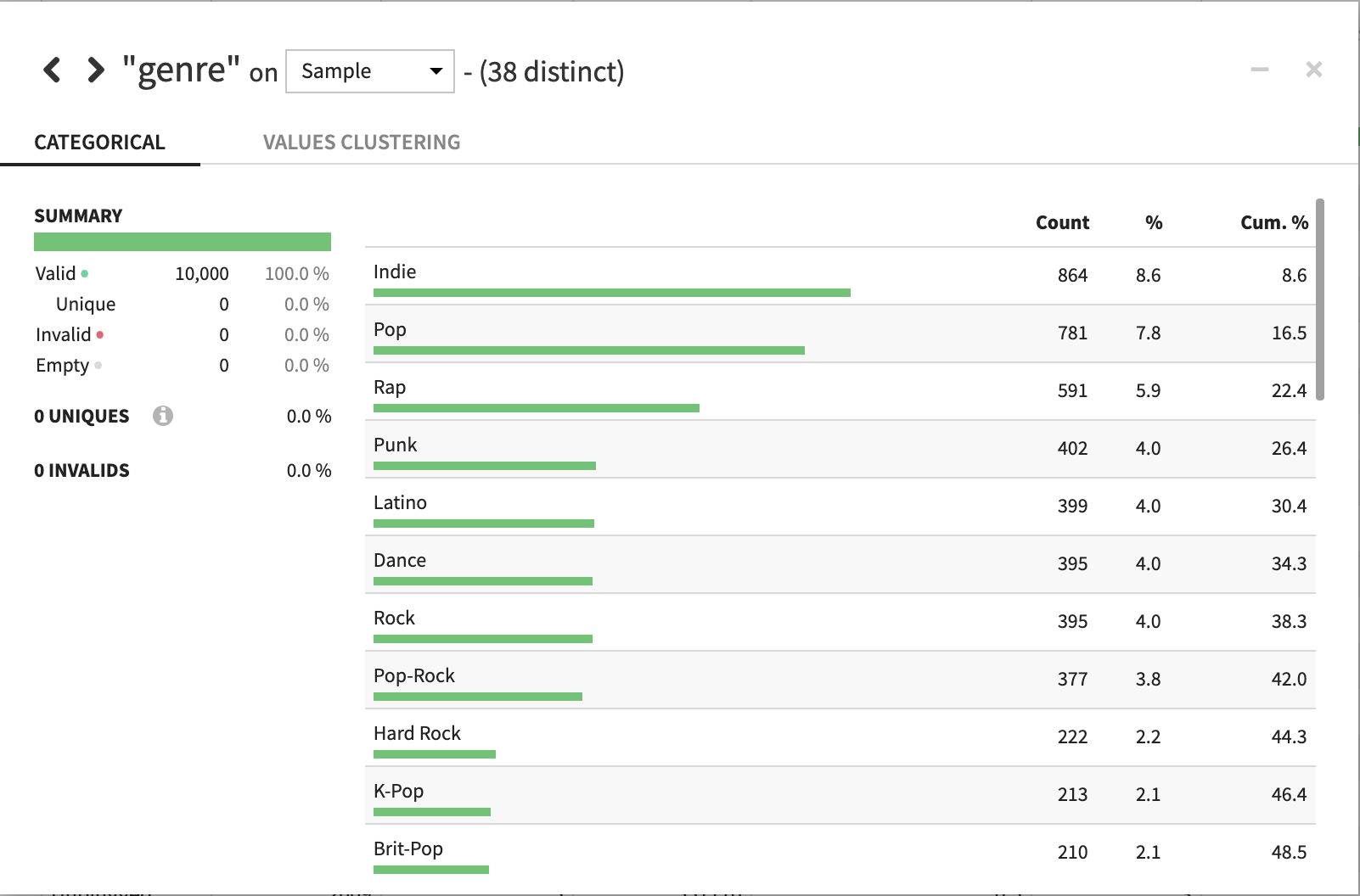
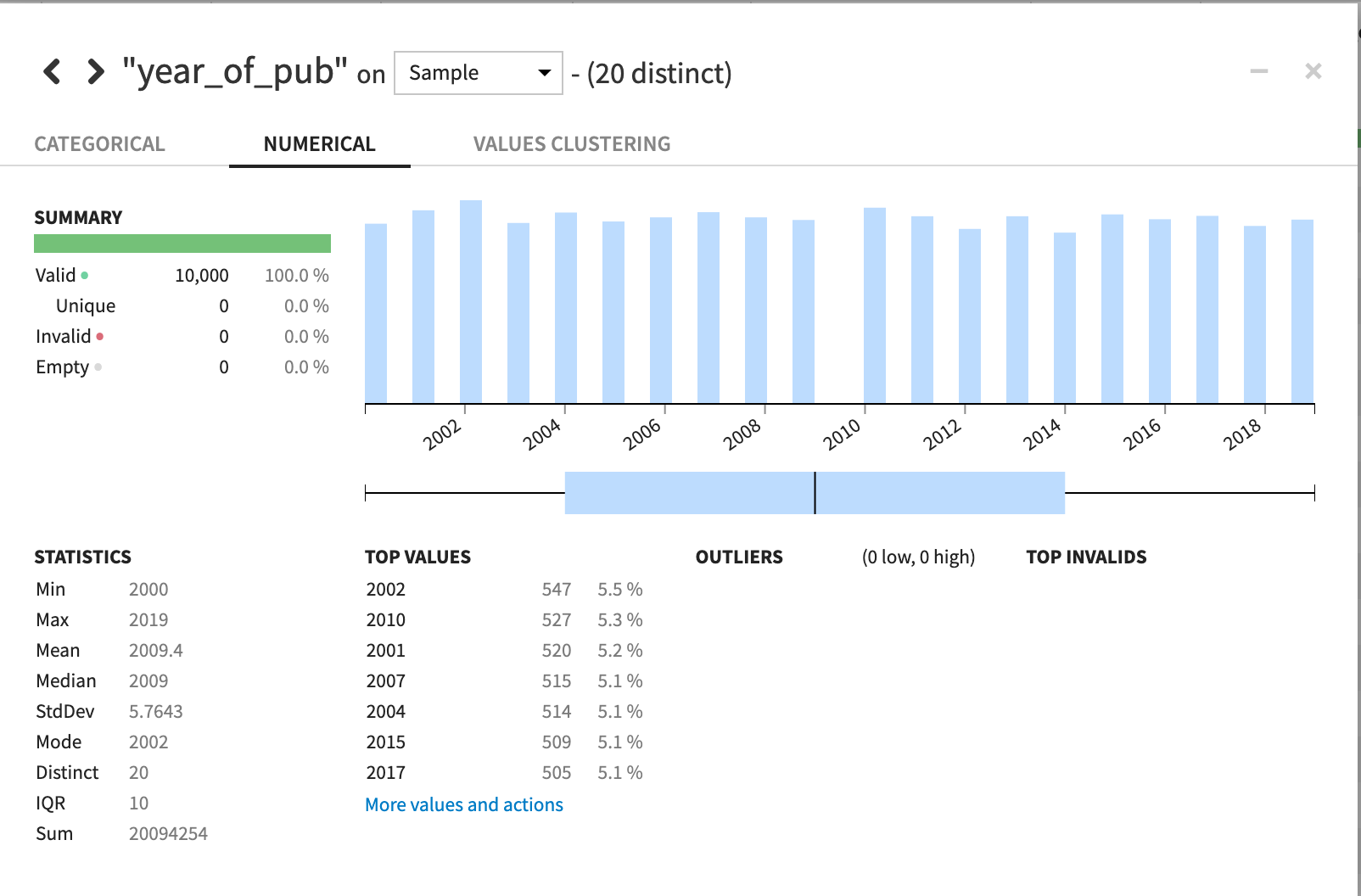
年ですが2000年から2019年の間のデータですね、各年度それぞれ500件前後のデータが入っているみたいです。
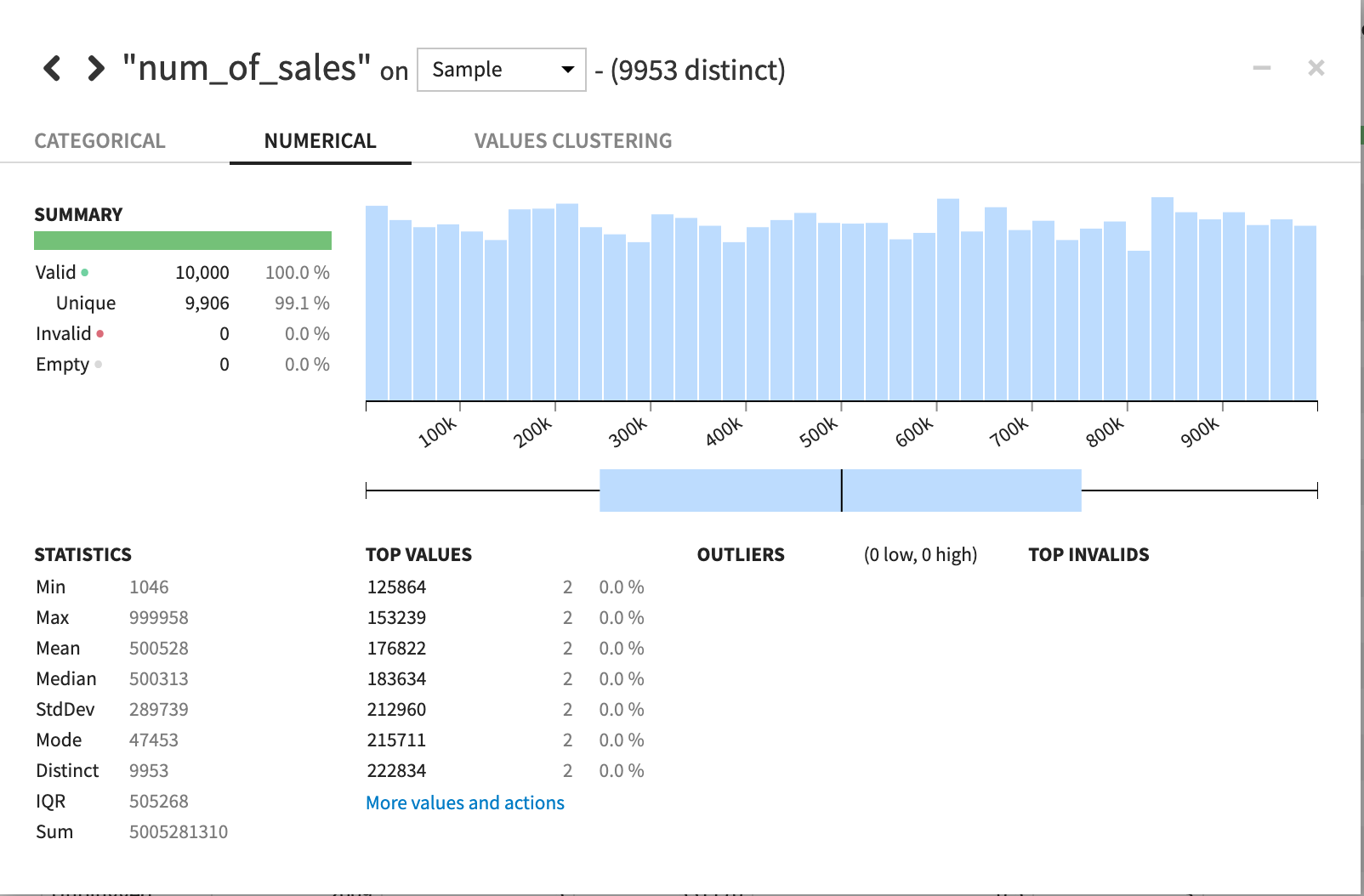
売上枚数は、平均500313枚、標準偏差が289739、最小値1046枚、最大999,958枚ですね。
分布が真っ平らなことや数字からもばらつきが大きいことが見て取れますね。
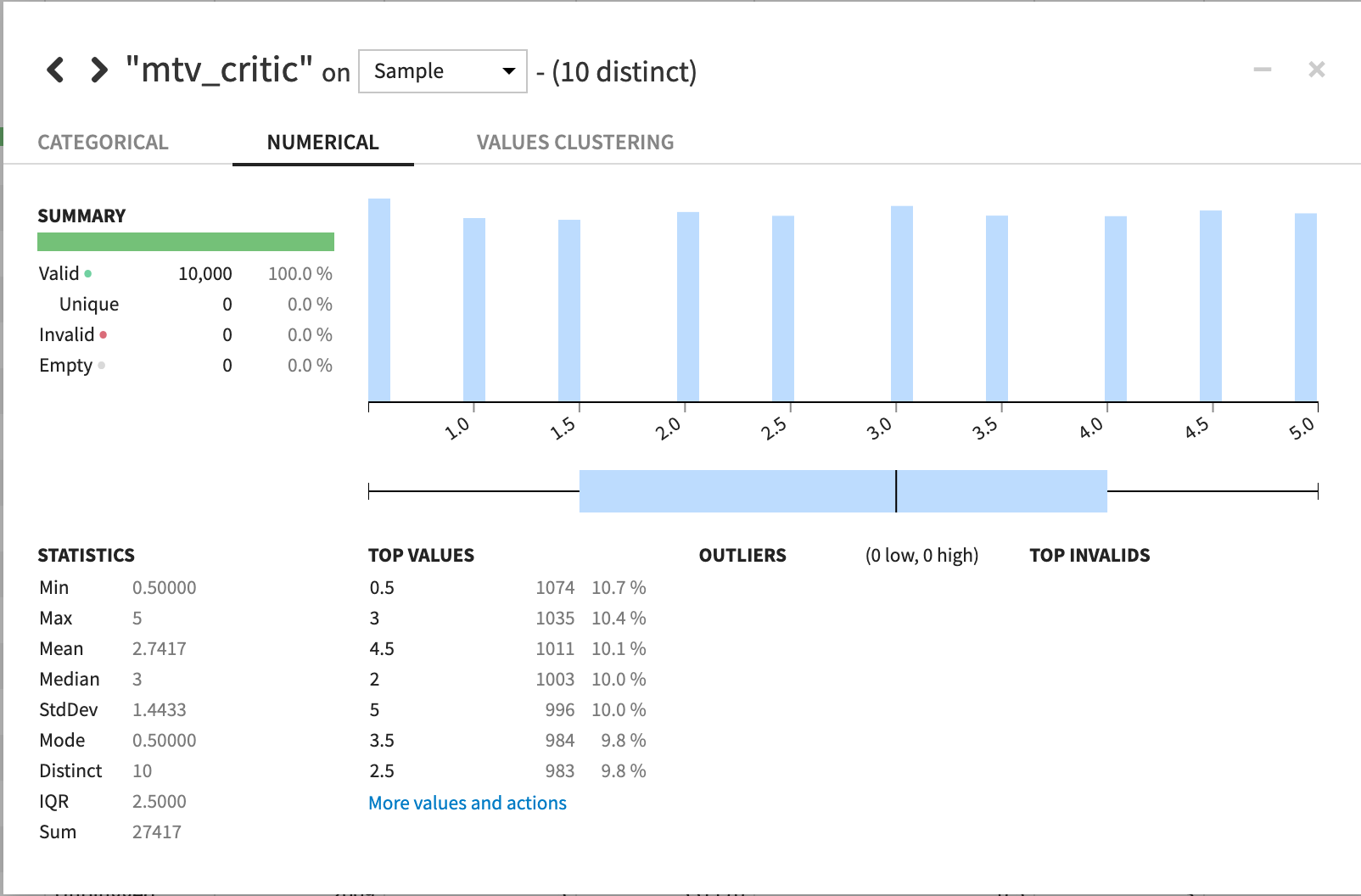
MTVの評価も、10段階評価(0から0.5刻みで5まで)で平均値が3、と偏りのない評価がされていますね。
2.2.「artists.csv」について
つづいて、「artists.csv」のデータセット画面を見てみます。
「art_name」で空白が、「country」と「zip_code」で形式違いデータがいくつか入っていますね。
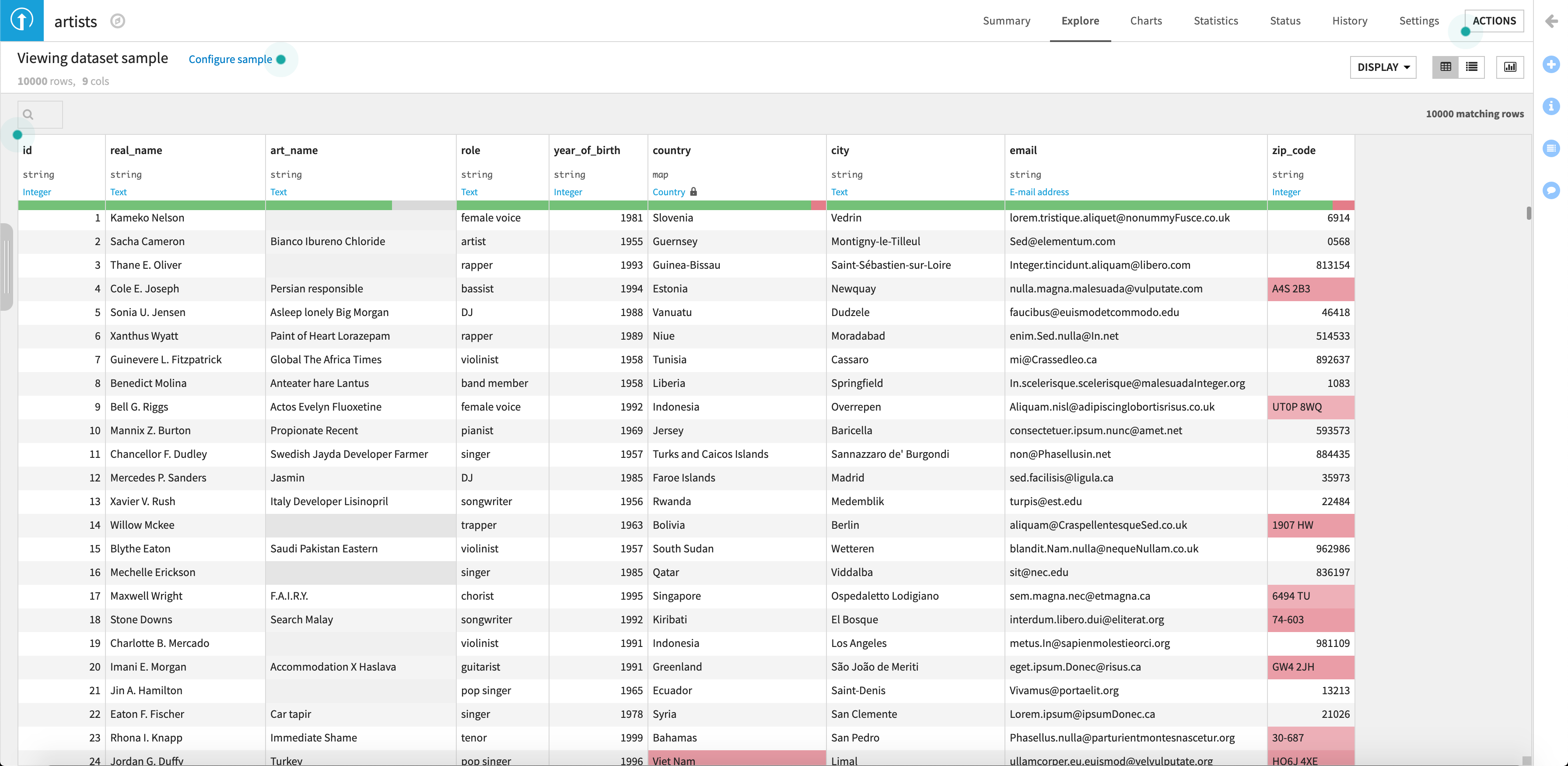
芸名を使っている人は7割程度みたいです。
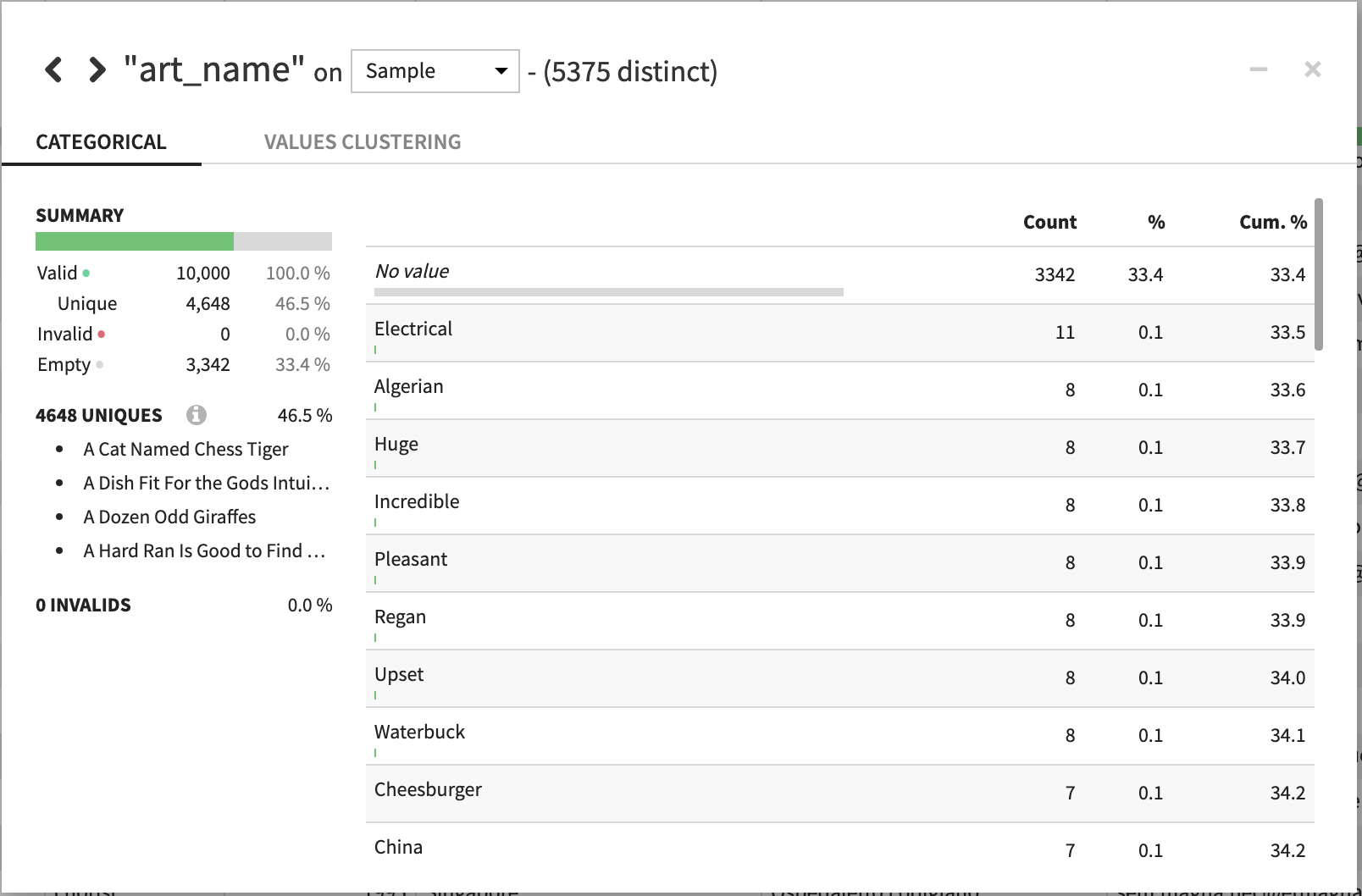
ラッパーが1割を締めています。ギタリストよりもドラマーが多いのはなぜでしょう。。。
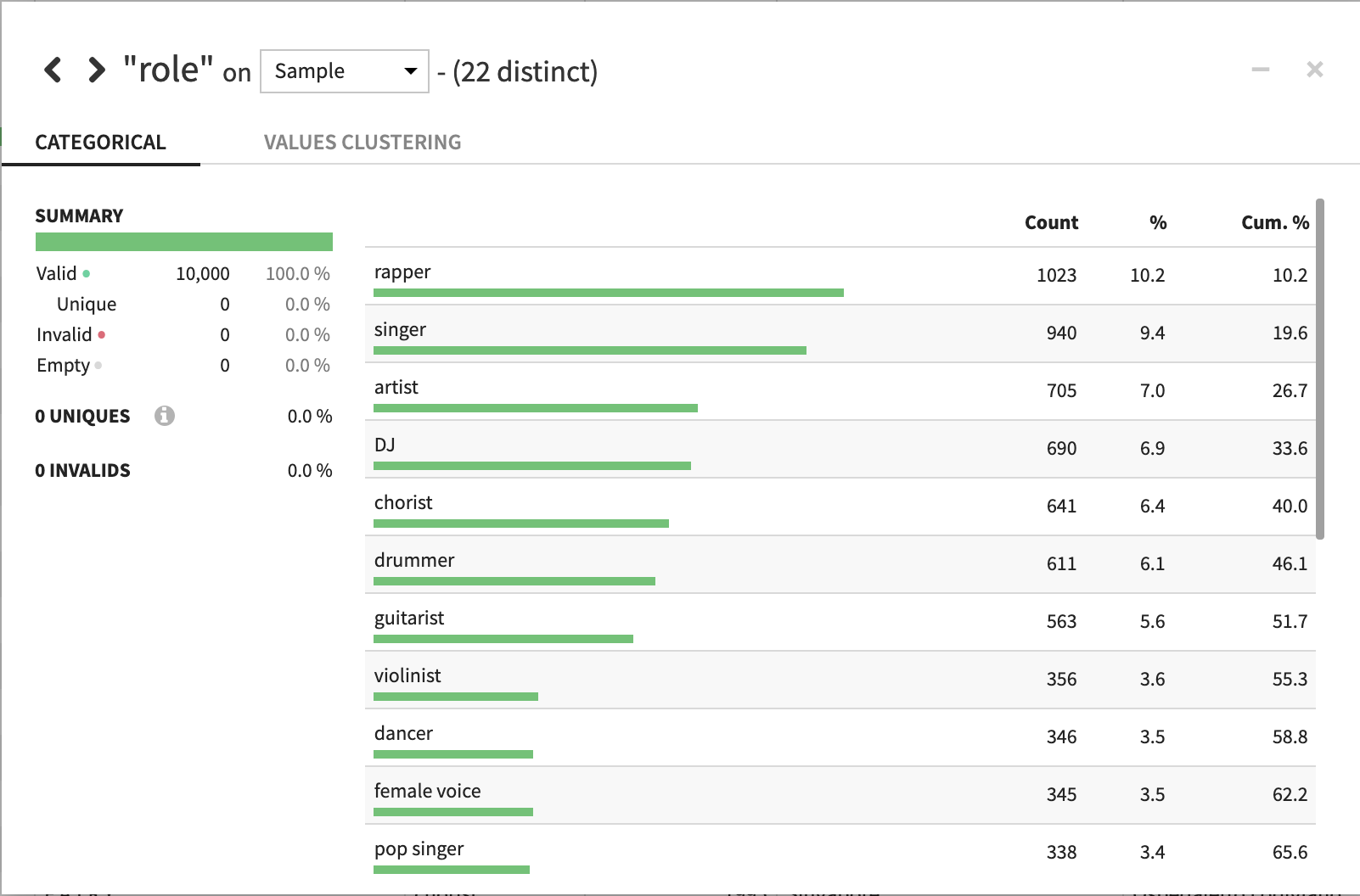
「country」はDataikuに登録されている国以外は、invalid(型式違い)として認識されるみたいなので、形式を「country」から「text」に変更しておきます。
以上が、データの整理・確認でした。
3.データの加工
つづいて、データを分析しやすい形に加工していきます。
3.1.結合処理
今回、「アーティストの出身地の違い」や「アーティストの主な役割」、「アーティストの誕生年」等によって評価されるメディアが違う。」といった仮説を立てました。
上記の仮説を検証するためにはメディアの評価についての情報が入っている「albums.csv」と
アーティストの出身地の情報が入っている「artists.csv」の2種を結合してあげる必要があります。
Dataikuでは、結合処理をSQLを書かずとも簡単に実行できるので、この機能を使って上記2種のデータセットを結合します。
Dataikuの機能の「JOIN」を使うと2つのデータセットを簡単に結合できます。
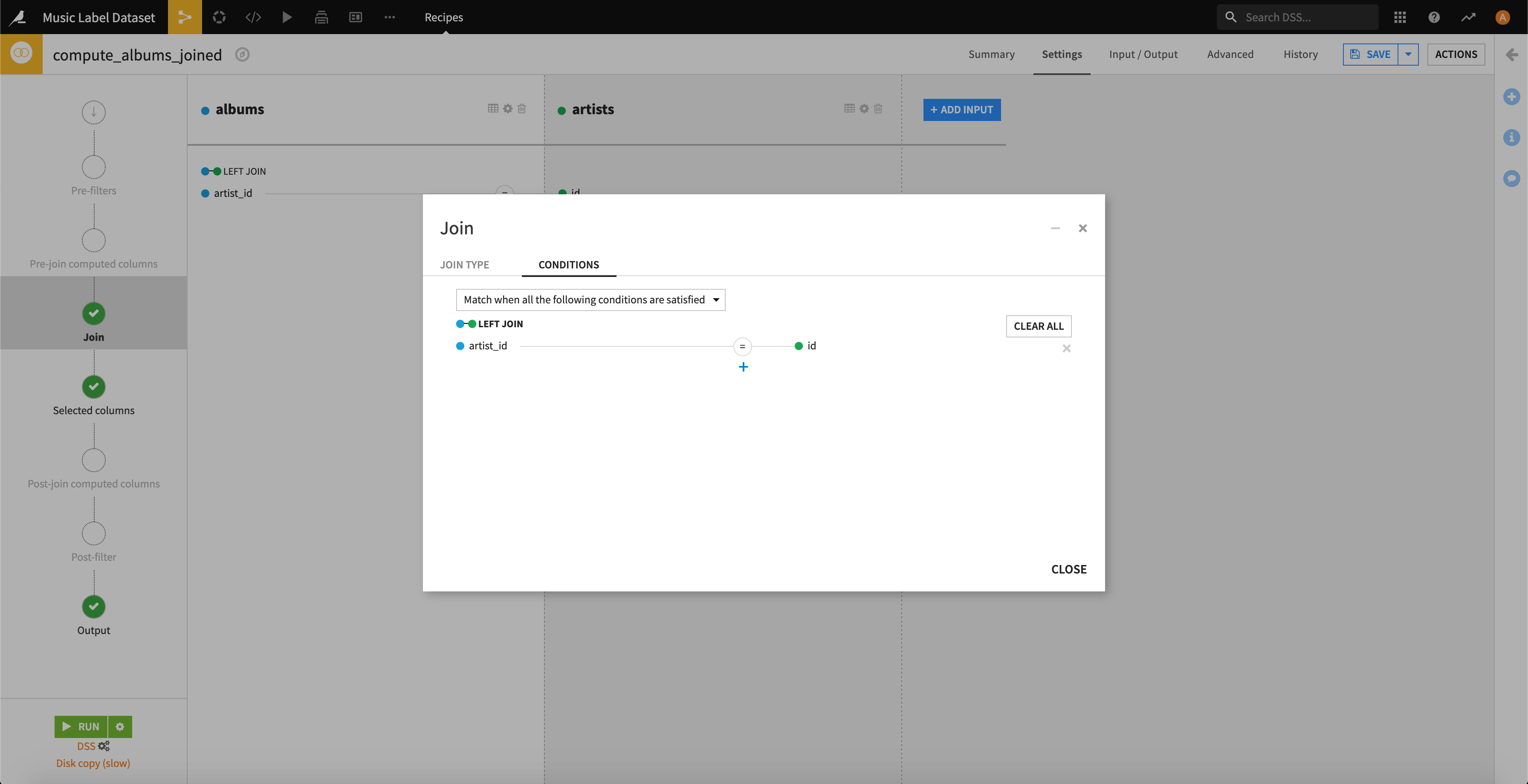
今回は、「artists.csv」の「id」は「albums.csv」の「artist_id」を参照している関係にあるので上記の2種の結合列同士で等結合させます。
結合後のカラムはこんな感じです。
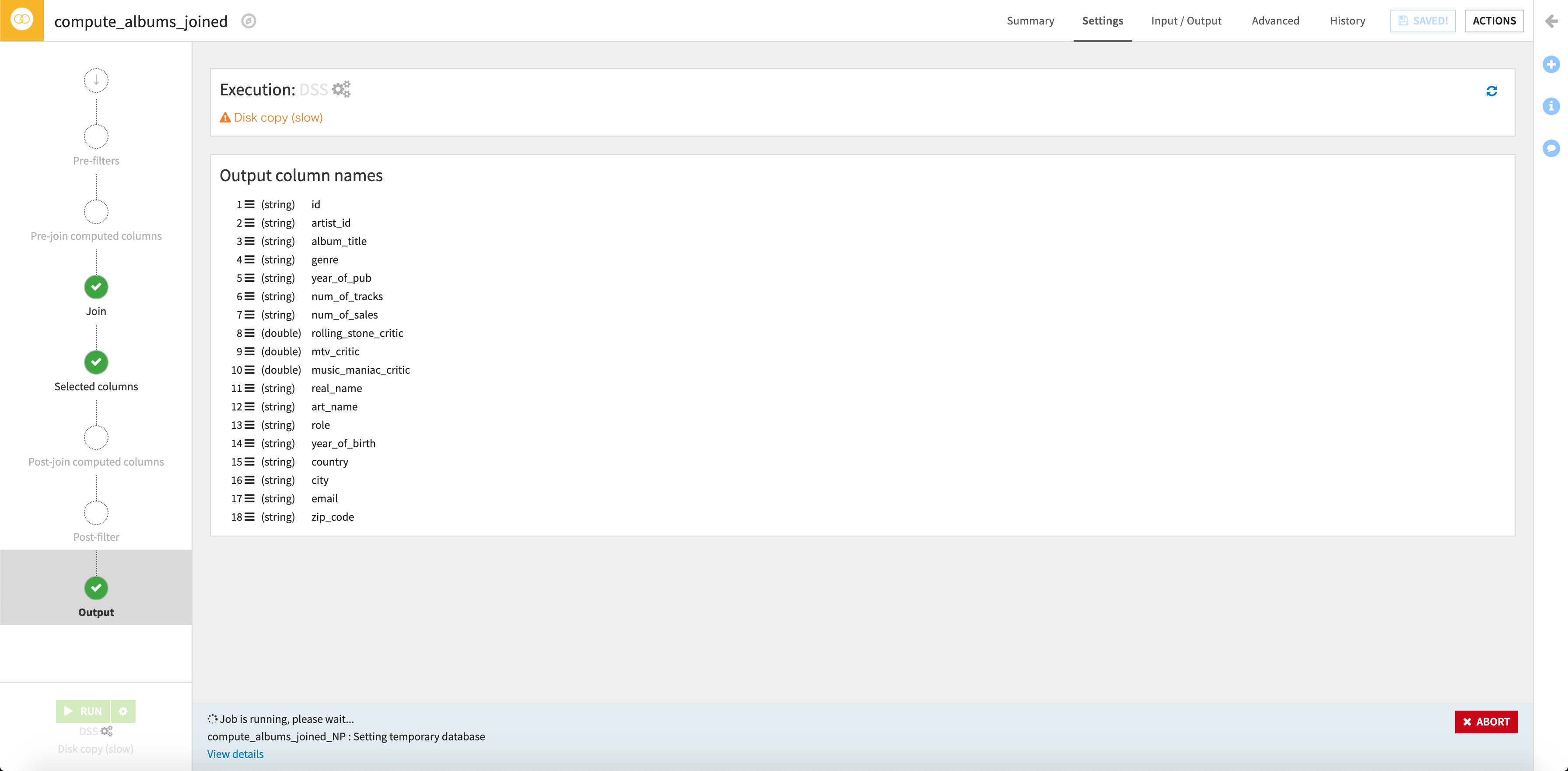
できました。。
ちゃんとカラムが結合されています。
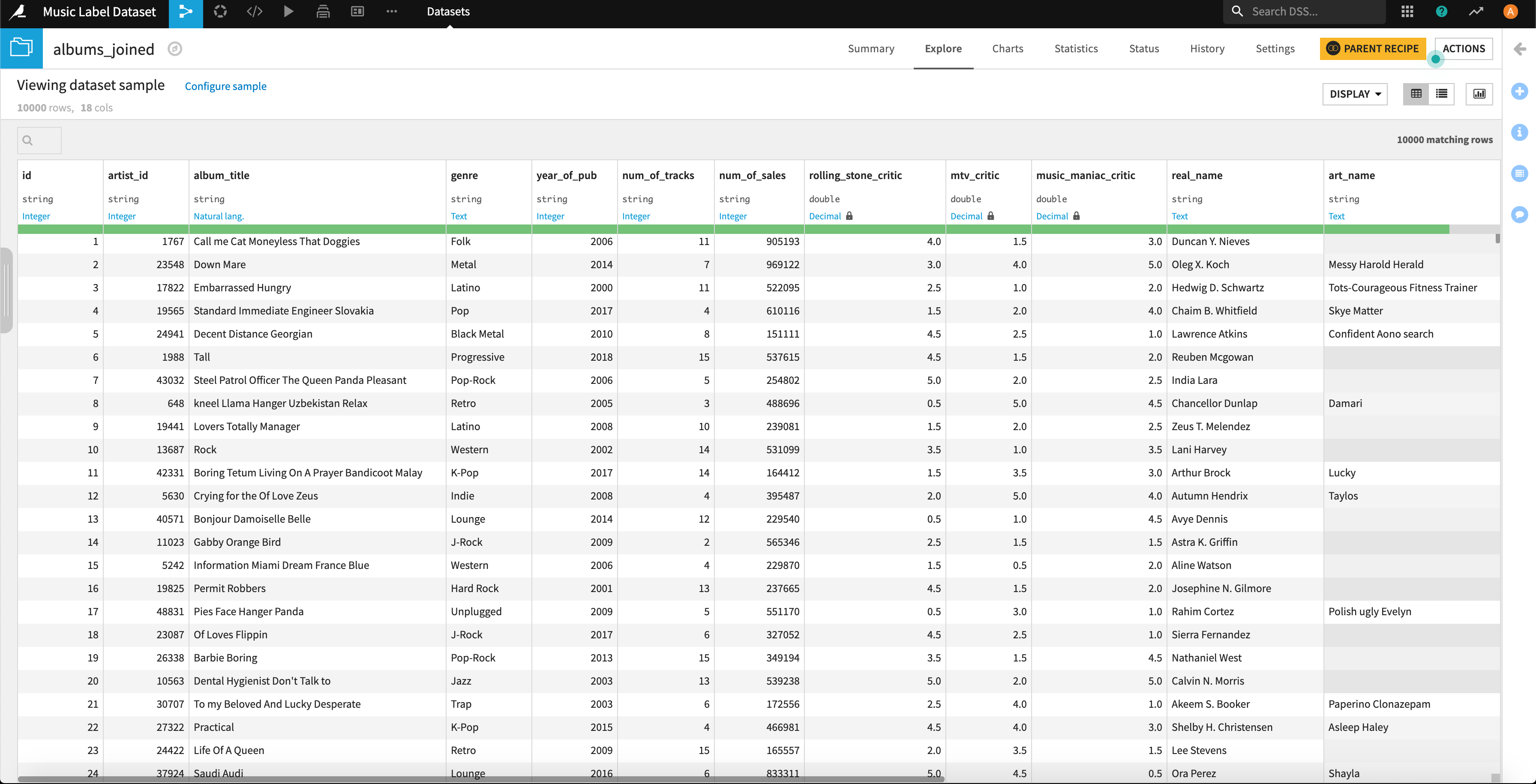
3.2.カラムの追加処理
続いては、「recipes」機能を使ったカラムの追加処理をやってみます。
3.2.1.アルバムデータの加工
今回「音楽配信の影響により、曲をストックせず早くリリースする傾向が進むと考えられるため、年が進むたびに1枚のアルバムあたりのトラック数は少なくなる。」という仮説も立てました。
上記の仮説を検証しやすくするために、今回は約10年区切りでの比較を実施しようと思います。
こちらについて、2000年から2009年までを「1」、2010年から2019年までを「2」と変換してあげることで可視化や統計処理をしやすくしてみます。
これについてはDataikuの「recipes」機能の「Formula」を使うと簡単にさっと書けます。関数等は公式リファレンスをご参考ください。

簡単なif文をさくっと書き、新しいカラムを追加します。
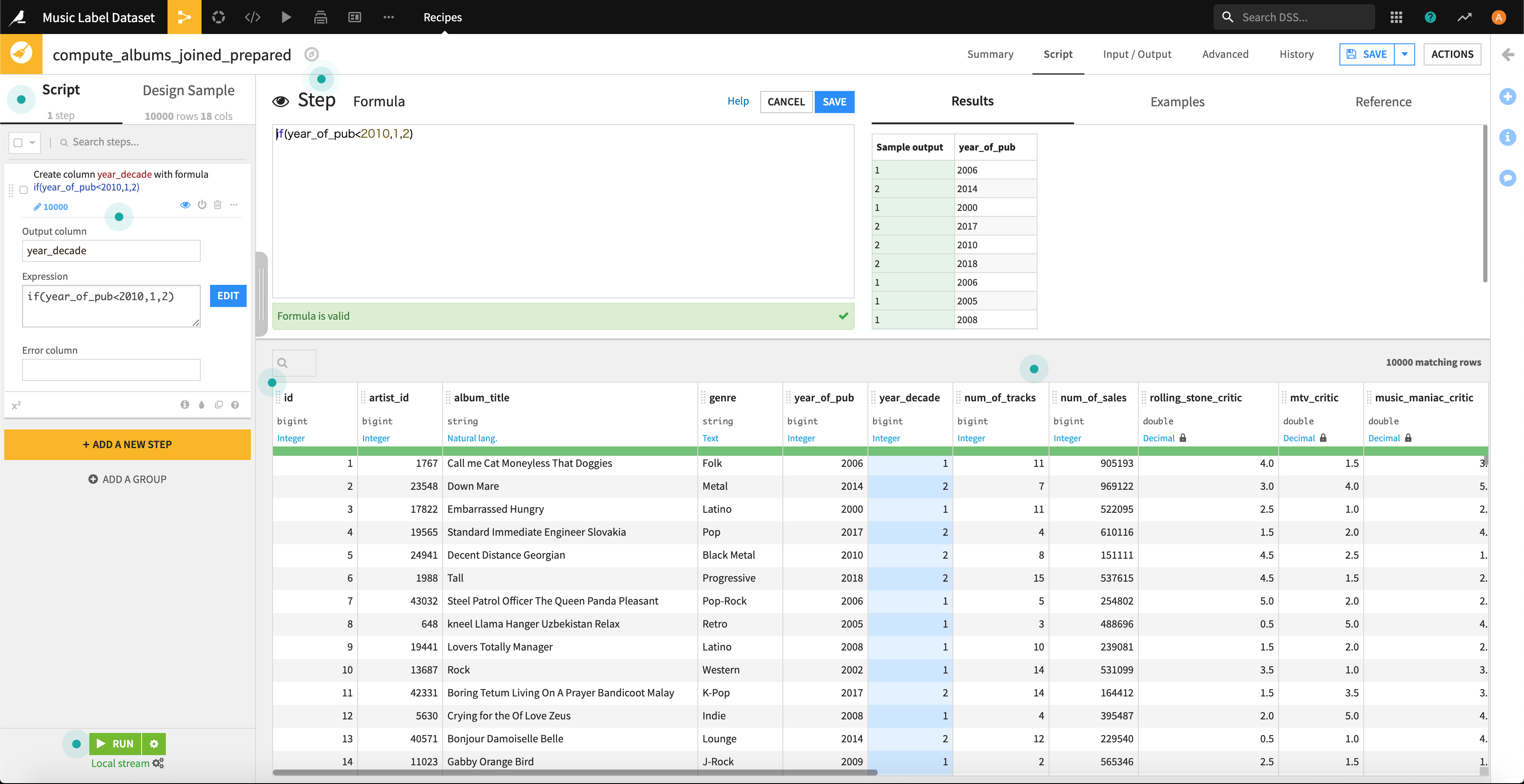
ちゃんとカラムが追加されています。
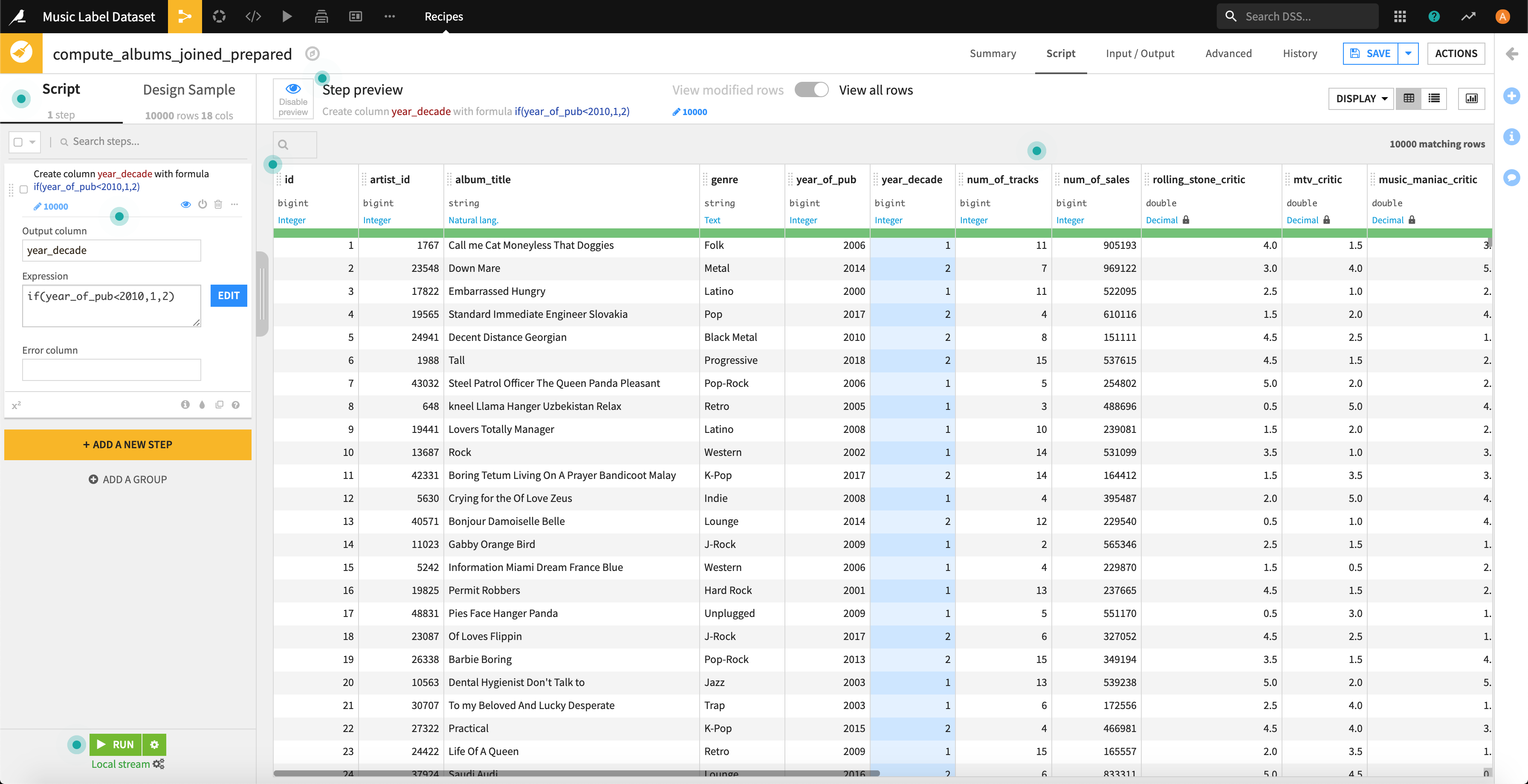
3つの評価(「rolling_stone_critic」「mtv_critic」「music_maniac_critic」)の総合得点として、左記3種の得点の平均値も新たな項目として抽出しておきます。
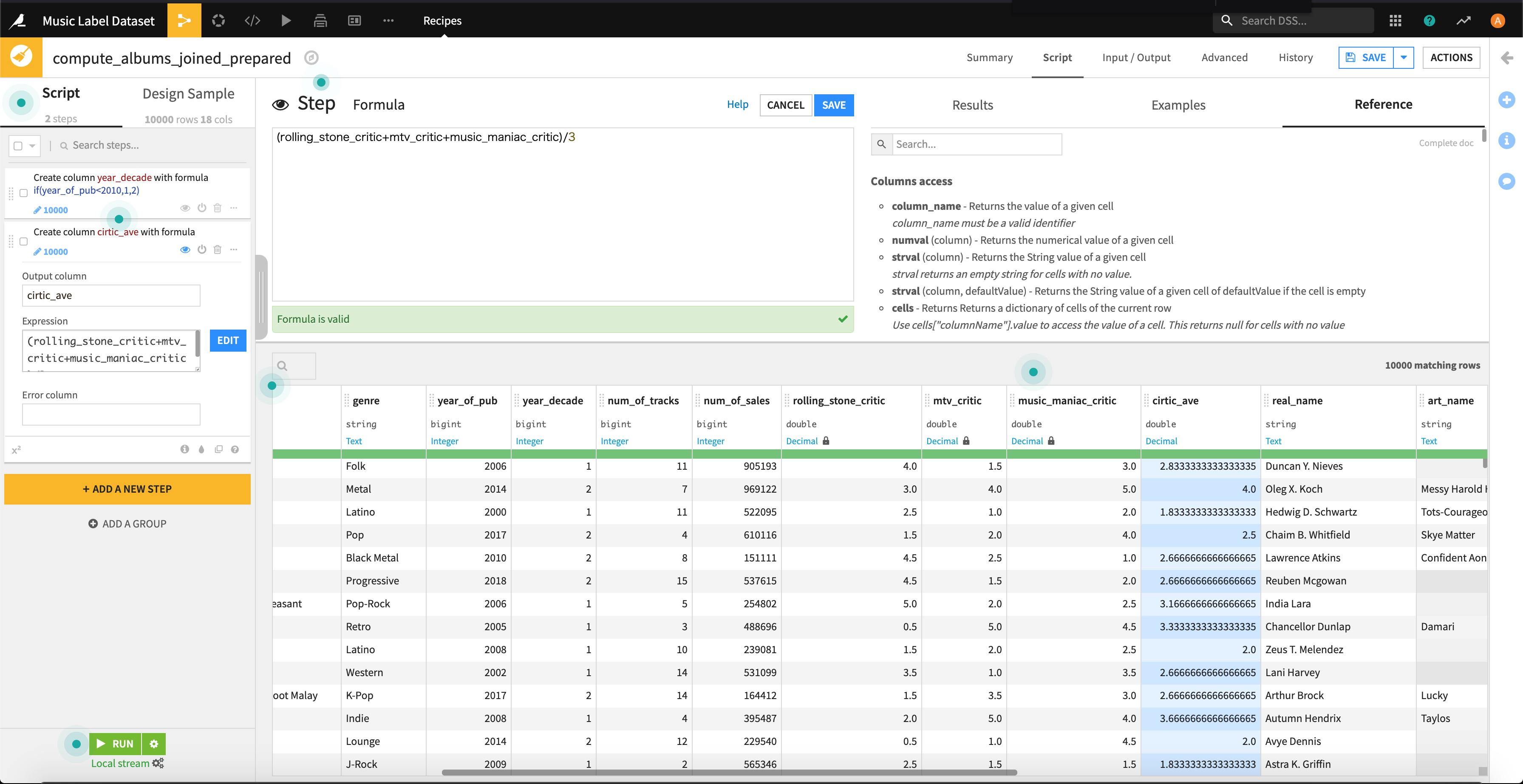
はい、出来上がりです。
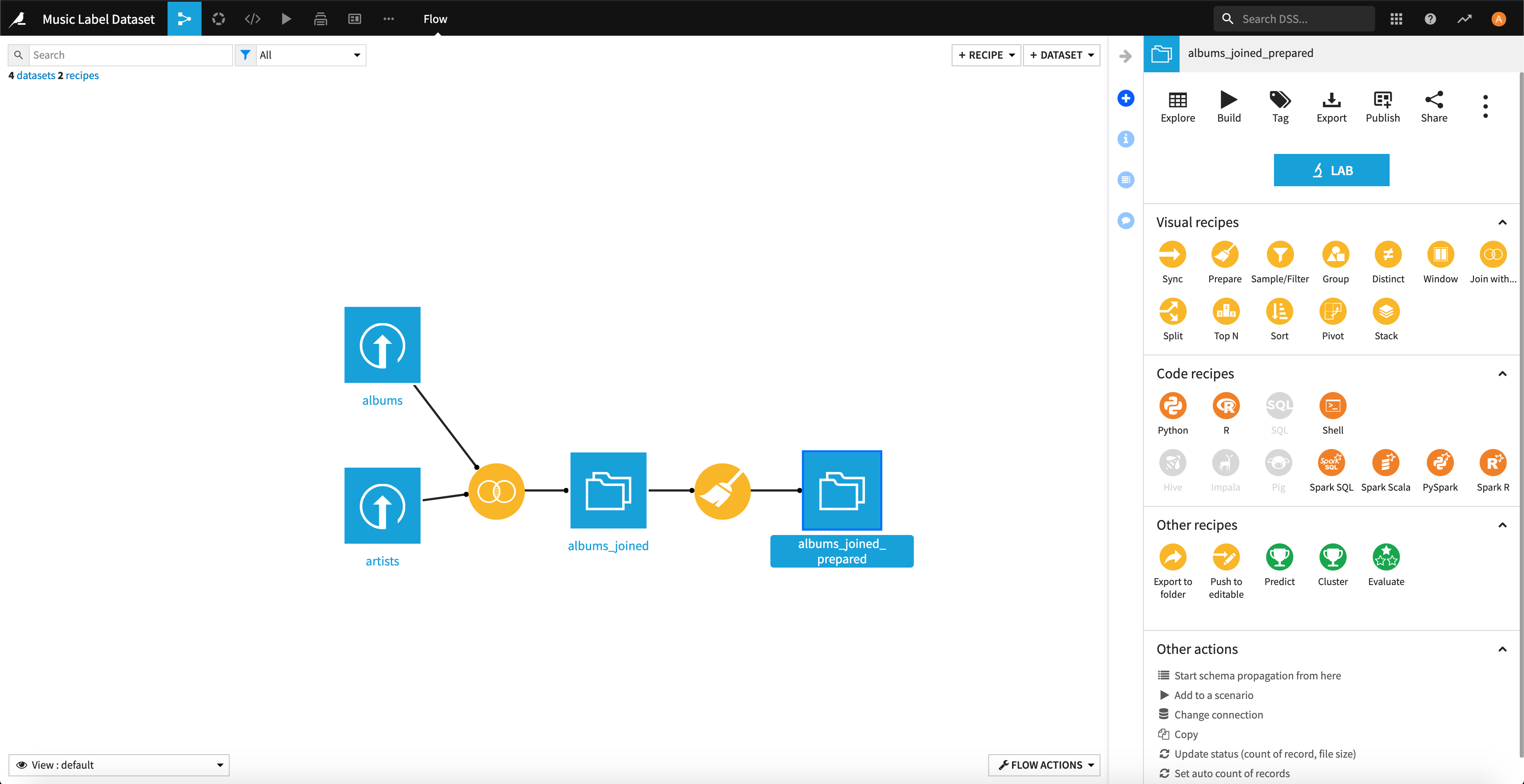
3.2.2.アーティストのパーソナルデータの加工
「アーティストの出身地の違い」と「アーティストの主な役割」についてはカテゴリカルなデータですので、要素が多くなってしまうと説明変数が多くなってしまうため、それぞれ要素の要約することで変数を少なくしていきます。
出身地の項目の「country」については、Dataikuの機能を用いて国名から緯度・経度を抽出し、この値を使って距離の近さでクラスタリングすることで要約してみようと思います。
「recipes」機能の「Geocode」を使うと外部APIを使い、緯度と経度の項目を追加できるのでこちらを使ってみます。
今回は、MapQuestOpenAPIを使います。※別途ID登録が必要です。
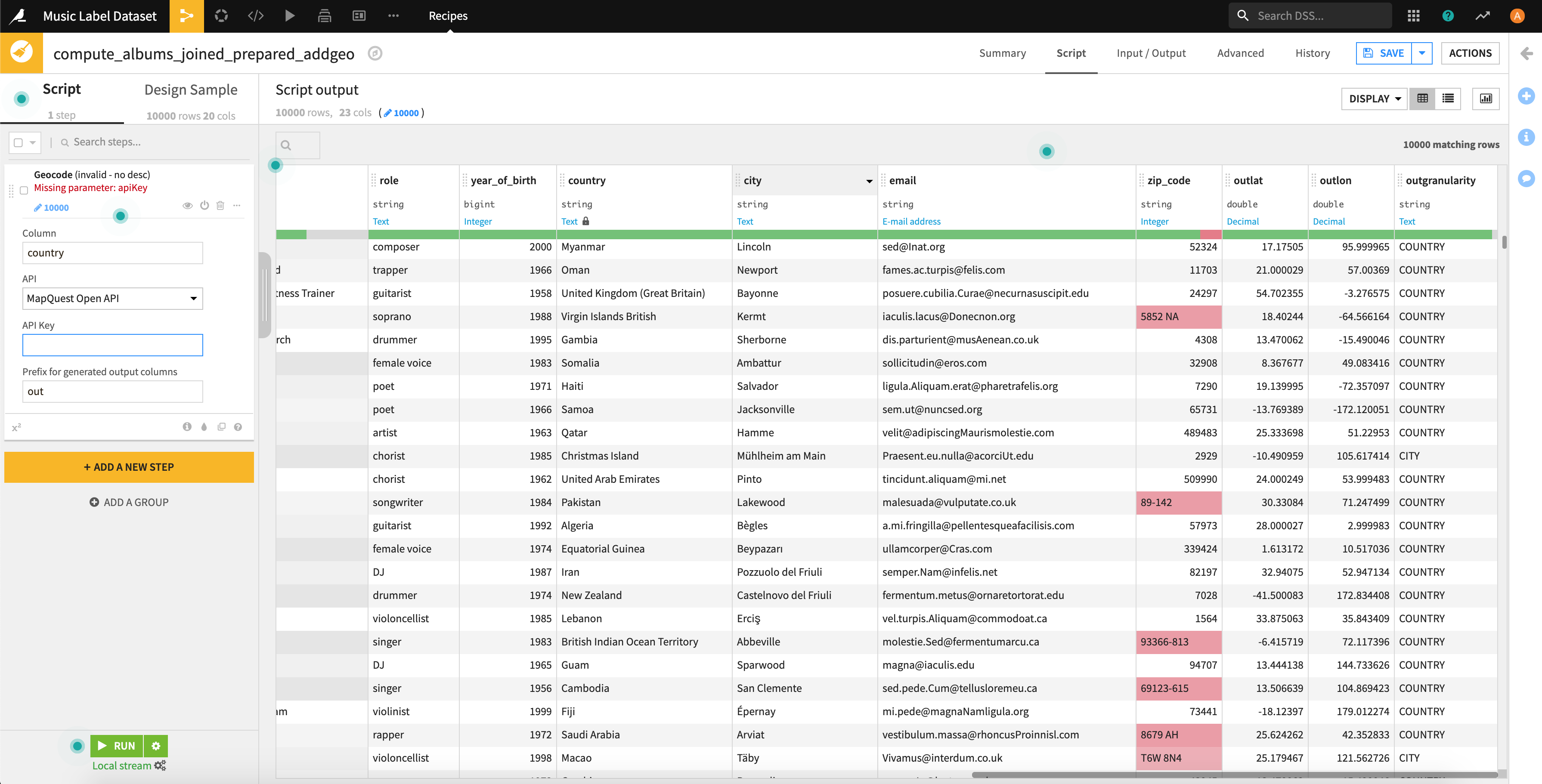
さらに「GeoPoint」でマップデータに変化しておきます。これをしておくことで、「charts」で地図を使った可視化ができます。
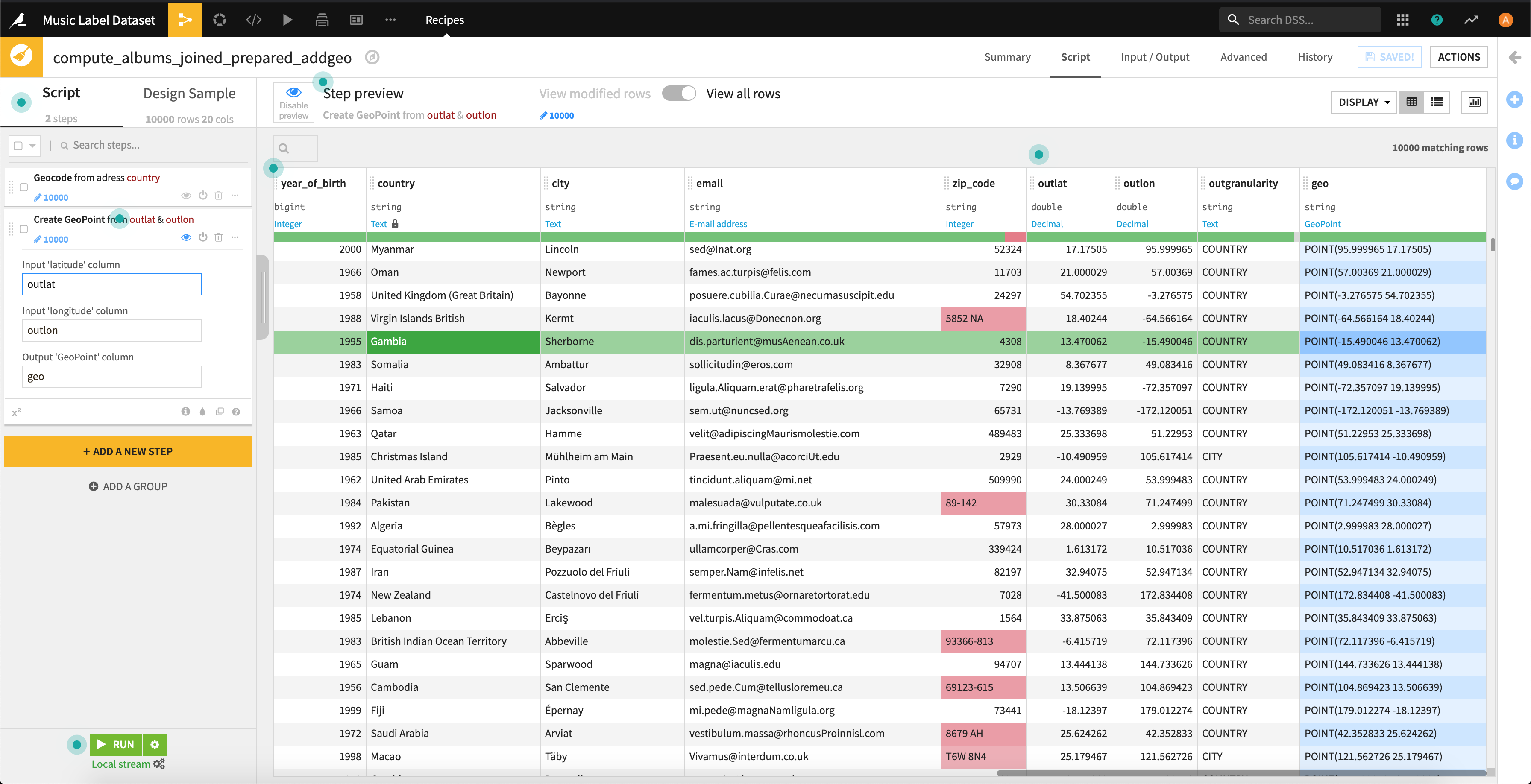
こんな感じです。
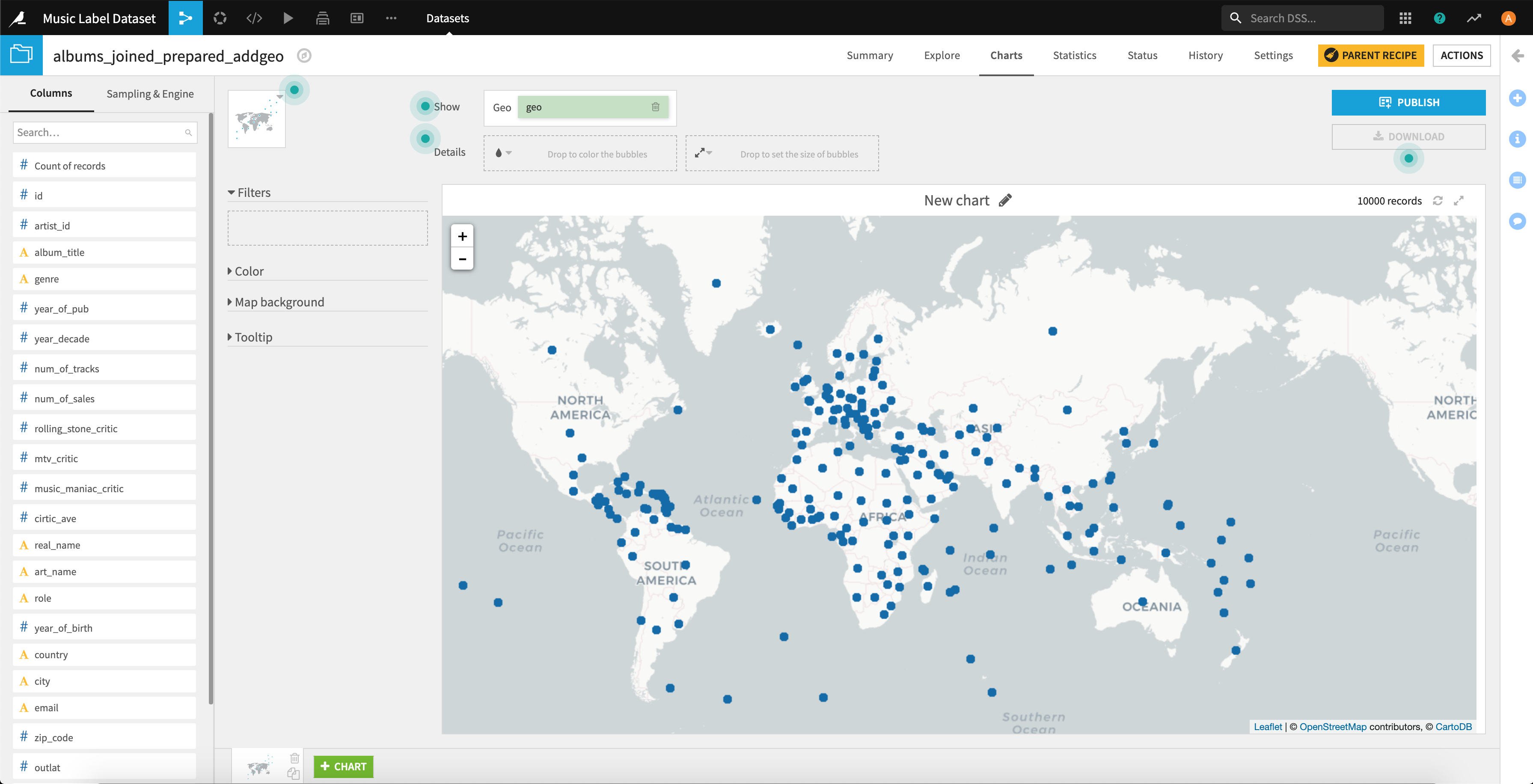
それでは続いてマップのクラスタリングを実施します。
データセットを選択し、Virtual analysisで分析を進めます。
今回は、概ね大陸ごとに分けられるように要約したいので、GMM(混合ガウスモデル)でクラスター数を増減させながら、うまく当てはまるように分類していきます。
項目も、緯度と経度の2変数のみにします。
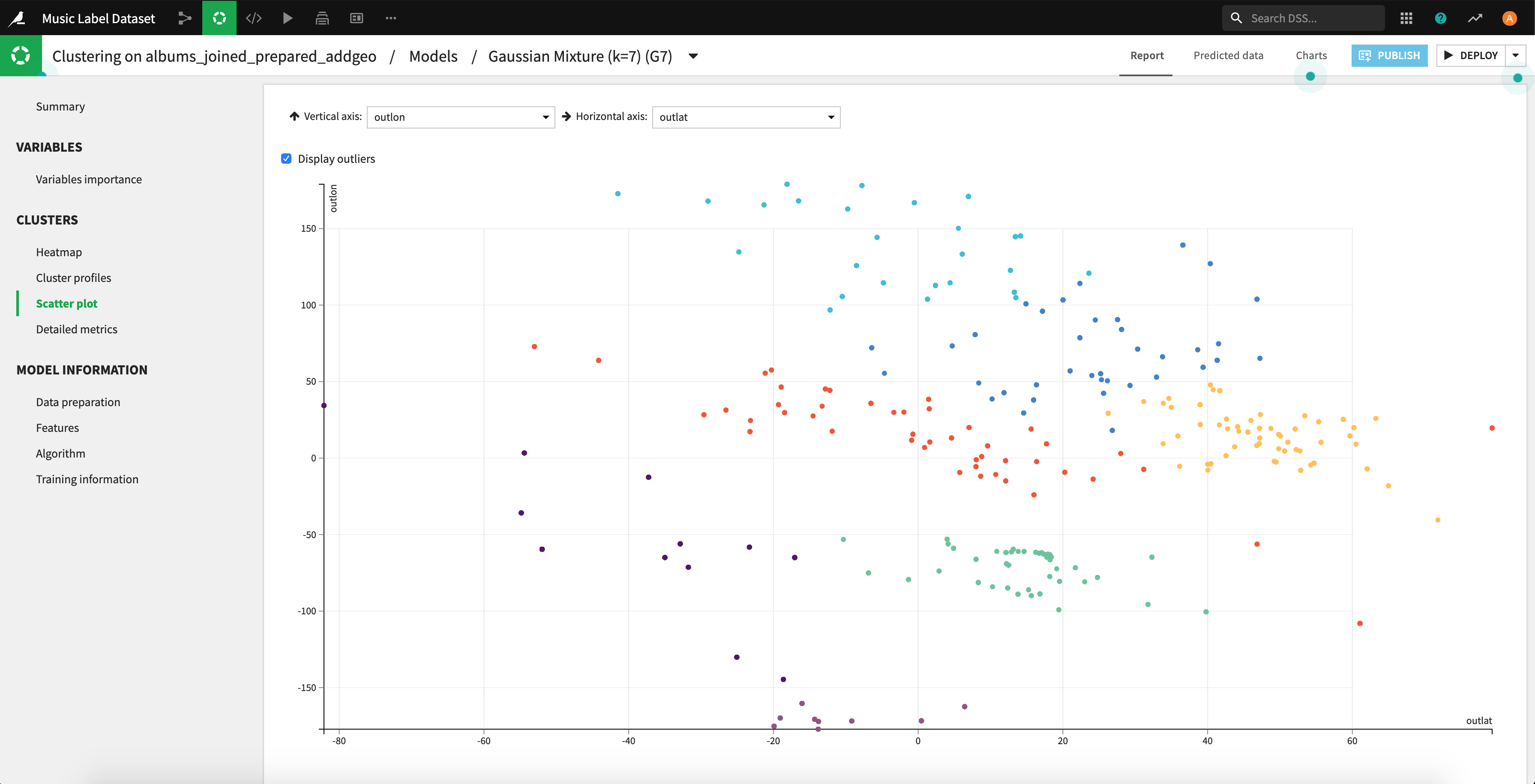
クラスタを散布図で見やすくカラフルに可視化してくれます。
データセットに書き出します。
ちゃんと項目が追加されています。
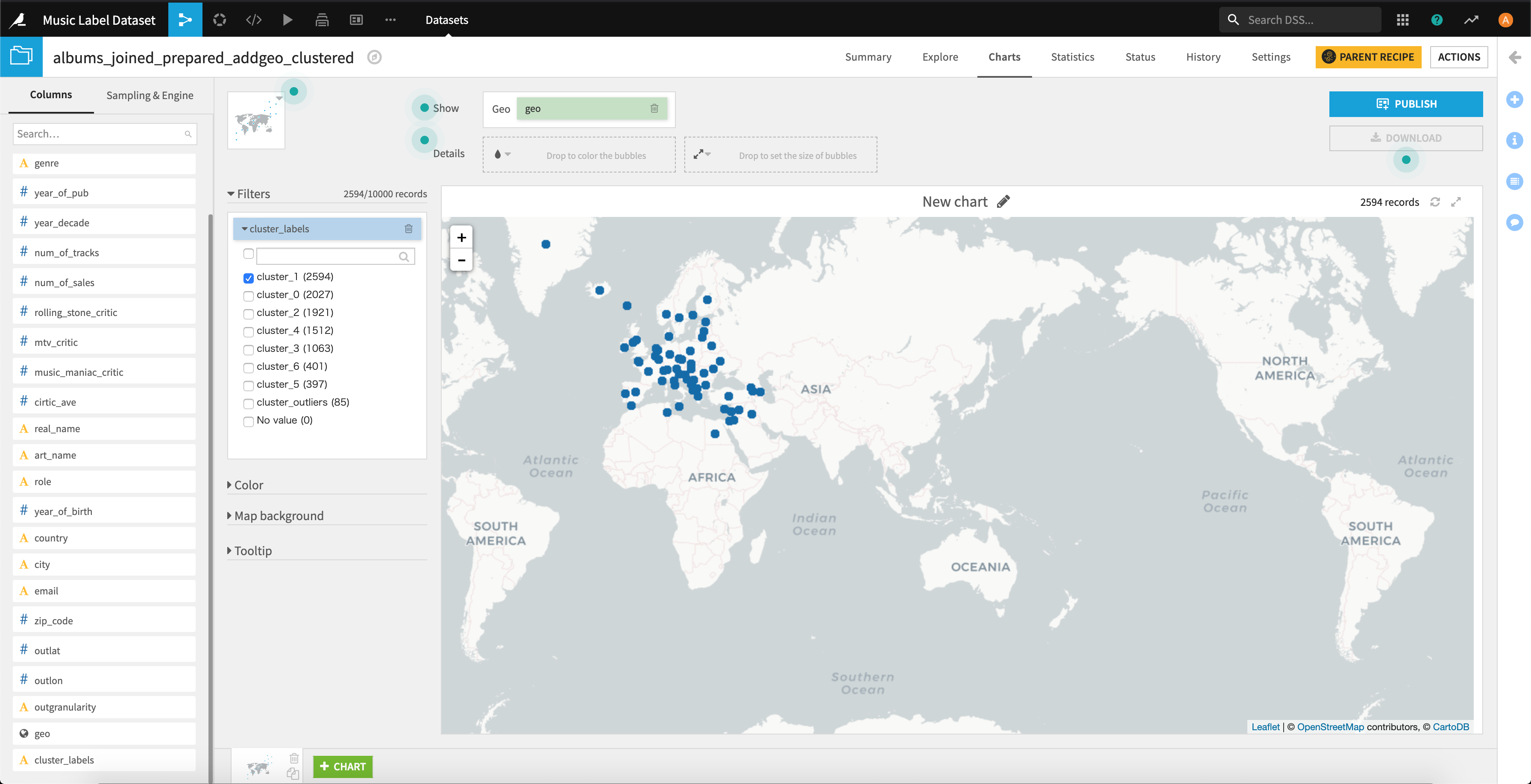
地図にプロットして、抽出されたクラスタでフィルターしてみましたが、概ねうまくいってそうです。
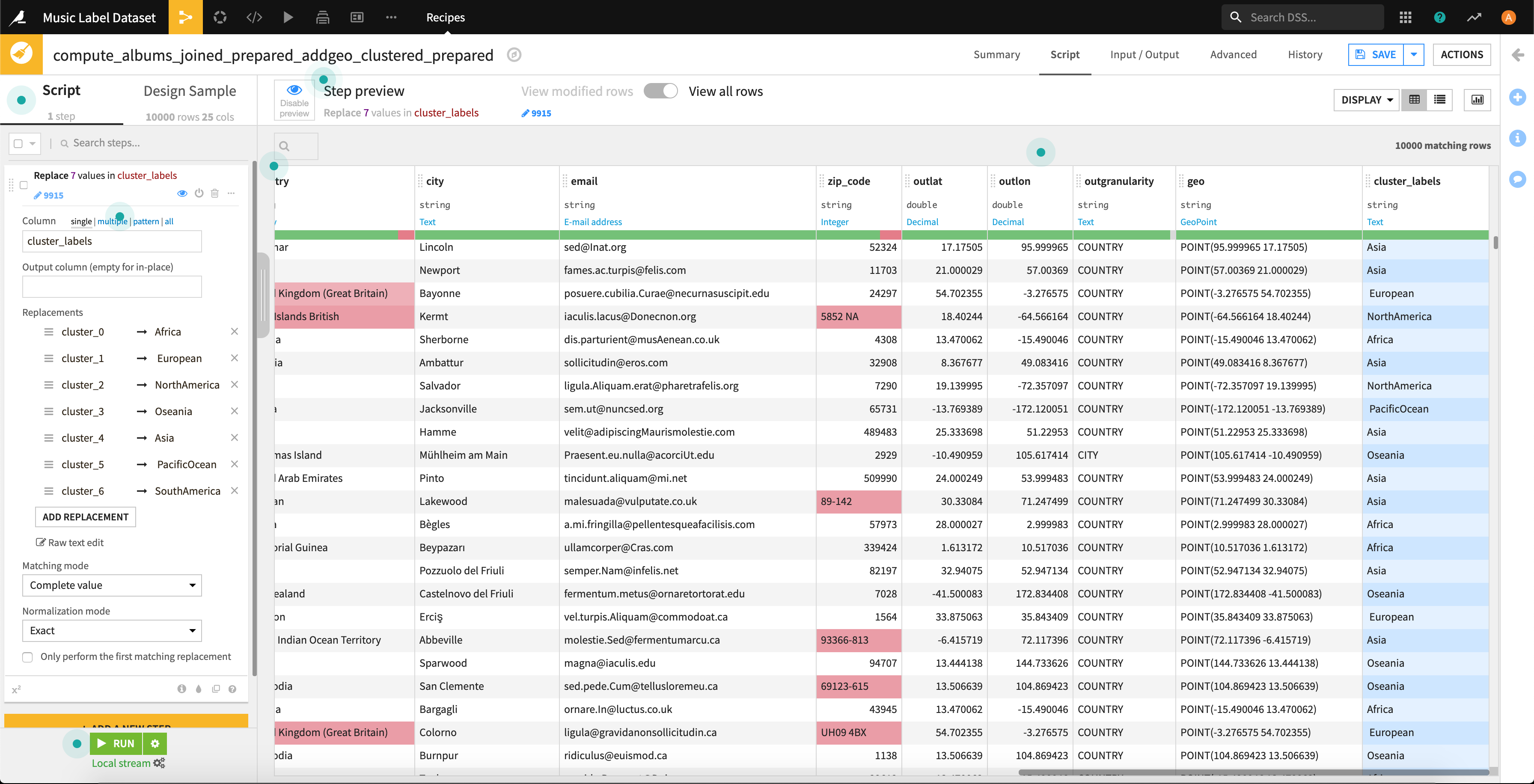
それぞれの大陸に名前を変更して終了です。※太平洋のど真ん中にある島国は「PacificOcean」としました。
次は、アーティストの主な役割の「role」を要約していきます。
これについては筆者の独断と偏見で「Singer」「Player」「Creator」の3種に分類しました。
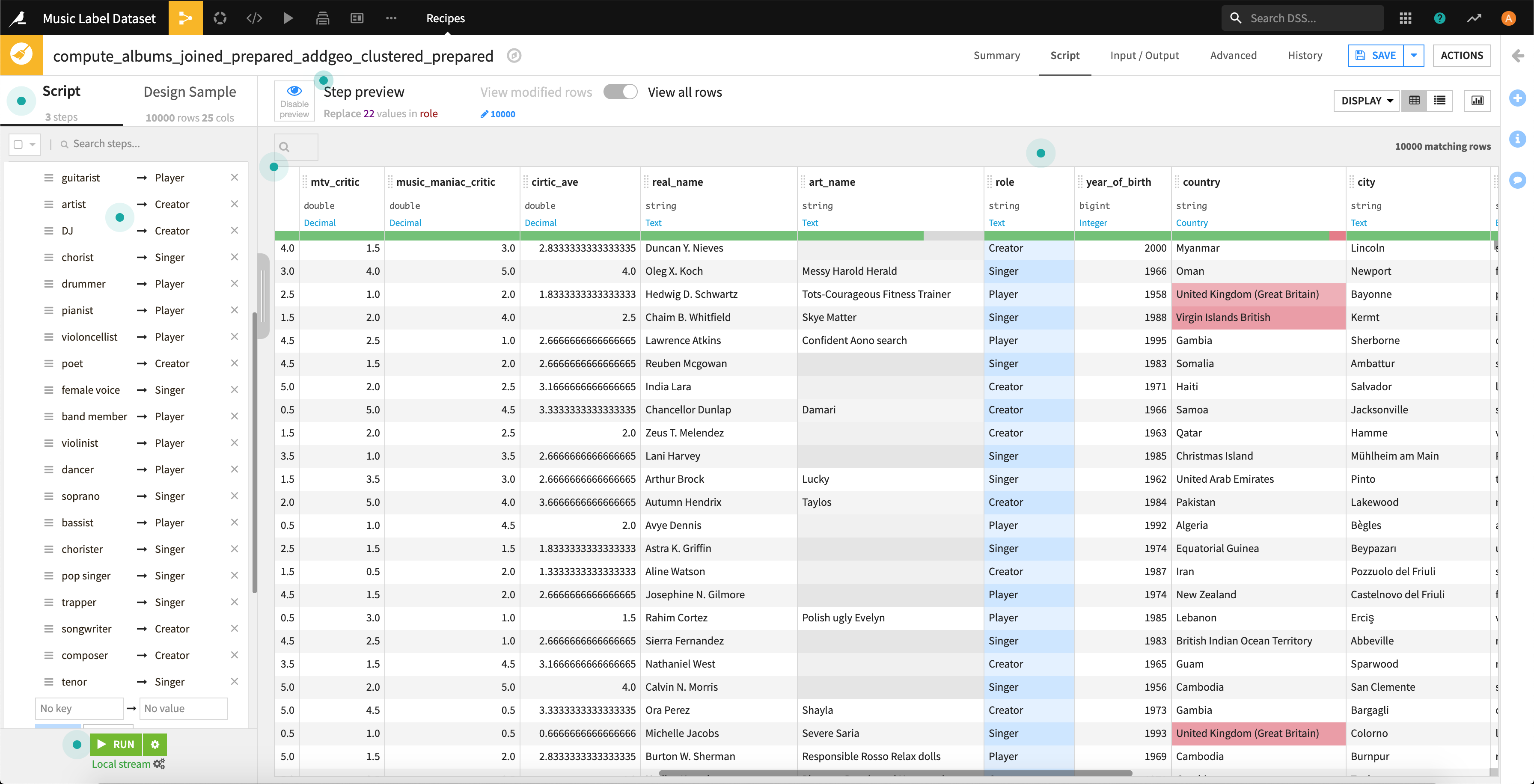
最後に、アーティストの誕生年の「year_of_birth」についてですが、最高齢が1965年生まれで、最年少が2000年生まれなので、5年区切りでカラム作っていきます。
できました。
4.データの可視化&仮説検証
概ね分析前のデータ加工処理は終わったので、続いて項目間の関係を可視化しながら、仮説を検証していきます。
4.1. MTVの評価の可視化
まずは、「音楽ジャンルがロックのアルバムはMTVの評価が高い」という仮説について、グラフで可視化しながら検証していきます。
今回はDataikuに搭載されているBI機能である「charts」と足りない部分はpythonの可視化ライブラリを使ってみます。
まずは単純にヒストグラムで見てみます。横軸を音楽ジャンル、縦軸をMTVの評価でプロットしました。
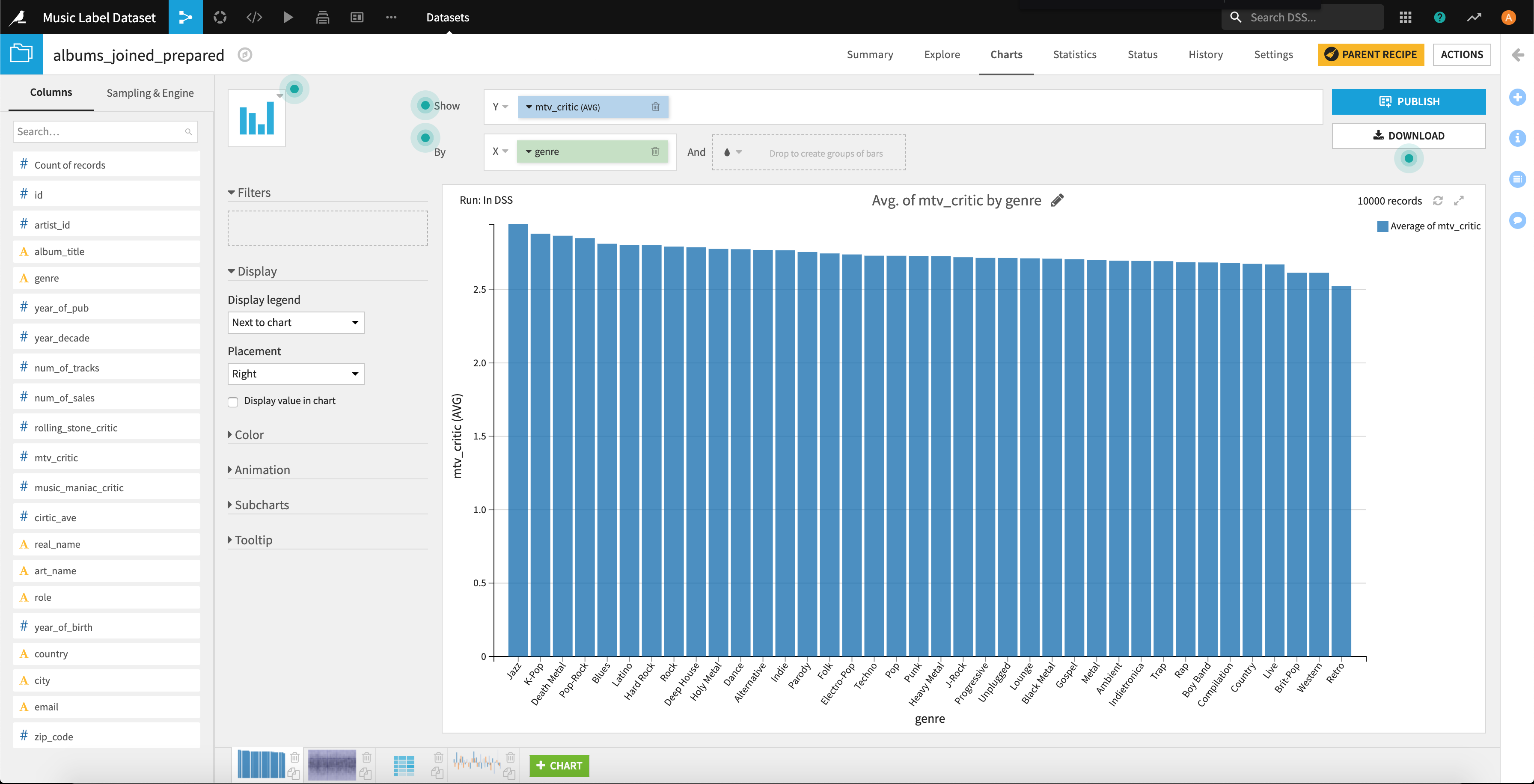
ざっと見た感じ、38種の音楽ジャンルのうち「Rock」が8位であったり、4位に「Pop Rock」7位に「Hard Rock」であったりとRockに近いジャンルは上位に来ていることが見て取れます。
しかしながら、それよりも「jazz」が1位、「k-pop」が2位ということもあり、ロックな音楽だけが評価が高いとまでは言えない感じですね。
※なお、サンプル数は各ジャンル数168~864個であること、箱ひげ図を見た感じほぼ等分散であると仮定できそうなので今回は平均値の差の検定は実施していません。
上記のヒストグラムは、全年度のデータを用いているので、10年ごとに傾向が違うかも見てみたいですね。フィルターを使って比較してみましょう。
こちらが2000年から2009年まで。jazzは頭一つ抜けている感じですね。この時期はよく放映されたのでしょうか。
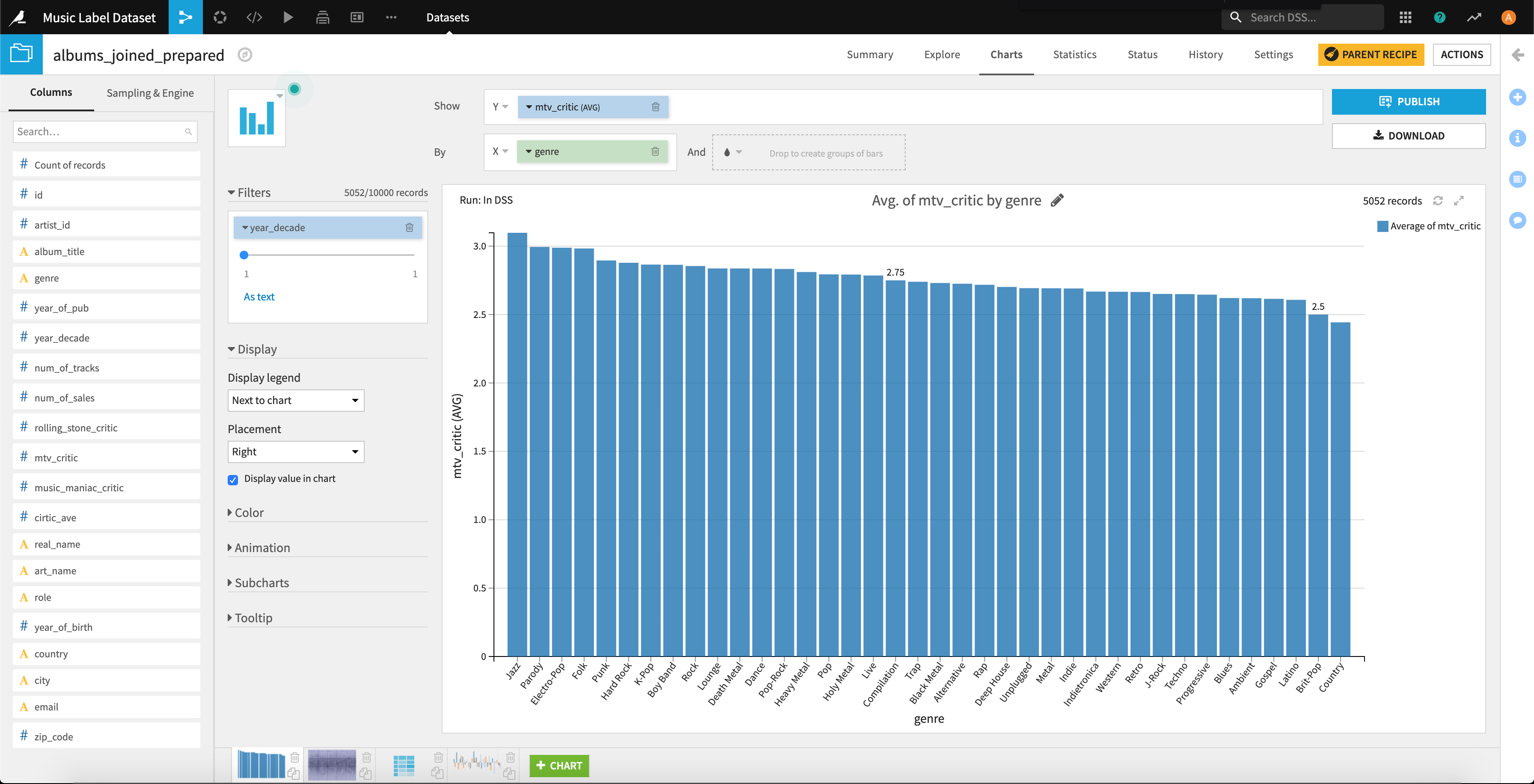
こちらが2010年から2019年まで。意外にもブルースやラテン、カントリーといったワールドミュージック系が上位に来ていますね。
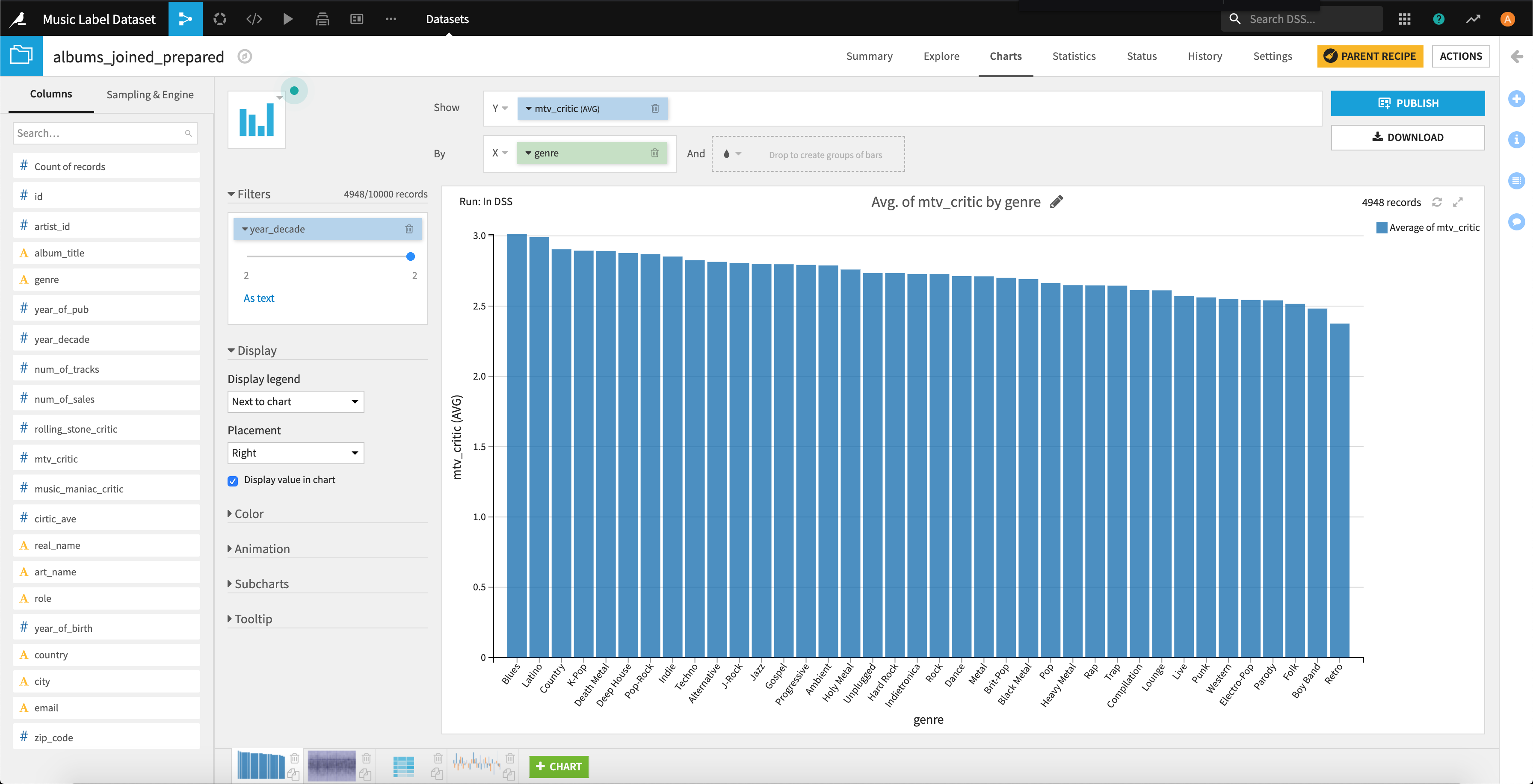
4.2.売り上げ枚数の可視化
続いては、「レビューサイトや雑誌の評価が高いと、リリース後の最初の1ヶ月間の売り上げ枚数は多くなる。」という仮説を検証していくために「レビューの総合評価(critic_ave)」と「リリース後の最初の1ヶ月間の売り上げ枚数(num_of_sales)」の2変数の相関を見ていきます。
まず、単純に「散布図(Scatter Charts)」で可視化してみます。ちょっと分かりづらいですね。。
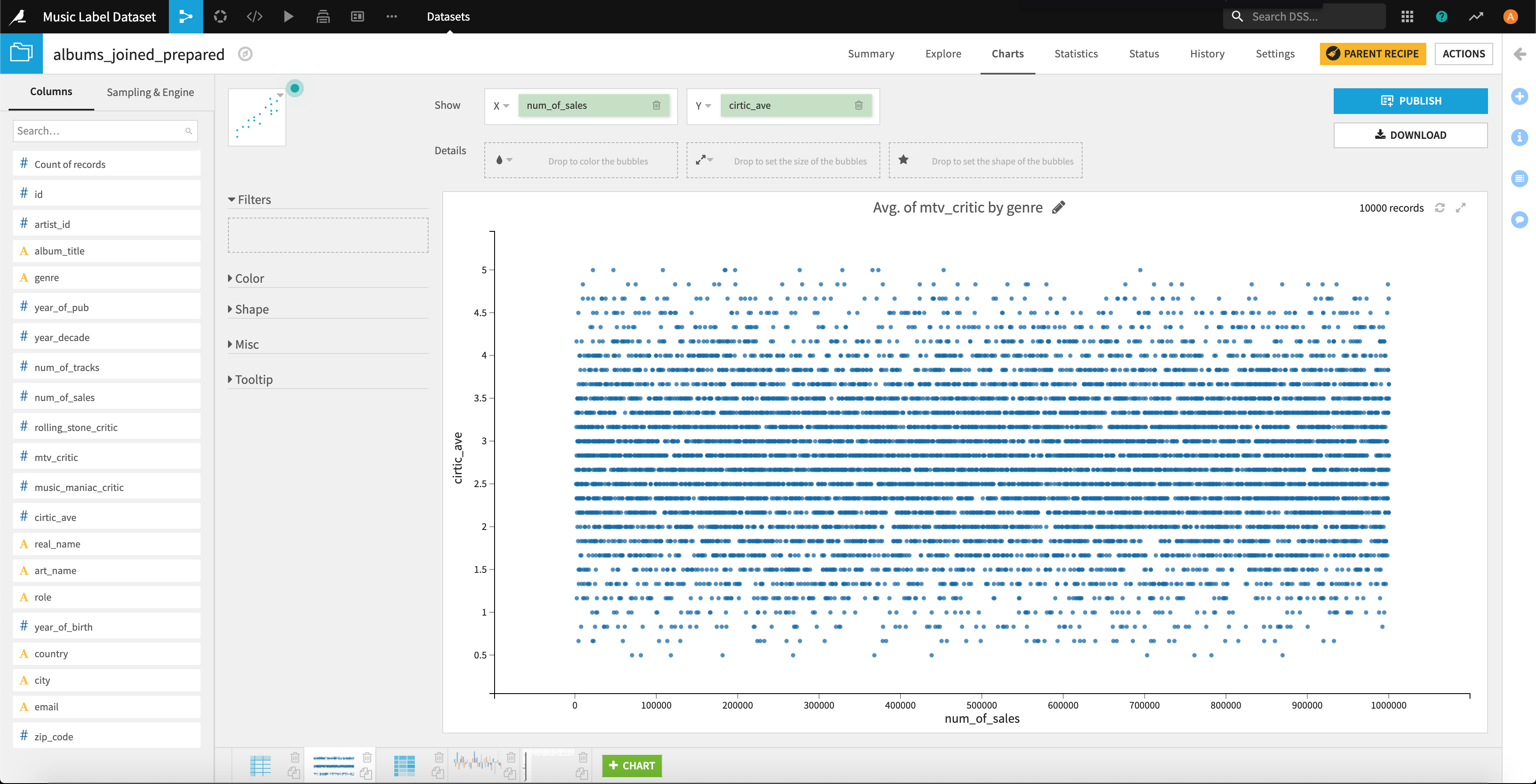
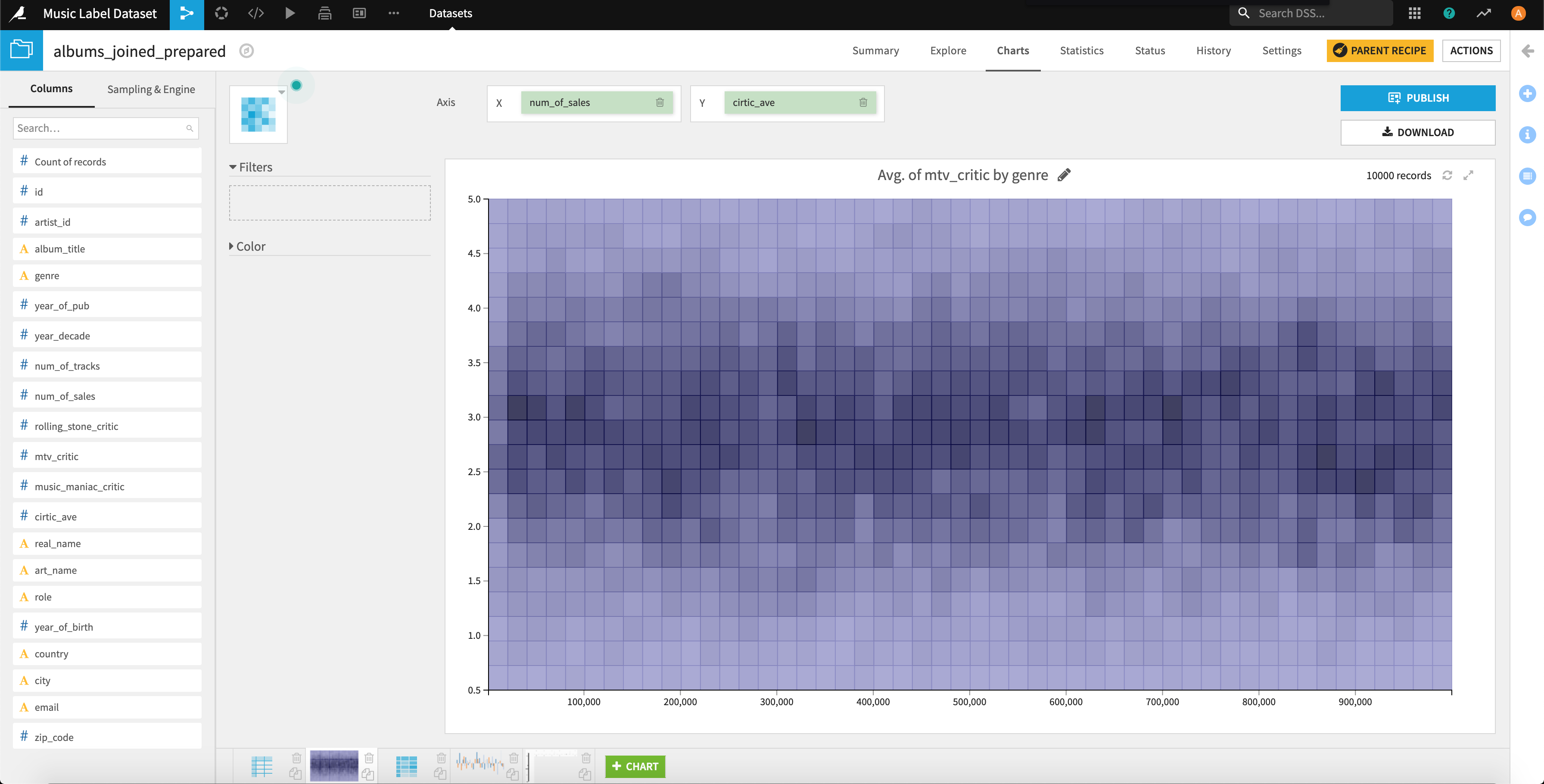
もう少しわかりやすい「2D Distribution」で可視化してみましょう。上記の散布図でいうところの点の密度の高さが高いほど色が濃くなります。
※内部アルゴリズムでカーネル密度推定をしているようです。
この濃い部分が右肩上がりだとレビューの総合評価に伴って、リリース後の最初の1ヶ月間の売り上げ枚数は上がるといえるのですが、濃い部分が横軸に足して平行に並んでいるので相関は高くなさそうですね。。。
Dataikuでは、基本的な統計量を抽出してくれる機能「statistics」があるので、これで相関係数を確認してみましょう。
ADD NEW CARDを選択。
散布図とサマリを表示してみます。
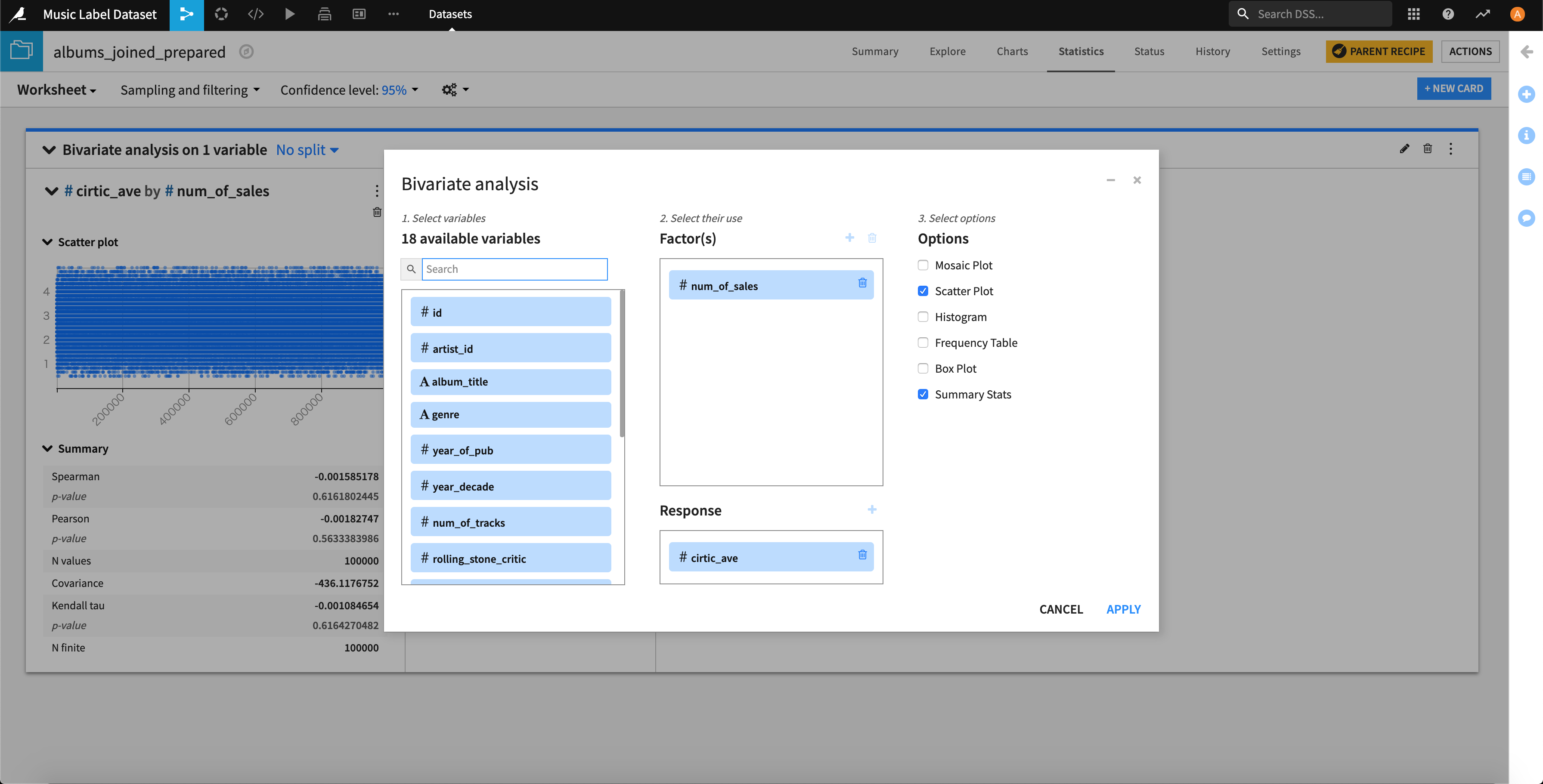
できました。。
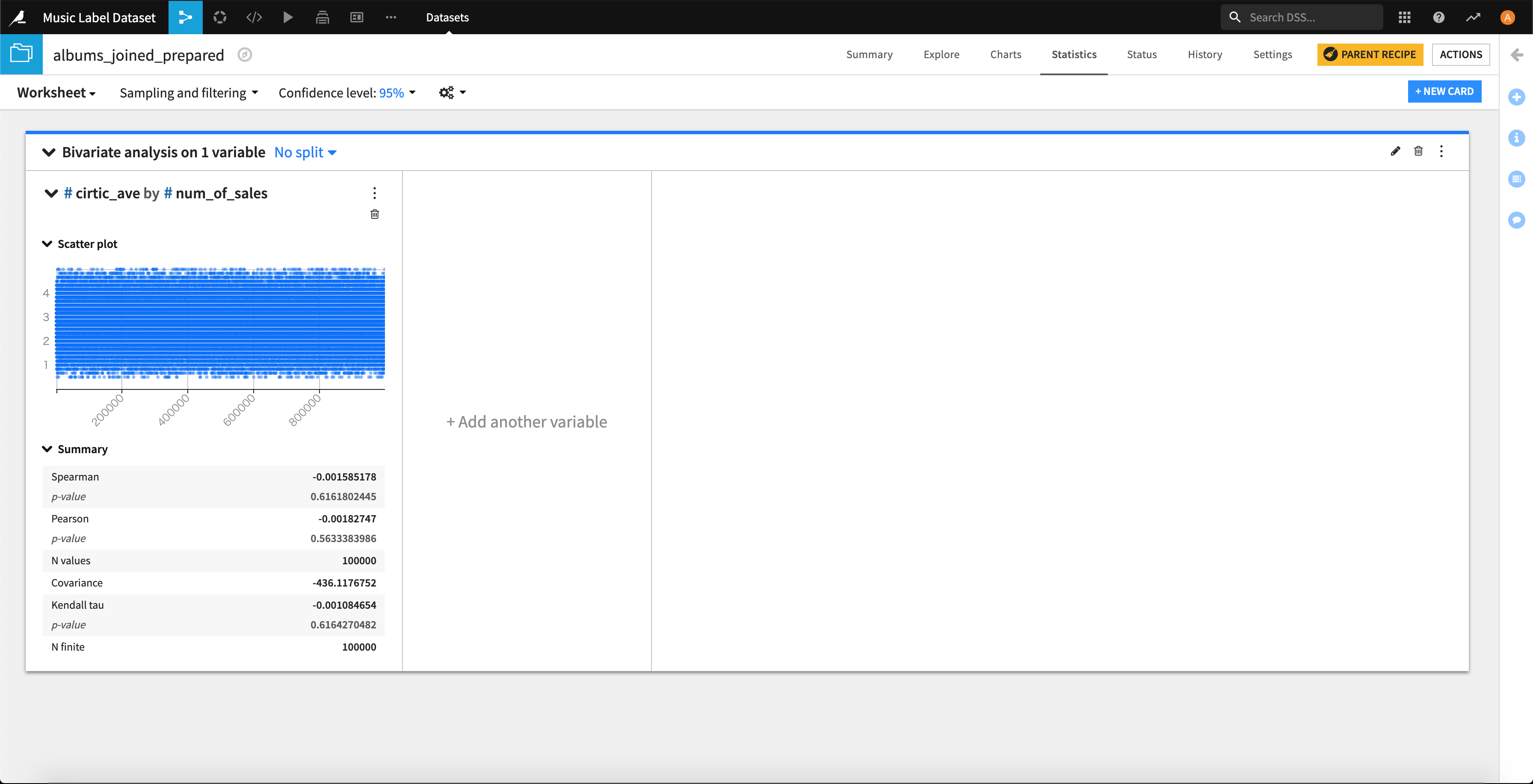
スピアマンの相関係数(ノンパラ)、ピアソンの相関係数(パラメトリック)がありますが、今回はリリース後の最初の1ヶ月間の売り上げ枚数(num_of_sales)の分布が正規分布に従っていないのでスピアマンの相関係数を見るのが妥当です。
値も、「-0.001585178」といった値であり、無相関であることが示されました。
よって、「レビューサイトや雑誌の評価が高いと、リリース後の最初の1ヶ月間の売り上げ枚数は多くなる。」という仮説は棄却されました。。
4.3.アルバムのトラック数の可視化
それでは「音楽配信の影響により、曲をストックせず早くリリースする傾向が進むと考えられるため、年が進むたびに1枚のアルバムあたりのトラック数は少なくなる。」の仮説を検証していきましょう。
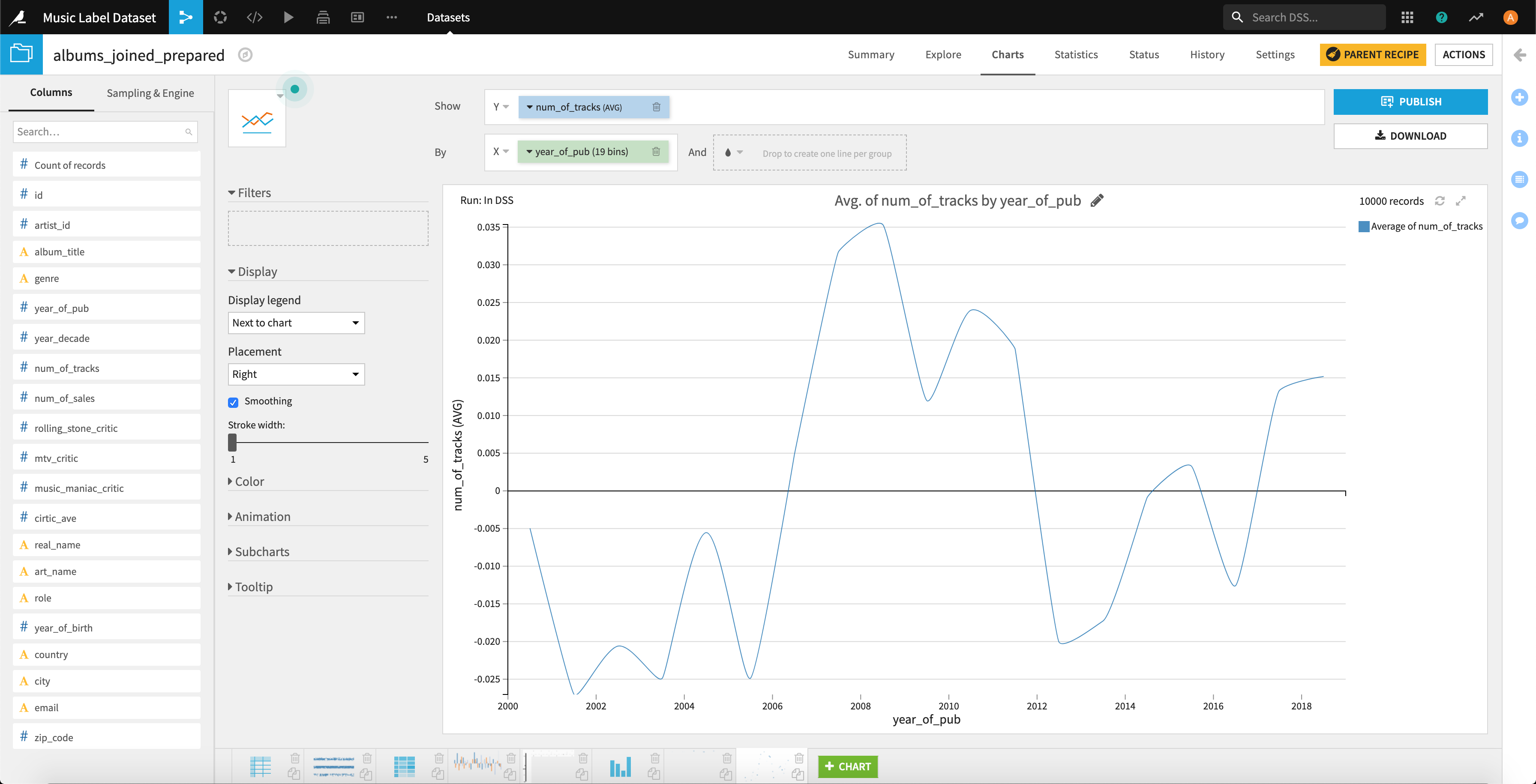
これについては、時系列データですので折れ線グラフでプロットしてみましょう。
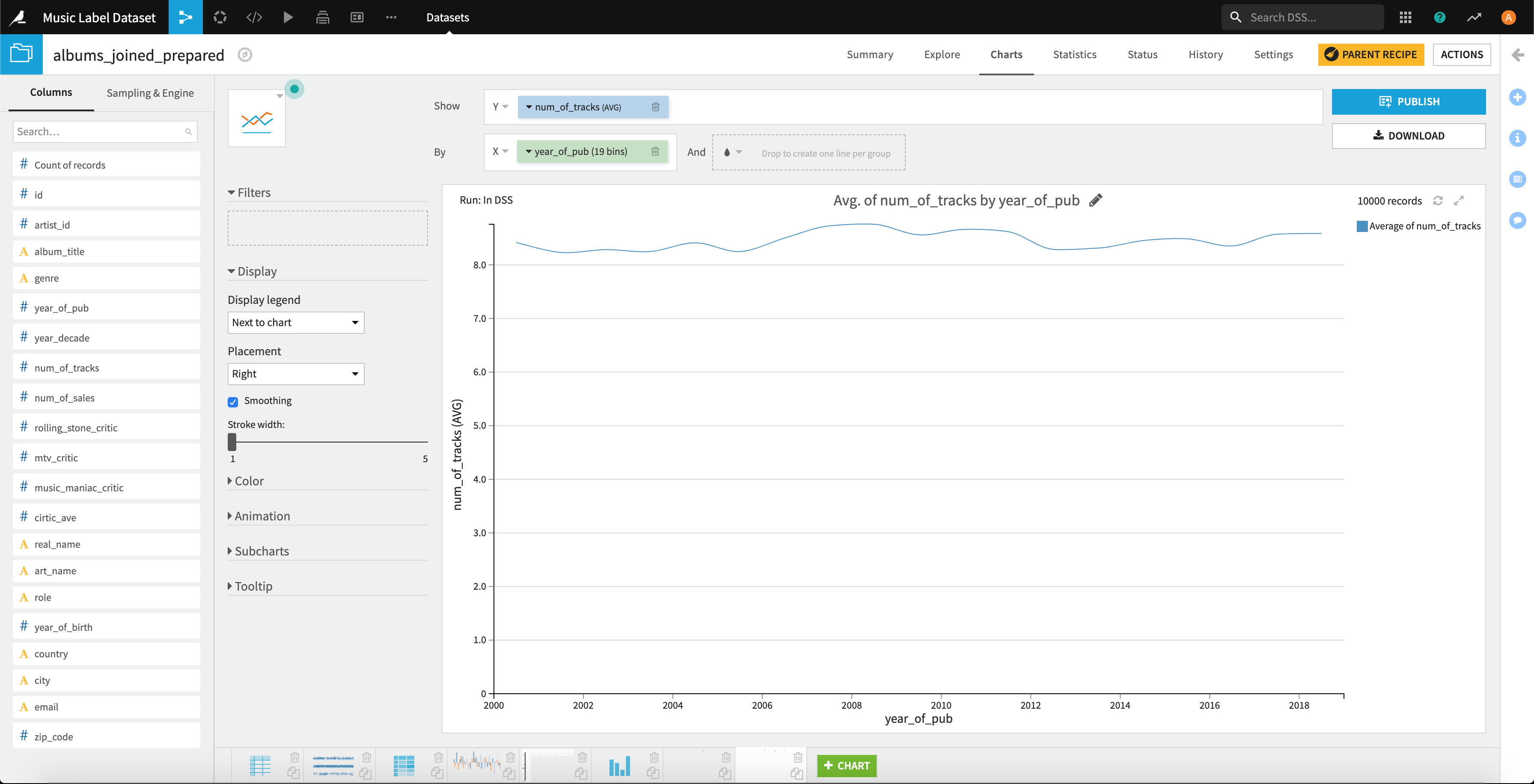
2008年あたりで少し緩やかなピークがきていますが、変動幅が0.03程度なので誤差の範囲と言っていいでしょう。(統計検定をするまでもないという感じですかね。。。)
ヒストグラムを用いて、10年ごとの比較もしてみましたが、左の2000年から2009年のグラフは「8.43」、右の2010年〜2019年のグラフは「8.49」
とほぼが差がないですね。
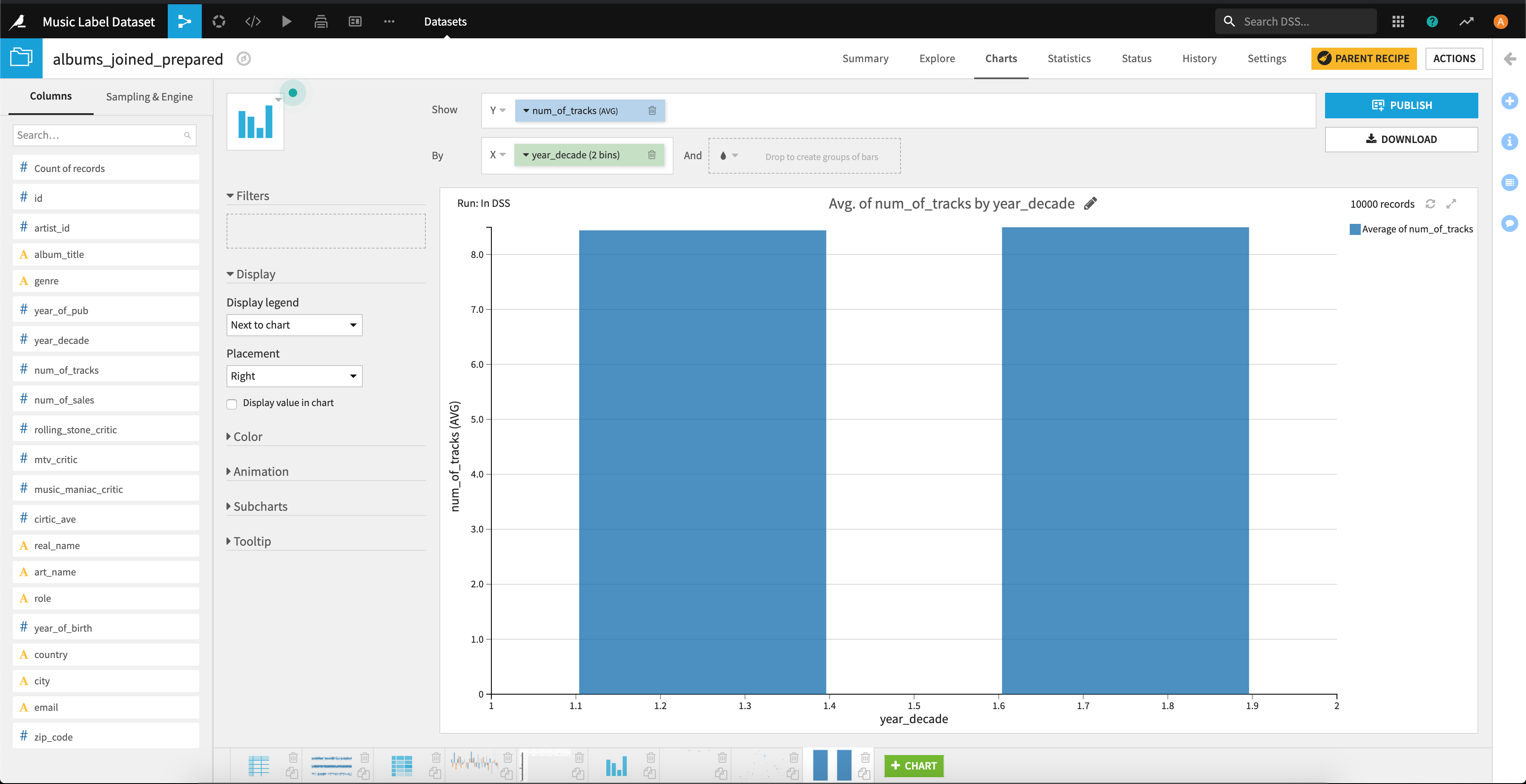
つまり、トラック数と年との関係性はほぼないと考えられます。(統計量の算出は割愛します。)
4.4.アーティストの可視化
それでは最後に「「アーティストの出身地の違い」や「アーティストの主な役割」、「アーティストの誕生年」等によって評価されるメディアが違う。」という仮説を検証していきましょう。
3種の評価と「アーティストの出身地の違い」や「アーティストの主な役割」、「アーティストの誕生年」との関連性を見るためにヒストグラムをプロットしてみます。
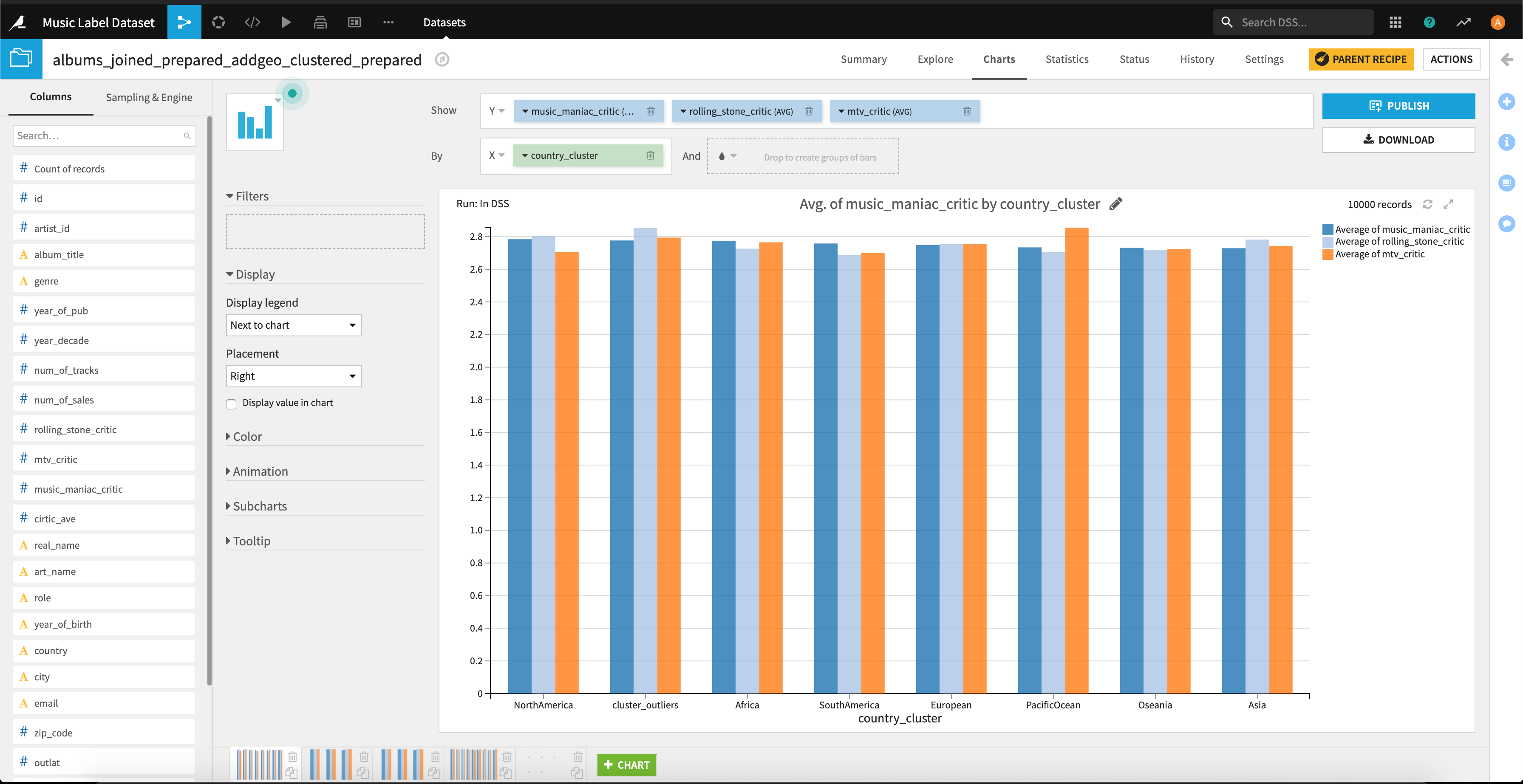
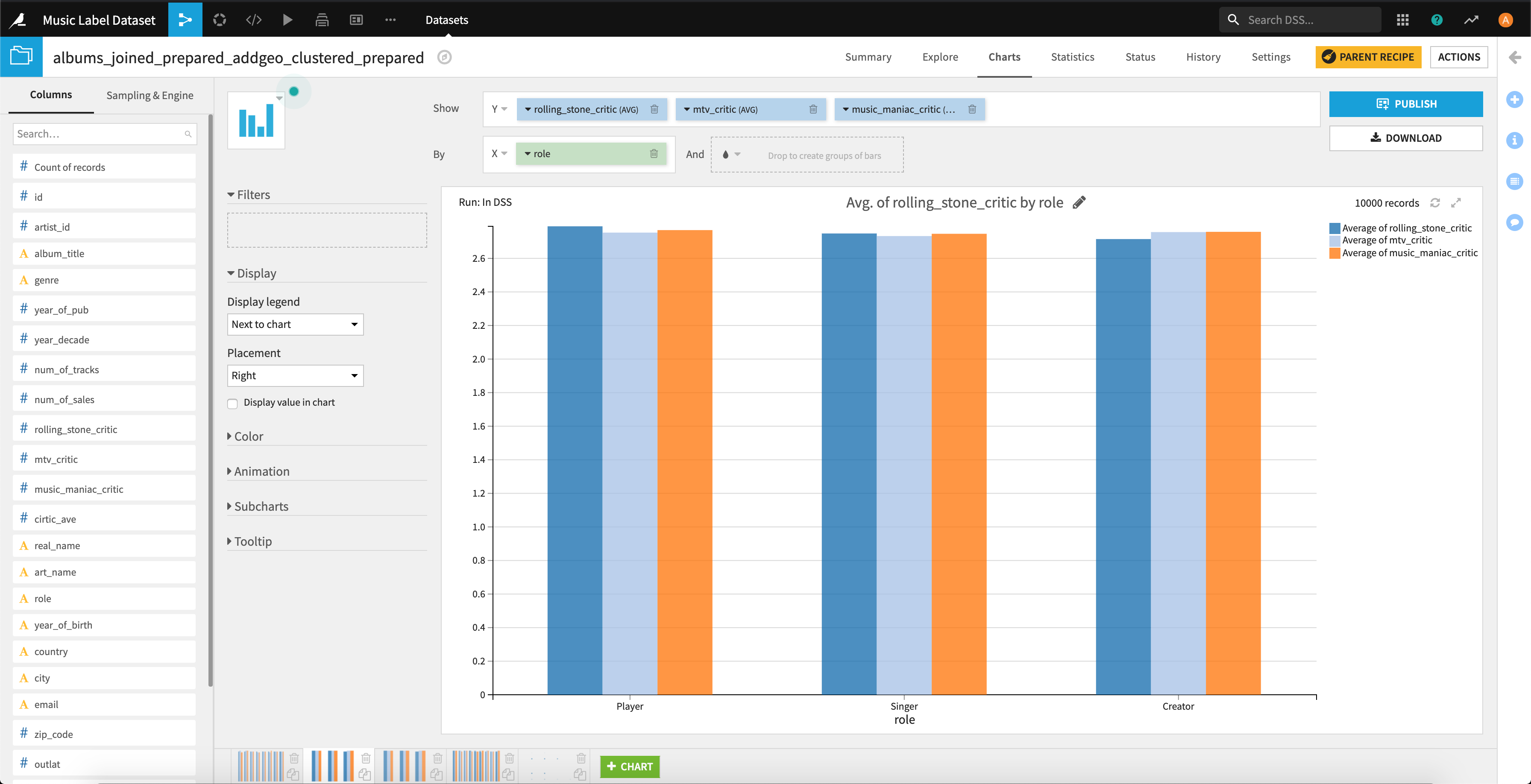
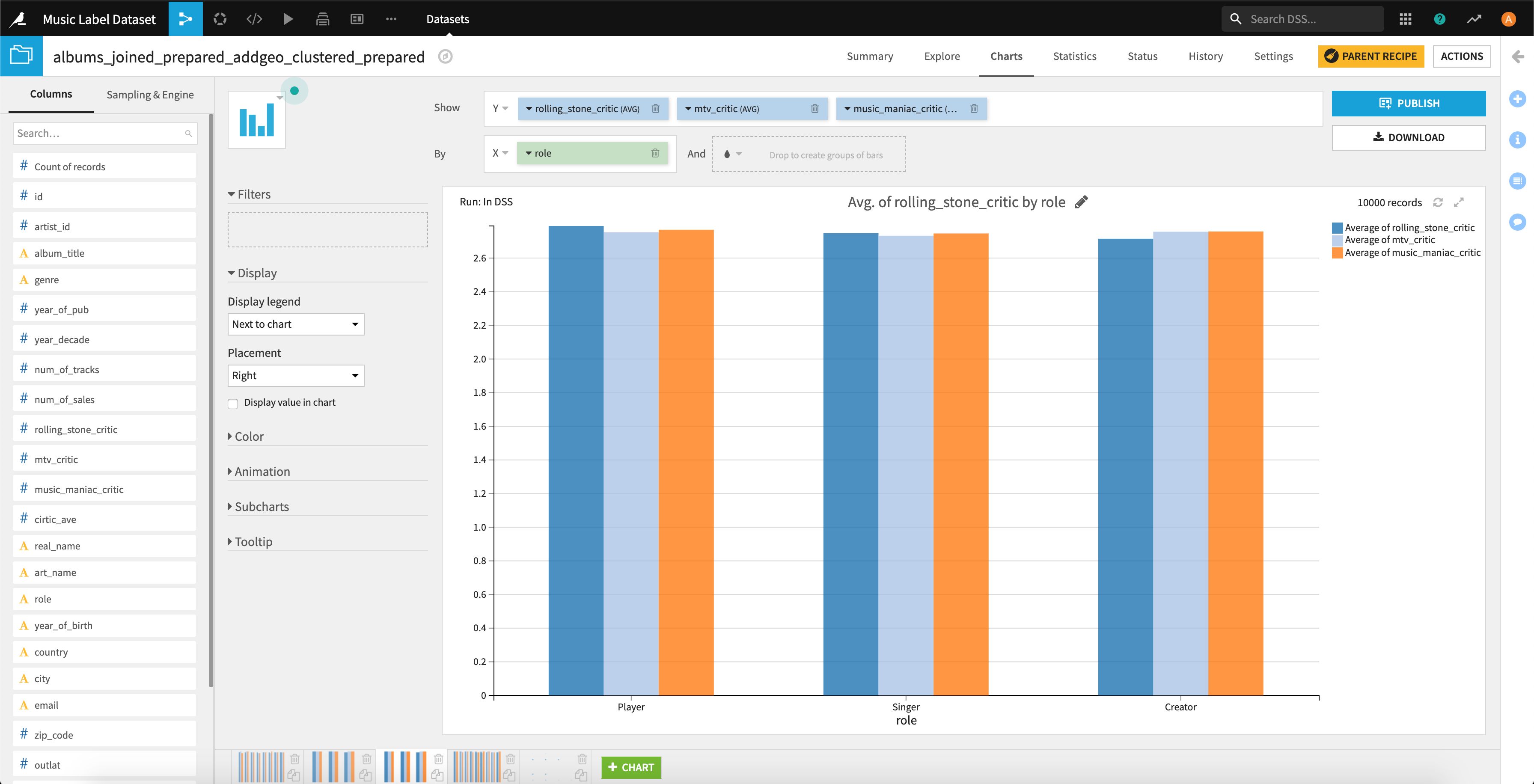
評価の点数が0.1程度の違いはありますが、3つの評価の間で特別な差はなさそうです。。。
4.5.仮説検証のまとめ
はい、それでは最後に仮説とその検証結果です!
①音楽ジャンルがロックのアルバムはMTVの評価が高い(MTV:1981年にアメリカで誕生した、24時間ミュージックビデオを放送する番組。ロック音楽のプロモーターであり影響力が強いと考えられる)
→比較的に上位にはきているものの、1〜8位が他ジャンルであるため評価が高いとは言えない。
②レビューサイトや雑誌の評価が高いと、リリース後の最初の1ヶ月間の売り上げ枚数は多くなる。
→レビューサイトの評価と、売り上げ枚数の間の相関は無相関に近いことから、そうであるとは言えない。
③音楽配信の影響により、曲をストックせず早くリリースする傾向が進むと考えられるため、年が進むたびに1枚のアルバムあたりのトラック数は少なくなる。
→そうとは言い切れない。
④「アーティストの出身地の違い」や「アーティストの主な役割」、「アーティストの誕生年」等によって評価されるメディアが違う。
→特定のパラメータによって評価されるメディアには差がないため、そうとはいえない。
はい、全体的に立てた仮説とは違う結果になってしまいました。
仮説の立て方が悪かったのか、データが悪かったのかは今回は仮想のデータなのでわからないですが、
実際のデータ分析では、この考察が一番大事で、結果を受けて次にどういった仮説を作るか
どういったデータを取得する必要があるか、などを考えて繰り返しプロセスを回していくことが非常に大事です!
おわりに
長文にもかかわらず、ここまで見てくださってありがとうございました!
今回は、ダミーのデータを使っての分析であったため、少し実用性がなかったですが、
また、面白そうな音楽の生データがあれば統計分析をしてみようと思います!
それでは、また!