はじめに
この記事では、AWSのApplication Load Balancer (ALB) を使用し、ターゲットグループに紐づくすべてのEC2インスタンスが正常でない場合に、Lambda関数を利用して動的にメンテナンスページ(固定レスポンスページ)を表示させる手順を紹介します。
この設定により、アプリケーションの可用性を高めつつ、ユーザーに適切なメンテナンス情報を提供することが可能になります。
本記事が、誰かの技術の支えとなることを願っています!
前提:本記事は前回の検証の続きになります。
今回の内容は、以下の記事に続く検証内容です。
前回は、Application Load Balancer (ALB) を使用して複数のEC2インスタンスへの負荷分散を行い、CloudWatchの「HealthyHostCount」とEventBridgeを組み合わせてEC2障害を検知するシステムを構築しました。
ALBで複数EC2インスタンスを負荷分散する手順
CloudWatchの「HealthyHostCount」とEventBridgeを使ったEC2障害検知システムの作成手順
今回は、続きの検証として、すべてのEC2インスタンスが正常でない場合に、Lambda関数を利用してメンテナンスページを表示する手順を実装します。
事前準備
ALBでの固定レスポンス機能の設定
AWS Management Consoleにログインし、EC2ダッシュボードに移動し、左側のメニューからLoad Balancersを選択し、対象のALBを選択します。

リスナーとルールのタブを開き、リスナーの設定を確認し、ルールを管理画面からルールを追加します。

ルール名を「Sorry」とし、新規ルールを追加します。
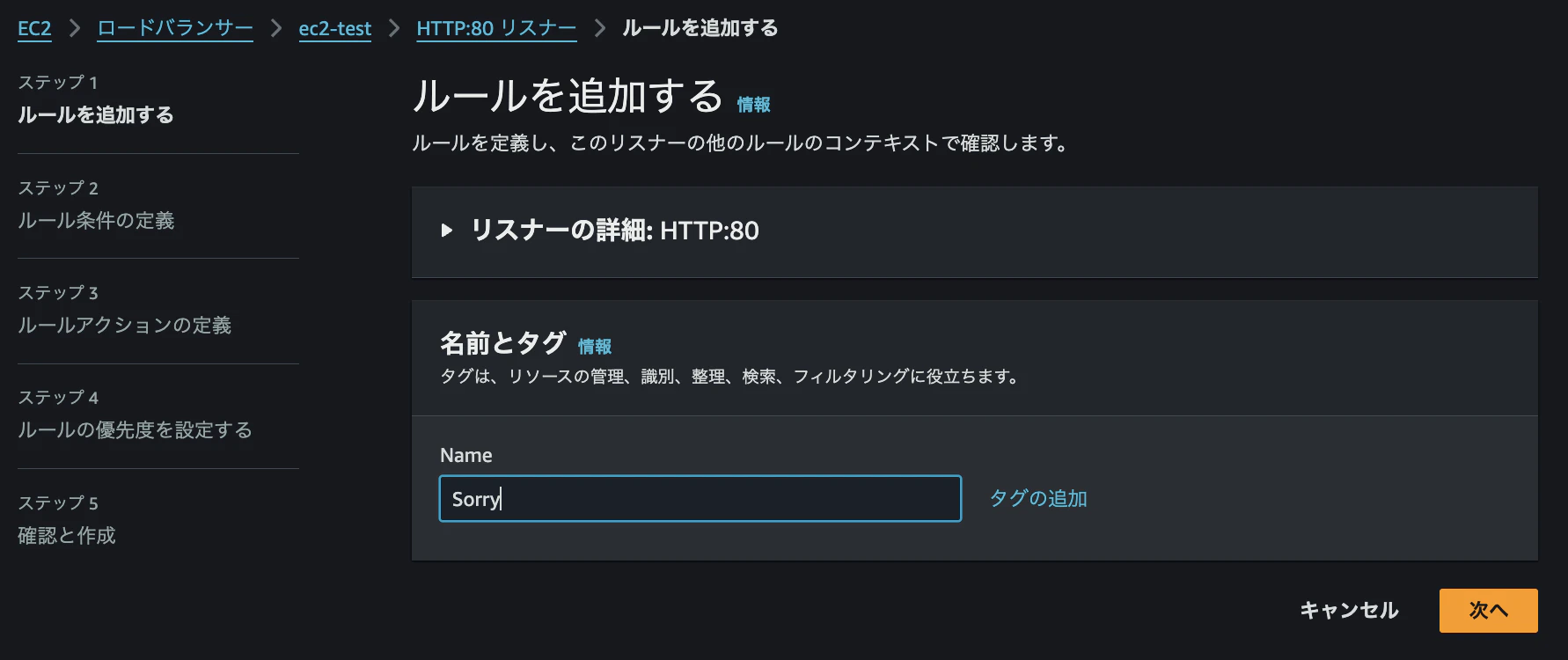
パスパターンには「*」を入力し、条件を追加します。

ルールアクションの設定画面で「固定レスポンスを返す」を選択します。
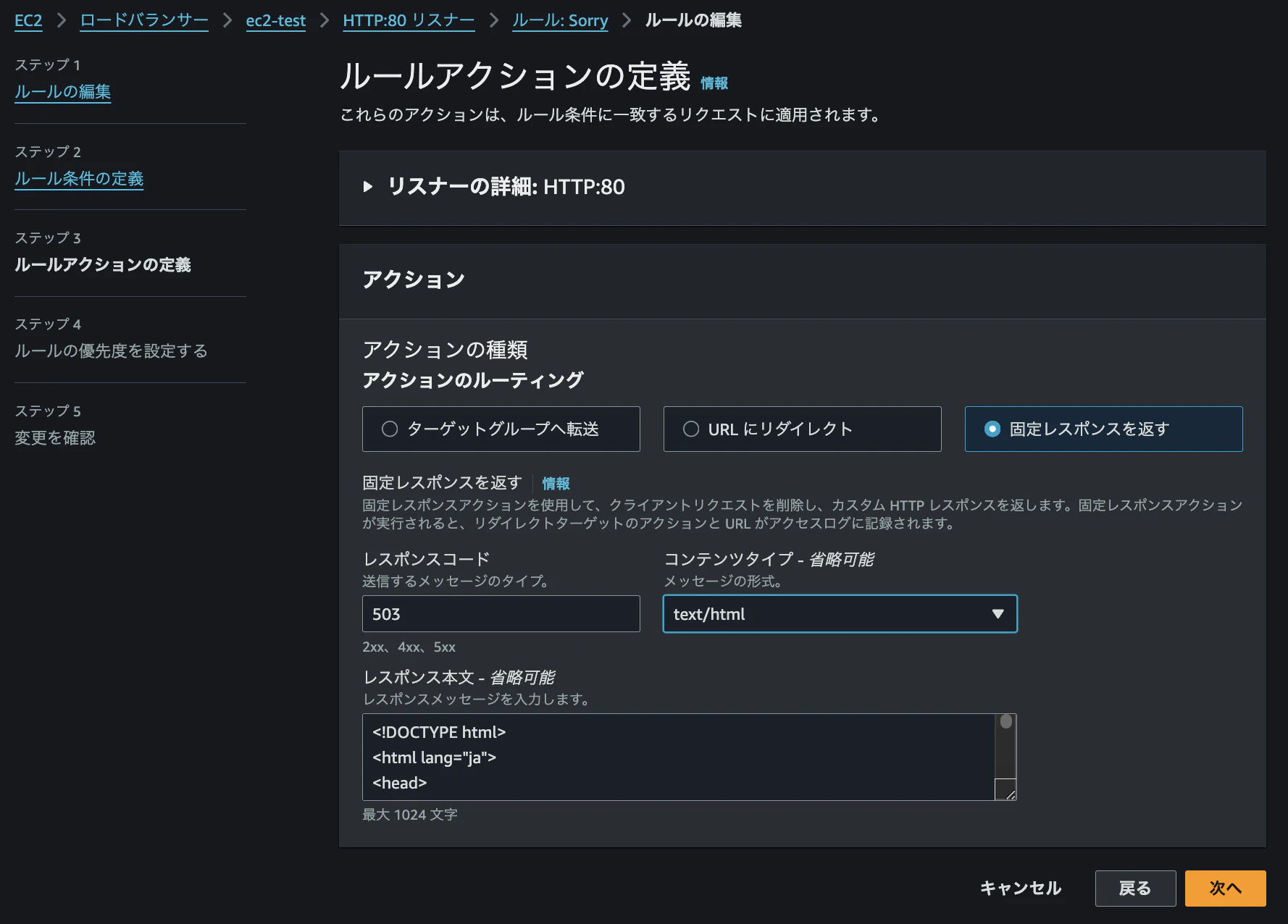
以下のHTMLファイルをレスポンス本文として入力します。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>障害発生中</title>
<style>
body {
font-family: Arial, sans-serif;
background-color: #f8d7da;
color: #721c24;
text-align: center;
padding: 50px;
}
h1 {
font-size: 2em;
}
p {
font-size: 1.2em;
}
</style>
</head>
<body>
<h1>障害が発生中です</h1>
<p>ご迷惑をおかけしております。復旧作業を行っておりますので、しばらくお待ちください。</p>
</body>
</html>
「Sorry」ルールの優先度を「3」に設定し、内容を確認したら作成をクリックします。
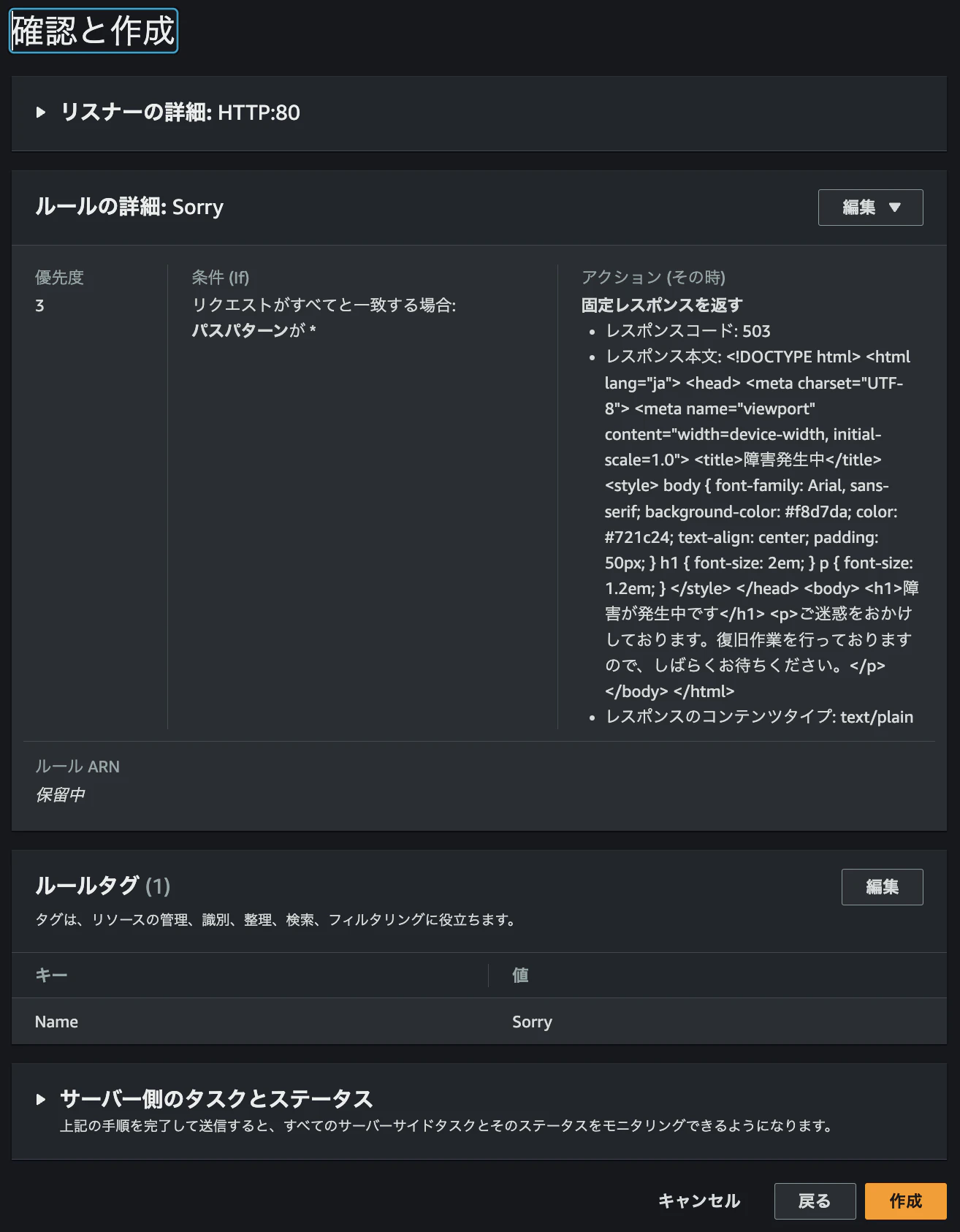
これで、ALBが特定の条件下でメンテナンスページを表示できるようになります。
ALBの通常ルール作成
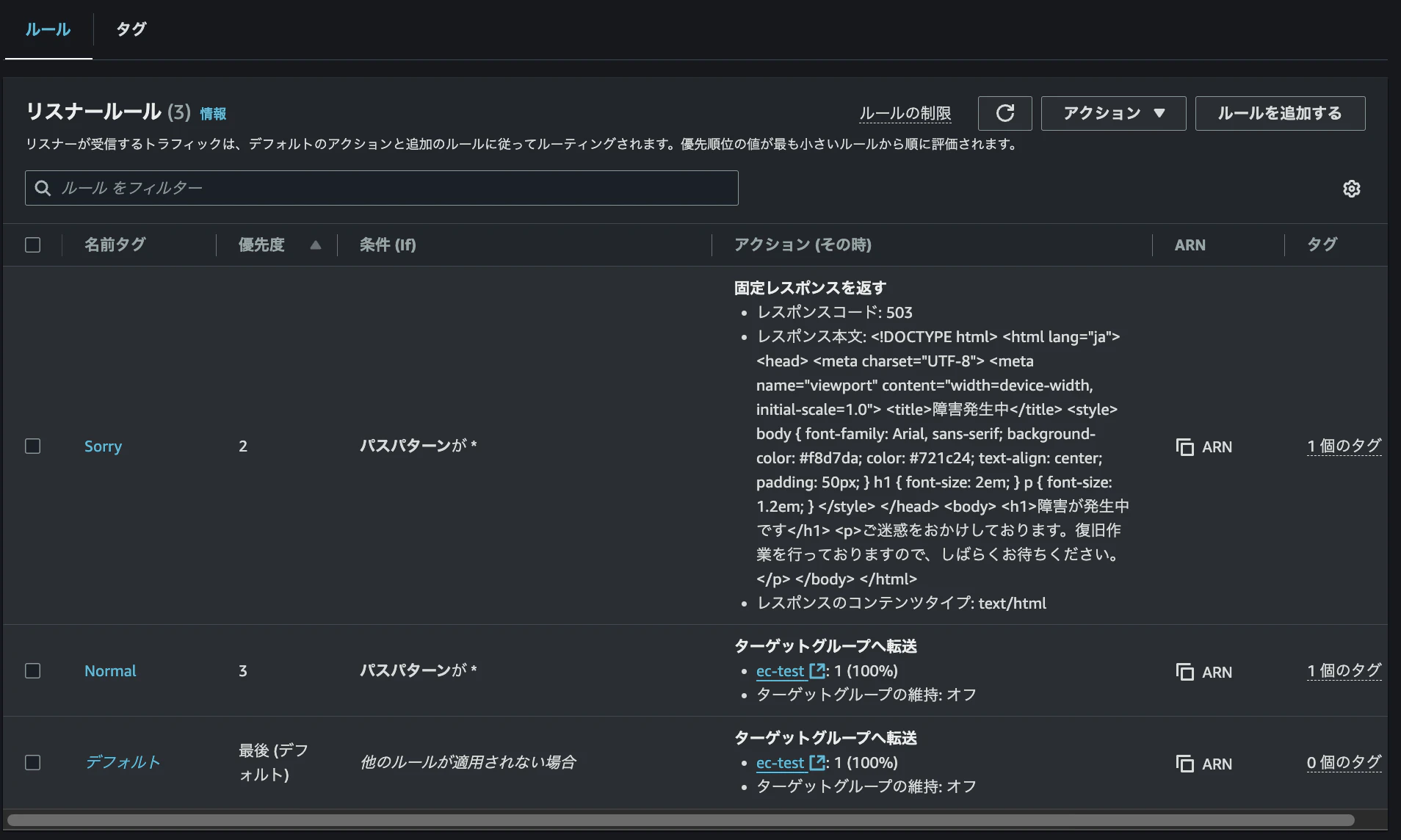
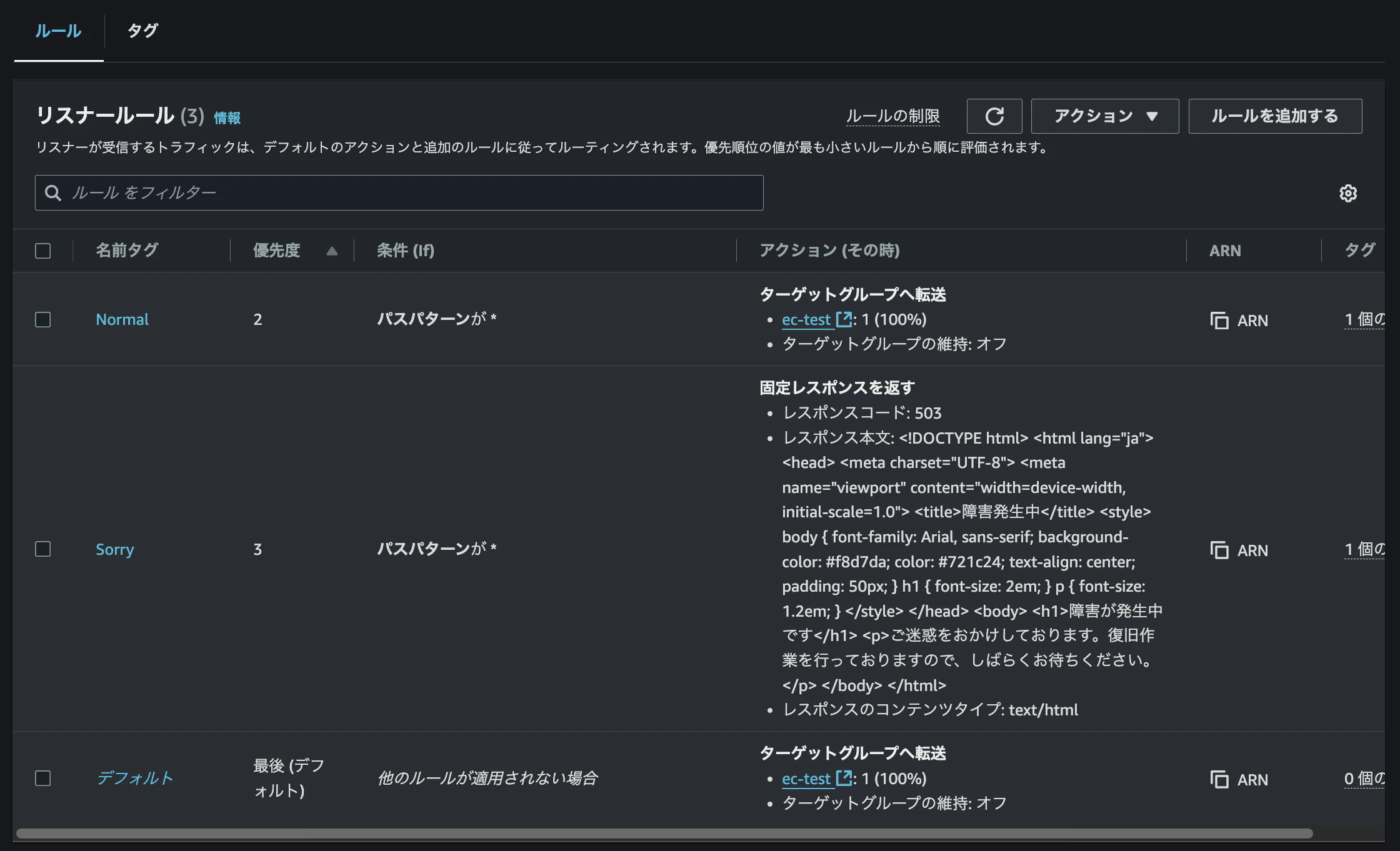
現在のALBのリスナーとルールの設定は以下のようになっています。

この設定では、すべてのアクセスに対して「*」が指定されているため、「Sorry」ルールが適用されてしまいます。
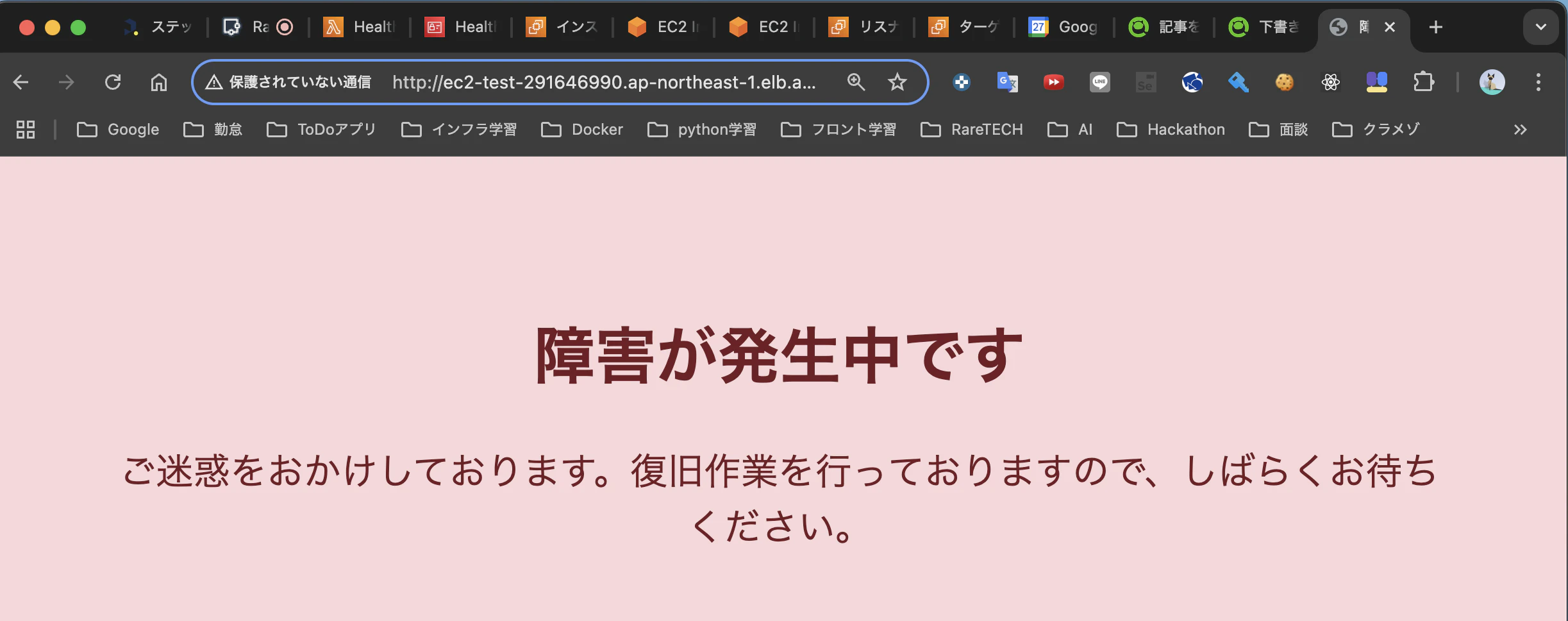
ALBのロードバランサーのDNS名にブラウザでアクセスしてみると、以下の通り、先ほど作成したメンテナンスページが表示されることを確認できます。
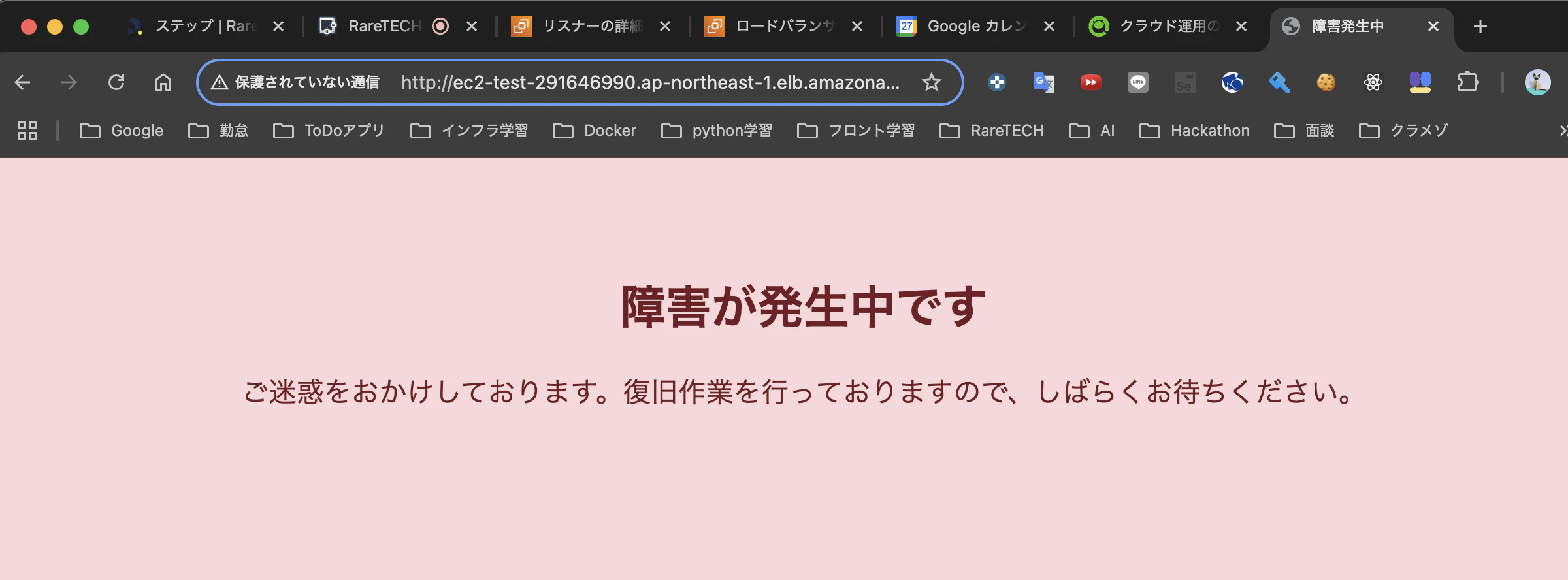
次に、優先度「2」で新規の「通常パターン」ルールを作成します。
リスナーとルールのタブから「ルールを追加」を選択し、ルール名を「Normal」として作成します。
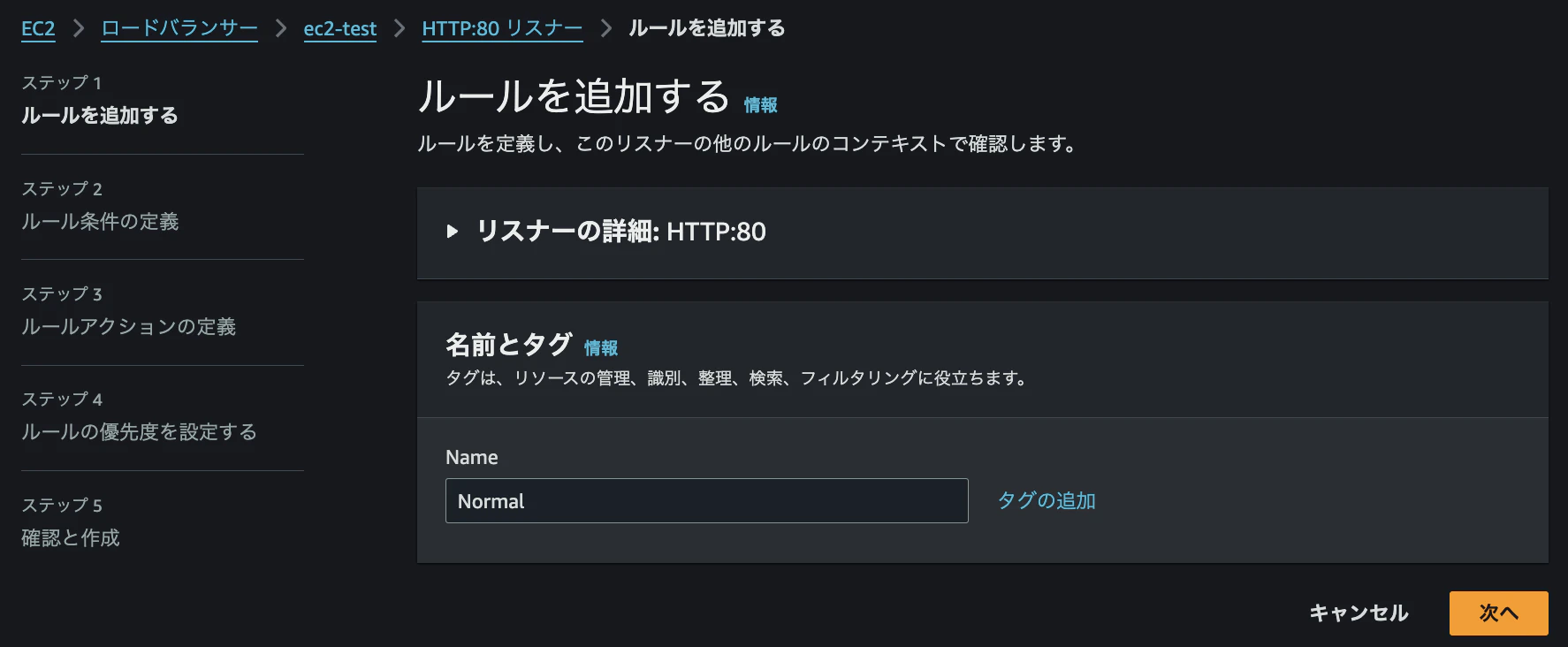
最終的に、以下のようにパスパターン設定を「*」とし、優先度を「2」に設定します。ターゲット先としては、EC2インスタンスが紐づいているターゲットグループを選択します。
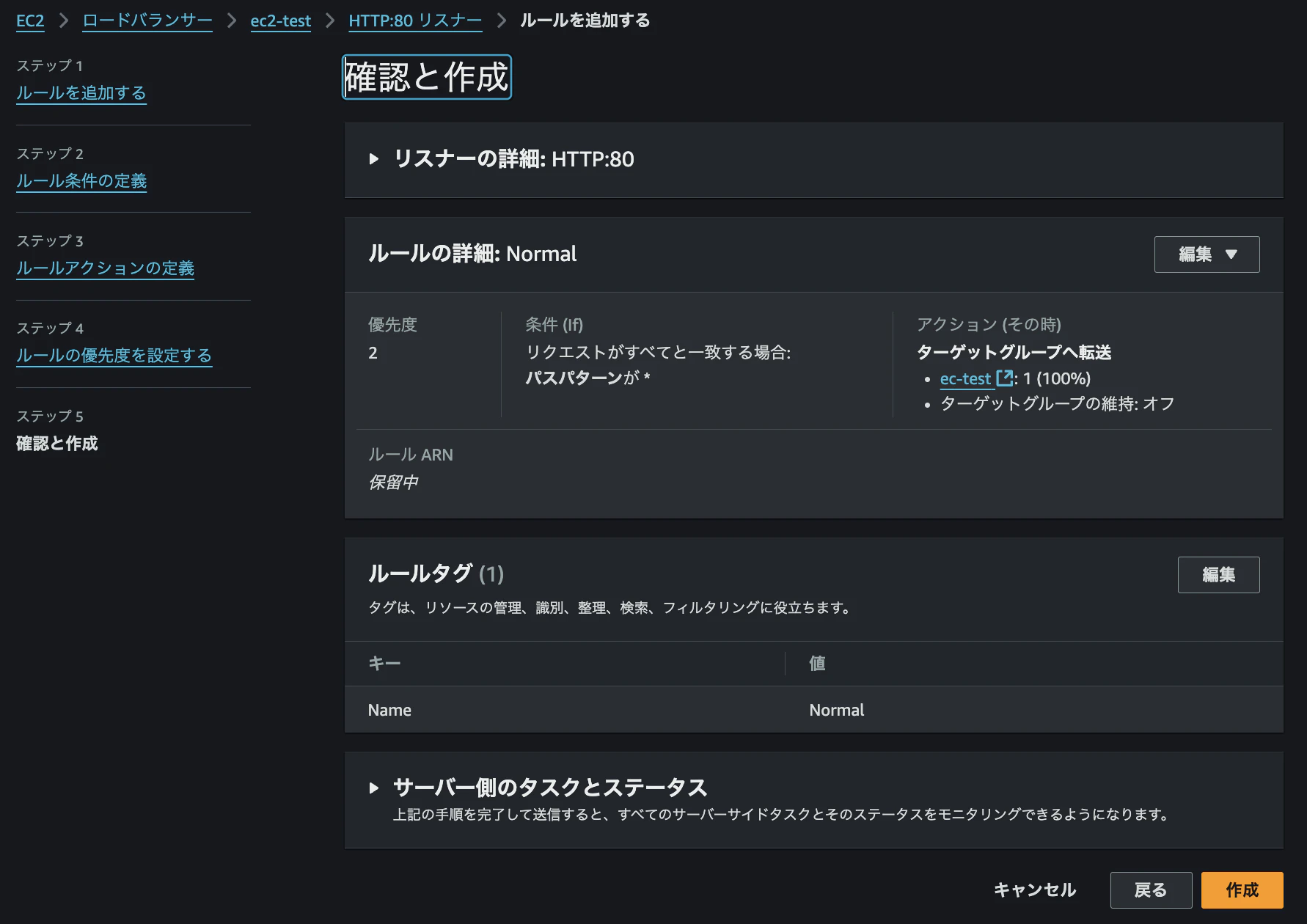
これにより、優先度が高い「Normal」ルールが適用される仕組みとなります。

実装手順
Lambda関数でALBの優先度変更プログラムを作成
次に、CloudWatchの「HealthyHostCount」とEventBridgeを使用したEC2障害検知システムの一部として、Lambda関数を作成します。
[変数]として設定する値は、ご自身の環境に合わせて適宜修正してください。
import json
import boto3
def lambda_handler(event, context):
alb_arn = "arn:aws:xxx"
alb_listener_arn = "arn:aws:xxx"
target_group_rule_arn = "arn:aws:xxx"
sorry_rule_arn = "arn:aws:xxx"
cloudwatch = boto3.resource('cloudwatch')
alarm = cloudwatch.Alarm("HealthlyHostCount")
client = boto3.client('elbv2')
current_rule_arn = client.describe_rules(ListenerArn=alb_listener_arn)['Rules'][0]['RuleArn']
if alarm.state_value == "ALARM" and current_rule_arn == sorry_rule_arn:
return {
'statusCode': 200,
'body': 'Sorryページはすでに表示されています'
}
elif alarm.state_value == "OK" and current_rule_arn == target_group_rule_arn:
return {
'statusCode': 200,
'body': '通常ページはすでに表示されています'
}
target_group_rule_priority = 2
sorry_rule_priority = 3
if current_rule_arn == target_group_rule_arn:
target_group_rule_priority = 3
sorry_rule_priority = 2
response = client.set_rule_priorities(
RulePriorities=[
{
'RuleArn': target_group_rule_arn,
'Priority': target_group_rule_priority
},
{
'RuleArn': sorry_rule_arn,
'Priority': sorry_rule_priority
},
])
return {
'statusCode': 200,
'body': json.dumps(response)
}
この関数は、ALBのルールを動的に切り替え、ヘルスチェックの結果に基づいて「Sorry」ルールと「Normal」ルールを切り替えます。
作成したLambda関数のデフォルトタイムアウトは「3秒」になっているため、「30秒」などに変更することをおすすめします。

テスト実行を行ったところ、以下のエラーが発生しました。調査したところ、Lambda関数に関連付けられているIAMロールの権限が不足していました。
[ERROR] ClientError: An error occurred (AccessDenied) when calling the DescribeRules operation: User: arn:aws:sts::xxx:assumed-role/HealthlyHostCount-Lambda-role-lsp6fcvh/HealthlyHostCount-Lambda is not authorized to perform: elasticloadbalancing:DescribeRules because no identity-based policy allows the elasticloadbalancing:DescribeRules action
Traceback (most recent call last):
この問題を解決するために、カスタムIAMポリシーを作成し、IAMロールにアタッチしました。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"elasticloadbalancing:DescribeRules",
"elasticloadbalancing:SetRulePriorities",
"cloudwatch:DescribeAlarms"
],
"Resource": "*"
}
]
}
Lambda関数とEventBridgeの統合
Lambda関数をEventBridgeと統合することで、ALBのターゲットグループの状態がすべて正常でない場合に自動でメンテナンスページを表示することができます。
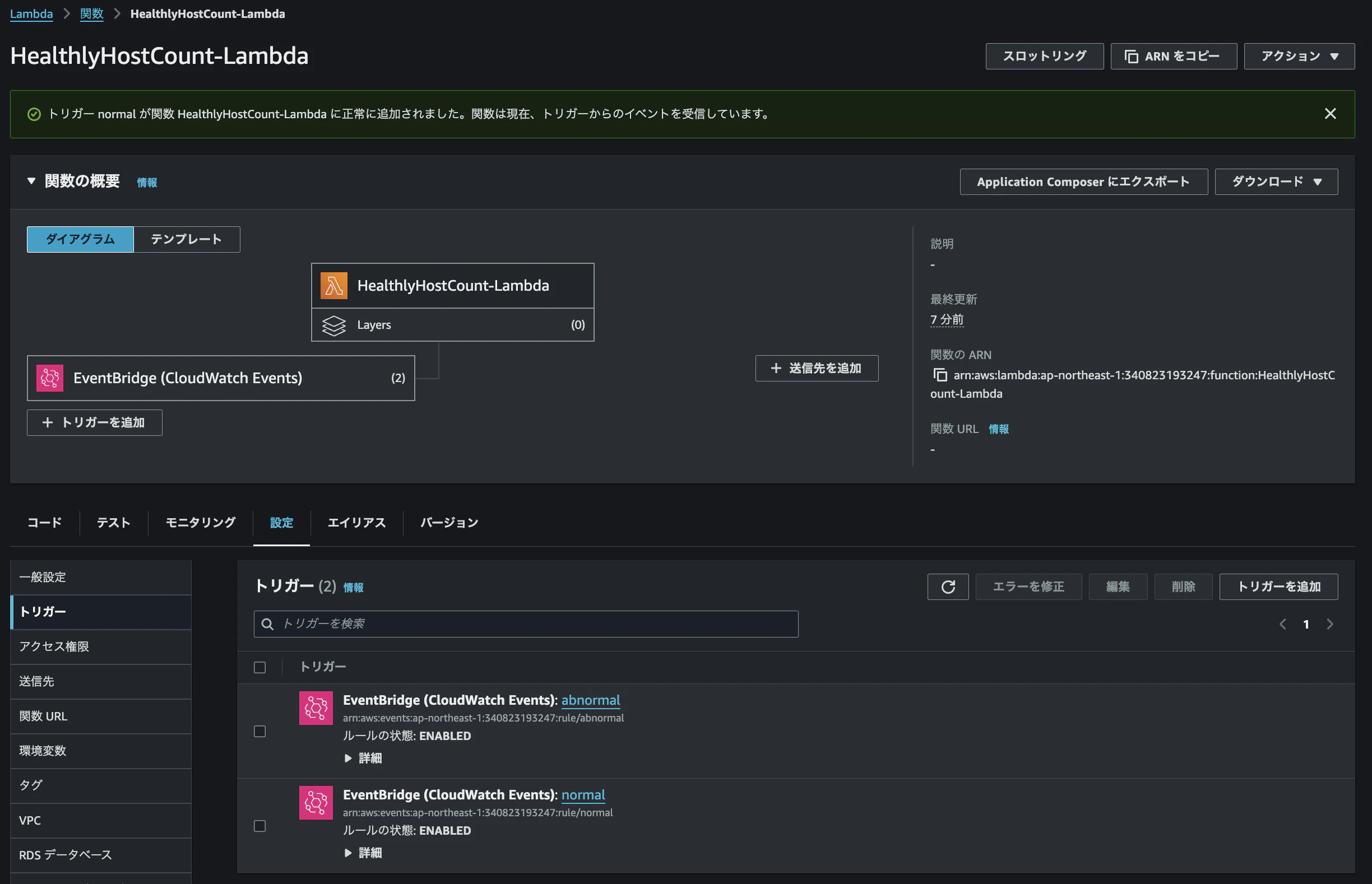
先ほど作成したLambda関数の画面からトリガーを追加します。

一つのLambda関数の処理に対して、EventBridge (CloudWatch Events)のルールを2つ設定します。
検証確認
障害発生時のパターン
ALBに紐づくターゲットグループがすべてNGとなった場合に、メンテナンスページ(503エラー)が表示されるかどうかを検証します。
まず、sudo systemctl stop httpd.serviceコマンドを使用してhttpdサービスを明示的に停止します。

ターゲットグループのヘルスチェックが全台NGになったことがCloudWatchで検知されました。
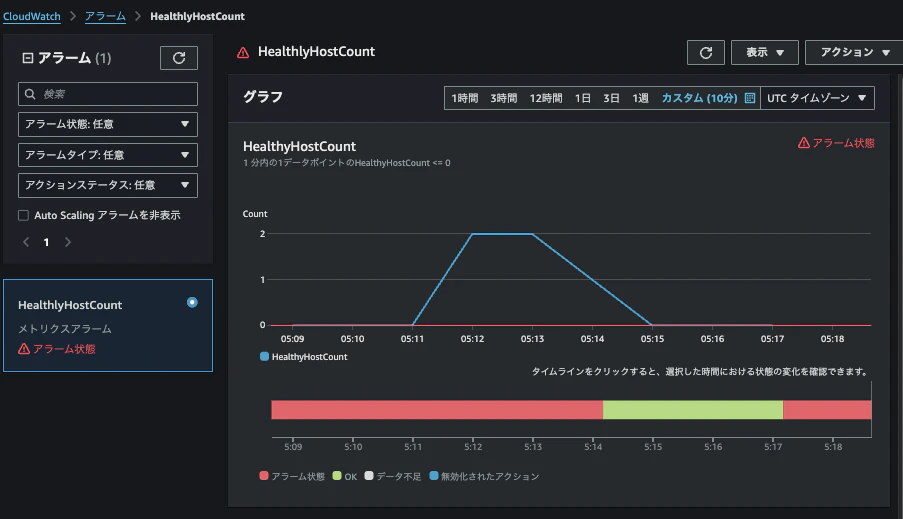
その後、EventBridgeのルールが正常に動作していることが確認できました。
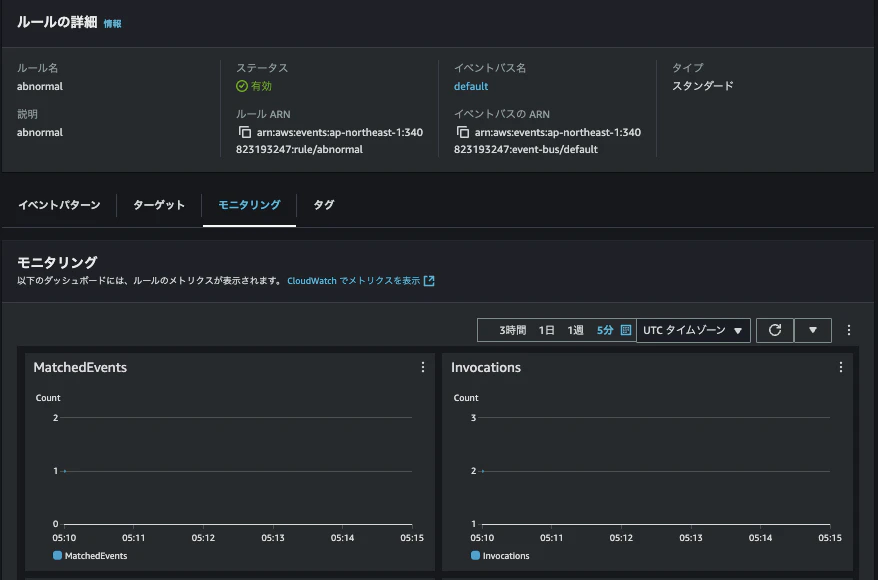
Lambda関数内でリスナーとルールの設定(優先度)が変更されていることも正常に確認できました。
最後に、ブラウザでアクセスした際にメンテナンスページが表示されることも確認できたため、障害発生時のパターンは成功です!
障害復旧時のパターン
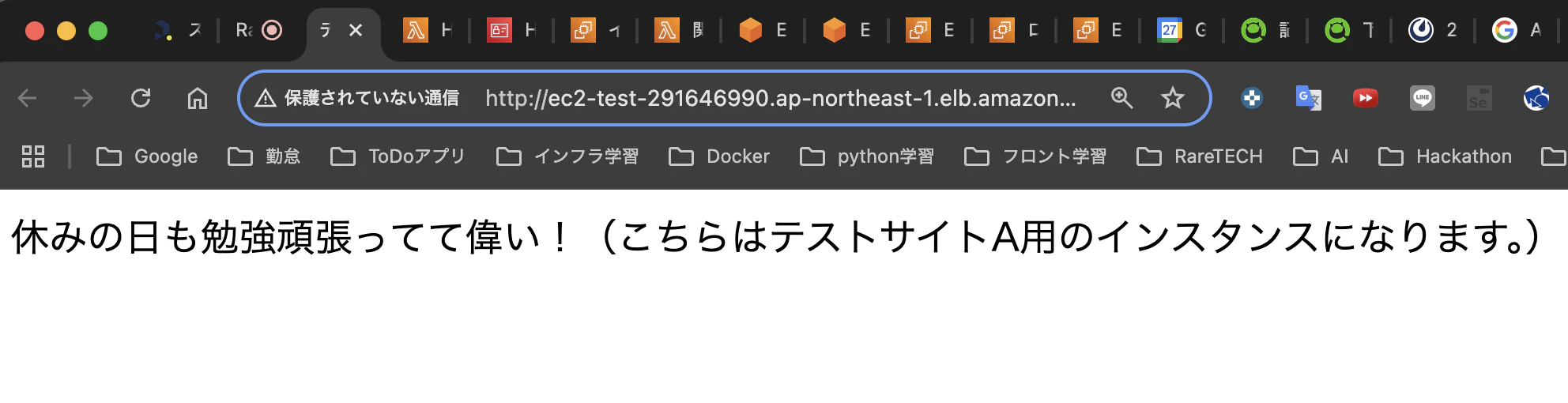
ALBのターゲットグループが正常に戻った際に、通常ページが表示されるかどうかを確認します。
今回は、あえてApacheサービスが1台のみ起動している場合でも動的に切り替えが行われるかを検証します(2台復旧時については動作確認済みです)。
次に、sudo systemctl start httpd.serviceコマンドを使用してhttpdサービスを明示的に起動します。
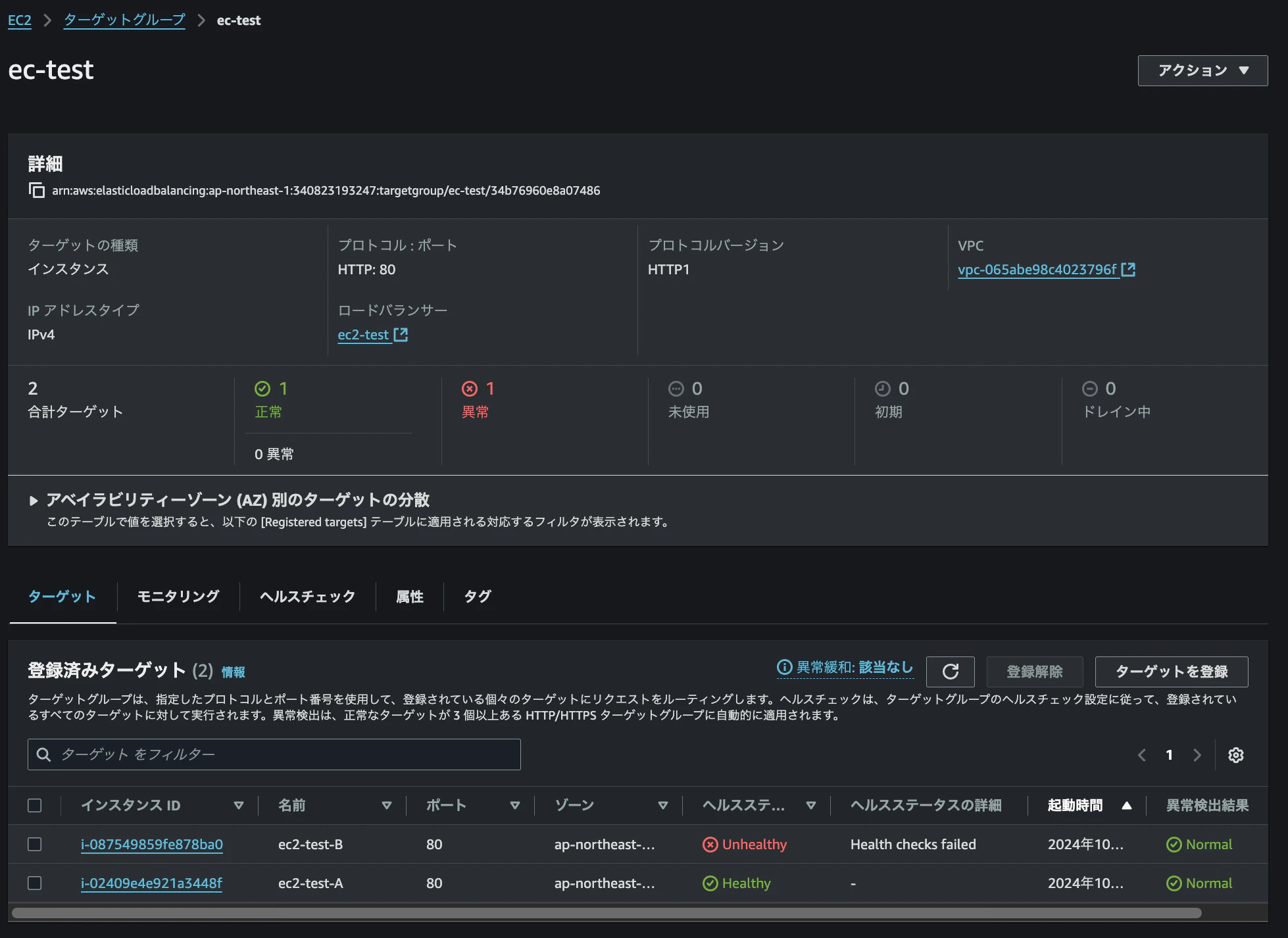
ターゲットグループのヘルスチェックで1台のみOKになったことがCloudWatchで検知され、アラート状態が復旧したことが確認できました。

その後、EventBridgeのルールが正常に動作し、Lambda関数内でリスナーとルールが変更(優先度)されていることも確認できました。
最後に、ブラウザでアクセスした際に通常ページが表示されることも確認できたため、障害復旧時のパターンも成功です!
まとめ
ここまで読んでいただきありがとうございました。
今回は、ターゲットグループ全台NG時にメンテナンスページが表示され、復旧後に通常ページへ自動切り替えできるかを検証しました。
ヘルスチェック、EventBridgeルール、Lambda関数の動作を確認する工程が多く難易度が高かったものの、すべて正常に動作し、検証をやり切ることができました。
過去の関連記事