こんにちは!
入社したてのころ、右も左もわからずにコーディングをしていました。
そんな中で、僕もよく悩まされたN+1についての対策について簡単にまとめてみました。
N+1は簡単に防げてパフォーマンスをあげることができます。
すぐできて、効果大なのでぜひ実践してみてください!
そもそもN+1とは
SQLクエリが 「データ量N + 1回 」走ってしまい、取得するデータが多くなるにつれて(Nの回数が増えるにつれて)パフォーマンスを低下させてしまう問題です。
N+1問題 / Eager Loading とは
(引用させていただきました)
→簡単にいうとデータ取得の際、余計にSQLを発行してしまいパフォーマンスを下げてしまうことです。
テーブルの定義
例えば配列展開でBook(本)からAuthor(著者)の名前を出力したい場合(以下ER図&作成データになります)。
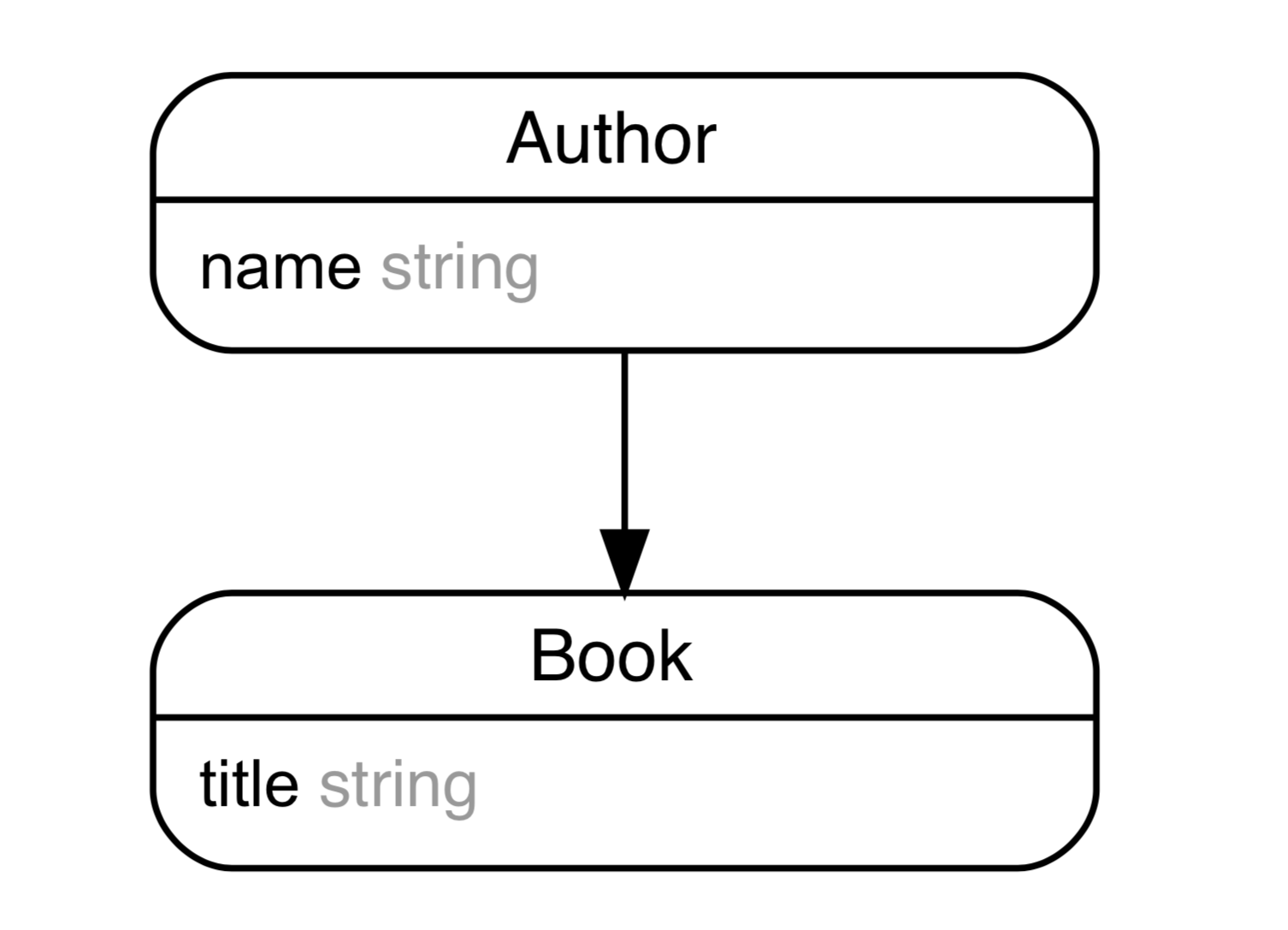
念の為コードも
Author
class Author < ApplicationRecord
has_many :books
end
Book
class Book < ApplicationRecord
belongs_to :author
end
データの用意
author(諫山さん)が6冊の本(book)のリレーションを持っています。
irb(main):004:0> Author.all # 全てのAuthorレコード
Author Load (0.5ms) SELECT "authors".* FROM "authors"
+----+--------+-------------------------+-------------------------+
| id | name | created_at | updated_at |
+----+--------+-------------------------+-------------------------+
| 1 | 諫山創 | 2019-05-05 10:44:51 UTC | 2019-05-05 10:44:51 UTC |
+----+--------+-------------------------+-------------------------+
irb(main):003:0> Book.all # 全てのBookレコード
Book Load (1.3ms) SELECT "books".* FROM "books"
+----+---------+-----------+-------------------------+-------------------------+
| id | title | author_id | created_at | updated_at |
+----+---------+-----------+-------------------------+-------------------------+
| 1 | 進撃の1 | 1 | 2019-05-05 10:46:17 UTC | 2019-05-05 10:46:17 UTC |
| 2 | 進撃の2 | 1 | 2019-05-05 10:46:25 UTC | 2019-05-05 10:46:25 UTC |
| 3 | 進撃の3 | 1 | 2019-05-05 10:46:28 UTC | 2019-05-05 10:46:28 UTC |
| 4 | 進撃の4 | 1 | 2019-05-05 10:46:31 UTC | 2019-05-05 10:46:31 UTC |
| 5 | 進撃の5 | 1 | 2019-05-05 10:46:35 UTC | 2019-05-05 10:46:35 UTC |
| 6 | 進撃の6 | 1 | 2019-05-05 10:46:38 UTC | 2019-05-05 10:46:38 UTC |
+----+---------+-----------+-------------------------+-------------------------+
irb(main):004:0> Author.first.books # 諫山さんが6冊の本(book)のリレーションを保持
Author Load (1.7ms) SELECT "authors".* FROM "authors" ORDER BY "authors"."id" ASC LIMIT ? [["LIMIT", 1]]
Book Load (0.2ms) SELECT "books".* FROM "books" WHERE "books"."author_id" = ? [["author_id", 1]]
+----+---------+-----------+-------------------------+-------------------------+
| id | title | author_id | created_at | updated_at |
+----+---------+-----------+-------------------------+-------------------------+
| 1 | 進撃の1 | 1 | 2019-05-05 10:46:17 UTC | 2019-05-05 10:46:17 UTC |
| 2 | 進撃の2 | 1 | 2019-05-05 10:46:25 UTC | 2019-05-05 10:46:25 UTC |
| 3 | 進撃の3 | 1 | 2019-05-05 10:46:28 UTC | 2019-05-05 10:46:28 UTC |
| 4 | 進撃の4 | 1 | 2019-05-05 10:46:31 UTC | 2019-05-05 10:46:31 UTC |
| 5 | 進撃の5 | 1 | 2019-05-05 10:46:35 UTC | 2019-05-05 10:46:35 UTC |
| 6 | 進撃の6 | 1 | 2019-05-05 10:46:38 UTC | 2019-05-05 10:46:38 UTC |
+----+---------+-----------+-------------------------+-------------------------+
コンソールで実行
配列展開でBookから親モデルのAuthorのnameを呼び出すとBookのデータ数分(6個)SQLを発行してしまいます。
→つまり5回もSQLが無駄に発行されてしまうのです。
books = Book.all
> Book Load (0.2ms) SELECT "books".* FROM "books"
irb(main):037:0* books.each do |book|
irb(main):038:1* book.author.name
irb(main):039:1> end
Author Load (0.6ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 1]]
Author Load (0.1ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 1]]
Author Load (0.1ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 1]]
Author Load (0.1ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 1]]
Author Load (0.1ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 1]]
Author Load (0.1ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 1]]
irb(main):040:1>

この無駄なクエリを防ぐにはincludesを追加するのがもっとも簡単です
includes追加
books = Book.all.includes(:author) #追加
Book Load (2.1ms) SELECT "books".* FROM "books"
Author Load (0.2ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = ? [["id", 1]]
お気づきでしょうか、includes追加により関連レコード(author)も一緒に取得されています。
→つまり、Bookと一緒に紐づいたAuthorモデルのレコードも取得し変数に代入していることになります。
Before
books = Book.all
> Book Load (0.2ms) SELECT "books".* FROM "books"
books = Bookモデルの全てのデータ
After

books = Bookモデルの全てのデータとそれらにひもづくAuthorデータ
この状態でもう一度booksを展開してみましょう!
irb(main):051:0* books.each do |book|
irb(main):052:1* book.author.name
irb(main):053:1> end
irb(main):054:0>
今度は展開のたびにAuthorを取得していません。
SQLの発行をおさえてパフォーマンス低下を防ぐことができましたね。
includesで色々なリレーションを取得する
先ほどは**N:1(Book:Author)**でのパターンでしたが、実際はもっと複雑な利用パターンが多いと思います。
そんな時に利用できる書き方をご紹介します。
N:1 = Book:Author
books = Book.all.includes(:author)
こちらは先ほどのパターンでしたね
N:1:1 = Book:Author:Profile
では、Authorのプロフィール情報を保存するAuthors::Profileがあった場合
books = Book.all.includes(author: :profile)
Book Load (1.6ms) SELECT "books".* FROM "books" LIMIT ? [["LIMIT", 11]]
Author Load (0.4ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = ? [["id", 1]]
Authors::Profile Load (0.4ms) SELECT "authors_profiles".* FROM "authors_profiles" WHERE "authors_profiles"."author_id" = ? [["author_id", 1]]
N:1:1:1 = Book : Author : Profile : ProfileImage
さらにProfileに1つのプロフィール写真Authors::ProfileImageひもづく場合
books = Book.all.includes(author: [profile: :profile_image])
Book Load (0.5ms) SELECT "books".* FROM "books" LIMIT ? [["LIMIT", 11]]
Author Load (0.1ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = ? [["id", 1]]
Authors::Profile Load (0.2ms) SELECT "authors_profiles".* FROM "authors_profiles" WHERE "authors_profiles"."author_id" = ? [["author_id", 1]]
Authors::ProfileImage Load (0.1ms) SELECT "authors_profile_images".* FROM "authors_profile_images" WHERE "authors_profile_images"."id" = ? [["id", nil]]
逆に**1:N(Author:Book)**なら?
これはリレーションを使い関連データを全て取得できますね。
> Author.first.books
Author Load (0.3ms) SELECT "authors".* FROM "authors" ORDER BY "authors"."id" ASC LIMIT ? [["LIMIT", 1]]
Book Load (0.3ms) SELECT "books".* FROM "books" WHERE "books"."author_id" = ? [["author_id", 1]]
N+1の予感とタイトルにありますが、余計にクエリを投げるケースは配列展開が多いと思います。
慣れていない方はeachやmap, selectなど配列展開のメソッドを使う際にN+1が起きていないかぜひ意識してみてください!