これは日本情報クリエイト Engineer's Advent Calendar 2017の5日目の記事です。
はじめに
Q Rubyって何?
A 黒澤(妹)です。
なんて書くと「ぶっぶーですわ~!」と怒られそうなので、
本当の説明は以下の通りです。
Ruby(ルビー)は、まつもとゆきひろ(通称 Matz)により開発されたオブジェクト指向スクリプト言語であり、スクリプト言語が用いられてきた領域でのオブジェクト指向プログラミングを実現する。
引用:Wikipedia
国産の言語なので日本語ドキュメントが結構見つかりますね。
なので、わからないことを読めない英語で調べて余計わからなくなることが少なかったです。
Q どうしてクローラー作りだしたの?
A ある日Laravel推しの方が作ったクローラーをポンっと渡されたからだよっ!
と書くと語弊がありますね。
元々使われていたクローラーを引き継ぐことになってクローラー開発が始まった感じです。
実際渡されたクローラーがどんなことをしているのか、当時の私にはちんぷんかんぷんだったので、
ちゃんと製作者の方に説明してもらいました。(ありがとうございます。)
Q なんでRubyなの?
A 渡されたのがRubyで作られてたからだよっ!
(当時入社1年目の私にPythonで作ろうとか言う考えは存在してませんでした。)
そんな私でも作れちゃうんですよ、はい。
ではでは、本題
なのですが、クローラーを作成する場合は、気を付けないと
クリーリング先に大きな負荷をかけてしまうことがあります。
過去にはこんな事件もありました
気を付けましょう。
クローラーの開発にあたってまずは環境構築からなのですが、
ここに関しては割愛します。
環境に関しては、ggってもらった方がいろんな方がすでに書いておられますし、
分かりやすいです!
(そして何より長くなるのでめんどくs・・)
さて、クローラー本体についてですが、基本的に
「Nokogiri」を使用しております。
「Nokogiri」はHTMLなどをパースするためのRubyライブラリのことです。
じゃあ実際にはどうやって使うの?ってことで
試しにくらさぽ広場の記事URLを取得します。
具体的には下の画像の赤枠記事へのリンクですね。
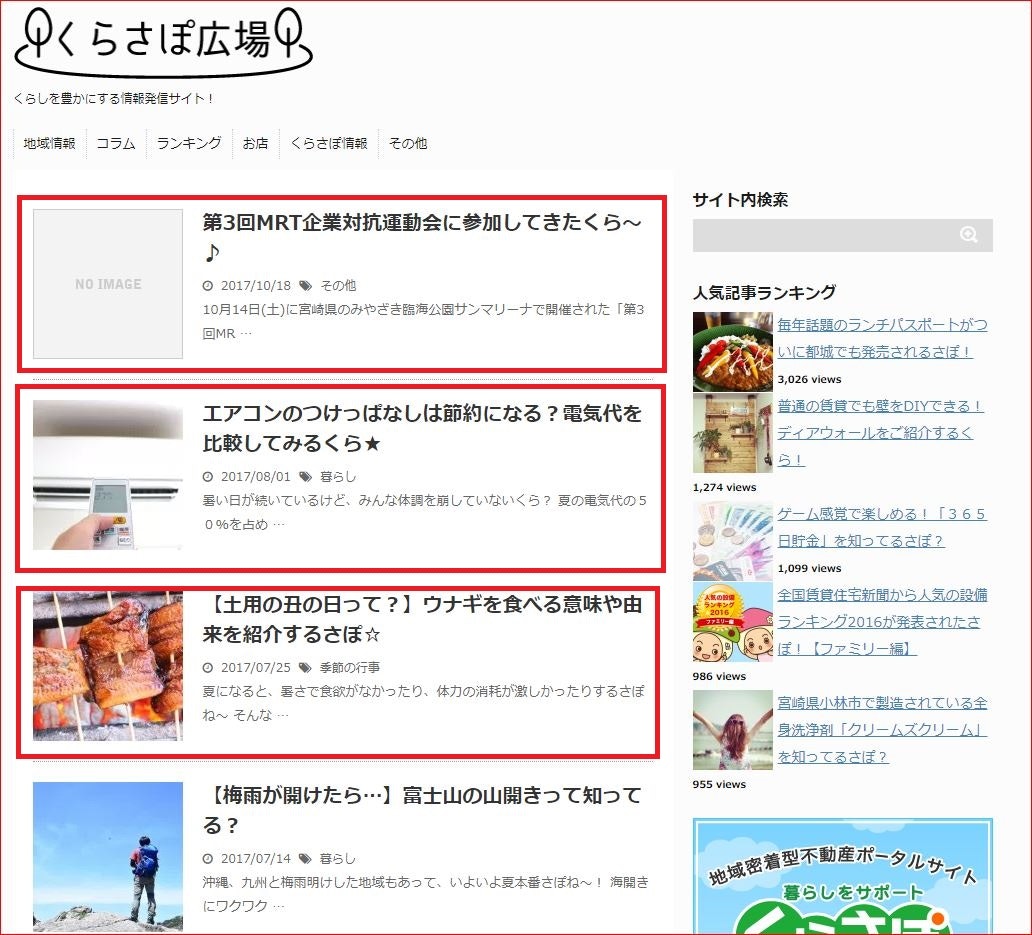
実際に書いてみます
まずは今回使用するライブラリを読み込みます。基本ですね!
「Nokogiri」は事前に gem install が必要です。
require 'nokogiri'
require 'pp'
require 'open-uri'
呼び出したのでNokogiriさんには働いてもらいます。
# アクセスしたいURLを指定します。
url = 'https://www.kurasapo-hiroba.com/'
# nokogiriクラスを利用し、HTMLを解析、扱いやすいオブジェクトに変換します。
kura = Nokogiri::HTML(open(url))
こんな感じで書いてあげればNokogiriさんがHTMLを解析してくれます。
あとは解析した結果からcssやxpathを使って、ほしい情報を取り出してあげればOK!
↓こんなかんじ
data = kura.css("h3 a").each do |elem|
pp elem[:href]
end
今回はURLを取り出すだけなのでシンプルなプログラムになりました。
全文は以下の通りです。
# -*- coding: utf-8 -*-
require 'nokogiri'
require 'pp'
require 'open-uri'
# アクセスしたいURLを指定します。
url = 'https://www.kurasapo-hiroba.com/'
# nokogiriクラスを利用し、HTMLを解析、扱いやすいオブジェクトに変換します。
kura = Nokogiri::HTML(open(url))
data = kura.css("h3 a").each do |elem|
pp elem[:href]
end
ちなみに、このプログラムを実際に実行してあげるとこのような結果になります。
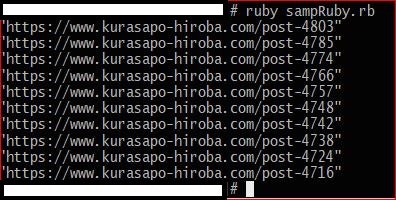
記事のURLが取り出せましたね。
こんな簡単に情報が取り出せちゃいます。
もっと作りこめば、取り出したURL先にさらにアクセスして
より多くの情報を取得出来たりもします。
おまけ
とある日、一件のクローラー作成依頼が入ってきました。
Aさん「xxxの情報がほしいのでクローリングをお願いします」
私「対応します」
いつものようにサクッと作ってやるぞぉ(/・ω・)/
と、クローリング先を確認。
私「ん?どこのリンクもURLが一緒・・・。あ、JavaScript・・・」
はい、Nokogiriさんが使えませんでした。(私は無知なだけかもしれない)
というわけでここで登場
Capybaraさ~ん~(某ネコ型ロボット風)

はい、もうこのネタいいですね。
CapybaraもRubyのライブラリとなります。
JavaScriptへの対応ができるようになります。
正確には、Capybara単体ではなくSeleniumやPoltergeistのような画面テストツールと一緒に使います。
今回の記事には詳細は記載しませんが、このようにクローラーといってもページによって作り方やライブラリを変えたりと
いろいろな作り方ができます。楽しいですね!
さいごに
クローラーを作成するにあたって「Rubyによるクローラー開発技法」という書籍を使いました。
クローラー作成にあたって必要な箇所しか読んでいませんが、
ruby、クローラー初心者の自分でもわかりやすかったです。
プログラム初心者でもクローラーは作れちゃいますので、
ぜひ、クローラーを作ってみてください。